和田卓人(t-wada)さんの講演が非常に参考になったのでまとめてみた
youtube
https://youtu.be/ueqjypYJnxk?si=voAg4h6R3e2nMpND
スライド
https://speakerdeck.com/twada/automated-test-knowledge-from-savanna-202406-findy-dev-prod-con-edition
なぜ自動テストを書くのか?
❌ コスト削減をするため(ありがちな誤解)
コスト削減を目的にすると大抵期待通りの結果を得られない。短期的には自動テストの学習コスト、中長期的にはテストコードの保守コストがかかる。思ったようなコスト削減効果が得られず、手動テストに戻るという判断をしてしまいがち。
🔺 今回作った機能にバグがないことを証明するため、品質保証のため(間違いではないが芯を食ってない)
⭕️ 機敏性、変更容易性を確保するため
「素早く躊躇なく変化し続ける力」を得るために自動テストを書く必要がある。
アジャイル開発に代表される現代のソフトウェア開発は継続的成長、継続的改善(新規機能追加、リファクタリングなど)が大前提。その際に既存の機能にデグレを起こしていないことを根拠をもって確認しながら進みたい。なので自動テストが必要。
自動テストの目的
信頼性の高い実行結果に短い時間で到達する状態を保つことで、開発者に根拠ある自信を与え、ソフトウェアの成長を持続可能にすること
以下に分解して記載していく
- 信頼性の高い
- 実行結果に
- 短い時間で到達する
- 状態を保つ
「信頼性の高い」
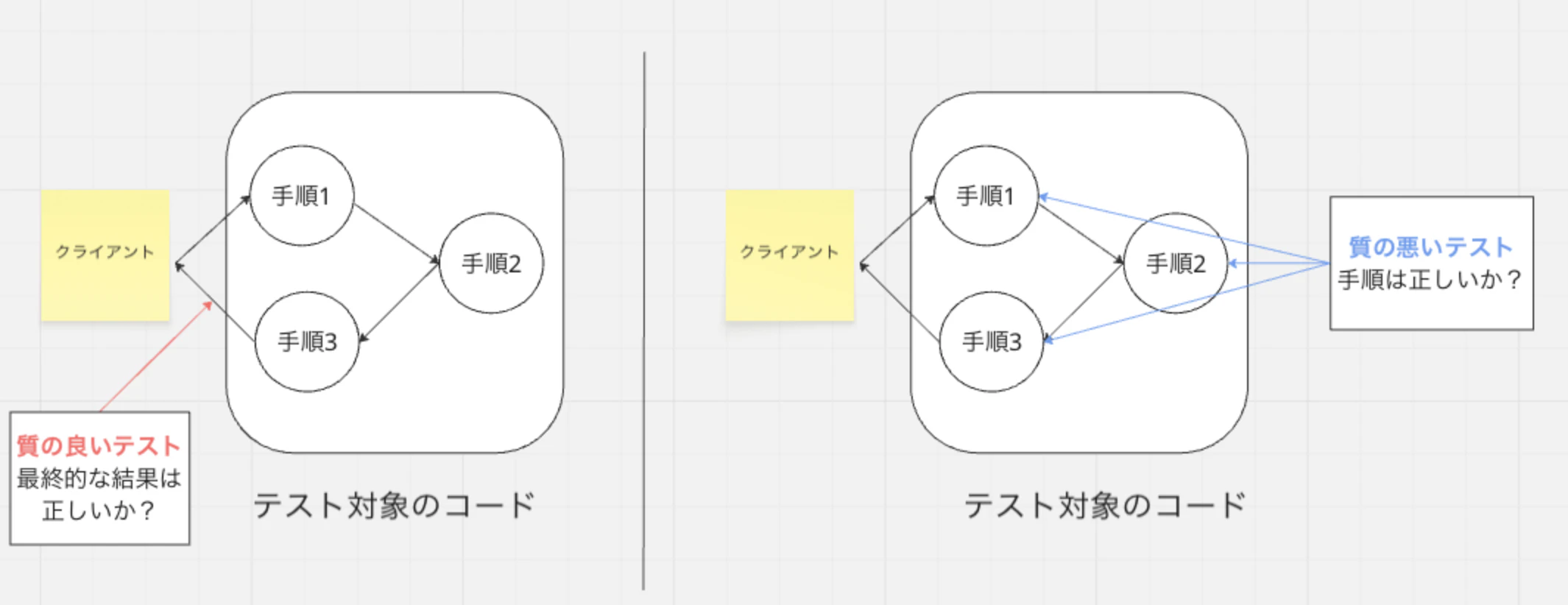
信頼性の高いテストとは?
→合格したソフトウェアであればリリース可能、不合格であれば重大な不具合がある、とチームが確信できるようなテスト
つまりテストの結果に嘘がないこと
テストの結果に嘘があるとはどういうことか?
→ 誤検知(偽陽性) と 見逃し(偽陰性)

以下、偽陽性と偽陰性のパターン
偽陽性
- 信頼不能テスト(flaky test)
- 脆いテスト(fragile test)
偽陰性
- 空振り
- カバレッジ不足、テスト不足
- 自作自演
偽陽性のパターン
信頼不能テスト(flaky test)
本番コード、テストコードに一切手を入れていないにもかかわらず成功したり失敗したり結果が変わってしまうテスト(非同期処理を含むテスト、ネットワーク発生するテスト等でなりやすい)
信頼不能性が1%に近づくと、狼少年的に信じられなくなっていく
「失敗してもリトライすればいいよ」とテストの意味がなくなっていく
→対策:不安定なものは隔離しておく。テストに「flaky」タグをつけるなど
脆いテスト(fragile test)
触っただけですぐ壊れるテスト
内部構造や処理手順に着目したテスト(実装に対する結合度が高すぎるテスト)を書いていると、リファクタリングしただけでテストが失敗してしまう。外部からみた振る舞いは変わっていないのにテストが壊れてしまう。
偽陰性のパターン
空振り
テスト動かしているつもりがテスト動いてませんでした
カバレッジ不足、テスト不足
カバレッジ不足は書かれているコードに対して書くべきテストケースが足りていない状態。
テスト不足はそもそも要求仕様に対して書かれるべきコードが書かれていない、なのでテストも書かれていない状態。人間の認識不足。
自作自演
テストになっていそうでなっていないパターン。テストコードと本番コードで同じ計算式を使っている(テスト対象ロジックのテストコードへの漏れ出し)など
例↓
プロダクトコード
class Item {
// コンストラクタ割愛
tax_amount() {
const rate = (this.tax_rate / 100);
return (this.price / (1 + rate)) * rate;//1円未満の端数が発生するバグがある
}
}
💬 1円未満の端数が発生するバグがある
テストコード
it('税込価格から税額を返す', () => {
const item = new Item('技評茶', 130, 8);
const expected = (130 / (1 + (8 / 100))) * (8 / 100);
assert.equal(item.tax_amount(), expected);
});
💬 テストコードの方も同じロジックで期待値を計算しているので、バグがあるのにテストが成功してしまう
「実行結果に」
テストの実行結果は情報であり、意思決定と行動につながることが大切。
つまり信号機の「緑」と「赤」の役割のように、「緑」なら前に進む、「赤」なら停止という判断ができるテストになってないといけない。
偽陽性と偽陰性がなくなれば、このような状態になる(テストの実行結果を疑わなくて良い理想の状態)

またテストが失敗した時には、なるべく何が、どこで、どのように失敗したかわかるような(問題の特定と修復に繋げられるような)テストにしておくことが大切
ダメな例:論理式でassertionを書いてしまう
@Test
void 税込価格を税率ごとに区分して合計した金額に対して税額を計算し端数は切り捨てること() {
var inv = createSimplifiedInvoice();
// 中略
var tax = inv.tax();
assertTrue(tax.reduced() == 40); // 単なる論理式では(工夫しないと)失敗時の情報が欠落する
}
org.opentest4j.AssertionFailedError: expected: <true> but was: <false>
期待通りだったか否かの情報しかかえって来ず失敗時の情報が欠落している。
何が、どこで、どのように失敗したかわからない。問題の特定と修復に繋げられない。
良い例:比較のためのアサーション
@Test
void 税込価格を税率ごとに区分して合計した金額に対して税額を計算し端数は切り捨てること() {
var inv = createSimplifiedInvoice();
// 中略
var tax = inv.tax();
assertEquals(40, tax.reduced()); // 比較のためのアサーションに変更
}
org.opentest4j.AssertionFailedError: expected: <40> but was: <39>
40を期待していたが、39で返ってきているので「1円ずれているから端数の計算のところで問題があるのかな?」と問題箇所の推測がしやすい。仮に0で返ってきたならばもっと根本的なところに問題がある、といったようにテスト失敗時の行動の初動が変わる。
「短い時間で到達する」
テストの実行時間が短くなると、実行のハードルが下がり、結果的に用意されるテストケースやテスト実行の頻度が増える。またフィードバックループのサイクルが早くなる。したがって実行時間の短さは自動テストにとって重要。
単体テストの定義ブレブレ問題
短い時間で実行される自動テストといえば単体テスト(ユニットテスト)だが、単体テストの定義、人によってブレブレ問題がある。
下記のような問いは人によってyes/noが大きく分かれる
- データベースにアクセスするのはユニットテスト? Yes / No
- ネットワークにアクセスするのはユニットテスト? Yes / No
- ファイルにアクセスするのはユニットテスト? Yes / No
- 現在時刻にアクセスするのはユニットテスト? Yes / No
- 依存先のモジュールに本物を使うのはユニットテスト? Yes / No
特に5問目の「依存先のモジュールに本物を使うのはユニットテスト?」は大きく分かれる(※古典学派とロンドン学派)
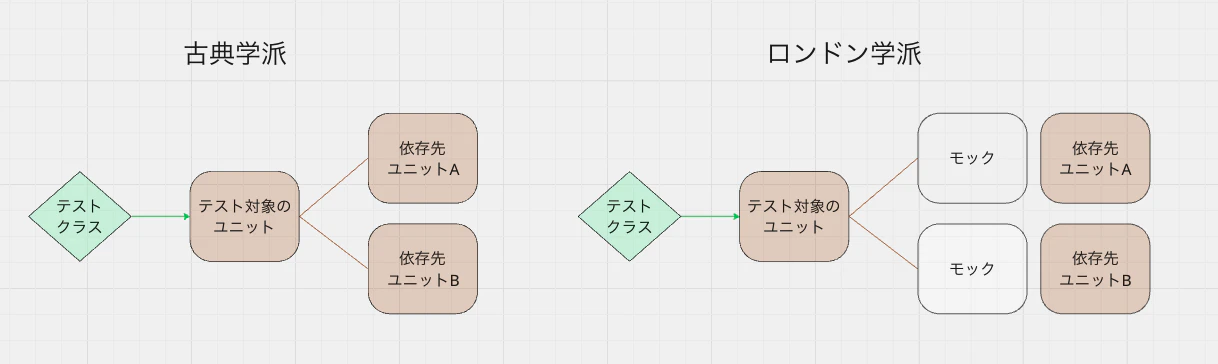
| 単体の意味 | 隔離対象 | モック対象 | |
|---|---|---|---|
| 古典学派 | 1つのふるまい | テストケース | 他のテストケースの実行に影響のある共有依存(DBとかファイルシステムとか) |
| ロンドン学派 | 1つのクラス | クラス | 全ての協力者オブジェクト |
解釈のブレが少ない分類:TestSize (Small,Medium,Large)
Googleのソフトウェアエンジニアリングではより曖昧さの少ないTest Sizeの分類が紹介されいてる
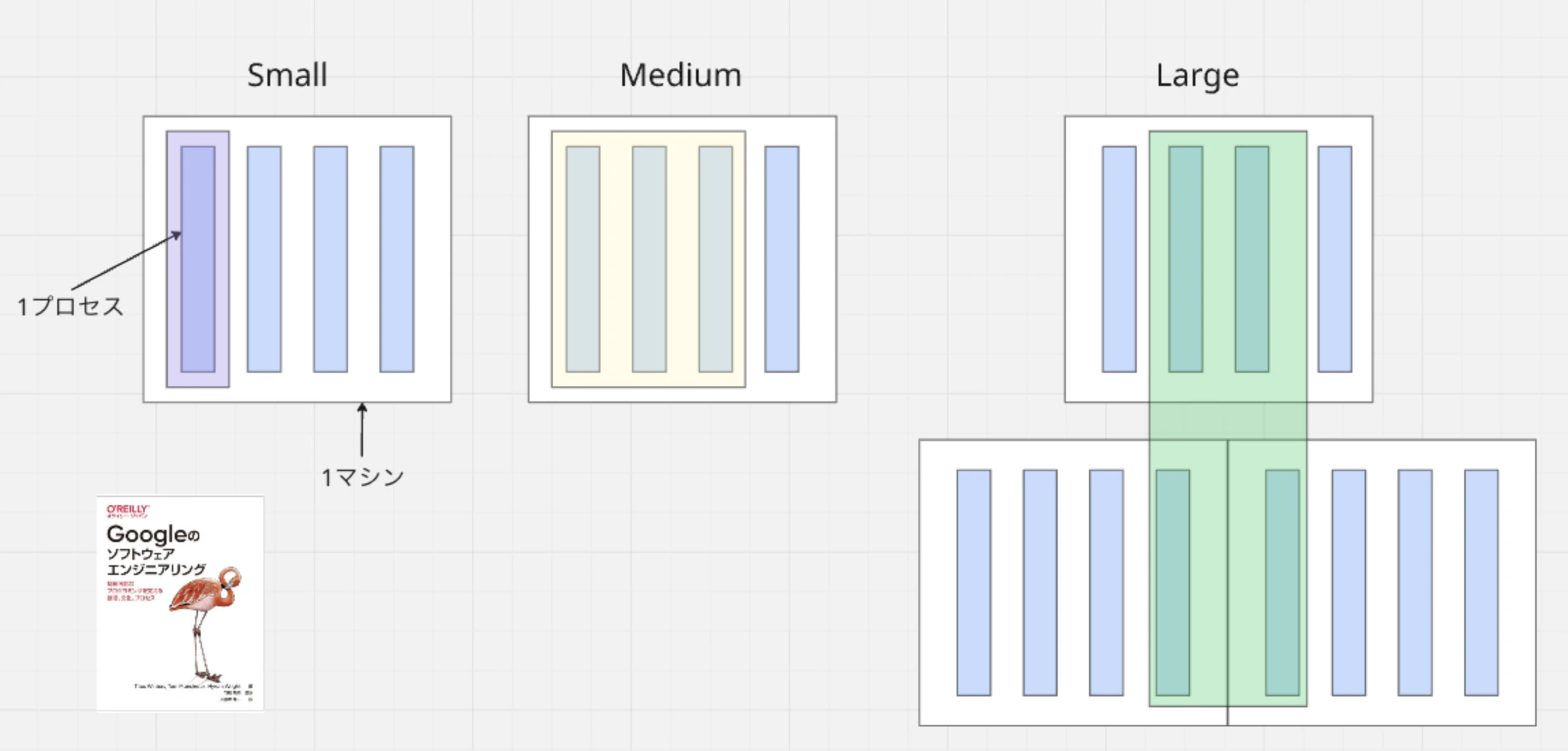
- small 1つのプロセスに閉じるテスト
- medium 1つのマシンに閉じるテスト(たとえばdocker-composeを使ってテスト用のDBコンテナ、バックエンド用コンテナ、フロント用コンテナを立ち上げて行うテストなど)
- large 複数のマシンを跨ぐテスト(外部ネットワークにアクセスするテスト)
例:GoogleのAndroid開発チームにおけるTestSizeは下記表のルールで運用されている
| 機能 (Feature) | Small | Medium | Large |
|---|---|---|---|
| ネットワークアクセス | No | localhost only | Yes |
| データベースアクセス | No | Yes | Yes |
| ファイルシステムアクセス | No | Yes | Yes |
| 外部システムの利用 | No | No | Yes |
| マルチスレッド | No | Yes | Yes |
| 時間制限(秒) | 60 | 300 | 900+ |
テストの実行速度や不安定さ(flakyさ)はこのテストサイズに強く影響を受ける。Largeテストは実行速度が遅く、flakyになりやすい。
「状態を保つ」
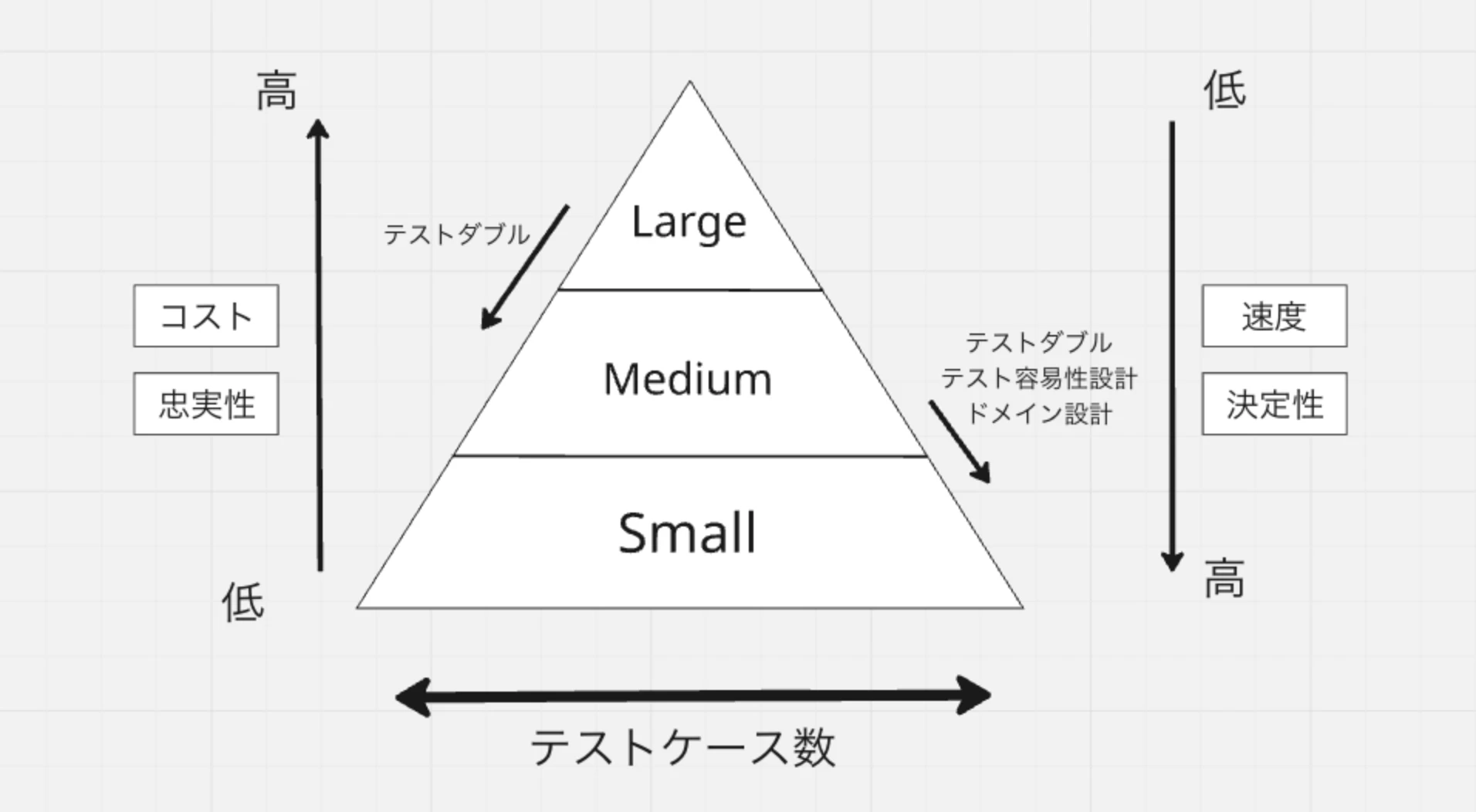
自動テストの信頼性を中長期的に保つ最適なバランス→テストピラミッド
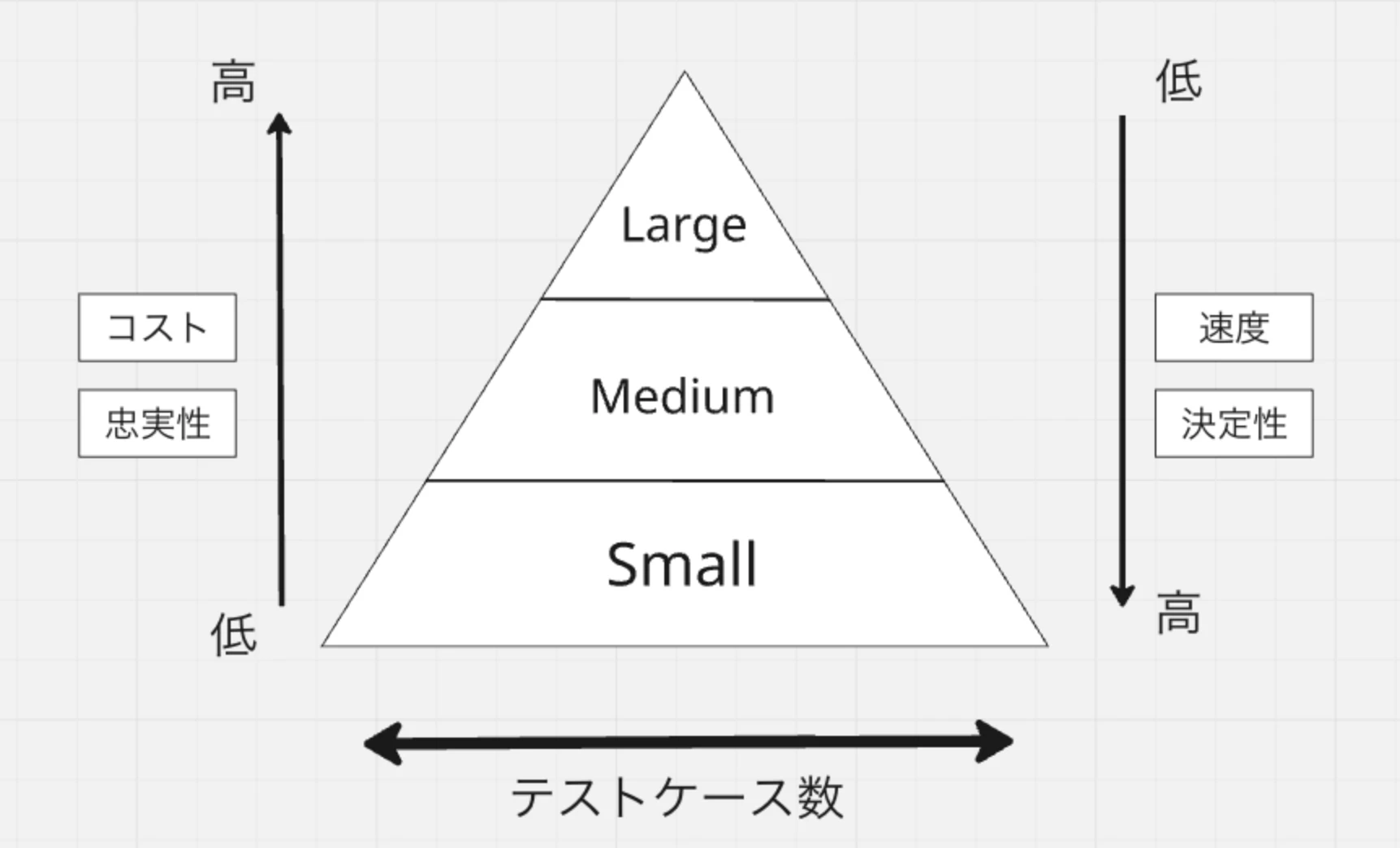
忠実性 = 本物に近い度合(低いほどプログラマの妄想の部分が多くなる)
決定性 = flakyじゃない度合
Largeテストになるほど実行時間が遅くなり、flakyさが増すのでパターン網羅のための和多くのテストはなるべくsmalltestで行う。ただsmallになるほど忠実性は下がるため、正常系など代表的なケースのLargeTestを用意しておくのも重要。
ちなみにCIを組む時もsmall testから先に流すのが良い。
medium/largeは実行時間が長くなるが、smallが失敗するならmedium/largeを流す意味ない。失敗なら早期に失敗させたい(フィードバックを早くするため)
通常のci時にはLarge testは流さず定時実行するtestでのみLargeを流すチームもあるそう。
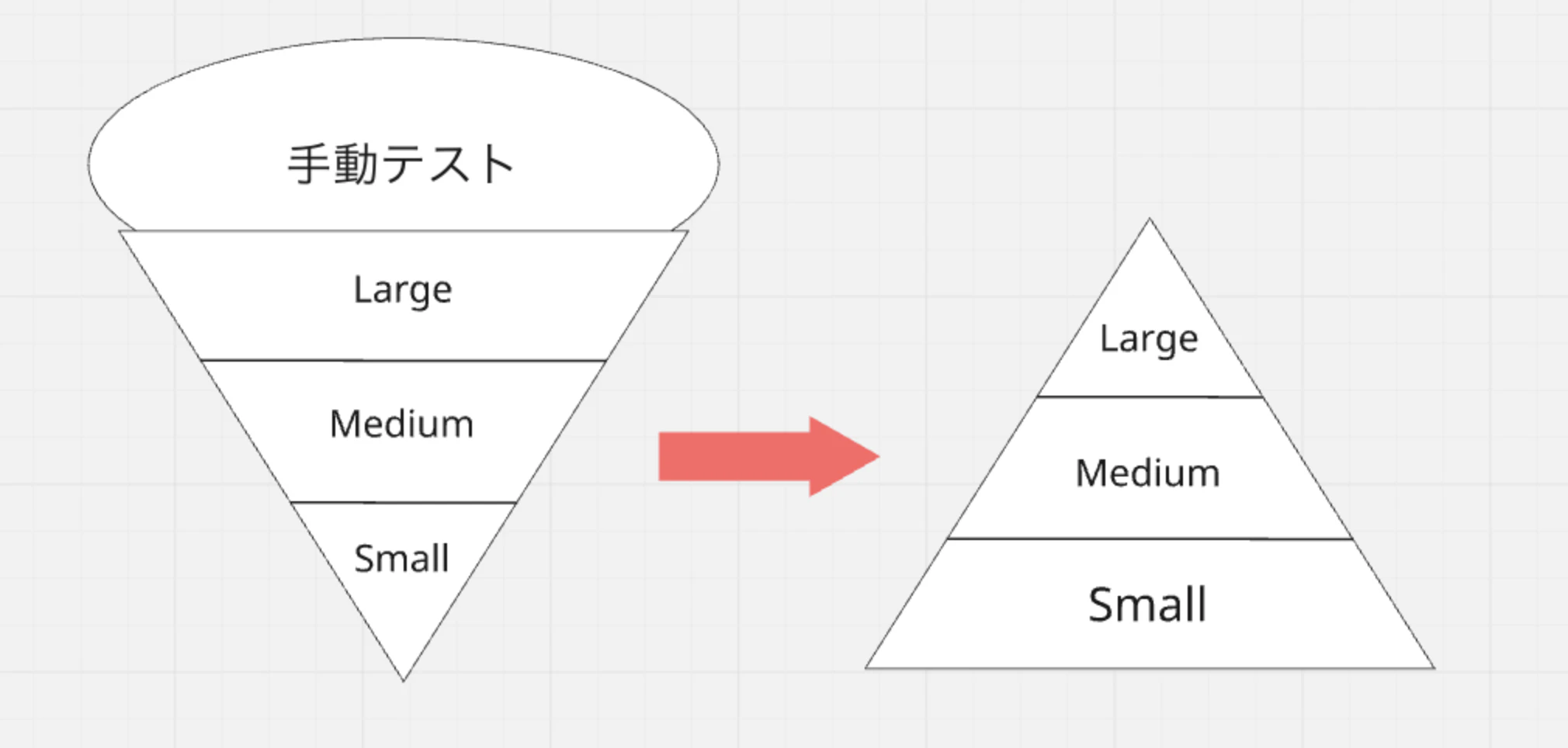
サイズダウン戦術:アイスクリームコーンからピラミッドへ
多くの現場ではピラミッドの逆のアイスクリームコーンから始まることが多い。ただ、それは悪いことではない。
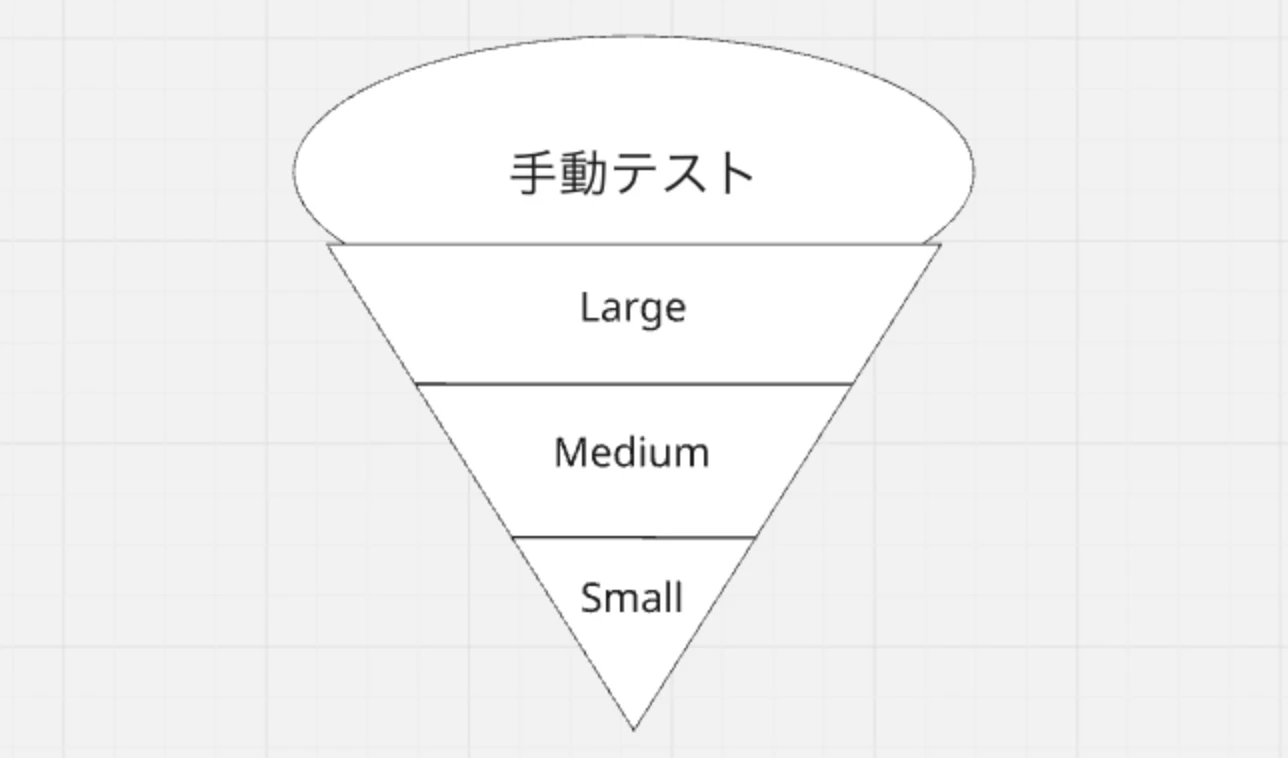
設計があまり決まっていない時に荒いレベルのテストや、エンドユーザー目線レベルのテストから始めるのは自然だし、悪いことではない。しかしこの状態を放置して、ソフトウェアの成長とともにアイスクリームが巨大になっていくとまずい(Largeばかりになるので実行時間が遅くflakyなテストばかりになるので。またLargeTestは構築や保守のコストも高い)
ちなみになぜアイスクリームコーンになってしまうのか?
開発者チームと自動テストを行うチーム(例、QAチーム)が分かれているとこうなりやすい。QAチームがベストを尽くそうとするとE2Eばっかりになってしまう。
エンドツーエンドテストを重視してしまう背景エンドツーエンドテストが多くなってしまう理由の1つは、テストの大部分を担当しているチームが開発チームではないことです。自動テストを行っている(すべてではないにしても)多くの QA チームは、UI テストに集中します。なぜならそれが彼らが慣れているアプリケーションやデータとのやりとりのしかただからです。
出典:『システム運用アンチパターン』
どうやってアイスクリームコーンをピラミッドにしていくか
ここでテストダブルの登場
テストダブルの注意点
- テスト対象の実装との構造的結合度が高まり、テストが脆くなり、偽陽性を招く
- 自作自演のテストのリスクがあり、偽陰性を招く
テストダブルの利点
- そもそもテストしにくいものをテスト可能にする
- テストの速度と決定性を向上させる
- テストサイズを下げる ←New!!
LargeからMediumへ
例:本番DynamoDBを呼ぶ代わりに、DynamoDBLocal(DynamoDB を
完全にローカル環境でエミュレーションして動かせるツール)を利用する
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/DynamoDBLocal.html
外部ネットワークへのアクセスがなくなり1マシンに閉じるので、Large→Mediumにテストサイズを下げられる
MediumからSmallへ
ドメインロジックと外部接続処理(DBアクセス、ファイルアクセス)を切り離すリファクタリングをすることにより、ドメインロジックの部分のsmall testをかけるようにする。=テスト容易性を上げる。HumbleObjectパターン(引用元:クリーンアーキテクチャ)
まとめ
テストダブルでサイズダウンして、各サイズをピラミッド型に配置し、テスト全体の信頼性を維持する。
一種類のテストで全てを網羅しようとするのではなく、役割を理解して最適配置をしていくことが重要。
自動テストの最大の効果は「根拠ある自信」
以下、和田卓人さんのスライドより
開発しているシステムが自分たちの想定どおりに動いていることが短い時間でわかると、
自信が生まれるようになります。ここまでさまざまな効果を説明してきましたが、根拠ある自信こそが、自動テストの最大の効果です。自動テストが整備されていなければ、もっと良い設計が浮かんだり、改善(リファクタリング)したほうが良いところが見つかったりしても、
すでに動いているコードを壊すのが怖いという不安が改善の手を止め、じわじわと保守性、開発生産性を下げていきます。自動テストが整備されていれば、考えるとおりに動くことが確認できて、動かなくなったらすぐにわかり、誰のコードでも同じように編集できます。
そこからは、いつでもどこからでも変化に適応できるという自信、改善に着手しようという勇気が生まれます。
自動テストが生み出す、根拠ある自信と勇気が長期的で継続的な変更と改善を支えるのです。