GCS へのファイルアップロードをトリガーにBigQueryにデータをインポートする。
やりたい事
Cloud Storage へのデータをアップロードしてCloud Functionsを起動してBigQueryにデータを取り込む。
今回はWEBサーバのアクセスログ(combined)にてやってみる。
ソリューション
- GCS
- Cloud Functions
- Big Query
GCS パケットを作成
gsutil mb -c regional -l asia-northeast1 gs://<バケット名>
-c ストレージクラス
-l ロケーション
注)GCS から BigQuery へデータロードする場合、GCS バケットと BigQuery のデータセットは同じロケーションに配置する必要がある。
Cloud Functionsの関数を作成
-
関数名:<任意>
-
リージョン:<任意>※GCSとかと同じところ
-
トリガータイプ:Cloud Storage
-
イベントタイプ:ファイナライズ/作成
-
バケット:作成したバケットを指定
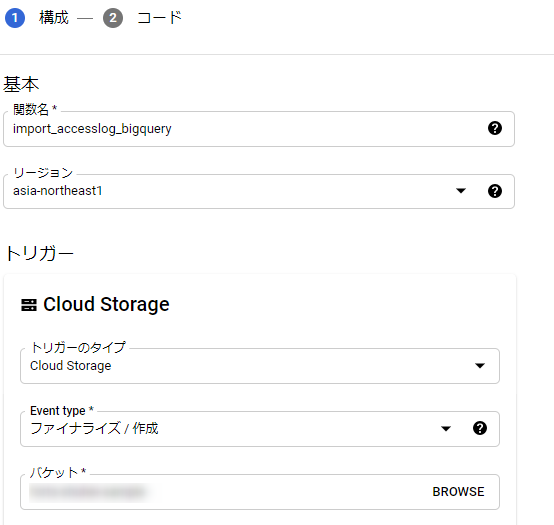
今回はランタイムとして、Python3.7を利用
- main.py
from google.cloud import storage, bigquery
from datetime import datetime
def <ENTRY_POINT>(data, context):
client = bigquery.Client()
project_id = '<PROJECTID>'
dataset_id = '<DATASETID'
bucket_name = data['bucket']
file_name = data['name']
file_ext = file_name.split('.')[-1]
if file_ext == 'csv':
uri = 'gs://' + bucket_name + '/' + file_name
file_ext = file_name.split('.')[-1]
table_id = 'accesslog'
#If you divide the table
#suffix = datetime.now().strftime("_%Y%m%d%H%M%S")
#table_id = 'accesslog' + suffix
# Job Configuration
dataset_ref = client.dataset(dataset_id)
job_config = bigquery.LoadJobConfig(autodetect=True)
#When you do not need to specify the schema
# job_config.skip_leading_rows = 1
job_config.schema = [
bigquery.SchemaField("host", "STRING", mode="NULLABLE"),
bigquery.SchemaField("clientid", "STRING", mode="NULLABLE"),
bigquery.SchemaField("auth", "STRING", mode="NULLABLE"),
bigquery.SchemaField("time", "STRING", mode="NULLABLE"),
bigquery.SchemaField("time_gmt", "STRING", mode="NULLABLE"),
bigquery.SchemaField("method", "STRING", mode="NULLABLE"),
bigquery.SchemaField("status", "INTEGER", mode="NULLABLE"),
bigquery.SchemaField("size", "INTEGER", mode="NULLABLE"),
bigquery.SchemaField("referer", "STRING", mode="NULLABLE"),
bigquery.SchemaField("ua", "STRING", mode="NULLABLE"),
]
job_config.source_format = bigquery.SourceFormat.CSV
# Job Request
load_job = client.load_table_from_uri(
uri,
dataset_ref.table(table_id),
job_config=job_config
)
print('Started job {}'.format(load_job.job_id))
load_job.result() # Waits for table load to complete.
print('Job finished.')
destination_table = client.get_table(dataset_ref.table(table_id))
print('Loaded {} rows.'.format(destination_table.num_rows))
else:
print('Nothing To Do')
- requirements.txt
google-cloud-storage == 1.14.0
google-cloud-bigquery == 1.11.2
ここまで書いたらを入力したらデプロイする。
以上をコマンドラインで行う場合には、
gcloud コマンド実行する階層に main.py と requirements.txt を配置して以下コマンドを実行。
gcloud functions deploy <関数名> --entry-point <ENTRY_POINT> --region <REGION> --runtime python37 --trigger-resource <BUCKET> --trigger-event google.storage.object.finalize
(参考)「gcloud functions deploy」のリファレンス
https://cloud.google.com/sdk/gcloud/reference/functions/deploy?hl=ja
CVS形式のファイル(今回はアクセスログをCSV形式に変換)をGCSへアップロードする
gsutil cp <アクセスログファイル> gs://<バケット名>/
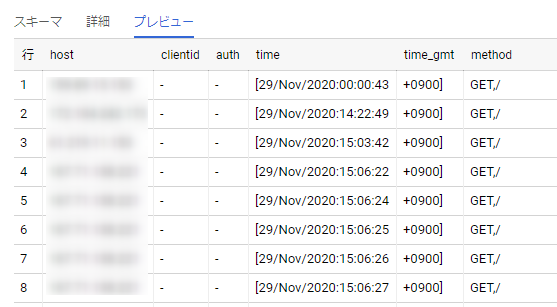
実行結果を確認
BigQuery にデータが取り込まれた。
最後に
BigQueryにデータを取り込むという一連の流れを触ってみる事を目的にまずはやってみました。
次はFirebase、Pub/Sub、Dataprocなどからの経由でのBigQueryへの取り込み。
BigQueryへ取り込んだデータの活用を検討予定。
![]() FORK Advent Calendar 2020
FORK Advent Calendar 2020
![]() 13日目 IMPORTFEED関数、GASを使ってお気に入りのサイトから情報収集 @shin77
13日目 IMPORTFEED関数、GASを使ってお気に入りのサイトから情報収集 @shin77
![]() : 15日目
: 15日目