この記事は畳み込みニューラルネットの規模と正答率の実験の続きのようなもの。
また、自身のブログ、Data Science Struggleを翻訳したものになる。
概略
ニューラルネットワークはその設計において、広い自由度を持つ。多くのレイヤーを持たせることやネットワークの途中からデータを入力として受け付けることなど、設計者次第で短くも長くもシンプルにも複雑にもなる。
tensorflowなどのフレームワークを使用すれば下記の図のようなシンプルなニューラルネットワークは比較的簡単に作成することができる。
今回は、上記の図のようなニューラルネットワークではなく、下記の図のような、途中で枝分かれをしたニューラルネットワークを作成していく。
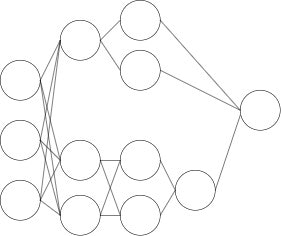
この記事の基本的な目的は以下の二点の確認になる。
- 枝分かれをしたニューラルネットワークをどのように書くか
- 精度の面でどのような特徴が見られるか
Tensorflowで書くのはちょっとめんどくさいのでkerasを使用。
上の二つの目的のうち、精度の確認は、そもそも分岐型のネットワークとそうでないネットワークで規模が既に異なり、一概に比較はできないので大体のものが見れれば良しとする。
分岐型ネットワークの書き方
まずはirisデータを用いて分岐型ネットワークのシンプルなモデルを書いてみる。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from keras.models import Model
from keras.layers import Dense, Input, merge
import keras
from keras.utils import np_utils
# data preparation
iris = datasets.load_iris()
features = iris.data
targets = np_utils.to_categorical(iris.target)
x_train, x_test, y_train, y_test = train_test_split(features, targets, train_size=0.7)
# model
inputs = Input(shape=(4,))
x_1 = Dense(8, activation='relu')(inputs)
x_1 = Dense(5, activation='relu')(x_1)
x_2 = Dense(7, activation='relu')(inputs)
x_2 = Dense(5, activation='relu')(x_2)
x = merge([x_1, x_2], mode='concat')
predictions = Dense(3, activation='softmax')(x)
model = Model(input=inputs, output=predictions)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
# training
history = model.fit(x_train, y_train, batch_size=5, epochs=100, shuffle=True, validation_split=0.1)
分岐型のニューラルネットワークをkerasで書くにはfunctional APIを使用する。関数型言語の作法でモデルを作成することが可能となる。
keras公式のkeras functional APIは説明がかなりわかりやすく、短時間でおおよその使い方はわかると思うので、確認したい。
上記コードのモデル部分を見ていく。
# model
inputs = Input(shape=(4,))
x_1 = Dense(8, activation='relu')(inputs)
x_1 = Dense(5, activation='relu')(x_1)
x_2 = Dense(7, activation='relu')(inputs)
x_2 = Dense(5, activation='relu')(x_2)
x = merge([x_1, x_2], mode='concat')
predictions = Dense(3, activation='softmax')(x)
model = Model(input=inputs, output=predictions)
Input関数により入力データ(説明変数)の次元数を定める。今回使用するirisは4つの説明変数を有している。
Functional APIを使用した書き方ではそれぞれのレイヤーが入力を受け付け、その出力を変数に既存もしくは新規の変数に格納していく形で進めていく。
今回のケースでは、入力層のすぐ後から、x_1、x_2の二つのルートに分岐しており、その二つが後のレイヤーでxにマージされている。
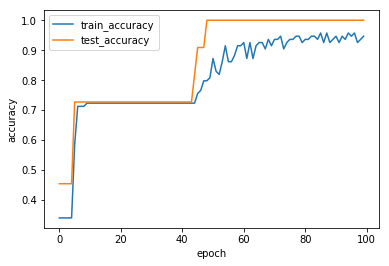
書き方の確認のためのモデルではあるが、一応、学習の進みをプロットする。
import matplotlib.pyplot as plt
def show_history(history):
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'test_accuracy'], loc='best')
plt.show()
show_history(history)
分岐型畳み込みニューラルネットワーク
cifar-10のデータを分類するための分岐型の畳み込みニューラルネットワークを作成してみる。
まずは、一応の比較対象として分岐をしない畳み込みニューラルネットワークを作成する。
def model_1(x_train, y_train, conv_num, dense_num):
input_shape = x_train.shape[1:]
# make teacher hot-encoded
y_train = to_categorical(y_train, 10)
# set model
model = Sequential()
model.add(Conv2D(conv_num, (3,3), activation='relu', input_shape=input_shape))
model.add(Dropout(0.2))
model.add(Conv2D(conv_num, (3,3), activation='relu'))
model.add(Dropout(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(conv_num * 2, (3,3), activation='relu'))
model.add(Conv2D(conv_num * 2, (3,3), activation='relu'))
model.add(Dropout(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(dense_num, activation='relu', W_regularizer = l1_l2(.01)))
model.add(Dropout(0.2))
model.add(Dense(int(dense_num * 0.6), activation='relu', W_regularizer = l1_l2(.01)))
model.add(Dense(10, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
# training
history =model.fit(x_train, y_train, batch_size=256, epochs=50, shuffle=True, validation_split=0.1)
return history
history_1 = model_1(x_train, y_train, 32, 256)
show_history(history_1)
結果は以下の通り。
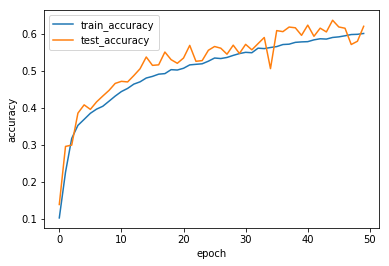
MacbookProでは1 epochの学習に大体180秒かかるため50 epochしか回していない。
そしてこれが分岐型の畳み込みニューラルネットワークのコード。
from keras.layers import Input, merge
def model_2(x_train, y_train):
inputs = Input(x_train.shape[1:])
# make teacher hot-encoded
y_train = to_categorical(y_train, 10)
# set model
x_orig = Conv2D(32, (3,3), activation='relu')(inputs)
x_orig = Dropout(0.2)(x_orig)
x_1 = Conv2D(32, (3,3), activation='relu', border_mode='same')(x_orig)
x_1 = Conv2D(24, (3,3), activation='relu', border_mode='same')(x_1)
x_2 = Conv2D(12, (3,3), activation='relu', border_mode='same')(x_orig)
x_2 = Conv2D(8, (3,3), activation='relu', border_mode='same')(x_2)
x_2 = Conv2D(4, (3,3), activation='relu', border_mode='same')(x_2)
x = merge([x_1, x_2], mode='concat')
x = Conv2D(32, (3,3), activation='relu')(x)
x = Dropout(0.2)(x)
x = Conv2D(64, (3,3), activation='relu')(x)
x = Conv2D(64, (3,3), activation='relu')(x)
x = Dropout(0.2)(x)
x = MaxPooling2D(pool_size=(2,2))(x)
x = Flatten()(x)
x = Dense(256, activation='relu', W_regularizer=l1_l2(0.01))(x)
predictions = Dense(10, activation='softmax')(x)
model = Model(input=inputs, output=predictions)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
# training
history =model.fit(x_train, y_train, batch_size=256, epochs=50, shuffle=True, validation_split=0.1)
return history
history_2 = model_2(x_train, y_train)
show_history(history_2)
結果は以下の通り。
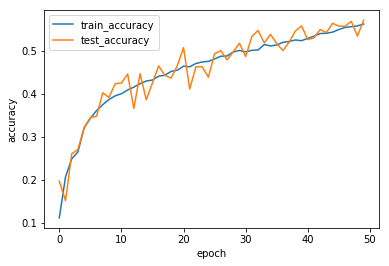
1 epochの学習におよそ700秒ほどかかった。これも50 epochでストップ。
残念ながら50 epochの時点では大きな差は見ることができなかった。
反省
- 入力データのスケーリングの有無も含めた実験にするつもりだったのにうっかり忘れてしまった
- 学習の早い段階で何かしかの違いがでるのではないかと期待して結局50 epochではまったく違いを観測できないという残念な感じになった
- 分岐するタイプのニューラルネットワークの分岐とマージに関しての記事が少なく、情報が確かか、少し不安