About
- データエンジニアリングを実践して、社内でのデータ活用を効率化する方向を目指した。
- Big Queryで今の業務改善に直結する部分に必要な、最小限でDWH構築をした。
- 成果
- データマート作成により 顧客レポートのクエリ時間を大幅に高速化できた。
- 手作業で行っていたデータ更新作業を 自動化 できた。
- 業務効率化という名目で、個人的に興味があったデータエンジニアという職務を、勝手に実践して経験積む機会にした。
Writer Who
あるIT企業の自社サービス事業部の正社員歴1年目, LP制作からReact, Railsまで何でもエンジニア![]()
就職するまで世界旅などしてました。
課題
事業課題として、レポート表示速度、CPU、人的リソースの無駄、サイロ化、メンテ不可クエリがある。今回は以下の課題にスコープを絞った。
- 顧客レポート表示
- BIで直接CloudSQLレプリカに接続して, SQLを直接書いてる
- 顧客ごと毎回コピペして、個別にSQLを書いてる
- 表示するたびにクエリが実行されるため遅い
- 月次レポートバッチ作業
- とんでもなく重い処理なので、毎回クエリではなく一応Rakeタスク化されていた.
- サーバー ssh で手作業でRails Rakeタスクを実行.
- 外部エンジニアに毎月作業依頼。人的リソースの無駄。
- BIでしか使わないテーブルをアプリケーションDBで保存, 人間が手動更新してるのはどうか。
1の高速化, 2の自動化を目的に、まずは必要最小限、ただし拡張可能のデータ基盤構築を行なった。
学習したこと
1からデータ基盤構築の流れとツールを学んだ。
![]() 実践に必要な部分だけ学ぶつもりだったので、定義や使い所がいい加減な可能性があります。
実践に必要な部分だけ学ぶつもりだったので、定義や使い所がいい加減な可能性があります。
データ基盤のアーキテクチャ
データの流れ
アプリDB -> ELT -> DWH [データレイク -> Transform -> データマート] -> Reverse ELT -> BI, アプリDB
主なツール, SaaS
ELTツール
アプリデータDBからDWHにデータ転送する処理。変換処理とワークフローエンジンを組み合わせたり一緒になってたりする。
- Embulk + digdag 日本語だとこの組み合わせの情報がたくさん出てくる
- Airbyte OSS, Nocodeで様々なデータソースに対応したコネクタが使える。データソースが増えたらこれを使ってみたい。
- trocco 国産のSaaS。金使えるならこれも良さそう
- Google Cloud Datastream
Transform
DWH内でデータ変換する
- dbt
- dataform
変換する際、テーブル間の依存関係を解決して、順番に実行してくれる。
DWH
- Big Query
- Snowflake
- Databricks
- Apache Sparkのマネージドサービス、ということでいずれ使ってみたい。
課題解決
最小限構成
弊事業部ではインフラを全てGoogle Cloudに載せているので、まずは全てGoogleに乗っかり, 各種ETLツール自体の運用は避けた。DataformがGAになったのが大きい。
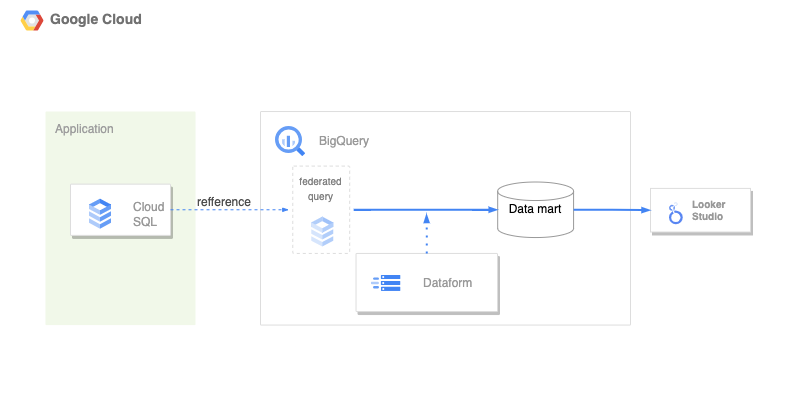
- Big Query
- Dataform
- can
- クエリ間の依存関係解決,
- クエリコードgit管理,
- SELECTによるテーブル作成&更新,
- スケジューリング。
- これなしではDWHを育てていけない。最初から使うべし。
- 知り、使うきっかけ
- snowflakeのdbt紹介動画を見て,めっちゃいいじゃん使いたい!
- でも最小スタートには要らないか、BigQueryのスケジュールで十分かな〜 => dataformを見つける。 Big Queryで dataformを使えば同じことできますよ、マネージドですよ
- だったら最初からこれでコード管理したらええやん。学習コストも低い。
- can
- 連携クエリ federated query
- big queryからcloud sqlを参照できる。dataformで使う時に多少詰まったが、使えた。
- トラブル解決記事(自著) https://qiita.com/shuent/items/2c5e934b81ae91c5318c
- ただ クエリによっては参照する回数やサイズが大きいので、参照ではなく、 data streamでニアリアルタイムでbigquery転送してしまった方が良いかもしれないと考えている。高そう。料金を比較しないといけない。
- データマートで使うテーブルが増えてきたら導入を比較検討する。
料金試算
DWH導入を社内で説明するため、月当たりの使用料を試算。2つの課題を達成するために, 現存のアプリDBから, データマートに使用する元データのデータ量, 更新頻度=クエリ回数書き出し, シミュレーション。
月当たりこれくらいデータ量が増えています、を Big Query + Looker Studioで図にした。1
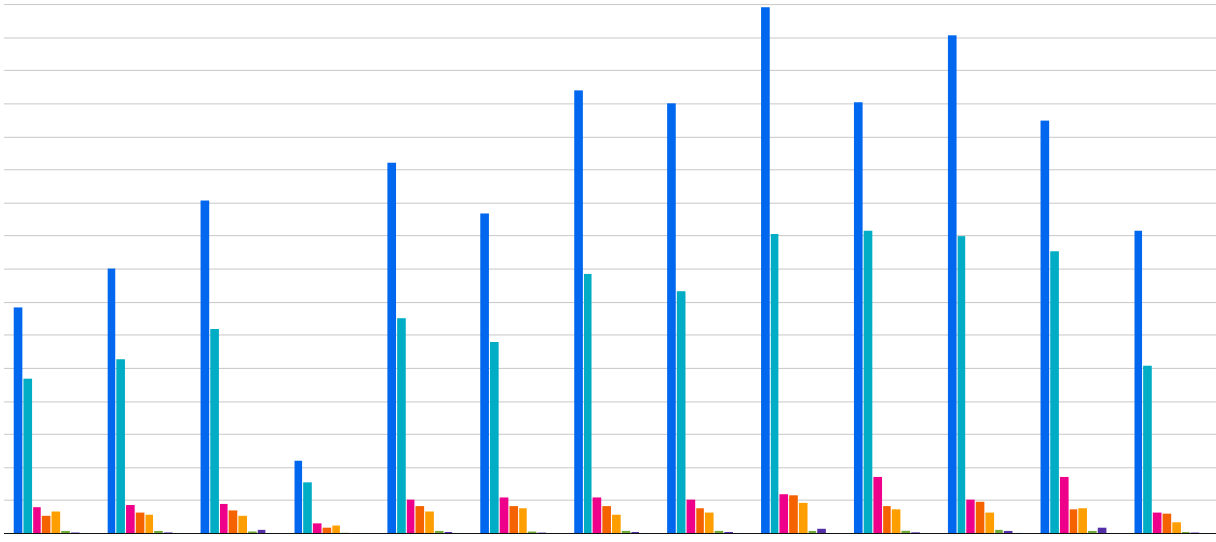
そこから月当たりの料金を概算した。結果、よほどのことがない限り低額で利用できることに。
キャッシュ
- Big Queryに対して、同じクエリを投げると無料でキャッシュを返す。
- Looker Studio は12時間(以下に設定可)ごとにデータ更新される。何回読み込んでも明示的に更新しない限りクエリを発行しない。
- よっていくらLSで閲覧が増えても課金額は増えない。
実装
- 全て Dataform のレポジトリ内で
*.sqlxファイルでクエリを記述した。 - クエリ実行スケジュールを Workflow Configuration から登録した
- CloudSQL呼び出しはこのように, 連携クエリで記述する。
config { type: "view" }
SELECT id, name
FROM EXTERNAL_QUERY(${constants.my_conn_id}, "
SELECT id, name FROM fruits;
")
成果
- データマート作成により 顧客レポートのクエリ時間を (長いと)10分から10秒 に高速化できた。
- 月次でサーバー内で手作業で行っていた レポート用データ更新作業を Dataformでスケジュールかすることにより自動化、工数削減できた。
次に目指す
私は、アプリケーション開発担当のスーパーリードエンジニアでもあるので、次に取り組み、アプリ自体のスリム化を目指したいところ。
- 管理画面上で分析データを表示するたびに呼んでいる 秘伝の SQLを、DWH内にロジックを移し、計算、 Material view化。Reverse ETLでアプリDBにデータ転送、スケジューリング。
- (SQLならまだしも, アプリコードと入り混じっていたりするので、そこの整理もしなくてはいけない)
また、これらの目先の課題を解決したら、大きい視点でデータ基盤を考えたい。GA4やログなど他のデータソースとの連携, グロースのための分析、 Reverse ETLによるデータ活用、等。
面白かったら、いいねを押してくださると、大変嬉しいです。![]()
-
tableごと色分け, XY軸はわざと切り取ってます。 ↩