はじめに
この記事は、最近巷で耳にするようになった連合学習(Federated Learning)を実際に手元のPCで行い、AI学習の先端技術に触れてみようと思います。
皆さんは連合学習というキーワードをご存じでしょうか。何かしらで耳にされてこの記事を読んでいただいていると思いますが、サラッとおさらいを述べて、本題(ハンズオン)に入りたいと思います。
連合学習(Federated Learning)とは
AIモデルの構築において従来のようにデータを1か所に集約することなく、分散された複数の学習環境によって並列的に学習を行う手法です。
各学習環境にあるデータを用いて各々が学習を行い、それぞれで生成されるニューラルネットワークのノードを繋ぐウェイト値を集約して統合することで、それぞれの学習環境のデータ量が少量であっても全ての学習環境で用いられたデータを使用して学習を行う場合と同等のモデルを構築することができます。
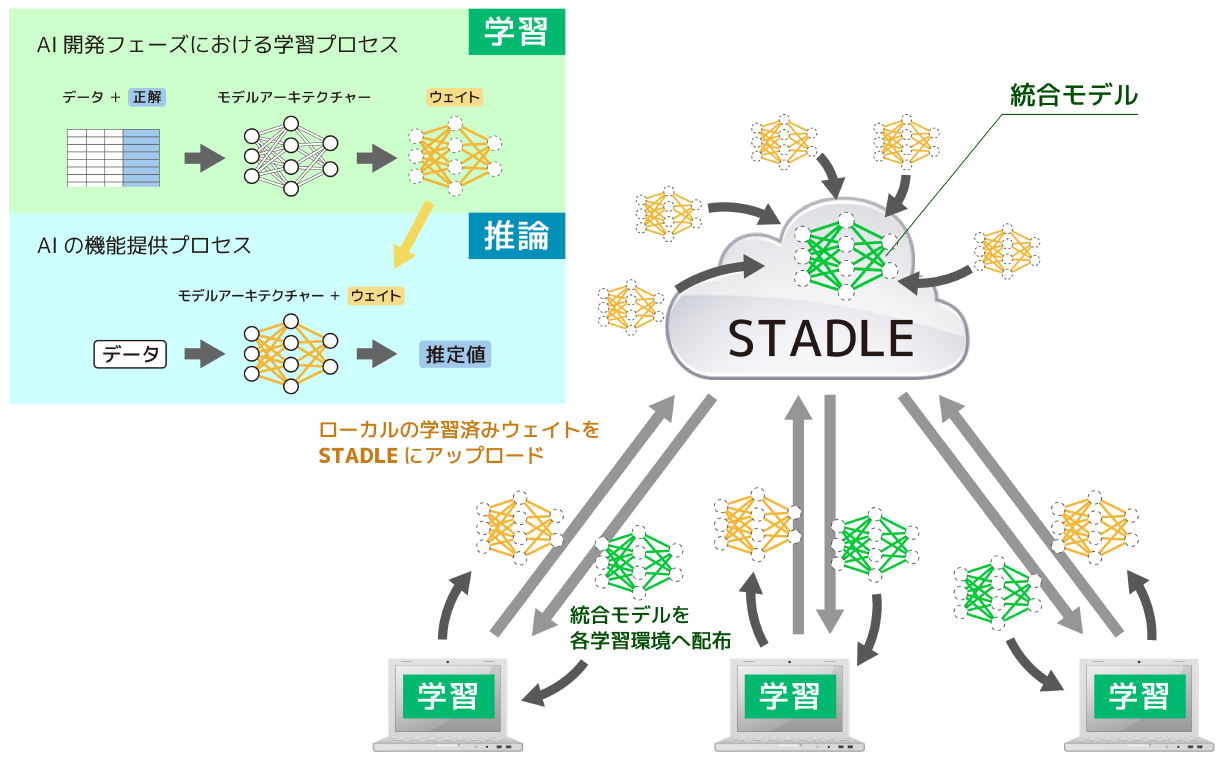
これにより、並列的に学習を進められるので単一の学習環境で行う学習に比べ効率的に学習が行えるうえに、各学習環境間で データを共有することなく 統合モデルを構築出来るので、企業間をまたいだ連合学習に参加しても秘匿情報を他社に共有することなく、数社のデータを使用した業界共通のグローバルモデルを構築することが可能です。
この連合学習は、Google社により2017年に既に実用化されていて、私たちが普段利用しているAndroid携帯のキーボード(Gboard)で予測変換モデルのリトレーニングに利用されています。
この予測変換モデルのリトレーニングは手元の携帯端末の中で行われ、リトレーニングの際には私たちが打ち込んだテキスト情報はどこにも送信されていません。
また、携帯端末の場合、大量の端末からモデルを集約できるので、驚くほど効率的にモデルの向上が可能です。
このように、データの秘匿性の担保と効率的な学習という点で、これから先のAIサービスの提供においてスタンダードな手法になると感じています。
既に社会実装が進んでいるこの連合学習ですが、具体的にはどのように行なうのかをハンズオンを通してご紹介します。
連合学習プラットフォーム
連合学習の環境を手元のPC上に構築することは、従来まではたいへん手間のかかる作業でした。
ここでは、SaaS化された連合学習プラットフォームである STADLE ( https://stadle.ai ) を使用して、連合学習のコアになる部分をセットアップすることなく学習環境側のセットアップのみで簡単に連合学習を体験していただく手順をご紹介します。
動作環境の前提
連合学習におけるモデルの集約(アグリゲーション)を行う部分は先述のプラットフォームを使用します。
したがって、この部分は特別なセットアップは不要で、下記のURLにアクセスしてサインアップすればOKです。
stadle.ai ( https://stadle.ai )
上記のサイトでモデルのアグリゲーターを起動して、手元のPCで実行するMLアプリケーションから接続をします。
Pythonで記述されたMLアプリケーションを実行しますので、Pythonの実行環境を用意してください。
筆者の環境はWindowsなので、AnacondaもしくはWSLで実行するUbuntuなどの選択肢があります。
基本的にはどちらでも手順は大きく変わりませんが、仮想環境の準備段階だけ注意が必要です。その点も含めて解説します。
ローカル環境(MLエージェント)のセットアップ
仮想環境の準備(Anacondaの場合)
Conda環境の作成
AnacondaプロンプトからMLアプリケーションを実行するためのライブラリをインストールする仮想環境を作成
> conda create -n ENVCLIENT python=3.8
※上記の例では ENVCLIENT というConda仮想環境を作成
作成した仮想環境(ENVCLIENT)をアクティベート
> conda activate ENVCLIENT
※カレントの冒頭に(ENVCLIENT)がついたことを確認
(ENVCLIENT) C:¥Users¥ユーザー名 >
仮想環境の準備(Ubuntuの場合)
任意のディレクトリにvenvを作成します。
下記の例では、~/dev/stadle_clientというディレクトリにvenv環境を作成しています。
venvの作成
$ pyton3 -m venv ENVCLIENT
※上記の例では ENVCLIENT というvenv環境を作成
作成したENVCLIENTをアクティベート
$ source ENVCLIENT/bin/activate
※カレントの冒頭に(ENVCLIENT)がついたことを確認
(ENVCLIENT) ~/dev/stadle_client $
pipのアップデート
※以下、Anacondaの場合で説明をしますがUbuntuでも同様です
pipをアップデート
> pip install --upgrade pip
STADLEクライアントのインストール
下記のコマンドで、必要なライブラリをインストール
> pip install stadle-client
ライブラリのインストールにより stadle.ai への接続準備が完了します。
以下、具体的にどのように連合学習を行うか解説をします。
連合学習の大まかな手順
連合学習においては以下のように2ステップの手順を行います。
- ベースモデルのアップロード
- 学習コードの実行
ベースモデルのアップロードとは、連合学習を行うモデルの構造(アーキテクチャ)をアグリゲーターに登録することを意味します。
そのうえで、各学習環境で学習コードを実行することによって生成されるウェイトの値を集約します。
MLアプリケーションのファイル構成
この例では、手書きの数字を分類するモデルの学習をmnistデータセットを用いて行います。
下記の構成でコードを用意していきます。
mnist_example/
├── config/
│ └── config_agent.json ← 学習コードの設定ファイル
├── models/
│ └── samplenet.py ← モデルアーキテクチャ(ベースモデル定義)
├── mnist_admin_agent.py ← ベースモデルのアップロード
└── mnist_ml_agent.py ← 学習コード
コードの内容
config/config_agent.json
連合学習中のローカルの学習結果の保存先やローカルモデルやセミグローバルモデルのファイル名を定義しています。
基本的には以下のままコピペしてconfig_agent.jsonとして保存してください。
重要な部分はagg_ipとreg_portです。
agg_ipは接続先のIPアドレスを指定します。
stadle.aiへの接続の場合は以下の例の通り、52.8.109.30を指定します。
reg_portは、後述するstadle.aiのGUIによりプロジェクト内で起動したアグリゲーターへの接続ポートを指定します。
後ほど編集するので一旦は適当な数値でかまいません。
{
"model_path": "./data/agent",
"local_model_file_name": "lms.binaryfile",
"semi_global_model_file_name": "sgms.binaryfile",
"state_file_name": "state",
"aggr_ip": "52.8.109.30",
"reg_port": "8866",
"init_weights_flag": 1,
"token": "stadle12345",
"simulation": "False",
"exch_socket": "0000",
"agent_name": "default_agent"
}
models/samplenet.py
通常、MLアプリケーションのコードを書く場合、冒頭付近でモデルアーキテクチャを定義します。
連合学習では各学習環境での学習を実行する前にこのモデルアーキテクチャをアグリゲーターに登録するため、学習のコードとは切り離して個別のファイルとしておきます。
mnistのデータセットに含まれる手書き数字の画像データは28ピクセル×28ピクセルのため、入力層を28×28の784として、中間層を1000、出力層10のシンプルな3層構造としています。
import torch
from torch import nn
import torch.nn.functional as f
class SampleNet(torch.nn.Module):
def __init__(self):
super(SampleNet, self).__init__()
self.fc1 = torch.nn.Linear(28*28, 1000)
self.fc2 = torch.nn.Linear(1000, 10)
def forward(self, x):
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return f.log_softmax(x, dim=1)
mnist_admin_agent.py
このコードで、上記のmodels/samplenet.pyで定義したアーキテクチャをアグリゲーターに登録します。
from stadle import AdminAgent
from stadle.lib.util import client_arg_parser
from stadle.lib.entity.model import BaseModel
from stadle import BaseModelConvFormat
# import model architecture
from models.samplenet import SampleNet
def get_samplenet_model():
return BaseModel("PyTorch-Mnist-Model", SampleNet(), BaseModelConvFormat.pytorch_format)
if __name__ == '__main__':
args = client_arg_parser()
admin_agent = AdminAgent(config_file="config/config_agent.json", simulation_flag=args.simulation,
aggregator_ip_address=args.aggregator_ip, reg_port=args.reg_port, agent_name=args.agent_name,
exch_port=args.exch_port, model_path=args.model_path, base_model=get_samplenet_model(),
agent_running=False)
admin_agent.preload()
admin_agent.initialize()
mnist_ml_agent.py
実際の学習を実行するコードです。
連合学習の効果を見やすくするために、mnistデータセットの中から使用するデータを選択して各学習環境において異なるデータで学習を実行できるように設定しています。学習を実行する際に引数で指定します。
import torch
import torch.nn.functional as f
from torch.utils.data import DataLoader, Subset
from torchvision import datasets, transforms
# import model architecture
from models.samplenet import SampleNet
# import stadle BasicClient class
from stadle import BasicClient
import argparse
def load_MNIST(batch=128, intensity=1.0, classes=None, sel_prob=1.0, def_prob=0.1):
trainset_size = 60000
# Set the dataset mask to perform training with biased data
if (args.classes is not None):
trainset = datasets.MNIST('./data',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x * intensity)
])
)
classes = [int(c) for c in args.classes.split(',')]
mask = (trainset.targets == -1)
for i in range(10):
class_mask = (trainset.targets == i)
mask_idx = class_mask.nonzero()
class_size = len(mask_idx)
size = sel_prob if (i in classes) else def_prob
mask_idx = mask_idx[torch.randperm(class_size)][:int(class_size * size)]
mask[mask_idx] = True
trainset.data = trainset.data[mask]
trainset.targets = trainset.targets[mask]
trainset_size = len(trainset)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch, shuffle=True)
else:
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x * intensity)
])),
batch_size=batch,
shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data',
train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x * intensity)
])),
batch_size=batch,
shuffle=True)
return {'train': train_loader, 'test': test_loader}, trainset_size
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='STADLE CIFAR10 Training')
parser.add_argument('--agent_name', default='default_agent')
parser.add_argument('--classes')
parser.add_argument('--def_prob', type=float, default=0.1)
parser.add_argument('--sel_prob', type=float, default=1.0)
parser.add_argument('--reg_port')
args = parser.parse_args()
# Number of times of learning
epoch = 50
# For saving learning results
history = {
'train_loss': [],
'test_loss': [],
'test_acc': [],
}
# Build Network
net: torch.nn.Module = SampleNet()
loaders, trainset_size = load_MNIST(classes=args.classes, def_prob=args.def_prob, sel_prob=args.sel_prob)
optimizer = torch.optim.Adam(params=net.parameters(), lr=0.001)
client_config_path = r'config/config_agent.json'
# Preload stadle_client
stadle_client = BasicClient(config_file=client_config_path, agent_name=args.agent_name, reg_port=args.reg_port)
stadle_client.set_bm_obj(net)
for e in range(epoch):
if (e % 2 == 0): # Set how many epochs the aggregation is executed
# Don't send model at beginning of training
if (e != 0):
# Get model performance
perf_dict = {
'performance':history['test_acc'][-1],
'accuracy' : history['test_acc'][-1],
'loss_training' : history['train_loss'][-1],
'loss_test' : history['test_loss'][-1]}
# Send trained local model
stadle_client.send_trained_model(net, perf_dict)
# Recieve semi global model
state_dict = stadle_client.wait_for_sg_model().state_dict()
net.load_state_dict(state_dict)
# Training
loss = None
net.train(True)
for i, (data, target) in enumerate(loaders['train']):
data = data.view(-1, 28 * 28)
optimizer.zero_grad()
output = net(data)
loss = f.nll_loss(output, target)
loss.backward()
optimizer.step()
if i % 10 == 0:
print('Training log: {} epoch ({} / {} train. data). Loss: {}'.format(e + 1, (i + 1) * 128,
trainset_size, loss.item()))
history['train_loss'].append(loss.item())
#Test
net.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in loaders['test']:
data = data.view(-1, 28 * 28)
output = net(data)
test_loss += f.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= 10000
print('Test loss (avg): {}, Accuracy: {}'.format(test_loss,
correct / 10000))
history['test_loss'].append(test_loss)
history['test_acc'].append(correct / 10000)
再度、上記までのファイルが以下のディレクトリ構成になっていることを確認してください。
mnist_example/
├── config/
│ └── config_agent.json ← 学習コードの設定ファイル
├── models/
│ └── samplenet.py ← モデルアーキテクチャ(ベースモデル定義)
├── mnist_admin_agent.py ← ベースモデルのアップロード
└── mnist_ml_agent.py ← 学習コード
stadle.ai
ここまでで、学習環境に必要なコードが揃いましたので、いよいよstadle.aiで連合学習を行います。
下記のURLからstadle.aiへアクセスします。
https://stadle.ai
サインアップとログイン
Sign up をしてアカウントを作成のうえログインをします。
プロジェクトの作成
ログインするとこのような画面に遷移します。
Create New Project ボタンをクリックして、新規プロジェクトを作成します。
Project Name をmnist_FLとでもしておきましょう。
Create Project ボタンで確定します。
すると、このようにmnist_FLプロジェクトができます。
Initiate Aggregator の+ボタンをクリックしてアグリゲーターを起動します。
画面を更新すると、Aggregator count が 1 に変わります。
左サイドバーの Dashboard をクリック
以下のようなダッシュボード画面に遷移します。
ここには先ほど作成したプロジェクトで起動しているアグリゲーターへの接続先として、IPアドレスとポート番号が表示されます。
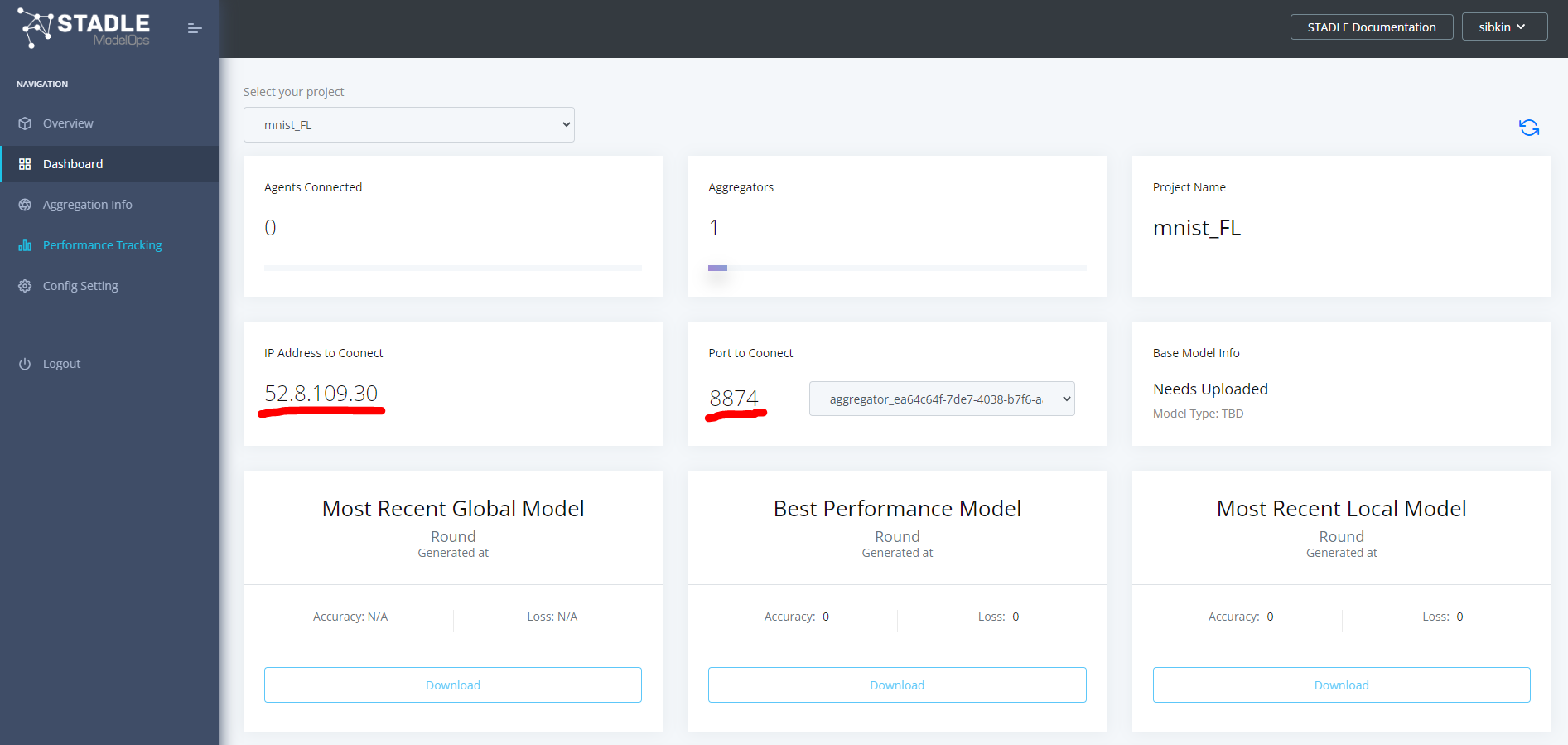
ここまででサーバーサイドの準備は完了です。
ローカル環境(MLエージェント)でMLアプリケーションを実行
次にローカルPC上でMLアプリケーションを実行します。
Configファイルの編集(config/config_agent.json)
先ほど用意したconfig/config_agent.jsonの reg_port の行を編集します。
ダッシュボードに表示されている4桁の番号にします。
※この例では8874ですが、アグリゲーターを起動するたびに異なる番号になります
{
"model_path": "./data/agent",
"local_model_file_name": "lms.binaryfile",
"semi_global_model_file_name": "sgms.binaryfile",
"state_file_name": "state",
"aggr_ip": "52.8.109.30",
"reg_port": "8874",
"init_weights_flag": 1,
"token": "stadle12345",
"simulation": "False",
"exch_socket": "0000",
"agent_name": "default_agent"
}
モデルアーキテクチャをアップロード
ここから各コードを実行します。
用意したディレクトリ( mnist_example/ )はWindowsのユーザーフォルダにあるものとします。
下記のように引数 --agent_name を使用して admin_agent を指定して実行します。
> python mnist_admin_agent.py --agent_name admin_agent
【接続エージェント識別名指定引数】
--agent_name エージェント名
プロセスが正常に終了したことを確認
stadle.ai のダッシュボードを更新すると、以下のようにアップロードしたモデルアーキテクチャ名が登録され、Agents Connected が1になります。
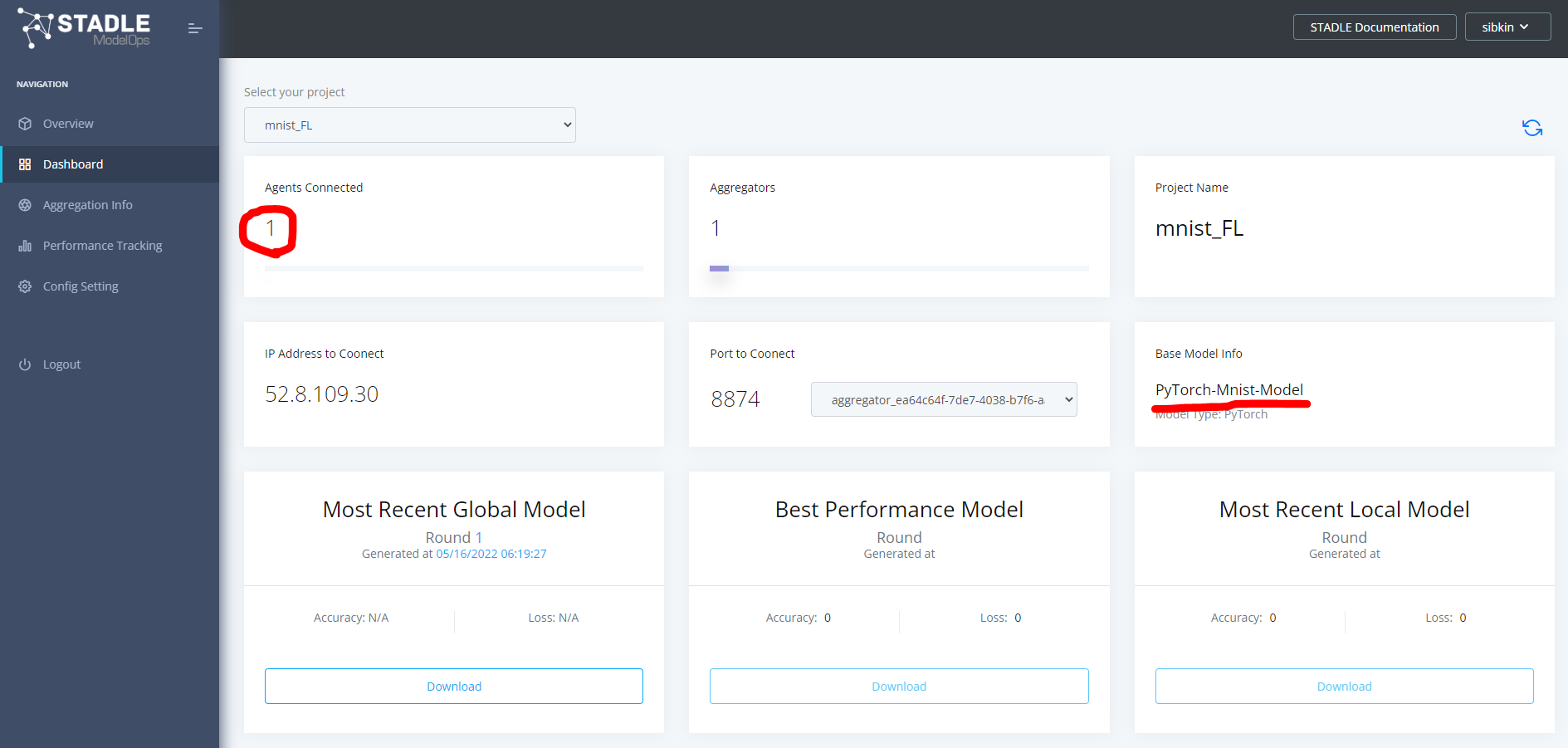
学習プロセスの実行
次に複数のターミナルで学習プロセスを実行します。
この例では、手元のPCだけで3つの学習環境を実行しますが、もちろん複数の異なるPCを使用した学習環境でも可能です。
その場合は、各PCへ環境構築をしておきます。
先ほどのモデルアーキテクチャをアップロードしたターミナルからは以下のコマンドで agent01 という名前でプロセスを実行します。
> python mnist_ml_agent.py --agent_name agent01 --classes 1,2,3 --sel_prob 1.0 --def_prob 0.05
他のターミナルを開いて、同様にconda環境 "ENVCLIENT" に入り、mnist_example/デレクトリに移動
以下のコマンドで agent02 という名前でプロセスを実行します。
> python mnist_ml_agent.py --agent_name agent02 --classes 4,5,6 --sel_prob 1.0 --def_prob 0.05
同様にして3つめのターミナルを用意して以下のコマンドで agent03 という名前でプロセスを実行
> python mnist_ml_agent.py --agent_name agent03 --classes 7,8,9,0 --sel_prob 1.0 --def_prob 0.05
上記コマンドの引数は、--classes が学習に使用するラベルを指定します。
上記の例では、agent01 が手書き文字の1/2/3を選択し、agent02 が4/5/6を選択し、agent03 が7/8/9/0を選択しています。
--sel_prob は選択した数字を学習で用いる比率で、1.0は選択した数字のデータを全て使用することを意味します。
--def_prob は選択されていない他の数字を学習に用いる比率で、0.05は5%を意味します。
すなわち、agent01 は1/2/3のラベルがついたデータを全て使用し、4以降の他の数字データについては5%しか使用せずに学習を実行しています。
【接続エージェント識別名指定引数】
--agent_name エージェント名
【使用データ選択引数】
--classes 指定クラス(カンマ区切り)
【選択データ使用比率引数】
--sel_prob 比率 0.0~1.0
【非選択データ使用比率引数】
--def_prob 比率 0.0~1.0
ここまでで、conda環境ENVCLIENT内で3つのMLプロセスが実行されます。
この状態でダッシュボードの表示は以下のようになり、Agents Connectedが4になっているはずです。
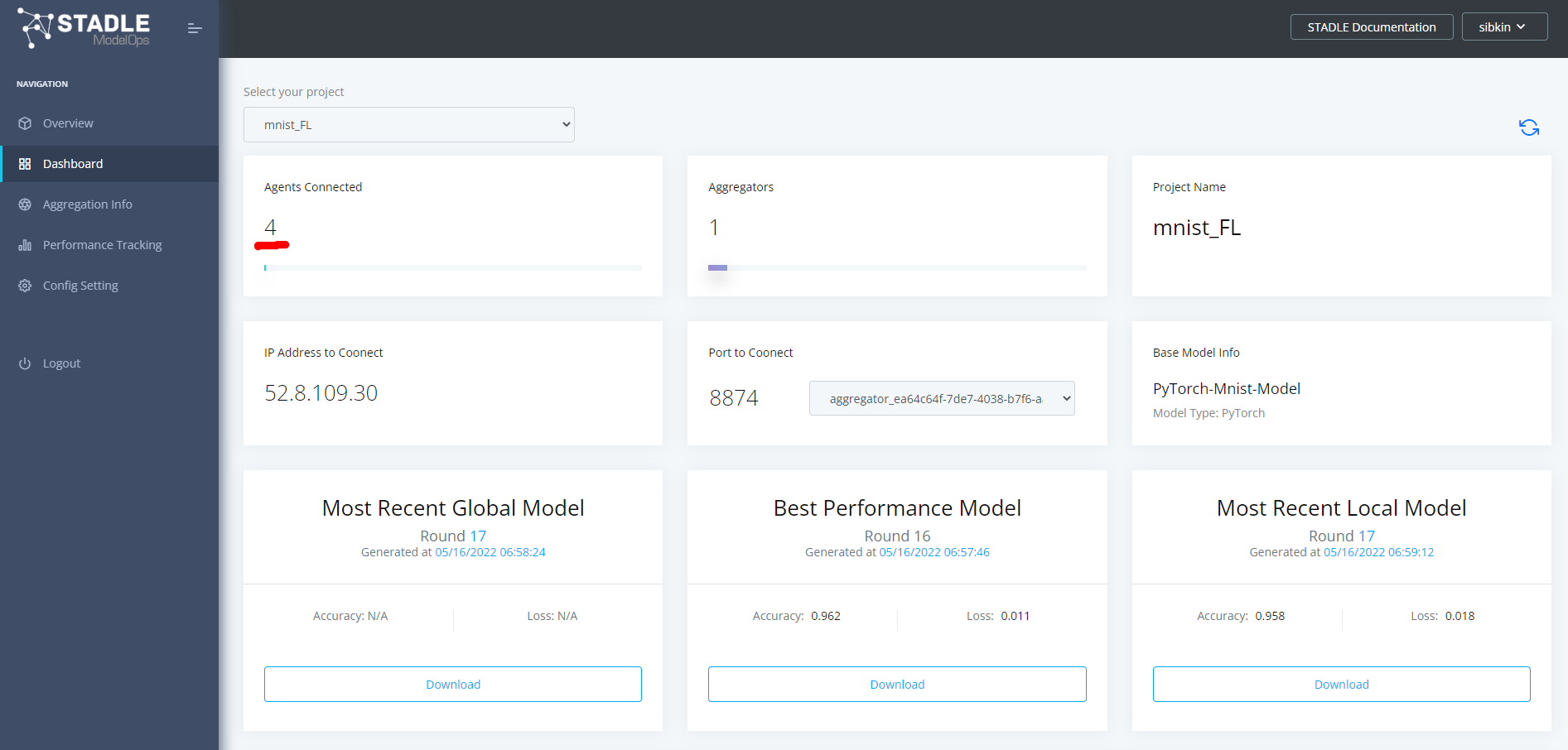
学習過程のモニタリング
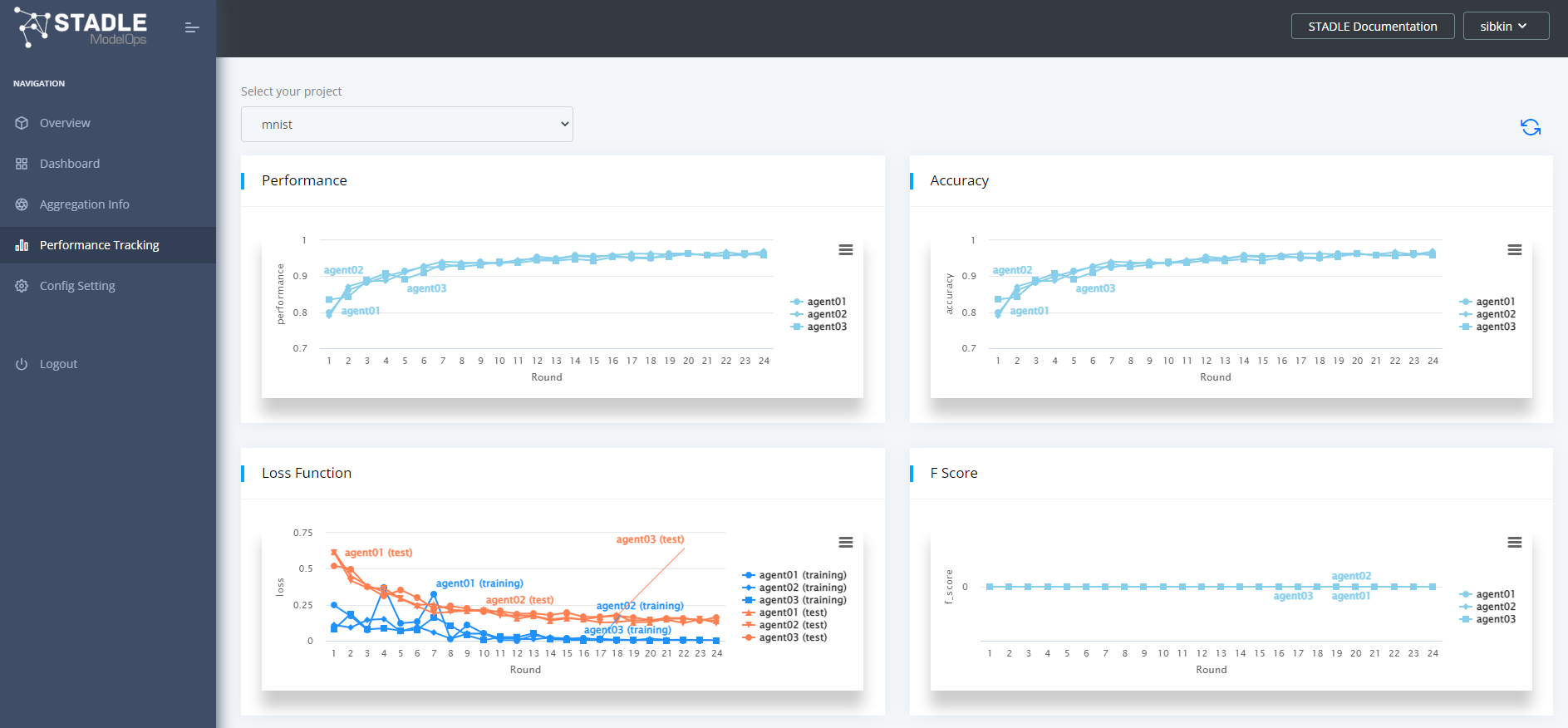
左のサイドバーからPerformance Trackingを選択するとモデルの各評価指標について学習過程のモニタリングが可能です。
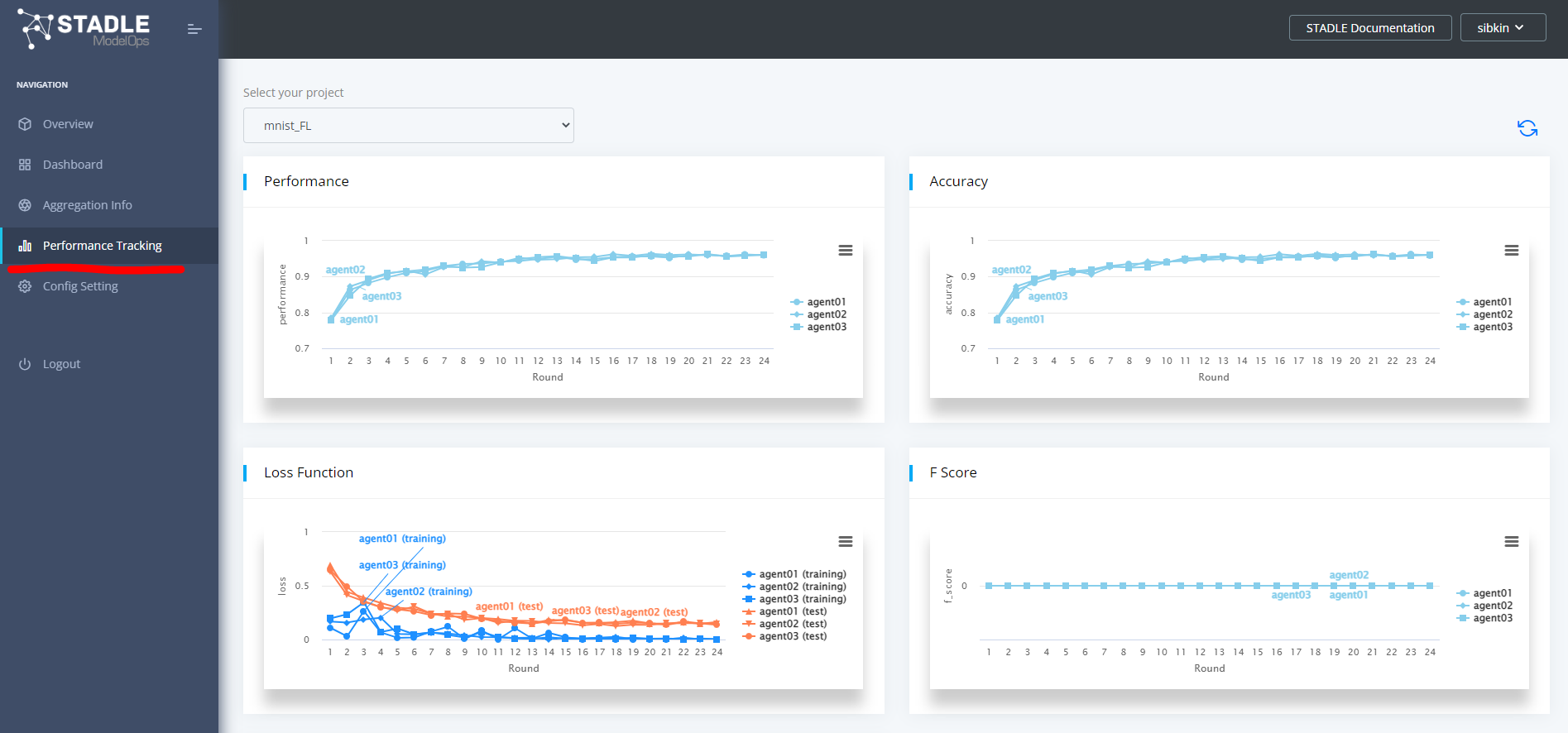
今回用意したMLアプリケーションのコードでは、各学習環境で2epochの学習が進むたびに stadle.ai に各学習環境のローカルモデルが集約されます。
それらを元に stadle.ai でセミグローバルモデルが生成されて各学習環境へ戻され、そのセミグローバルモデルをベースに、また各学習環境のデータを用いた学習が行われるというサイクルになります。
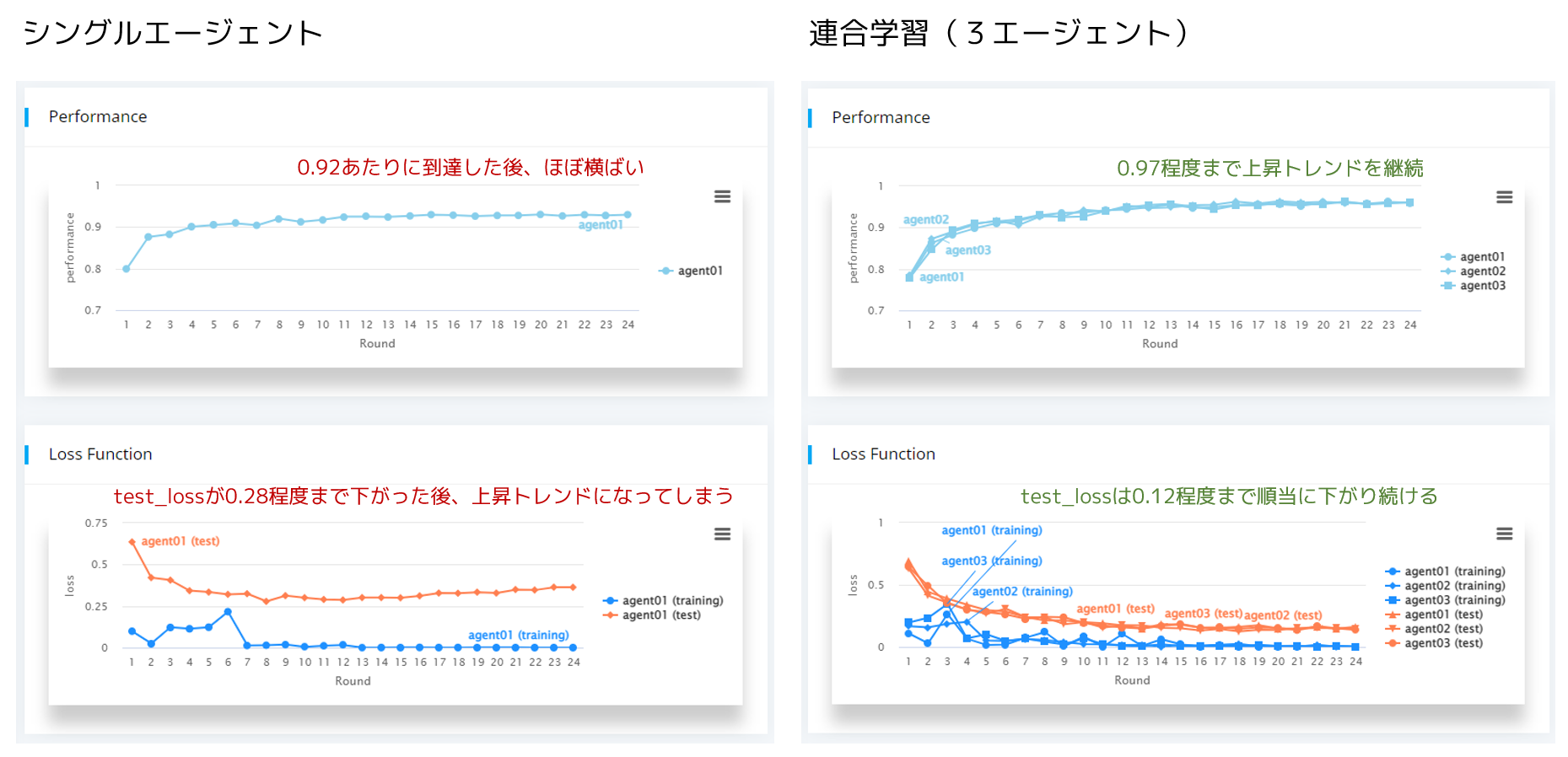
単一エージェントでの学習結果と比較
上記の連合学習の結果とシングルエージェントによる学習結果を比較してみましょう。
シングルエージェントは、先述の agent01 と同じ条件で、1/2/3のデータをフルで使用して4以降のデータに関しては5%程度とした学習を行いました。
シングルエージェントで且つ極端に偏りのあるデータでは十分に学習を進める事ができませんが、複数の学習環境にあるデータで補い合う事で正常に学習を進める事が出来ています。
他の画面での連合学習中の各操作については、リファレンス編を別途ご用意する予定です