はじめに
この記事はUiPathブログ発信チャレンジ2022サマーの4日目の記事です。
昨日は@RPA_Journeyさんの記事、明日は@masatomixさんの記事です。
AI Centerでプリセットされている機械学習モデル「物体検出(Object Detection)」を深堀りしてみます。
AI Centerの大まかな使い方は以下の記事で説明しています。
つかうもの
※クラウド環境は2022年6月時点のもの
- Automation Cloud(AI Center) Enterprise版
モデルの概要
物体検出とは、深層学習(ディープラーニング)を使用したデジタル画像内に映っている特定のクラス(人間、建物、車といったカテゴリ)の物体を検出するモデルです。
AI Centerで用意されているものは、YOLO v3を使ったモデルです。GPUはサポートさせていません。
COCOデータセットを使って事前学習がされているので、以下の80個のクラスであれば、再トレーニングをしなくても検出することが可能です。
一覧にないクラスを検出するのであれば、自分でデータセットを準備し、再トレーニングします。
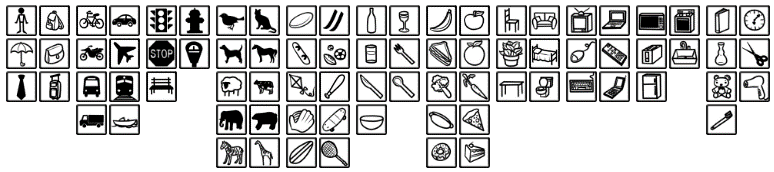
| 事前学習済みのクラス |
|---|
| person, backpack, umbrella, handbag, tie, suitcase |
| bicycle, car, motorcycle, airplane, bus, train, truck, boat |
| traffic light, fire hydrant, stop sign, parking meter, bench |
| bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe |
| frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket |
| banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake |
| chair, couch, potted plant, bed, dining table, toilet |
| tv, laptop, mouse, remote, keyboard, cell phone |
| microwave, oven, toaster, sink, refrigerator |
| book, clock, vase, scissors, teddy bear, hair drier, toothbrush |
データセット
再トレーニングするためのデータは、PASCAL VOCという形式に準拠したセットを用意する必要があります。
- 画像ファイル(.jpgまたは.pjeg)とアノテーションファイル(.xml)の1対1で用意する
- 画像ファイルとアノテーションファイルのファイル名は同じにする
- 画像ファイルは同じサイズに統一する(推奨 800*600)


用意するデータセットの目安です(あくまで参考です)。
- 最低限のレベルは、1クラスに対して、100枚程度
- 標準的なレベルで、1クラスに対して、500~1,000枚程度
- 高精度(似た物体を分けて認識するなど)なレベルで、1クラスに対して、5,000枚以上
データ準備とラベリング作業は、かなり大変です。
アノテーションファイルを手作業で作成するのは、コスト的に現実的ではないので、何かしらのツールを使います。
オープンデータセットを活用する手もあります(ものによっては、PASCAL VOCでダウンロード可能です)。
パイプライン
フルパイプライン(トレーニング+評価)のみサポートされています。
実行時に指定できる環境変数(ハイパーパラメータ)は、以下の通りです。
- learning_rate:学習率(ディープラーニングを実行する際、勾配をどれくらい変化させるかを示したもの)。デフォルトは、0.0001。
フルパイプラインの実行時間は、経験上、250件程度のデータセットを用意して、6時間半くらいかかりました(あくまで参考です)。
実行結果
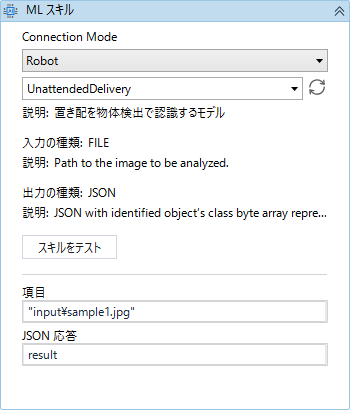
入力は、画像ファイルのパスです(String型)。
出力は、検出したクラスとスコアを含むJSONです(String型)。
スコアは、0~1の間の数値で、1に近いほど信頼できる予測となります。
検出した物体の座標値は出力されないので、これらが欲しい場合は、Pythonのコードを修正する必要がありそうです(試したことはありません)。
{
"Predicted Class ": "[
{'class': 'package', 'score': ' 0.93'}
]",
"Predicted ByteArray": "..."
}
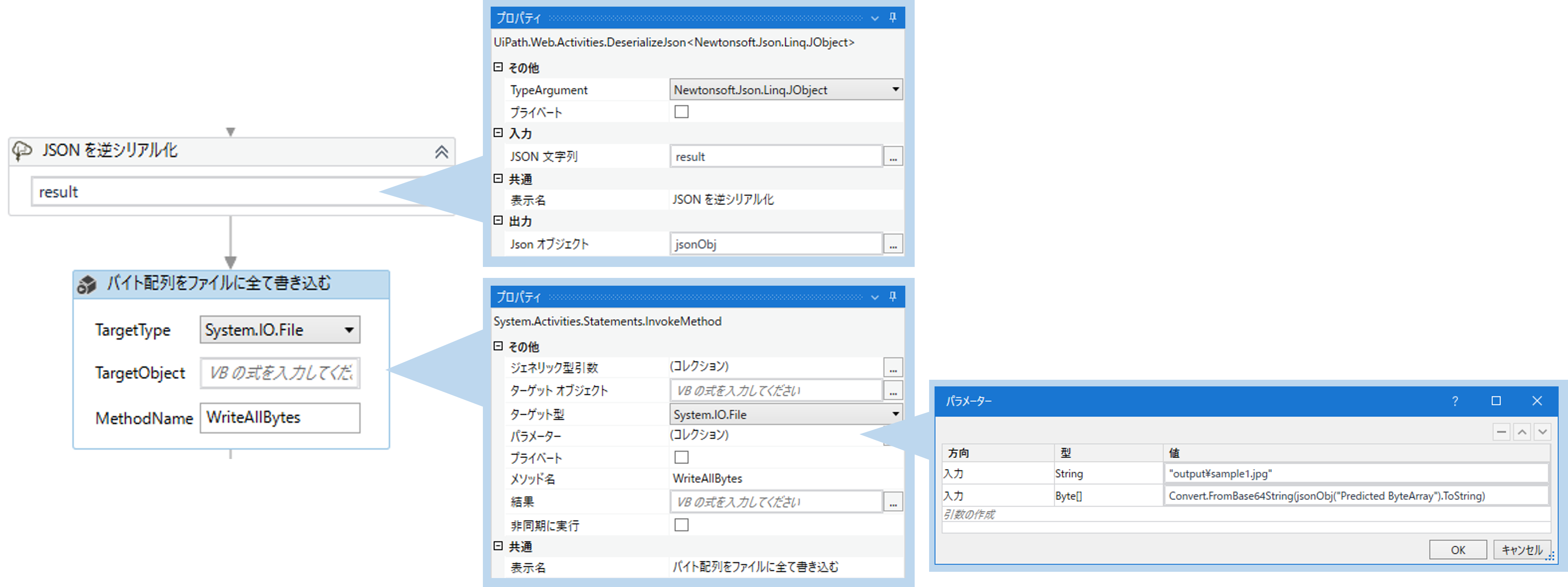
「Predicted ByteArray」はエンコードされた画像データです。以下の処理で画像ファイルに戻すことができます。

おわりに
実際の業務で使用する場合は、COCOデータセットではなく、業務データを使って再学習するケースがほとんどかと思います。
物体検出モデルはよく使用されるモデルなので、使い方を覚えておいて損はないかと思います。
機会があれば、他のモデルも試したいと思います。
参考