RAGシステムの魅力と課題
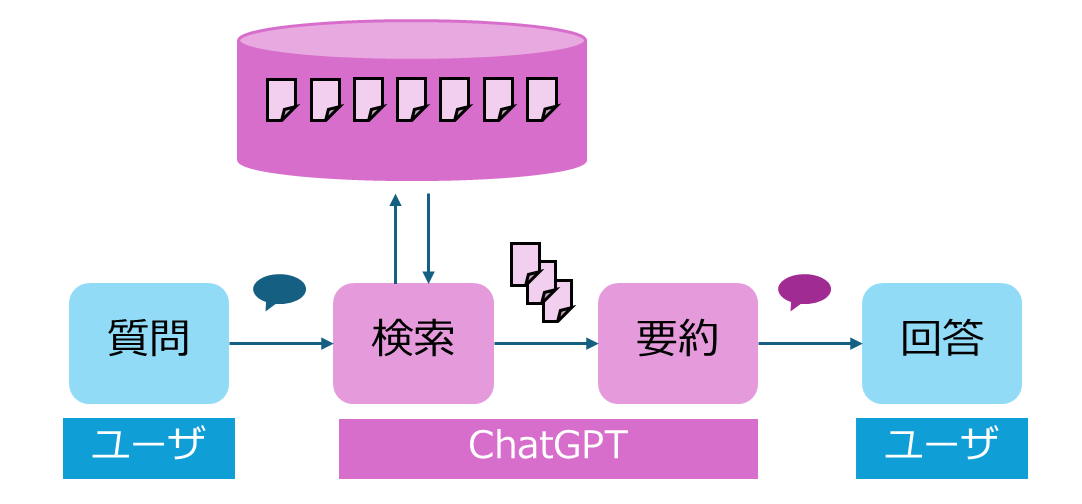
ChatGPTを活用したシステム設計において、Retrieval-Augmented Generation(RAG)は、その柔軟性とパワーで一般的なシナリオになっているかと思います。やっぱり、素のChatGPTだけでは物足りなさを感じますよね。(下図参照)
一方で、検索精度が低いために回答が不十分だったり、欲しい情報が検索結果に埋もれてしまったりすることもあります。また、時には単純な検索だけで充分な場合もあるのではないでしょうか。
この記事では、求める情報のタイプに応じたRAGシステムのパターンについて、整理紹介していきます。
顧客が本当に必要だったもの
私自身、RAGを利用している際、検索元のドキュメントを最終的に自分の目で確認しなければならないことがしばしばあります。このような場合、満足感を得られていないことが多いのですが、皆さんはどうでしょうか?RAGの回答に対して、どのような時に満足し、どのような時に満足できていないでしょうか?
RAGシステムを構築・利用してきた経験から、私は大きく2つのパターンに分けられると考えています。もちろん、これに異論がある方や、他のパターンをお持ちの方もいらっしゃるかもしれません。ぜひコメントでご意見をお聞かせください。
-
回答型RAG
- 情報を参照して要約した回答を求める場合
-
検索型RAG
- 根本的には検索結果そのものを求める場合
将来的には、言語モデルの進化や検索技術の向上により、これらのカテゴリーを分ける必要がなくなるかもしれません。しかし、現時点では、少なくとも今後1年間はこれらを別々に考えることに意味があると感じています。
それでは、それぞれのタイプについて詳しく説明し、処理フローについても触れていきます。
(1) 回答型RAG
回答型RAGは、ユーザーが求める回答を提供することを目的としています。検索元を見ることはあっても、基本的には回答を受け入れるパターンです。例えば、概要が知りたいとか、コードが欲しいとかですね。現行のRAGシステムの多くがこのパターンに該当するかなと思います。
- プログラムコードなど、回答を元に検証できるので、間違っていても修正できる
- ある程度知識があって、ユーザ側で回答が正しいか判断できる
- あくまで土台的な情報が欲しいのであって、正確性はそこまで求めていない
このような場合、回答型RAGは非常に有用です。ユーザーは時折、提供された情報の出典を確認するかもしれませんが、主には提供された回答に満足することが多いのではないでしょうか。以下に、このタイプのRAGの一般的な実装フローを示します。

動作イメージはこんな感じです。極めて一般的なRAGですね。(画像はCopilot利用時)
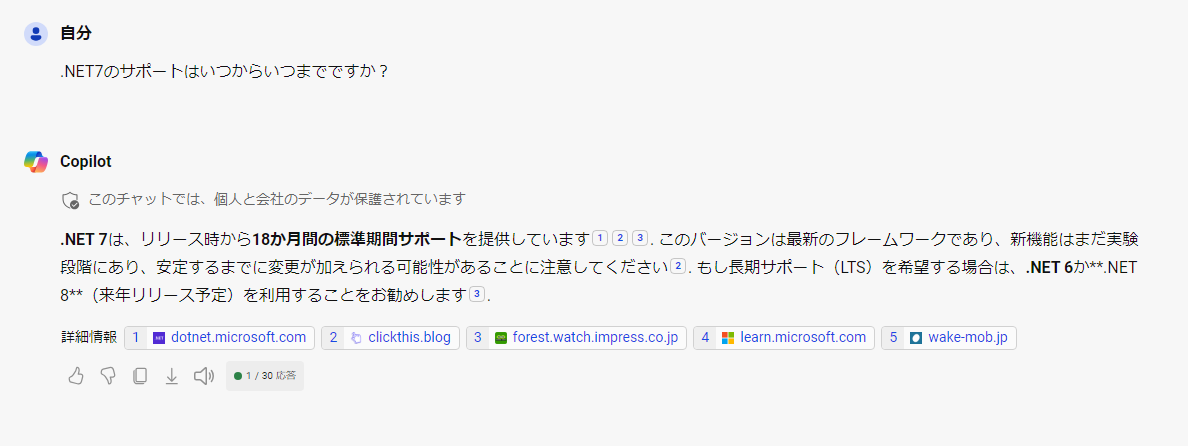
で、この回答を見て満足できればいいですし、必要に応じて詳細情報のリンク先を見てもよいっていうやつですね。
(しかし私はこの回答に満足できない…)
(2) 検索型RAG
情報の正確性が特に重要視される場面では、検索型RAGの利用が非常に有効なパターンとなります。例えば、マニュアルや技術文書などの情報の正確さが求められる状況で、RAGの回答をそのまま受け入れるのではなく、検索元を確認することがほぼ必須となるようなケースです。
検索型RAGは、以下のようなシナリオで特に役立ちます:
- 技術文書など、回答の正確性が極めて重要な場合
- 誤情報(ハルシネーション)が許されない状況で、検索元の確認が必要な場合
- ユーザが最終的に求める情報を、元の情報源を基に自ら確認する必要がある場合
- ユーザはある程度答えの存在を知っており、その確認がしたい
いずれ言語モデルの出力精度や、検索エンジンの検索精度が十分に上がっていけば、最終的には検索型RAGはすべからく回答型RAGで十分になっていくのだとは思っています。なので、モデルや技術の精度に不満がある現状のための過渡期のパターンかもしれませんが、現状検索に特化した形のRAGは実用性がありそうです。
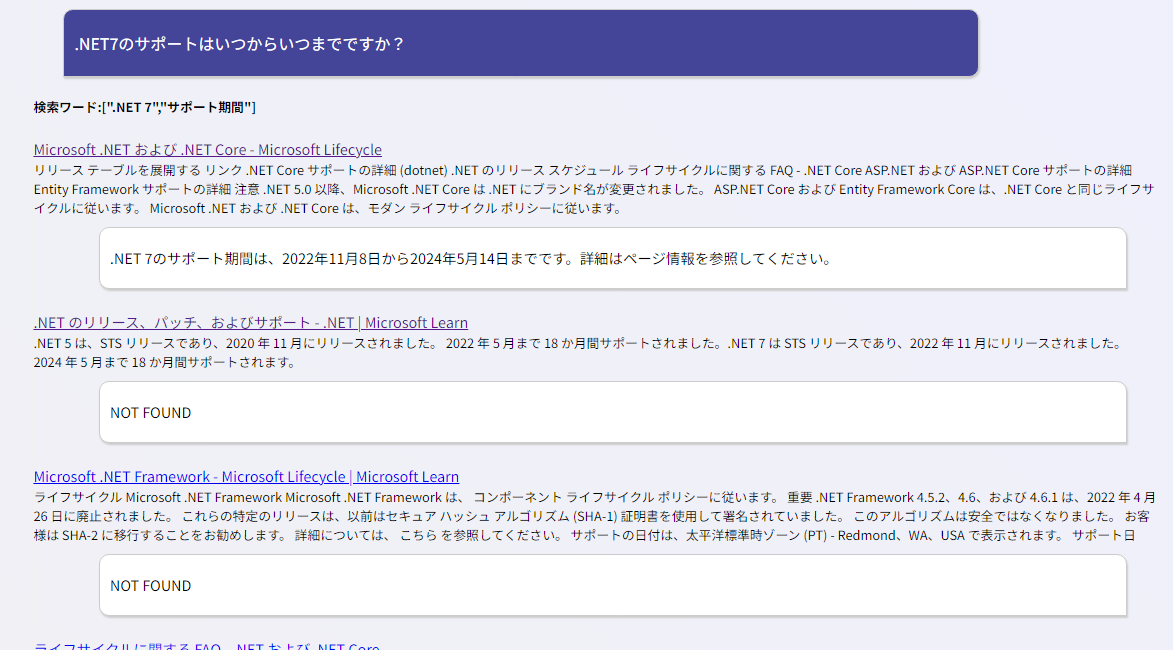
以下に、この検索型RAGの実装フローを示します。

動作イメージはこんな感じです。検索結果の上位x件を並べてそれぞれについてユーザからの質問に回答する感じです。(関係ない情報であればNOT FOUNDとしてます)
この例だと、一番上のリンクを見れば、公式サイトの情報をしっかり確認できるというわけです。
さらに嬉しいことに、この処理パターンだと検索結果を一度ユーザに返すことができ、さらにx件の要約は非同期で並列に処理が実行可能です。ので、画面上はすぐに検索結果が一度返ってきてから並列にChatGPTのストリーム処理をするなんてことが可能です。(体感ちょっぱやになります)
シーケンス的にはこんな感じです。

結局どっちがいいの?
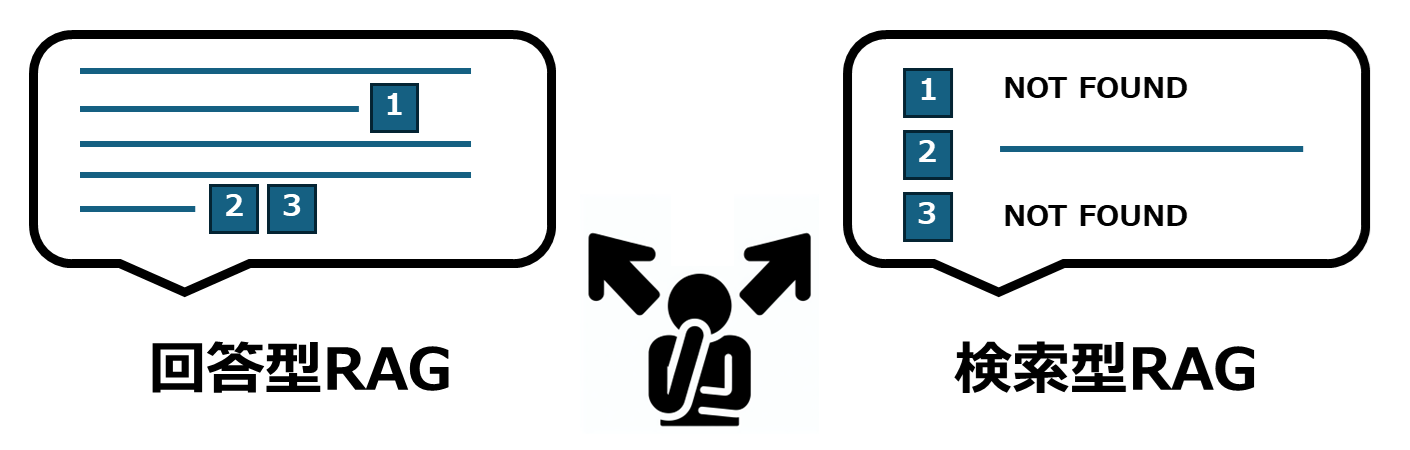
回答型RAGは、検索精度が高く、引用を含めた正確な回答を返せる場合に非常に有効です。多くのシナリオでは、このタイプが十分な性能を発揮します。一方で、以下の回答型RAGのネガティブケースと検索型RAGのポジティブケースに該当する場合は、検索型RAGが良いシナリオがあります。
【回答型RAGのネガティブケース】
- 検索精度が高くない
- 引用付きの回答がうまく生成できない
- スピードが遅い(RAGに取り込むデータ量が多くなると遅くなるため)
- 回答がどうあれ引用元の資料の確認が必須
【検索型RAGのポジティブケース】
- 引用先の文章の確認が絶対に必須
- 少しでも早いレスポンスが欲しい
- ある程度答えの概要は把握しており、最終的な確認をしたい
なお、検索型RAGは処理ごとにシステムプロンプトが追加されるため、トークン数が増加し、結果としてコストが若干高くなる可能性があります。しかし、実際のトークン数の増加はそれほど大きな影響を与えないことが多いです。例えば、検索結果が2件でトークン数がそれぞれ1000と2000、システムプロンプトが200トークンの場合、回答型RAGではトークン数が3200になりますが、検索型RAGでは3400になります。この差は小さく、実際にはリクエスト数の方がコストに大きな影響を与えることが予想されます。実際のシステム構築時には、これらの要素を検証検討する必要があります。
まとめ
この記事では、RAGシステムについて、回答型RAGと検索型RAGの2つのパターンについて紹介しました。一般的には、回答型RAGが主流であり、多くの場面でその価値を発揮しています。しかし、技術文書や公式情報を扱う際には、検索型RAGの方が適している場面も少なからずあるのではないでしょうか。
特に、回答型RAGの速度や回答の質に不満を感じている方にとって、検索型RAGは新たな選択肢となり得ます。検索型RAGの具体的な実装コードについては、今後どこかで公開予定しようと考えていますので、その際は改めて解説記事を投稿します。
検索型RAGの最大の魅力は、単なる検索を超え、必要な情報がどの文献に含まれているかを即座に特定できる点にあります。回答型RAGに対する不満から検索エンジンの根本的なチューニングやデータの再整理を考えている方には、ぜひ検索型RAGのパターンも検討してみてもらえたらなと思います。