AWS Certified Machine Learning - Specialtyを受けてきた。830点くらいで合格できた。その攻略方法を後学のためにメモ書き。
試験の流れ
制限時間は180分。出題数は65問だった。
試験のあとに10問程度のアンケートがある。
時間に関してはかなり余裕があるので心配無用。
試験を受けるために本人確認書類が必要である。運転免許証とクレジットカードでなんとかなった。運転免許証と保険証ではNGみたい。
出題されたサービス
- 超重要
- SageMaker
- S3
- Glue
- Kinesis[Stream/Firehose/Analytics]
- Athena
- Spark
- 知っておくべき
- Redshift
- EMR
- Polly,Comprehendなどの自然言語処理系のサービス
- Cloudwatch
- QuickSight
- Elastic Search
- ECR
- Storage Gateway
- 名前だけ出てきた
- Lambda
- Dynamo/Auroraなどのデータベース
試験のサンプルではAmazon Machine Learningという古めかしいサービスがやたらと参照されていたが、実際のところあまり重要ではなかった。
本当に重要なのはSageMakerなので、ドキュメントは読み込んだほうが良い。これをどこまで熟知しているかで合否が決まる。
特に重要なポイントを挙げる。
- S3との連携
- Pipeモード、RecordIO protobuf 形式
- 「S3に巨大なデータがあって、リアルタイムにトレーニングしたいんだけど〜」みたいな設定が多かった
- ステップ 2.2.3: トレーニングデータセットを変換し、Amazon S3 にアップロードする - Amazon SageMaker
- エンドポイントの負荷テスト
- ハイパーパラメータの調整
- 組み込みアルゴリズム
- ランダムカットフォレストがよく出た
Tips
機械学習の知識は基本的なところまででOK
- DeepLearningの問題が出てくるが、AlexNetやVGGなどの固有名詞は出なかった。
- seq2seqやCNNなどがわかればOK。
- 学習曲線のグラフからモデルの評価が出来るようにしておく。
- 本格的なGPUの使い方などは出なかった。インスタンスタイプ(P3とG3の違い)くらいまで。
- TP/TN/FP/FN、AUC、F1、Recall/Precision...などは簡単なので落とさない。
- DBSCAN/T-SNEくらいの用語は選択肢に出てくるので「あーあのクラスタリングのアルゴリズムね」くらいは把握しておく必要あり。
- 欠損値の埋め方(多重代入、ペアワイズ)とかカテゴリ変数の処理(One-hot/ラベル/ターゲット)なども出てくる。
試験サンプルでは不均衡データの扱いが多かったが、本番でも多少出てきた。アンダーサンプリング/オーバーサンプリング/重み付けなどでどれが適切かをきちんと選べるようにしておく。
学習/検証のerrorが乖離していく → 過学習/未学習に対する打ち手を選ばせる問題も多かった。
教師あり/教師なしがわかれば一発などの設問もあるので、ある程度詳しい人は特に対策しなくていいと思う。
性能面、セキュリティ、作業量(コード量)を考慮して回答する設問が多い
「ぱっと見では全部の選択肢で実現可能なんだけど、一番効率がいいのはどれ?」みたいな設問が多かった。これがこの認定試験の難しい&参考になるポイントなんだと思う。基本的にはAWSのベストプラクティスに書いてあるが、選択肢からなんとなく感じたコツを書いておく。
-
作業量が最も少ないものを選べ→ Glueなどのマネージドサービスを選ぶ -
大量のデータを処理したい→ SageMakerやAthenaなどの分散処理が効きそうなものを選ぶ。(結局マネージドサービスを選ぶ) -
データをインターネットに出せない→ VPCエンドポイントでS3とノートブックインスタンスを接続
迷ったら新しいサービスを選ぶ。OSSは選ばない?
選択肢の中に「EC2にOSSの〜を突っ込んで〜する」みたいなものが出てきた。これが正答になることはほぼないと思われる。
AWSも「自社のサービスを知って欲しい、使って欲しい」という目的でこの試験を作っているのだから、AWSのサービスを差し置いて「単純にOSSを使おう!」を選ばせるとは思えない。おそらくAWSのサービスが正答になるような問題を作ってくるはずである。
その他所感
- 日本語は機械的に翻訳されたなーという感じの文章。意図が汲み取れない場合は英語に切り替えることも可能なので、応募するときは日本語でいいと思う。
- 試験のサンプルと比べて、出てくるサービスが新しい。
- PollyやTranslateなどのマネージドサービスも出てくる
- セキュリティ重視
- 問題の想定シーンが割とリアル
- 新サービスを出すときに経営陣から「絶対にミスるなよ?」と言われています(どうデプロイするか?)
- 大量のデータがS3に格納されていて前処理をする必要があります。もっとも効率良い方法は?
- ヒストグラムが出てスケールを変更できるボタン?があったが押しても何も機能しなかった。1
おすすめ勉強法
AWSのこのレベルの試験は対策本や問題集がないので、ドキュメントやベストプラクティスを読み込むしかない。とはいえ、「これは効果的だったな」というものがいくつかあるので紹介する。
ブログを読め
AWSのブログは非常に参考になったのでおすすめ。
この試験は性能面やセキュリティを考慮した実戦的な設問が多いため、ドキュメントを読むだけだと「問い」と「答え」が結びつかないように思う。ブログでは「各サービスをどう連携するか?」「メリットはどこにあるか?」などを関連づけて学ぶことができるし、おそらくそれが試験の答えになるはず。
具体的なリンク先をいくつかピックアップしておく。あまりにも新しい記事は出題されないので去年くらいの記事を見ておくといいかも。
- SageMaker | Amazon Web Services ブログ
- Amazon SageMaker 推論パイプラインと Scikit-learn を使用して予測を行う前に入力データを前処理する | Amazon Web Services ブログ
- Amazon SageMaker ランダムカットフォレストアルゴリズムを使用した Amazon DynamoDB ストリームでの異常検出 | Amazon Web Services ブログ
- Amazon SageMaker Object2Vec の概要 | Amazon Web Services ブログ
SageMakerは触って覚える
SageMakerはこの試験で一番よく出てくるサービスなので実際に触っておくと問題文からイメージが湧きやすい。実際にJupyter Notebookのサンプルを動かしてみたり、推論エンドポイントを立ててみたりすると勉強が捗ると思う。
お金かけたくない!クラウド破産こわい!という人はYoutubeでもいい。
Live Coding with AWS | Training and Deploying AI with Amazon SageMaker - YouTube
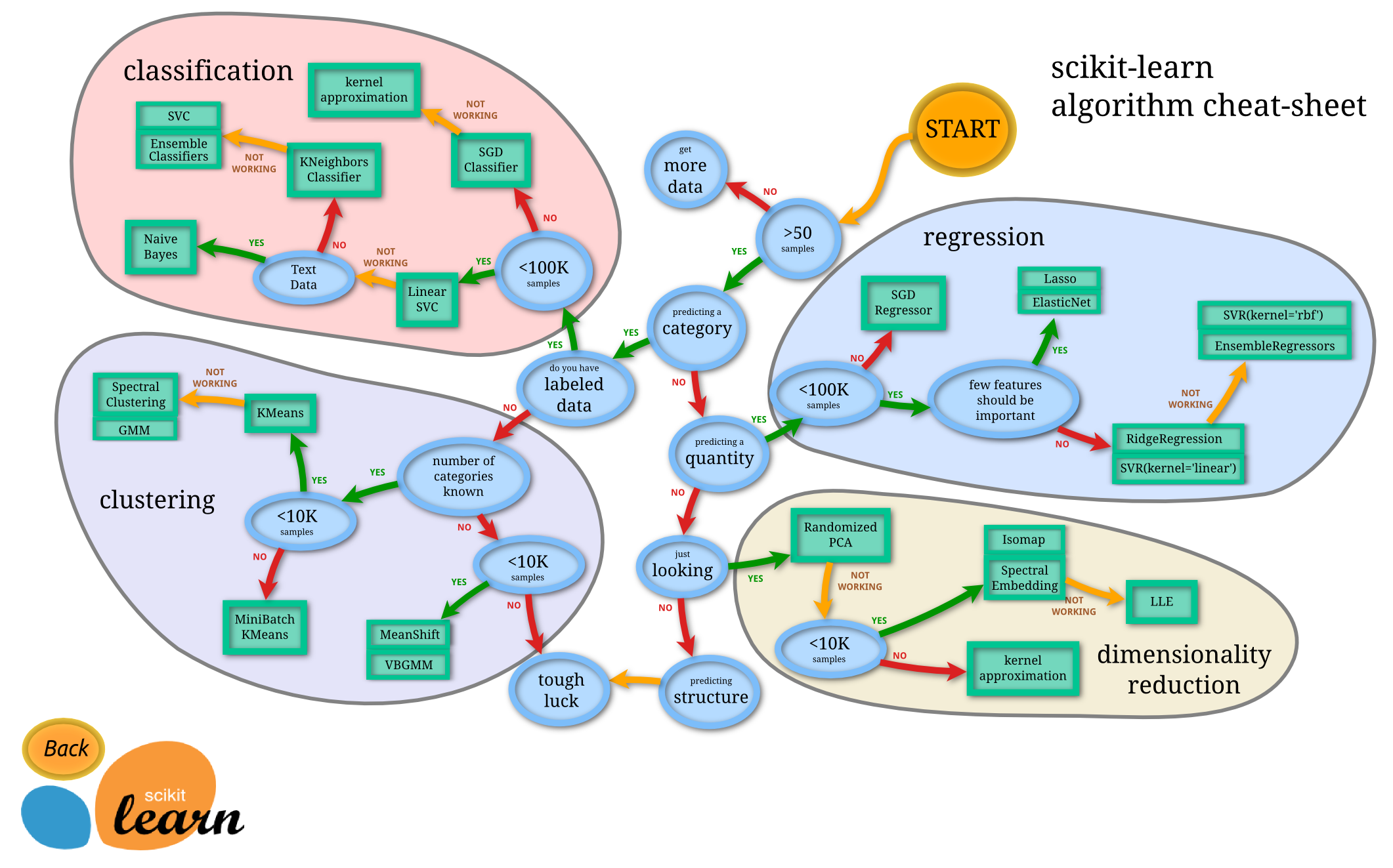
機械学習の基礎知識
広く浅い知識が求められる。適当な入門書を一冊読んでおけば十分2だと思う。scikit-learnのチートシートを見て、すんなりわかるようなら基本事項に関しては心配無用。XGBoostやDeepLearning系のアルゴリズム、SageMakerのビルトインアルゴリズムも覚えておく。