はじめに
ChatGPT、やっぱりちょっと処理が遅くて気になるときがあります。時間帯によっても遅くなったりしますし、またRAGなんかだと入力するトークンが多くても遅くなってきます。
そこでChatGPTのレスポンスをより快適にユーザに届けるために、ストリーミングは大事な要素の1つになりますが、一方で、ストリーミングだけだと、特にAzure OpenAI Serviceの場合はConent Fileterの影響でバルクが少し大きく、カクカク感が否めなかったりもしますよね。
今回は、Azure-Saples/azure-search-openai-demoで実現している素晴らしい手法に加えて、公式・非公式なTipsを含めて、ChatGPTのパフォーマンスを上げたり、少しでもユーザの待機感を減らす方法について整理してみたいと思います。
ChatGPTのパフォーマンスを上げる方法
公式のガイドでは以下の7つの方法が提示されています。
1. 最適なモデルの選択:
最新のGPT-3.5 Turboモデルシリーズが最低のレイテンシーを提供します。モデル精度との兼ね合いですが、複雑な処理が不要なものと、必要なものでモデルを使い分けるのも有効な方法です。例:検索クエリの生成はGPT-3.5 Turbo、要約処理はGPT-4 Turboなど。なるべく速いモデルを選びます。
2. 生成サイズとMax tokens:
生成するトークンの数を減らすことで、リクエストごとのレイテンシーを減らすことができます。max_tokenパラメータを可能な限り小さく設定し、不要なコンテンツの生成を防ぐためにストップシーケンスを含めます。またプロンプトを工夫して極力短い回答を作成させることも有効です。
3. ストリーミング:
stream: trueをリクエストに設定すると、全てのトークンが生成されるのを待たずに、利用可能になり次第トークンを返します。これにより、最初のレスポンスまでの時間が短縮されます。許される限り、こちらは利用すべきポイントですね。
4. コンテンツフィルタリング:
安全性を高めるためにコンテンツフィルタリングシステムがありますが、レイテンシーに影響を与える可能性があります。パフォーマンスを優先する場合は、コンテンツフィルタリングポリシーの変更を検討することができます。
5. ワークロードの分離:
異なるワークロードを同じエンドポイントで混在させるとレイテンシーに悪影響を及ぼす可能性があります。可能であれば、各ワークロードごとに別々のデプロイメントを持つことを推奨しています。
6. プロンプトサイズ:
プロンプトサイズは生成サイズほどではありませんが、レイテンシーに影響します。特にサイズが大きくなるとかなりの影響が出てきます。不要なプロンプトを少しでも減らすことでパフォーマンスが改善します(少しでも)。RAGの場合は投入するデータを要約するなどして、少なくするなども有効です。
7. バッチ処理:
複数のリクエストを同じエンドポイントに送信する場合、リクエストを単一の呼び出しにバッチ処理することで、全体の応答時間を改善する可能性があります。並列処理をする場合は逆にばらした方がいいケースもあります。
====ここまでが、公式のTipsです。それぞれどこまでできるか、っていう観点もありますが、これに加えて以下の要素もあるかと思います。
+8. マルチリージョン呼び出し:
並列で複数リージョンに問い合わせし、最も早く返ってきた回答を利用する方法です。複数呼び出しをするため、コストが増加しますが少しでも早いレスポンスが必要な場合、検討の余地があります。特にモデルのおかれたリージョンの日中はレスポンスが遅くなったりということは多々ありますので、複数リージョン呼び出しはコストは増えますが有効な方法です。参考サイト
+9. PTUの利用:
Azure OpenAI Service ではプロビジョニングスループットと呼ばれる占有プランがあります。こちらもコストとの兼ね合い次第では検討の余地はあります。特に複数ワークロードをまとめて全体的な改善につながりやすいです。(コストはかかりますが、待機時間がほぼ無くなるので劇的な改善につながりやすいです)
ChatGPTの待機感を減らす方法
また上記以外にもパフォーマンスを直接改善するのではなく、ユーザ側の待機感を少なくする方法として以下の方法もあります。
+10. ストリーミングの出力平滑化:
Azure-Saples/azure-search-openai-demoで実現している素晴らしい手法です。ストリーミングで取得したデータを少しずつ出力させることでユーザの待機感を減らす方法です。以下はSvelteでの実装イメージです。contentにはストリーミングで取得したデータを入れます。なお、ReactでしたらAzure-Saples/azure-search-openai-demoを確認してください。
async function delayOutputNewContent(content) {
await new Promise(resolve => setTimeout(() => {
displayedAdvice += content;
resolve(null);
}, 33));
}
+11. ローディングマーク:
どうしても出力が遅い場合に少しでも待機感を減らす方法です。くるくるマークなんかです。やっぱり完全に止まっている状況はストレスになりますので。また+10.の手法と組み合わせて、回答が完全に終えるまでのローディングと、1文字ずつ出力している間のローディングマークを切り替えることで、さらにストレスを減らすことができます。(少しですが)
{#if isStreaming && isWriting}
<span class="streaming_fast"></span>
{:else if isStreaming && !isWriting}
<span class="streaming"></span>
{:else if !isStreaming && isWriting}
<span class="streaming_fast"></span>
{/if}
+10と+11を組み合わせた動作イメージは以下です。(内容は適当です。)

さらにRAGの場合は、全体のトークンを分割して並列に処理する方法も、要件次第では検討可能です。(一種のワークロード分割ではありそうです。)
+12. 検索型RAG:
検索したデータを全部まとめて処理をするのはやはり時間がかかりますので、検索データを個別にGPT処理させる方法です。参考サイトで解説していますが、動作イメージは以下となります。
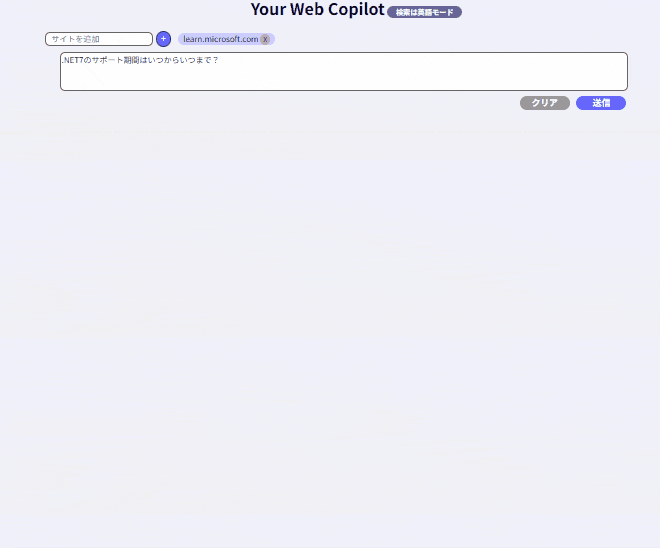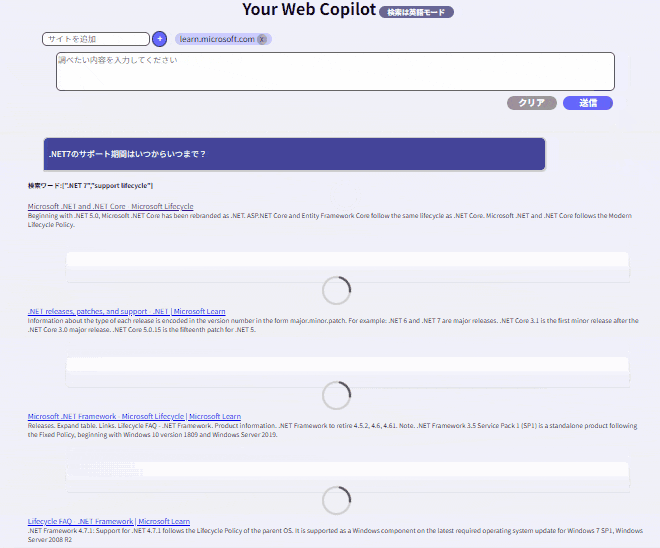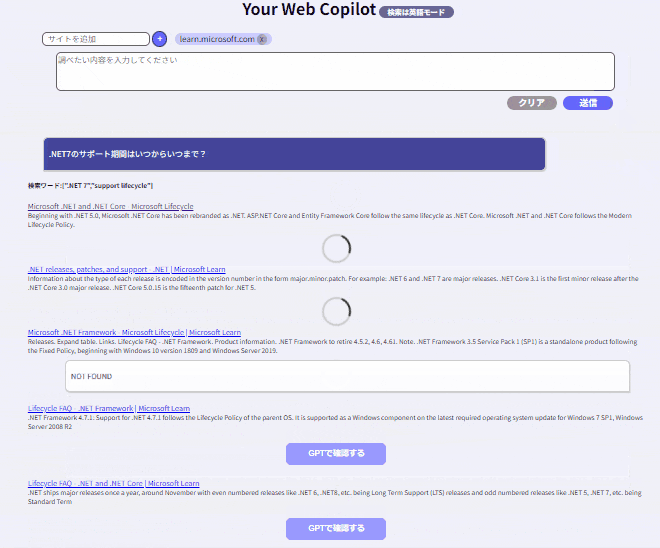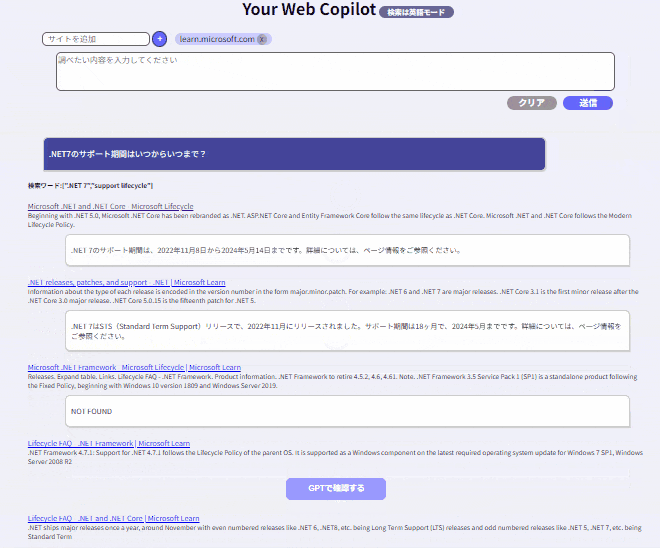
おわりに
公式、非公式含めてとりあえずパフォーマンスを改善する、待機感を軽減する方法をまとめてみました。要件によっては使えるもの、使えないものもあるかもしれませんが、いずれも検討すべき項目かなと思います。
もし抜けているものや、もっといい方法など、何かあればぜひコメントなどでご教示ください。