この記事は、自身のブログ、Data Science Struggleを翻訳したものになる。
概略
色々な試みの中でニューラルネットワークを組むことが増えてきたので、組んでいく上での勘所をまとめておく。
ニューラルネットワークは自由度が高く、調整可能箇所の多いアルゴリズムなので、より良いモデルを作成するための調整には気にする手順がある。
それも含めてまとめておく。
ニューラルネットワークの構成要素
構成要素を、必須要素とオプション要素に分けて整理する。今回整理しておく構成要素は、実際にニューラルネットワークを組むときに意識しなければいけないものに限る。
ニューラルネットワークそのものの全体像については別記事に緩くまとめたのでそちらを参照で。
必須要素
- レイヤー
- ノード
- 活性化関数
レイヤー、ノード
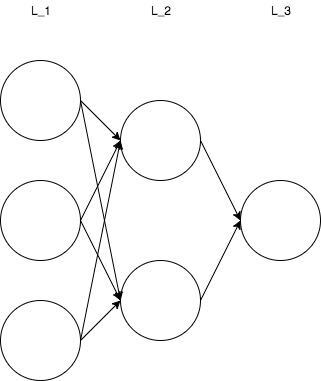
上記図のL_1、L_2、L_3がそれぞれレイヤーになる。レイヤーを構成している円がノードになる。
ニューラルネットワークを作成する際に、その全体の規模はレイヤーとレイヤーあたりのノードの数で決めることがでいる。
この図ではL_1、L_2、L_3はそれぞれ入力層、隠れ層、出力層となる。基本的に、入力層はデータの形、出力層は出力の形、つまりモデルの目的に左右されることになるため、モデル作成者が調整することになるのはこの隠れ層の部分になる。
レイヤーの数、レイヤーあたりのノード数を増やすことでモデルはよりデータに対する追跡能力を上げることになるが、更新する重みの数が増えるため学習には時間がかかるようになる。
モデルの精度のスケールの最も大きい部分を担うので、モデルを作成するときにはここを大雑把に決めることからスタートする。
活性化関数
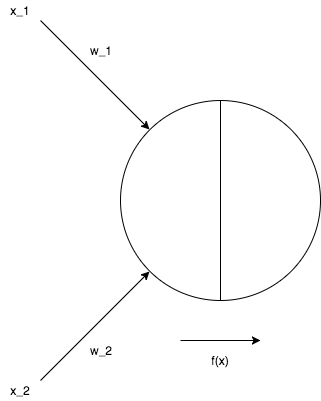
活性化関数はノードが受け付けたインプット(データもしくは前のレイヤーの出力)と重みの線形結合された値に対して使用する関数だ。
この関数は上記の図からわかるようにノードごとに設けられる。実際にニューラルネットワークを作成するときにはレイヤー単位で設定することになる。
出力層と隠れ層では基本的に使用する活性化関数が異なる。出力層の活性化関数はモデルに求められる出力の形に左右される。
隠れ層の活性化関数はいくつも種類があり、その選択によってモデルの精度も異なる。
一部を挙げてみる。
- Linear
- ReLU
- sigmoid
- Leaky ReLU
- Parametric ReLU
- maxout
オプション要素
オプション要素は基本的には過学習の防止のために設けられる。ニューラルネットワークはレイヤーとノードの数を増やすことで非常に高いデータへの追跡能力を持つことになるため、汎化作用は大切だ。
- ドロップアウト
- 正則化
ドロップアウト
データを読み込んでモデルの訓練を行うときに、一定割合の数のノードを不活性化させて学習をしていく。一定割合のノードを不活性化させてパラメーターを更新させていくことで過学習を防ぐ。
どのレイヤーにドロップアウトを設置し、どれだけの割合のノードを不活性化させるかを選択する。
ドロップアウトさせるレイヤーの割合が高すぎると、学習がうまく進まないことがあるため、全てのレイヤーに高めの割合で仕込めば良いというものではない。
正則化
損失関数に対して正則化項を加えることでパラメーターの値が大きくなりすぎてしまうことを防ぐ。これもいくつか種類がある。
- L1正則化
- L2正則化
どの正則化の手法を選択し、その係数(ハイパーパラメーター)の値をどうするかなどの選択をする。
正則化を強めすぎるとこれもまた学習が進まなくなるため、一概に全てのレイヤーのノードに強めの正則化を仕込めば良いというものでもない。
実際に組んでいく時の手順
ニューラルネットワークを組むときに気にしなければいけないのは以下の二点。
- データを追いかけるのに十分な規模を持つこと
- 過学習が起きてないこと
まず、ニューラルネットワークがデータに対応し、目的を達するのに十分な精度を持っている必要がある。さらに、訓練データに対するaccuracyが十分であっても、未知のデータに対する精度が低ければモデルは用を果たさない。汎化能力を十分に持たせる必要がある。
上記の二つを満たすためにはだいたい以下の順で進める。(思いっきり主観)
- なるべく少なめのレイヤー数、ノード数のモデルを作成する
- レイヤー数やノード数を増やしていき、lossを下げ、accuracyを上げていく
- lossを下げていった段階で過学習が起きたようなら、ドロップアウトや正則化を設置して過学習を解消する
要するに、必須要素の部分でスケールを掴みつつ、オプション要素で生じた問題を調整していくということになる。
kerasでの例
例えばkerasでは以下のように、レイヤー、レイヤーあたりのノード数、活性化関数、ドロップアウトを設置できる。
model.add(Dense(8, input_dim=4, W_regularizer = l1_l2(.01)))
model.add(Activation('relu'))
model.add(Dropout(0.2))