[目次]
1.はじめに
2.結論
3.確認内容
3-1.環境
3-2.ライブラリインポート
3-3.データ数確認、画像水増し、画像チェック
3-4.画像データ分割
3-5.モデル構築
3-6.学習実施
3-7.モデル精度確認
3-8.転移学習でのトライ
3-9.苦労した点
4.感想
1.はじめに
・どんな人に読んでほしいか
深層学習に興味ある人。
画像認識に興味ある人。
python初心者。
・この記事から何がわかるか
tensorflowを用いたCNN画像分類の流れ。
(tensorflowとはGoogleが開発したオープンソースの機械学習ライブラリです。)
ご参考:いとは [tensorflowとは]
https://ainow.ai/2021/03/26/254046/
・背景
私自身、製造業で開発、評価を行う仕事を行なっており、日々データと向き合う仕事でした。近年は新しいハードの追加やデータロガーの追加で日々、扱うデータ量が増えていき、データ確認、データ整理でみんないっぱいいっぱいです。さらに個人個人でデータ整理後のアウトプットも全く同じというわけではないので、もどかしさを感じてきました。その中で、なんとか効率化できないのかと調べているとAIに可能性を感じ、AIに興味が出てきました。そして、現在まで3ヶ月という短い期間ですがアイデミーというスクールで機械学習と自然言語処理を学んできました。その最終成果物をまとめます。
題材ですが、色々考えた結果、深層学習を用いた画像分類を行うことしました。何の分類器を作ろうかということですが、自分の興味あるものを分類できるかトライしてみることにしました。それはSUVです。SUVと言ってもたくさんありますがなんとなく形が似ている6車種を選定し、その6車種について分類できるか確認していきます。似た形の車をどこまで見分けられるのかという単純な興味です。また、個人的にもよく画像認識とか自動運転とかよく聞きますが、仕組みが分かっておらずいまいちピンときていませんでした。この実装を通して経験値を積みたいと思います。
分類した車種はこちらの6車種です。
[Jeep]

[FJ cruiser]

[Jimny]

[Mersedes G]

[Land cruiser 60]

[Land cruiser 40]

共通点は車両のカタチがカクカクしていてヘッドライトが丸目というところです。
2.結論
結論から言うと、準備した画像データと構築したモデルでは正しく分類できた正解率は約55%でした。要改善ですが、画像分類の流れをメインで記載します。
3.内容
分類を行った中身の話をしていきます。
分類の仕組みとしてはすべての画像データ(訓練データ)に答え(教師データ)となる車種別の番号を紐付けて、モデルに各車両の画像の特徴を学習させます。
今回は6車種の分類なのでこのように番号で紐付けています。
0番:Jeep
1番:FJcruiser
2番:Jimny
3番:Mersedes G
4番:Landcruiser60
5番:Landcruiser40
そして学習したモデルに新たな画像を分類させるとそれぞれの車両の番号に対して、認識が何%の確率か計算し、一番確率が高い番号が該当する車両であると予測し、分類出来ます。
例えば、犬猫の判定だけだとインプット、アウトプットのモデルイメージは以下です。(ネコが95%の確率。)
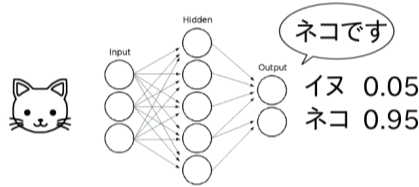
3-1.環境
プログラミングの言語はpythonで、確認した環境については以下です。
環境:Google Colaboratory
Googleアカウントを持っていればアプリ内のドライブから選択できます。
これでパソコン本体へのターミナルでのpythonライブラリパッケージのインストールは不要です。
また、今回のCNN畳み込みでは学習回数(epoch)を多く設定したのでプログラム完了まで莫大な時間がかかってしまいました。ランタイムのタイプをNoneからGPUに変更してプログラムを実行することをお勧めします。GPUにすると1/12くらいの速さになり、さらにGoogle Colaboratory PROにアップグレードするとさらに半分くらいのスピードになりました。(ただアップグレードは月額1000円くらいの支払い費用が発生します。。。膨大なデータを扱わない限り不要です。)
3-2.データ数確認、画像水増し、画像チェック
まずは学習に必要なデータ集めです。今回はデータ集めからですので、ネットより各6車種についてちまちまと各車両について約110枚画像データを集めました。(計650枚)
この650枚のデータをGoogleのクラウドにディレクトリ別にアップロードしておきます。
画像データをサイトから自動で取得するスクレイピングとかも手法としてあるのですが、自分の学習が追いつかず。。またサイトの利用規約の反するのが大体でしたのでスクレイピングはやめました。
集めた約650枚のデータを元に、学習データと検証データを事前に分け、それぞれの車種ごとに学習データを約3250枚、検証データを930枚まで水増しします。画像の水増し状況を下記の表に示します。
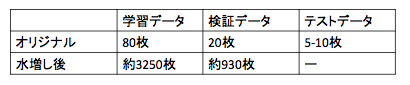
そして、実行したプログラムはこちらです。
まずはGoogle Colaboratoryでコードを分割し下記のコードでクラウドのドライブに接続できるようにします。(クラウドに保存してある各車両の画像にアクセスするため。)
from google.colab import drive
drive.mount('/content/drive')
Google Colaboratoryの画面上では、こんな感じでコードが分割されます。
ここからはtensorflowのImageDataGeneratorメソッドを使ってランダムに設定した変化を与えて画像を水増しします。
学習データの水増ししたコードはこちらです。
今回、TensorFlowのImageDataGeneratorを使って水増しを行いました。
ImageDataGeneratorには多くの引数があり、それらを適切に指定することで、簡単にデータを加工することができます。また複数の加工を組み合わせて新しい画像を生成することもできます。
from google.colab import drive
drive.mount('/content/drive')
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import numpy as np
import os
import glob
# 1枚あたり50枚の画像を水増し
N_img = 50
# 入力画像の保存先フォルダ
folder = ["01_Jeep", "02_FJcruiser", "03_Jimny", "04_Mersedes_G","05_Landcruiser60", "06_Landcruiser40"]
#folder_filename = folder[0]
#入力画像の保存先パス
pass_dir = "/content/drive/My Drive/SUV/Train/"
#画像出力先パス名
pass_dir_out = "_Output_Train"
#作成したファイル名の日付け
day_name = "0120"
# 入力画像の保存先パス
for suv_name in folder : #folderからindexの0番目から順番に名前を取り出す
dir = pass_dir + suv_name #ディレクトリを保存先名を決定
files = glob.glob(dir + "/*.jpeg") #上記のディレクトリからjpegファイルを全て選択
# 出力画像の保存先パス
output_path = pass_dir + suv_name + pass_dir_out
if os.path.isdir(output_path) == False:
os.mkdir(output_path)
for i, file in enumerate(files):
img = load_img(file)
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
# ImageDataGeneratorの生成
datagen = ImageDataGenerator(
width_shift_range=0.1, #ランダムに水平方向に平行移動する、画像の横幅に対する割合
height_shift_range=0.1, #ランダムに垂直方向に平行移動する、画像の縦幅に対する割合
zoom_range=0.3, #ランダムに画像を圧縮、拡大させる割合。
horizontal_flip=True, #Trueを指定すると、ランダムに水平方向に反転。
vertical_flip=True, #Trueを指定すると、ランダムに垂直方向に反転。
samplewise_center=True, #各サンプルの平均を0にする。
samplewise_std_normalization=True, #標準化。個々の特徴を平均0、分散1にすることで、特徴ごとのデータの分布を近づける手法。
#コメントオフで不使用 featurewise_center=True, #データセット全体で,入力の平均を0にする
#コメントオフで不使用 zca_whitening=True, #白色化
channel_shift_range=100, #ランダムに色のチャンネルをシフトする範囲
rotation_range=20.0, #ランダムに回転する回転範囲(単位degree)
)
# 1枚あたり50枚の画像を水増し生成
dg = datagen.flow(x, batch_size=32, shuffle=True, save_to_dir=output_path, save_prefix=suv_name+day_name, save_format='jpeg')
for i in range(N_img):
batch = dg.next()
検証データの水増しコードはこちらです。(訓練データの時とほぼ同じです。)
from google.colab import drive
drive.mount('/content/drive')
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import numpy as np
import os
import glob
# 1枚あたり50枚の画像を水増し
N_img = 50
# 入力画像の保存先フォルダ
folder = ["01_Jeep", "02_FJcruiser", "03_Jimny", "04_Mersedes_G","05_Landcruiser60", "06_Landcruiser40"]
#folder_filename = folder[0]
#保存先パス
pass_dir = "/content/drive/My Drive/SUV/Validation/"
#出力先パス名
pass_dir_out = "_Output_Val"
#作成したファイル名の日付け
day_name = "0120"
# 入力画像の保存先パス
for suv_name in folder : #folderからindexの0番目から順番に名前を取り出す
dir = pass_dir + suv_name #ディレクトリを保存先名を決定
files = glob.glob(dir + "/*.jpeg") #上記のディレクトリからjpegファイルを全て選択
# 出力画像の保存先パス
output_path = pass_dir + suv_name + pass_dir_out
if os.path.isdir(output_path) == False:
os.mkdir(output_path)
for i, file in enumerate(files):
img = load_img(file)
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
# ImageDataGeneratorの生成
datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True,
samplewise_center=True,
samplewise_std_normalization=True,
# featurewise_center=True,
# zca_whitening=True,
channel_shift_range=100,
rotation_range=20.0,
)
# 1枚あたり50枚の画像を水増し生成
dg = datagen.flow(x, batch_size=32, shuffle=True, save_to_dir=output_path, save_prefix=suv_name+day_name, save_format='jpeg')
for i in range(N_img):
batch = dg.next()
参考文献:
西住工房 【Keras/TensorFlow】画像データセットの水増し
https://algorithm.joho.info/programming/python/flask-keras-image-extend/
こちらが水増ししたJeep画像の抜粋した結果です。画像がランダムで反転したり、回転したり出来ています。
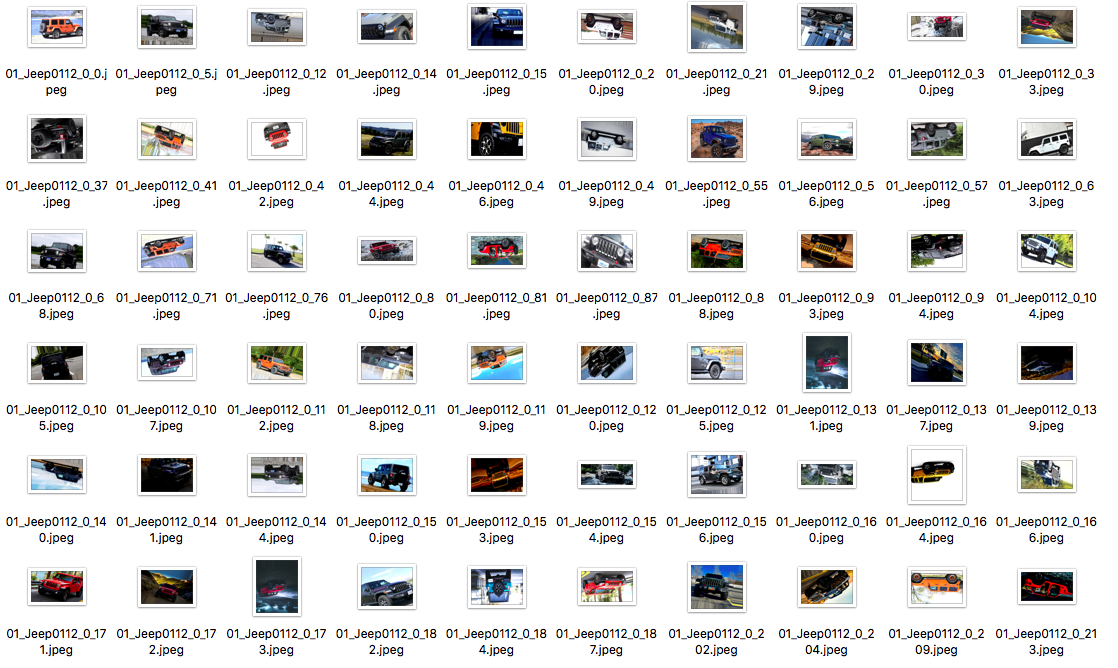
なぜか狙った通り画像が50倍増加にならず。。80枚を4000枚狙いが約3250枚くらいに。
要原因特定です。。
3-3.ライブラリインポート
ここからはCNNの実装です。上記と同様にはpythonのtensorflowを使用していきます。
CNN:Convolutional Neural Network(畳み込みニューラルネットワーク)
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow import keras
from tensorflow.keras.layers import Activation, Conv2D, Dense, Dropout, Flatten, MaxPooling2D, BatchNormalization
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import optimizers
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
import glob
import tensorflow as tf
3-4.画像データ読み込み
水増しした画像データ(訓練データ、検証データ)を読み込みます。そして最後に完成したモデルで確認するテストデータも準備します。
# 画像データを6個のフォルダから読み込む。データセットの作成。
#(6クラス = ['01_Jeep_Output2', '02_FJcruiser_Output2', '03_Jimny_Output2' '04_Mersedes_G_Output2', '05_Landcruiser60_Output2', '06_Landcruiser40_Output2'])
# 画像データの読み込み、画像サイズ調整、Numpy配列化してX、Yに追加
folder_train = ["01_Jeep_Output_Train", "02_FJcruiser_Output_Train", "03_Jimny_Output_Train", "04_Mersedes_G_Output_Train","05_Landcruiser60_Output_Train", "06_Landcruiser40_Output_Train"]
folder_val = ["01_Jeep_Output_Val", "02_FJcruiser_Output_Val", "03_Jimny_Output_Val", "04_Mersedes_G_Output_Val","05_Landcruiser60_Output_Val", "06_Landcruiser40_Output_Val"]
folder = ["01_Jeep", "02_FJcruiser", "03_Jimny", "04_Mersedes_G","05_Landcruiser60", "06_Landcruiser40"]
image_size = 64 #画像サイズ変更値
#訓練データの前処理
X_train = [] #空のリスト
y_train = [] #空のリスト
for index, suv_name in enumerate(folder_train): #folder_trainからindexとフォルダ名を順番に取り出す
train_dir = "/content/drive/My Drive/SUV/Train/" + suv_name #画像ファイル保存先のディレクトリ(フォルダ)アドレス
files = glob.glob(train_dir + "/*.jpeg") #ディレクトリからjpegの全画像ファイルを読み込んでリスト化しfilesへ
print(files) #コンソールにファイル名を出力
for i, file in enumerate(files): #filesリストから順番に画像データをfileとして取り出す
image = Image.open(file) #画像データfileを開いてimageへ
image = image.convert("RGB") #カラーに変換
image = image.resize((image_size, image_size)) #写真のサイズを変更
data = np.asarray(image) #Numpy配列に変換してdataへ
X_train.append(data) #Numpy配列の画像データ(data)をリストXへ追加
y_train.append(index) #folderのindex(ラベル)をリストYへ追加
X_train = np.array(X_train) #Numpy配列に変換
y_train = np.array(y_train) #Numpy配列に変換
#画像データをfloat32型にし、0から1の範囲に変換
X_train = X_train.astype('float32')
X_train= X_train / 255.0
# 正解ラベルの形式をone hotエンコーディング
y_train = to_categorical(y_train)
#検証データの前処理
X_val = [] #空のリスト
y_val = [] #空のリスト
for index, suv_name in enumerate(folder_val): #folder_valからindexとフォルダ名を順番に取り出す
val_dir = "/content/drive/My Drive/SUV/Validation/" + suv_name #画像ファイル保存先のディレクトリ(フォルダ)アドレス
files = glob.glob(val_dir + "/*.jpeg") #ディレクトリからjpegの全画像ファイルを読み込んでリスト化しfilesへ
print(files) #コンソールにファイル名を出力
for i, file in enumerate(files): #filesリストから順番に画像データをfileとして取り出す
image = Image.open(file) #画像データfileを開いてimageへ
image = image.convert("RGB") #カラーに変換
image = image.resize((image_size, image_size)) #写真のサイズを変更
data = np.asarray(image) #Numpy配列に変換してdataへ
X_val.append(data) #Numpy配列の画像データ(data)をリストXへ追加
y_val.append(index) #folderのindex(ラベル)をリストYへ追加
X_val = np.array(X_val) #Numpy配列に変換
y_val = np.array(y_val) #Numpy配列に変換
#画像データをfloat32型にし、0から1の範囲に変換
X_val = X_val.astype('float32')
X_val= X_val / 255.0
# 正解ラベルの形式をone hotエンコーディング
y_val = to_categorical(y_val)
#テストデータの前処理
X_test = [] #空のリスト
y_test = [] #空のリスト
for index, suv_name in enumerate(folder): #folderからindexとフォルダ名を順番に取り出す
test_dir = "/content/drive/My Drive/SUV/Test/" + suv_name #画像ファイル保存先のディレクトリ(フォルダ)アドレス
files = glob.glob(test_dir + "/*.jpeg") #ディレクトリからjpegの全画像ファイルを読み込んでリスト化しfilesへ
print(files) #コンソールにファイル名を出力
for i, file in enumerate(files): #filesリストから順番に画像データをfileとして取り出す
image = Image.open(file) #画像データfileを開いてimageへ
image = image.convert("RGB") #カラーに変換
image = image.resize((image_size, image_size)) #写真のサイズを変更
data = np.asarray(image) #Numpy配列に変換してdataへ
X_test.append(data) #Numpy配列の画像データ(data)をリストXへ追加
y_test.append(index) #folderのindex(ラベル)をリストYへ追加
X_test = np.array(X_test) #Numpy配列に変換
y_test = np.array(y_test) #Numpy配列に変換
#画像データをfloat32型にし、0から1の範囲に変換
X_test = X_test.astype('float32')
X_test = X_test / 255.0
# 正解ラベルの形式をone hotエンコーディング
y_test = to_categorical(y_test)
# 学習データ、検証データ、モデル確認用データの表示(確認用)
#print('')
#print('X_train')
#print(X_train) #学習データ
#print('')
#print('X_val')
#print(X_val) #検証データ
#print('')
#print('y_train')
#print(y_train) #学習データ用正解ラベル
#print('')
#print('y_val')
#print(y_val) #検証データ用正解ラベル
#print('')
#print('X_test')
#print(X_test) #モデル確認用データ
#print('')
#print('y_test')
#print(y_test) #モデル確認用データ正解ラベル
#print('')
# データセットの個数を表示
print(X_train.shape, 'X_train samples')
print(X_val.shape, 'X_val samples')
print(y_train.shape, 'y_train samples')
print(y_val.shape, 'y_val samples')
print(X_test.shape, 'X_test samples')
print(y_test.shape, 'y_test samples')
print('')
#ImageDataGeneraterを使って水増し
datagen = ImageDataGenerator(width_shift_range=0.1, #ランダムに水平方向に平行移動する、画像の横幅に対する割合
height_shift_range=0.1, #ランダムに垂直方向に平行移動する、画像の縦幅に対する割合
zoom_range=0.3, #ランダムに画像を圧縮、拡大させる割合。
horizontal_flip=True, #Trueを指定すると、ランダムに水平方向に反転。
vertical_flip=True, #Trueを指定すると、ランダムに垂直方向に反転。
samplewise_center=True, samplewise_std_normalization=True, #標準化。個々の特徴を平均0、分散1にすることで、特徴ごとのデータの分布を近づける手法。
featurewise_center=True, zca_whitening=True, #白色化
channel_shift_range=100, #ランダムに色のチャンネルをシフトする範囲
rotation_range=20.0, #ランダムに回転する回転範囲(単位degree)
)
datagen.fit(X_train) #X_trainデータにImageDataGeneraterを適用
上記のコードの最後にImageDataGeneraterを使って訓練データをランダムに加工しています。
参考文献:
でんだろ KerasのCNNを使用してオリジナル画像で画像認識を行ってみる
https://newtechnologylifestyle.net/keras%E3%81%AEcnn%E3%82%92%E4%BD%BF%E7%94%A8%E3%81%97%E3%81%A6%E3%82%AA%E3%83%AA%E3%82%B8%E3%83%8A%E3%83%AB%E7%94%BB%E5%83%8F%E3%81%A7%E7%94%BB%E5%83%8F%E8%AA%8D%E8%AD%98%E3%82%92%E8%A1%8C%E3%81%A3/
3-5.モデル構築
Tensorflowを用いてモデルを構築していきます。
CNN(畳み込みニューラルネットワーク)とは、人間の脳の視覚野と似た構造を持つ 「畳み込み層」 という層を使って特徴抽出を行うニューラルネットワークです。
畳み込み層は全結合層とは違い2次元のままの画像データを処理し特徴の抽出が行えるため、線や角といった 2次元的な特徴を抽出するのに優れています。
またCNNでは多くの場合、畳み込み層と共に「プーリング層」という層が使われます。プーリング層は畳み込み層の出力を縮約しデータの量を削減する層であり、最終的に画像の分類などを行います。
参考として下記にCNN構造である畳み込み層とプーリング層を示します。
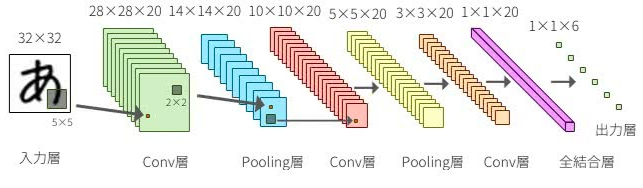
TensorFlowでは、まずモデルを管理するインスタンスを作り、addメソッドで層を一層ずつ定義していきます。
# TensorFlowでモデル作成
# model(活性化関数にReLUを使うモデル)の定義
model = Sequential()
model.add(Conv2D(input_shape=(64, 64, 3), #Conv2DはCNN畳み込み層、input_shapeは64×64。チャンネル数はカラーでRGBの3
filters=20, #生成する特徴マップの数
kernel_size=(3, 3), #カーネル(畳み込みに使用する重み行列)の大きさ
strides=(1, 1), #カーネルを動かす距離
padding="same")) #sameで出力される特徴マップが入力のサイズと一致するように入力画像の周囲にピクセルを追加
model.add(BatchNormalization()) #バッチ正規化
model.add(Activation('relu')) #活性化関数ReLU
model.add(Conv2D(filters=20, #CNN畳み込み層
kernel_size=(3, 3),
strides=(1, 1),
padding="same"))
model.add(BatchNormalization()) #バッチ正規化
model.add(Activation('relu')) #活性化関数ReLU
model.add(MaxPooling2D(pool_size=(2, 2))) #MAXプーリングでデータ削減
model.add(Dropout(rate=0.5)) #Dropoutで過学習防止。0.5でユニットを5割減
model.add(Conv2D(filters=20, #CNN畳み込み層
kernel_size=(3, 3),
strides=(1, 1),
padding="same"))
model.add(BatchNormalization()) #バッチ正規化
model.add(Activation('relu'))
model.add(Conv2D(filters=20, #CNN畳み込み層
kernel_size=(3, 3),
strides=(1, 1),
padding="same"))
model.add(BatchNormalization()) #バッチ正規化
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.5)) #Dropoutで過学習防止
model.add(Flatten()) #多次元のデータを全結合層に入力するため、データを一次元に平滑化
model.add(Dense(512)) #512ユニットの全結合層
model.add(BatchNormalization()) #バッチ正規化
model.add(Activation('relu'))
model.add(Dropout(rate=0.5)) #Dropoutで過学習防止
model.add(Dense(256)) #256ユニットの全結合層
model.add(BatchNormalization()) #バッチ正規化
model.add(Activation('relu'))
model.add(Dropout(rate=0.5)) #Dropoutで過学習防止
model.add(Dense(6)) #SUV車種6クラスの分類なので今回は6とする
model.add(Activation('softmax')) #活性化関数
def my_cross_entropy(y_true, y_pred): #loss損失関数の設定
loss = tf.keras.losses.categorical_crossentropy(y_true, y_pred, label_smoothing=0.1)
return loss
sgd = optimizers.SGD(lr=0.1)
model.compile(optimizer='sgd', #sgd or adam or adadelta
loss=my_cross_entropy, #'categorical_crossentropy' or my_cross_entropy
metrics=['accuracy'])
3-6.学習実施
構築したモデルに訓練データと検証データを渡して学習します。
# モデル学習
history = model.fit(X_train, y_train, batch_size=32, epochs=150, validation_data=(X_val, y_val))
print('')
3-7.モデル精度確認
構築したモデルを定量的に評価します。
機械学習の評価指標として以下4つがあります。
正解率(accuracy)
精度(適合率, Precision)
再現率(Recall)
F値(F-measure)
今回は画像分類なので正解率で評価していきます。
# 評価
scores = model.evaluate(X_val, y_val, verbose=0)
print('scores : 汎化精度(新規データに対する精度)_損失関数の値と正解率')
print(scores)
print('') #コンソールに空白行を追加
print('') #コンソールに空白行を追加
scores2 = model.evaluate(X_test, y_test, verbose=0)
print('scores2 : 学習に使用していない画像データ45枚でモデルの検証_損失関数の値と正解率')
print(scores2)
print('')
# 予測
predictions = model.predict(X_test)
results = predictions.argmax(axis=1)
answers = y_test.argmax(axis=1)
print('モデル確認用データ45枚について予測')
print('予測値の結果')
print(results)
print('予測値に対する答え')
print(answers)
print('')
# 精度の可視化(グラフ化)
print('精度の可視化')
plt.plot(history.history['accuracy'], label='acc', ls='-', marker='o') #ラベル名とマーカーの設定
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-', marker='x')
plt.title('Model Evaluaton', fontsize=14) #グラフタイトルとフォント指定
plt.xlabel('epoch') #x軸の名前
plt.ylabel('accuracy') # y軸の名前
plt.legend(['acc', 'val_acc']) #グラフに凡例追加
plt.grid(color='gray', alpha=0.1) #縦軸のメモリ設定
plt.show() #グラフ化
plt.plot(history.history['loss'], label='loss', ls='-', marker='o')
plt.plot(history.history['val_loss'], label='val_loss', ls='-', marker='x')
plt.title('Model Evaluaton', fontsize=14)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['loss', 'val_loss'])
plt.grid(color='gray')
plt.show()
こちらは可視化のコンソール出力結果です。
学習150回の結果です。
Epoch 150/150
611/611 [==============================] - 6s 10ms/step - loss: 0.7336 - accuracy: 0.8695 - val_loss: 1.4143 - val_accuracy: 0.5752
scores : 汎化精度(新規データに対する精度)_損失関数の値と正解率
[1.414254069328308, 0.5752449035644531]
scores2 : 学習に使用していない画像データ45枚でモデルの検証_損失関数の値と正解率
[1.3084768056869507, 0.644444465637207]
モデル確認用データ45枚について予測
予測値の結果
[0 0 0 0 0 5 0 0 0 3 4 5 1 5 5 5 5 1 1 4 2 2 2 2 4 5 0 3 3 0 3 3 3 3 4 4 5
4 0 4 5 5 5 5 1]
予測値に対する答え
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 3 3 3 3 4 4 4
4 4 4 5 5 5 5 5]
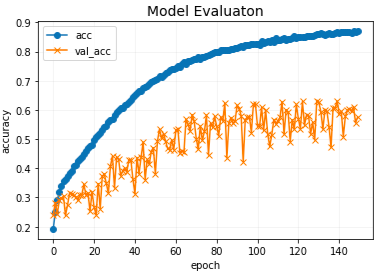
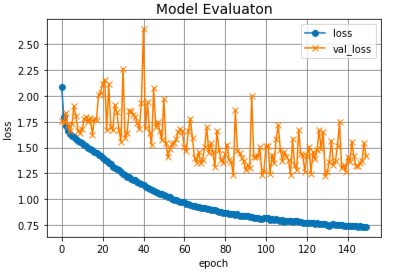
150回学習(epochs=150)を行いました。あまり良い結果とはならず、正解率はグラフ内のval_accから約55%と言ったところでしょうか。上記の1つ目のグラフより、acc(学習データの正解率)に対してval_acc(検証データの正解率)の乖離が大きいため、過学習を起こしているようです。上記の2つ目のグラフより、損失関数の値も大きいままです。
3-8.転移学習でのトライ
うまく分類できないモデルを構築したということで転移学習にもチャレンジしてみます。
転移学習とは:学習済みのモデルを使って新たなモデルの学習を行うこと。
TensorFlowでは、ImageNet(120万枚,1000クラスからなる巨大な画像のデータセット)で学習した画像分類モデルとその重みをダウンロードし、使用できます。その中からVGG16というモデルを使用してみます。
ここからは転移学習を行った際の全コードです。
VGG16の後に私が作ったモデルを結合して確認します。
from google.colab import drive
drive.mount('/content/drive')
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow import keras
from tensorflow.keras.layers import Activation, Conv2D, Dense, Dropout, Flatten, MaxPooling2D, BatchNormalization, Input
from tensorflow.keras.models import Sequential, load_model, Model
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import optimizers
from sklearn.model_selection import train_test_split
from tensorflow.keras.applications.vgg16 import VGG16
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
import glob
import tensorflow as tf
# 画像データを6個のフォルダから読み込む。データセットの作成。
#(6クラス = ['01_Jeep_Output2', '02_FJcruiser_Output2', '03_Jimny_Output2' '04_Mersedes_G_Output2', '05_Landcruiser60_Output2', '06_Landcruiser40_Output2'])
# 画像データの読み込み、画像サイズ調整、Numpy配列化してX、Yに追加
folder_train = ["01_Jeep_Output_Train", "02_FJcruiser_Output_Train", "03_Jimny_Output_Train", "04_Mersedes_G_Output_Train","05_Landcruiser60_Output_Train", "06_Landcruiser40_Output_Train"]
folder_val = ["01_Jeep_Output_Val", "02_FJcruiser_Output_Val", "03_Jimny_Output_Val", "04_Mersedes_G_Output_Val","05_Landcruiser60_Output_Val", "06_Landcruiser40_Output_Val"]
folder = ["01_Jeep", "02_FJcruiser", "03_Jimny", "04_Mersedes_G","05_Landcruiser60", "06_Landcruiser40"]
image_size = 64 #画像サイズ変更値
#学習データの前処理
X_train = [] #空のリスト
y_train = [] #空のリスト
for index, suv_name in enumerate(folder_train): #folder_trainからindexとフォルダ名を順番に取り出す
train_dir = "/content/drive/My Drive/SUV/Train/" + suv_name #画像ファイル保存先のディレクトリ(フォルダ)アドレス
files = glob.glob(train_dir + "/*.jpeg") #ディレクトリからjpegの全画像ファイルを読み込んでリスト化しfilesへ
print(files) #コンソールにファイル名を出力
for i, file in enumerate(files): #filesリストから順番に画像データをfileとして取り出す
image = Image.open(file) #画像データfileを開いてimageへ
image = image.convert("RGB") #カラーに変換
image = image.resize((image_size, image_size)) #写真のサイズを変更
data = np.asarray(image) #Numpy配列に変換してdataへ
X_train.append(data) #Numpy配列の画像データ(data)をリストXへ追加
y_train.append(index) #folderのindex(ラベル)をリストYへ追加
X_train = np.array(X_train) #Numpy配列に変換
y_train = np.array(y_train) #Numpy配列に変換
#画像データをfloat32型にし、0から1の範囲に変換
X_train = X_train.astype('float32')
X_train= X_train / 255.0
# 正解ラベルの形式をone hotエンコーディング
y_train = to_categorical(y_train)
#検証データの前処理
X_val = [] #空のリスト
y_val = [] #空のリスト
for index, suv_name in enumerate(folder_val): #folder_valからindexとフォルダ名を順番に取り出す
val_dir = "/content/drive/My Drive/SUV/Validation/" + suv_name #画像ファイル保存先のディレクトリ(フォルダ)アドレス
files = glob.glob(val_dir + "/*.jpeg") #ディレクトリからjpegの全画像ファイルを読み込んでリスト化しfilesへ
print(files) #コンソールにファイル名を出力
for i, file in enumerate(files): #filesリストから順番に画像データをfileとして取り出す
image = Image.open(file) #画像データfileを開いてimageへ
image = image.convert("RGB") #カラーに変換
image = image.resize((image_size, image_size)) #写真のサイズを変更
data = np.asarray(image) #Numpy配列に変換してdataへ
X_val.append(data) #Numpy配列の画像データ(data)をリストXへ追加
y_val.append(index) #folderのindex(ラベル)をリストYへ追加
X_val = np.array(X_val) #Numpy配列に変換
y_val = np.array(y_val) #Numpy配列に変換
#画像データをfloat32型にし、0から1の範囲に変換
X_val = X_val.astype('float32')
X_val= X_val / 255.0
# 正解ラベルの形式をone hotエンコーディング
y_val = to_categorical(y_val)
#テストデータの前処理
X_test = [] #空のリスト
y_test = [] #空のリスト
for index, suv_name in enumerate(folder): #folderからindexとフォルダ名を順番に取り出す
test_dir = "/content/drive/My Drive/SUV/Test/" + suv_name #画像ファイル保存先のディレクトリ(フォルダ)アドレス
files = glob.glob(test_dir + "/*.jpeg") #ディレクトリからjpegの全画像ファイルを読み込んでリスト化しfilesへ
print(files) #コンソールにファイル名を出力
for i, file in enumerate(files): #filesリストから順番に画像データをfileとして取り出す
image = Image.open(file) #画像データfileを開いてimageへ
image = image.convert("RGB") #カラーに変換
image = image.resize((image_size, image_size)) #写真のサイズを変更
data = np.asarray(image) #Numpy配列に変換してdataへ
X_test.append(data) #Numpy配列の画像データ(data)をリストXへ追加
y_test.append(index) #folderのindex(ラベル)をリストYへ追加
X_test = np.array(X_test) #Numpy配列に変換
y_test = np.array(y_test) #Numpy配列に変換
#画像データをfloat32型にし、0から1の範囲に変換
X_test = X_test.astype('float32')
X_test = X_test / 255.0
# 正解ラベルの形式をone hotエンコーディング
y_test = to_categorical(y_test)
# 学習データ、検証データ、モデル確認用データの表示(確認用)
#print('')
#print('X_train')
#print(X_train) #学習データ
#print('')
#print('X_val')
#print(X_val) #検証データ
#print('')
#print('y_train')
#print(y_train) #学習データ用正解ラベル
#print('')
#print('y_val')
#print(y_val) #検証データ用正解ラベル
#print('')
#print('X_test')
#print(X_test) #モデル確認用データ
#print('')
#print('y_test')
#print(y_test) #モデル確認用データ正解ラベル
#print('')
# データセットの個数を表示
print(X_train.shape, 'X_train samples')
print(X_val.shape, 'X_val samples')
print(y_train.shape, 'y_train samples')
print(y_val.shape, 'y_val samples')
print(X_test.shape, 'X_test samples')
print(y_test.shape, 'y_test samples')
print('')
#ImageDataGeneraterを使って水増し
datagen = ImageDataGenerator(width_shift_range=0.1, #ランダムに水平方向に平行移動する、画像の横幅に対する割合
height_shift_range=0.1, #ランダムに垂直方向に平行移動する、画像の縦幅に対する割合
zoom_range=0.3, #ランダムに画像を圧縮、拡大させる割合。
horizontal_flip=True, #Trueを指定すると、ランダムに水平方向に反転。
vertical_flip=True, #Trueを指定すると、ランダムに垂直方向に反転。
samplewise_center=True, samplewise_std_normalization=True, #標準化。個々の特徴を平均0、分散1にすることで、特徴ごとのデータの分布を近づける手法。
featurewise_center=True, zca_whitening=True,
channel_shift_range=100,
rotation_range=20.0, #ランダムに回転する回転範囲(単位degree)
)
datagen.fit(X_train) #X_trainデータにImageDataGeneraterを適用
#Tensorのデータセットを転移学習を用いて分類します。
#input_tensorを定義
input_tensor = Input(shape=(64, 64, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) #多次元のデータを全結合層に入力するため、データを一次元に平滑化
top_model.add(Dense(512)) #512ユニットの全結合層
top_model.add(BatchNormalization()) #バッチ正規化
top_model.add(Activation('relu'))
top_model.add(Dropout(rate=0.5)) #Dropoutで過学習防止
top_model.add(Dense(256)) #256ユニットの全結合層
top_model.add(BatchNormalization()) #バッチ正規化
top_model.add(Activation('relu'))
top_model.add(Dropout(rate=0.5)) #Dropoutで過学習防止
top_model.add(Dense(6)) #SUV車種6クラスの分類なので今回は6とする
top_model.add(Activation('softmax')) #活性化関数
# vgg16とtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 19層目までの重みをfor文を用いて固定
for layer in model.layers[:19]:
layer.trainable = False
def my_cross_entropy(y_true, y_pred):
loss = tf.keras.losses.categorical_crossentropy(y_true, y_pred, label_smoothing=0.1)
return loss
sgd = optimizers.SGD(lr=0.1)
model.compile(optimizer='sgd', #sgd or adam or adadelta
loss=my_cross_entropy, #'categorical_crossentropy' or my_cross_entropy
metrics=['accuracy'])
# モデル学習
history = model.fit(X_train, y_train, batch_size=32, epochs=150, validation_data=(X_val, y_val))
print('')
# 評価
scores = model.evaluate(X_val, y_val, verbose=0)
print('scores : 汎化精度(新規データに対する精度)_損失関数の値と正解率')
print(scores)
print('') #コンソールに空白行を追加
print('') #コンソールに空白行を追加
scores2 = model.evaluate(X_test, y_test, verbose=0)
print('scores2 : 学習に使用していない画像データ45枚でモデルの検証_損失関数の値と正解率')
print(scores2)
print('')
# 予測
predictions = model.predict(X_test)
results = predictions.argmax(axis=1)
answers = y_test.argmax(axis=1)
print('モデル確認用データ45枚について予測')
print('予測値の結果')
print(results)
print('予測値に対する答え')
print(answers)
print('')
# 精度の可視化(グラフ化)
print('精度の可視化')
plt.plot(history.history['accuracy'], label='acc', ls='-', marker='o')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-', marker='x')
plt.title('Model Evaluaton', fontsize=14)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['acc', 'val_acc'])
plt.grid(color='gray', alpha=0.1)
plt.show()
plt.plot(history.history['loss'], label='loss', ls='-', marker='o')
plt.plot(history.history['val_loss'], label='val_loss', ls='-', marker='x')
plt.title('Model Evaluaton', fontsize=14)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['loss', 'val_loss'])
plt.grid(color='gray')
plt.show()
こちらがコンソールの出力結果です。
訓練データ、検証データ、テストデータの総数です。
(19527, 64, 64, 3) X_train samples
(5615, 64, 64, 3) X_val samples
(19527, 6) y_train samples
(5615, 6) y_val samples
(45, 64, 64, 3) X_test samples
(45, 6) y_test samples
VGG16の読み込み結果です。
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58892288/58889256 [==============================] - 0s 0us/step
58900480/58889256 [==============================] - 0s 0us/step
150回学習後の結果です。
Epoch 150/150
611/611 [==============================] - 9s 15ms/step - loss: 0.5488 - accuracy: 0.9798 - val_loss: 1.4932 - val_accuracy: 0.5154
scores : 汎化精度(新規データに対する精度)_損失関数の値と正解率
[1.4931787252426147, 0.5154051780700684]
scores2 : 学習に使用していない画像データ45枚でモデルの検証_損失関数の値と正解率
[1.52700936794281, 0.4888888895511627]
モデル確認用データ45枚について予測
予測値の結果
[4 0 0 5 1 5 0 1 0 3 3 2 1 3 0 1 1 4 3 1 2 1 2 2 3 0 5 0 0 3 3 3 4 3 4 4 4
5 0 4 5 5 5 1 1]
予測値に対する答え
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 3 3 3 3 4 4 4
4 4 4 5 5 5 5 5]
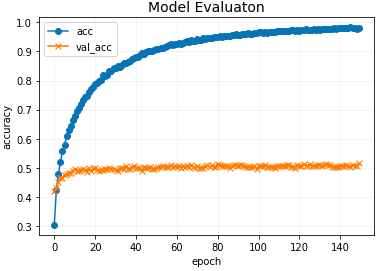
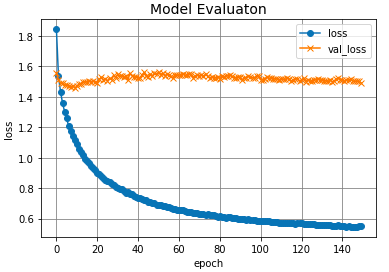
グラフはばらつきが少なくて綺麗なのですが、上記1つ目のグラフより、正解率は50%程度で収束しているように見えます。また、やはりこちらも過学習を起こしています。要対策。。。
3-9.苦労した点
結局、分類としてはうまくいかず。。(正解率90%が目標でした。)ここのところは今後も何が問題なのか探って行きます(チューニングが難しいですね)。あとは1から画像分類をやるとなるとデータを用意するところが大変ですね。データをネットから大量にとればいいかと思っているとサイトの利用規約に反してしまうため、データ収集が難しいと感じました。
4.感想
今回、自分で1からデータを集めてCNNの画像分類をやってみて、プログラミングの楽しさを実感しました。何が楽しかったかは以下2点です。
1.自分自身でシステムを構築することが出来る点。
2.チューニング次第で結果が良くなる点。
今後もチューニング等のスキル向上させて仕事に取り入れて行きたいですね。
あとは無料でデータを提供するサイトがあると楽しいですね。。。
もちろん、これからも人口知能の勉強を継続していくつもりです。