MirroredStrategy
TensorFlowの計算を複数GPUで行いたいと思い、実装方法を調べていたけど、なかなか大変そう。そんな中、もとのコードをほとんど変更することなく複数GPU処理を可能にするAPIを知りました。
- https://www.youtube.com/watch?v=bRMGoPqsn20
- https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/distribute
- https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/MirroredStrategy
まだ開発中なので、今後機能が追加されたり、仕様が変更になったりすると思いますが、とりあえずはと思い試してみたので、それに関するレポートです。
以下に、MNISTでの実装例をおいています。
https://github.com/shu-yusa/tensorflow-mirrored-strategy-sample
MirroredStrategyの組み込み
EstimatorへのMirroredStrategyの設定
https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/MirroredStrategy
で述べられているように、MirroredStrategyの組み込みは、少ない変更で行えます。すなわち、MirroredStrategyのインスタンスを生成して、tf.estimator.RunConfig経由でEstimatorに渡すだけです。
distribution = tf.contrib.distribute.MirroredStrategy()
config = tf.estimator.RunConfig(train_distribute=distribution)
classifier = tf.estimator.Estimator(model_fn=model_fn, config=config)
MirroredStrategyのコンストラクタには、device引数に使用するデバイスを配列で、またはnum_gpus引数で使用するGPU数を指定することができます。指定しない場合は自動で検出されます。
現時点では、num_gpuに1を指定するとエラーになりました。2以上を指定する必要があるようです。
input_fnの返り値をDatasetにする
もとのMNISTのチュートリアルコードでは、tf.estimator.Estimator.train()のinput_fn引数に、tf.estimator.inputs.numpy_input_fnを使用していますが、MirroredStrategyを使用する場合、input_fnはtf.data.Datasetを返さなければならないようです。実際numpu_input_fnのまま実行すると、
ValueError: dataset_fn() must return a tf.data.Dataset when using a DistributionStrategy.
というエラーが出ます。上述のサンプルコードでは、以下のようにDatasetに直して返すように変更しています。
class InputFnProvider:
def __init__(self, train_batch_size):
self.train_batch_size = train_batch_size
self.__load_data()
def __load_data(self):
# Load training and eval data
mnist = tf.contrib.learn.datasets.load_dataset("mnist")
self.train_data = mnist.train.images # Returns np.array
self.train_labels = np.asarray(mnist.train.labels, dtype=np.int32)
self.eval_data = mnist.test.images # Returns np.array
self.eval_labels = np.asarray(mnist.test.labels, dtype=np.int32)
def train_input_fn(self):
"""An input function for training"""
# Shuffle, repeat, and batch the examples.
dataset = tf.data.Dataset.from_tensor_slices(({"x": self.train_data}, self.train_labels))
dataset = dataset.shuffle(1000).repeat().batch(self.train_batch_size)
return dataset
def eval_input_fn(self):
"""An input function for evaluation or prediction"""
dataset = tf.data.Dataset.from_tensor_slices(({"x": self.eval_data}, self.eval_labels))
dataset = dataset.batch(1)
return dataset
# (中略)
# Train the model
mnist_classifier.train(
input_fn=input_fn_provider.train_input_fn,
steps=10000)
# Evaluate the model and print results
eval_results = mnist_classifier.evaluate(input_fn=input_fn_provider.eval_input_fn)
ちなみに、返り値のところを
return dataset.make_one_shot_iterator().get_next()
とした場合もエラーになります。
バッチサイズの変更
以下で述べられているように、現時点では、GPU数に合わせてバッチサイズを変更する(バッチサイズをGPU数で割る)必要があるようです。最初これに気づかず、並列しても計算時間が減らなくて悩みました。
- https://github.com/tensorflow/models/blob/master/official/resnet/resnet_run_loop.py
- https://github.com/tensorflow/models/blob/master/official/utils/misc/distribution_utils.py
計算実行例
実際にGeForce GTX 1080を使用して計算した結果を以下に示します。
まずは、GPU使用率です。MirroredStrategyを使用しない場合:

MirroredStrategyを使用した場合:
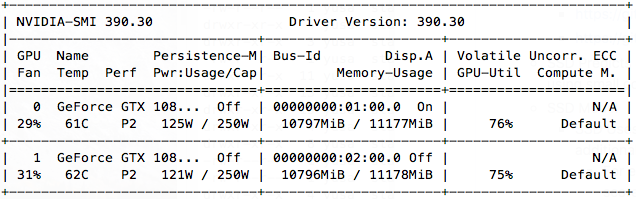
ちゃんと複数GPUが計算に使われているようです。
10000ステップ計算した際の計算時間を以下に示します。
| GPU数 | Batch Size | Accuracy | Time |
|---|---|---|---|
| 1 | 100 | 0.9511 | 68.0 sec |
| 2 | 50 | 0.9515 | 90.6 sec |
遅くなってる😇
残念ながらこのコードでは速くなりませんでした。別の、もっと複雑なネットワークで計算した場合は速くなったので、このMNISTのコードだとオーバヘッドの方が多いのかもしれないです。
まとめ
新しく開発中のMirroredStrategyを使って、複数GPU計算を試してみました。まだ、開発途上と感じられる部分が多く、使う際は注意が必要でした。しかし、これが実現すると、複数GPU計算の実装がかなり簡単に行えそうなので、要注目です。