BERTとは?
BERT (Bidirectional Encoder Representation From Transformer) は、2008年にGoogleが開発した自然言語処理モデルです。Googleの発表によると、BERTは近年発表された探索アルゴリズムの中でも最も画期的で優れた精度を担保しており、Googleの検索機能を飛躍的に向上させたそうです。BERTの登場により、人間が入力した複雑な文章でも、機械が理解し、適切な回答を返すことが可能となりました。
実際 Google が発表した資料[1]では、下の図の様に、"Can you get medicine for someone pharmacy" :「薬局で誰か他の人の薬をもらうことは可能か?」という質問に対し、 以前のGoogle検索だと左下の様に、「処方箋のもらい方」を示したページがトップにきてしまっていました。しかし、BERTを利用すると右下の様に、「処方薬を患者の家族や友達が代わりに受けてとることは可能か」というページがヒットしました。この様に、BERTは、複雑な文章のパターンでも適切にプロセスでき、様々な場面での応用が期待されています。
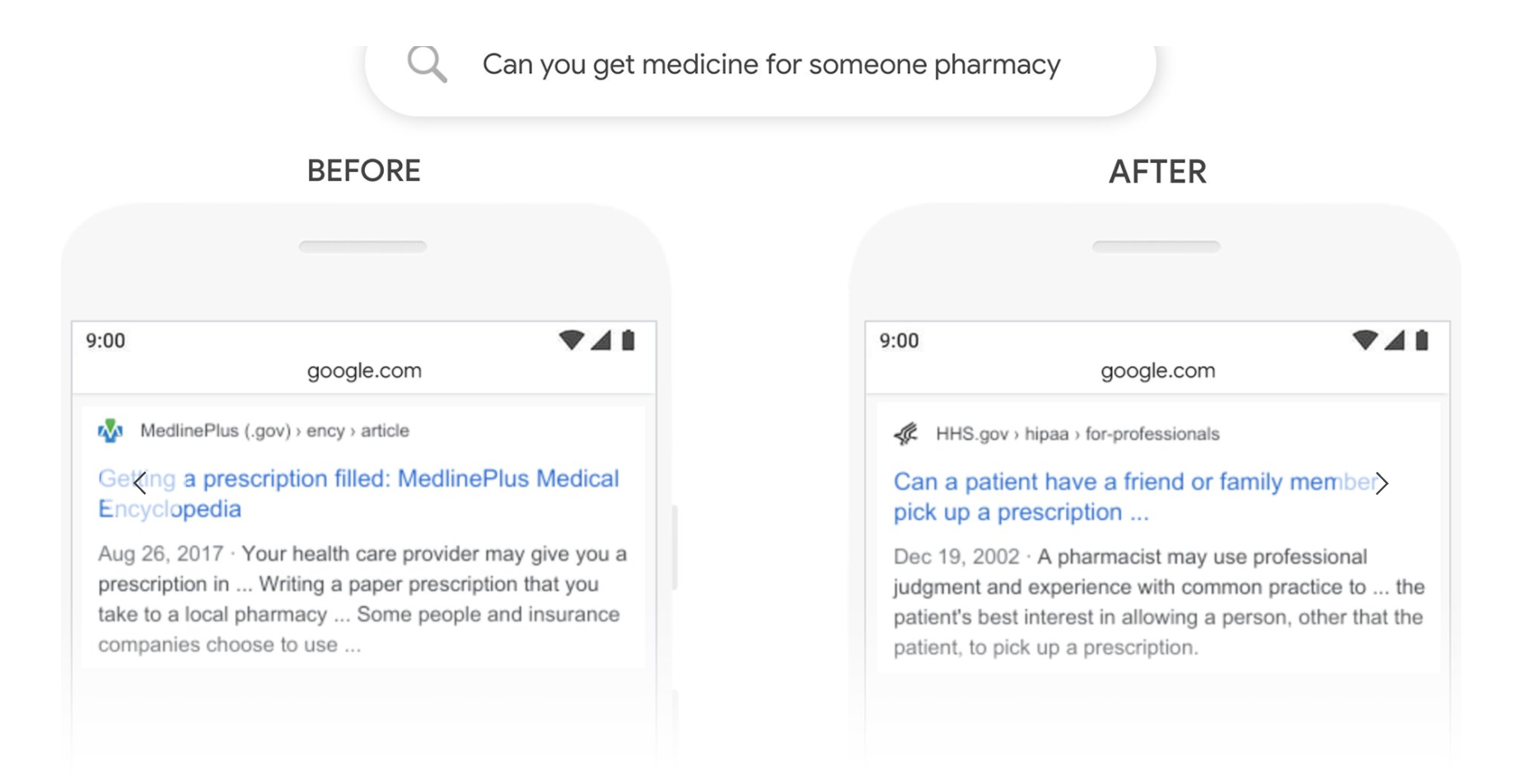 参照: Pandu Nayak, Google, "Understanding searches better than ever before"
参照: Pandu Nayak, Google, "Understanding searches better than ever before"
BERT の仕組み
ここではBERTの仕組みを簡単に説明したいと思います。
Bidirectional
自然言語処理の機械学習で代表的なモデルにRNN (Recurrent Neural Network)があります。RNNは、CNNなどのNNと違い、入出力データの長さが決まってくてもモデルを構築することが可能です。ただ、RNNの問題として、文章が長くなればなるほど、文脈を理解する精度が落ちるということです。RNNは、文章を左から右に向かうシーケンスとして処理していきます。しかし、下の様な文章があったとします。
??> に入る言葉が何かを推測するとします。この時、左から右に単語を辿っていくよりも、右から左に単語を辿り、推測する方が簡単なのは一目瞭然です。その為、BERTでは、**Bidirectional** 、つまり両方向に伝達するRNNの層により構成されています。"Japan ??> the game against England. "
Attention
目の前に世界地図が広げられているとします。そこから、サンパウロを探してください。というお題が課せられたとします。皆さんならどのようなアプローチをとるでしょうか。勿論、地図の端から順に探していけばいずれサンパウロに辿り着くでしょう。しかし、それでは膨大な手間と時間が必要となります。なので、多くの人はおそらく、範囲をブラジル、あるいはその近辺に絞って探すのではないでしょうか。BERTでも同じように、探索の対象となる語に関連した範囲を予め絞って処理を行います。BERTでは、この関連する語やものを Attention といいます。
下の例文を使って、Attentionの計算方法を簡単に説明します。
"I saw a Japanese man walking down the street when I was heading to a Japanese restaurant."
(1) まず文を単語ごとに区切ります。
I saw a Japanese man walking down the street when I was heading to a Japanese restaurant.
(2) 一つ一つの単語をベクトルに直します。また、このベクトルをKey (キー) と呼びます。これにより、違う意味をもつ同じ語(ここでいう2つのJapaneseのように)が存在しても、別の単語として処理することができます。
(3) 各キーと、目的の単語 Query (クエリ) の関連度を計算し、関連が低いものは消します。例えば、1つ目の "Japanese" をクエリとした時、
I saw a Japanese man walking down the street when I was heading to a Japanese restaurant.
というように、不要なワード以外を Attention として残します。
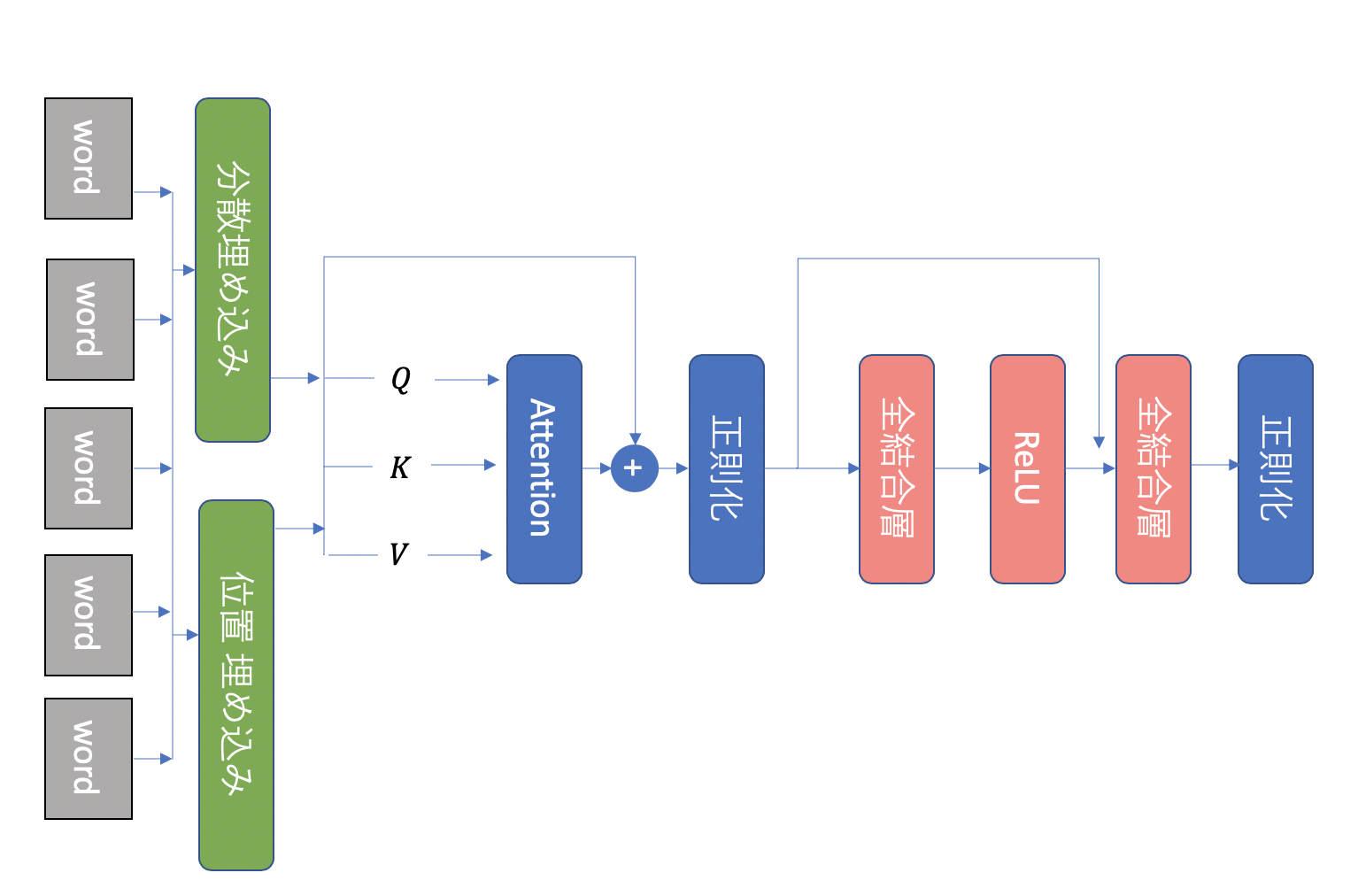
Encoder
実際のネットワークでは、まず単語のシークエンスをonehot encodeでベクトル化し、予め構築された分散埋め込み層と、単語の位置情報をいれる位置埋め込み層(Positional Embedding)を通して、クエリQ、 キー K と 実際の値 V に分けられます。ここで、分散埋め込みだけだと、単語自体の相対的な意味合いはわかりますが、文中で相対的にどの位置で使われているかはわかりません。なので、位置埋め込みを通し位置情報を入力値に含める必要があります。[2]そして、Q, K, Vが Attention層に入力されます。Attention層から出力された値は正則化され、全結合層を通り、ReLU活性化関数に渡されます。そして、再び全結合層を通り正則化され、ベクトル h として出力されます。これがBERTのTransformer Encoderです。
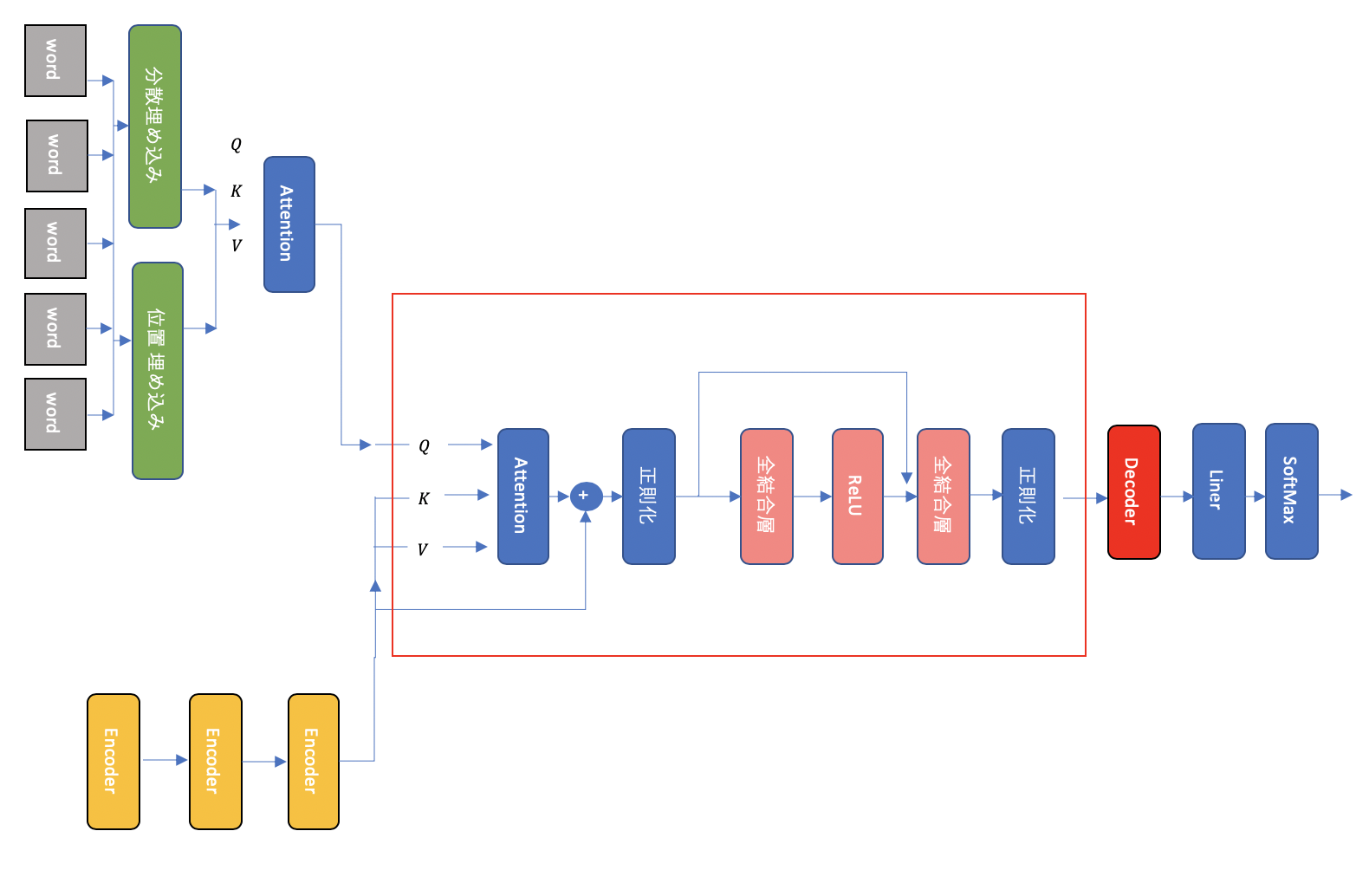
Decoder
Encoderにより作られたベクトル h は decoderで学習データにfitされます。下の図の赤枠が1つのdecoderを表しています。まず h により key K と Value V が計算されます。 Q には one-hot encoding と埋め込みを通った真の値が入力されます。そして、正則化 -> 全結合層 -> 活性化関数 -> 全結合層 -> 正則化を通り、ベクトルを出力します。出力値は、残りのdecoderを通り、linear 層 と softmax 層を通って、最終的なアウトプットを輩出します。
学習
BERTでは、モデル構築の際、メインの学習の前に事前学習(Pre-training)というフェーズがあります。このフェーズでは、**Masked LM (Masked Language Model)**という、一部の単語を隠してそこに何が入るか当てるタスクと、NSP (Next Sentence Prediction) という2つの文章を比べて、連続している文章かどうかどうかを当てるタスクを通し学習を進めます。
メインの学習では、先ほどの decoder と事前学習で得られた結果を使って、モデルをフィットさせます。
ソースコード
ソースコードはこちらにGoogleにより公開されています[3]。
参照
[1] Pandu Nayak, Google, Oct 25, 2019, "Understanding searches better than ever before", https://www.blog.google/products/search/search-language-understanding-bert/
[2] Peter Shaw,Jakob Uszkoreit,Ashish Vaswani Google, 12 Apr 2018, "Self-Attention with Relative Position Representations"
[3] https://github.com/google-research/bert/