本記事は「文字列アルゴリズム Advent Calendar 2017」の20日目の記事です.
10日目の記事では @tsukasa_diary 氏によって BDD/ZDD が紹介されましたが,その記事の最後でちらりとふれられている文字列版の Decision Diagram の紹介をしたいと思います.定義などはできるだけ踏襲していきます.
Sequence Binary Decision Diagram
Sequence Binary Decision Diagram (SeqBDD, 系列二分決定グラフ) は 非巡回決定性有限オートマトン (Acyclic Deterministic Finite Automata; ADFA) と BDD の間のようなデータ構造で,有限長文字列の有限集合を表現します.全順序が定義されたアルファベット $\mathit{\Sigma}$ 上の文字列集合を表す SeqBDD $\mathcal{S}$ は,ノード集合 $N$ と根ノード $r$ に 3 つの写像 $\ell$, $c_0$, $c_1$ を用いて $\mathcal{S} = (\mathit{\Sigma}, N, r, \ell, c_0, c_1)$ と定義することができます,根ノードは省略されることもあります.SeqBDD では全てのノードがそれぞれなんらかの文字列集合に対応しており,ノード $v$ が表す文字列集合を $L(v)$ と書くことにします.ノード集合 $N$ には終端と呼ばれる 2 つの特殊なノード $\top$ と $\bot$ が含まれています.$\top$/$\bot$ はオートマトンでいうところの出次数 0 の受理状態/非受理状態に相当します.終端以外のノードは内部ノードと呼ばれます.写像 $\ell \colon N \setminus \{\top, \bot\} \rightarrow \Sigma$ は各内部ノードに文字をラベルづけするものです.SeqBDD では辺にではなくノードにラベルがついていることに注意してください.また,SeqBDD の内部ノード $v$ は 0-エッジおよび 1-エッジと呼ばれるエッジを 1 つずつもち,それらの辺が向かう先にあるノードを $v$ の 0-子および 1-子と呼びます.写像 $c_b \colon N \setminus \{\bot, \top\} \rightarrow N$ は各内部ノードの b-子をただ 1 つ定めます.ただし,制約として自らの祖先を子にもってはならず(つまり非巡回),また $\forall v \in N \setminus \{\bot, \top\}, \ell(v) < \ell(c_0(v))$ が成り立っていなければなりません.よって,SeqBDD では任意のノードから辺を可能な限り辿っていくと $\bot$ もしくは $\top$ の終端に行き着きます.本記事の図では 0-エッジを点線,1-エッジを実線で表します.例として文字列集合 $S = \{\mathtt{baa}, \mathtt{bab}, \mathtt{bac}, \mathtt{bcb}, \mathtt{bcc}, \mathtt{cb}, \mathtt{cc} \}$ を表す SeqBDD の図を以下に示します.
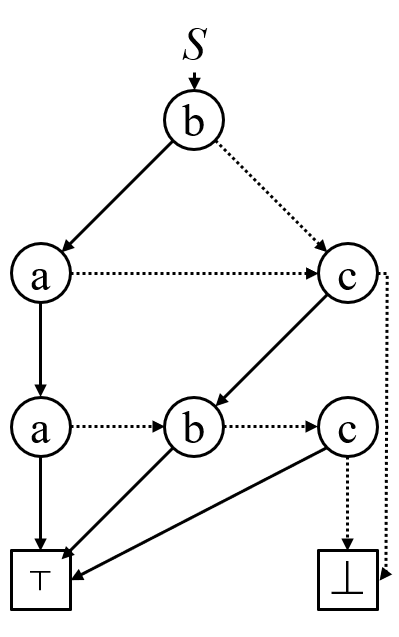
長さ $2k + 1$ でノードと 0, 1 が交互に現れる列 $\pi = (\pi_1, b_1, \ldots, \pi_k, b_k, \pi_{k + 1}) \in (N \times \{0, 1\})^k \times N$ について,$\forall j \in \{1, \ldots, k\}, c_{b_j}(\pi_j) = \pi_{j+1}$ であるとき,$\pi$ を $\mathcal{S}$ 上のパスと呼びます.あるパス $(\pi_1, b_1, \ldots, \pi_k, b_k, \pi_{k + 1})$ の $\pi_{k+1} = \top$ であるとき,そのパスは文字列 $\ell(\pi_1)^{b_1} \cdots \ell(\pi_k)^{b_k}$ を表しているという.この文字列の長さは $k$ 以下であることに注意.ここでノード $u$ からノード $v$ にいたる全てのパスの集合を $\mathit{PATH}(u, v)$ とすると,ノード $u$ が表す文字列集合 $L(u)$ とは $\mathit{PATH}(u, \top)$ に含まれる全てのパスが表す文字列からなる集合と等しい.
これだけではピンとこないかもしれないので,ある文字列集合に対する SeqBDD の構築方法を二通りの方向から示してみます.
ADFA からSeqBDD へ
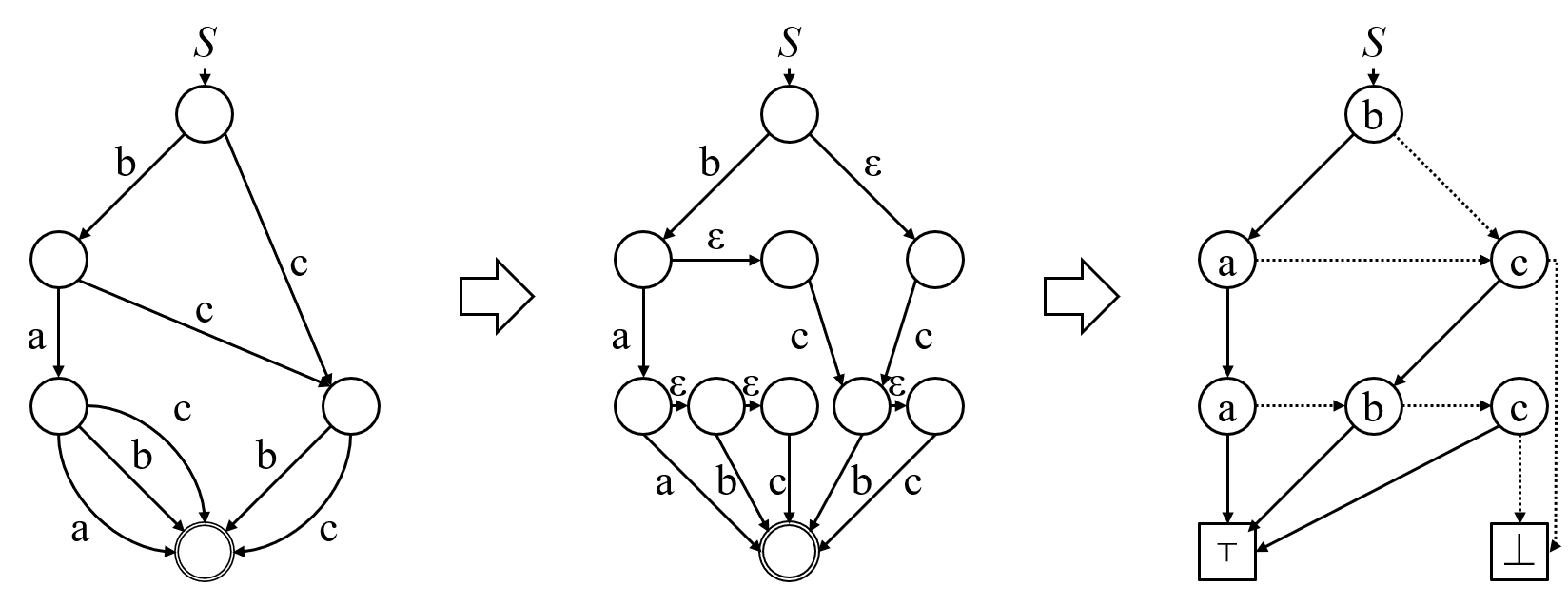
ADFA が与えられたときに,以下のような手順で SeqBDD に変換することができます.
- ADFA を binarize する: 複数の遷移をもつ状態を 1 つのラベル付き遷移と高々 1 つの $\varepsilon$-遷移しかもたない状態に分割する.元々 1 つの状態だったものが $\varepsilon$-遷移でつながった複数の状態となる.ただし,$\varepsilon$-遷移でつながった状態を先頭からみていったときにラベル付き遷移における文字が昇順に出現するようにする.
- Edge-labeled から node-labeled にする: 各状態は高々 1 つしかラベル付き遷移をもたないので,遷移ではなく状態にラベルをつけ SeqBDD ノードにする.このときにラベル付き遷移だったものを 1-エッジ,$\varepsilon$-遷移だったものを 0-エッジとする.また,出次数 0 の状態を SeqBDD の終端に変更する.受理状態だった場合は $\top$,非受理状態だった場合は $\bot$ へ.
- 最小化: 同じ文字列集合を表すノードを 1 つにまとめて最小化する.ADFA においては別の状態からの遷移であったノードでも SeqBDD では共有できる場合がある.
これを図にしたものが以下になります.
オートマトンでは遷移にラベルがついており,SeqBDD ではノードにラベルがついているのでそれぞれのサイズを遷移の個数,非終端ノードの個数として定義すると,SeqBDD のサイズは同じ文字列集合を表現する ADFA より必ず小さく,最良で $O(\mathit{\Sigma})$ 倍小さくなることが知られています.ただ実際には,SeqBDD は 1 節点あたり 2 つのポインタをもつので結構メモリが要ります.
文字列集合の分割から SeqBDD へ
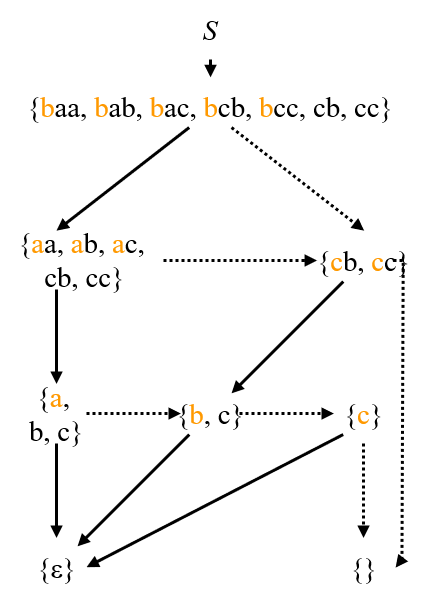
文字列集合 $S$ が与えられたときに,以下のような $S_1$ と $S_0$ に分解します.ただし,$\mathit{minhead}(S) = \min\{a \mid as \in S, a \in \mathit{\Sigma}, s \in \mathit{\Sigma}^*\}$ とします.
$S_1 = \{s \mid as \in S, a = \mathit{minhead}(S) \}$, $S_0 = S \setminus \mathit{minhead}(S) \cdot S1$
つまり $S_1$ は辞書順最小の先頭文字をもつ文字列集合を取り出して先頭文字を除去したもの,$S_0$ はそれ以外の先頭文字から始まる文字列の集合です.文字列版の Shanon 分解のようなものです.与えられた文字列集合に対してこの分解を再帰的に繰り返し行うことで,その文字列集合を表現するために必要な SeqBDD を求めることができます.
上図の SeqBDD に対応する文字列集合分解は 以下になります.
SeqBDD の特徴
ここまで読んでくれた人の中には「結局,SeqBDD って構造に制約をつけただけのオートマトンでは?」と思った人もいるかもしれません.そしてそれは概ね正しいです.ただ,文字列集合を表す構造としてはオートマトンと大きく変わりませんが,"SeqBDD" と言うときには Decision Diagram 系から受け継いだハッシュテーブルの技法を伴って実装されていることが強く意識されます.その技法とは,
- 複数の SeqBDD 間でのノード共有: SeqBDD ではハッシュテーブルを用いてあるラベル,0-子,1-子の 3 つ組を持つようなノードが既に存在しているかどうかを管理しています.これはもし同じ 3 つ組を持つようなノードが複数存在した場合,それらは同じ文字列集合を表現するものになってしまうため,そういった冗長なノードを生成しないようにするためです.さらに,複数の SeqBDD を同時に扱いたい場合でもこのハッシュテーブルはメモリ上に 1 つしか持たないようにします.そうすることで異なる SeqBDD の間でも等価なノードが必要になった場合はノードを共有することが自然と可能になりメモリ効率がよくなります.
- 複数の SeqBDD 間での演算結果の共有: SeqBDD では BDD や ZDD と同様に表している文字列集合に関して種々の演算を実行することができます.ごく基本的なところだと,和集合,積集合,差集合を求める演算があり,他にも発展的な演算が色々あります.これらの演算の多くは SeqBDD のノードを引数にとり,与えられた SeqBDD を再帰的にくだっていく(文字列集合の分解に相当)ことで所望の SeqBDD をボトムアップに構築していきます.SeqBDD ではある演算 $\mathit{op}$ を引数 $\mathit{args} \in N^*$ に対して実行したときの結果をハッシュテーブルに入れて記憶していきます.これにより一度行った計算を何度も繰り返す必要がなくなります.さらに,この演算結果をメモしておくハッシュテーブルもメモリ上に 1 つしか持たないようにすることで,ある SeqBDD $\mathcal{S_1}$ に対して行った演算 $\mathit{op}$ の途中結果を別の SeqBDD $\mathcal{S_2}$ に対し $\mathit{op}$ を実行するときにも再利用することができるようになります.
上記のハッシュテーブルに基く技法は特に同じような文字列集合を複数同時に扱いたいときに効果を発揮します.たくさんの文字列集合に対して何度も演算を繰り返すなど,動的な計算を多く行いたい場合には SeqBDD は有効な選択肢の一つとなるでしょう.
SeqBDD のデメリット
とは言いましても,SeqBDD にも色々デメリットはあります.
- 検索の遅さ: ノードごとに 1 文字ずつしかラベルをもっていないのである文字を探すには 0-エッジを何度も辿らなくてはなりません.文字列 $s \in \mathit{\Sigma}$ を検索するのにかかる最悪時間計算量は $O(|\mathit{\Sigma}||s|)$ です.簡潔データ構造を用いることでメモリ使用量を削減しつつ,検索を $O(|s|)$ で行う手法もありますが,動的な演算を行うことが困難になります.ただ,通常の SeqBDD と簡潔版の SeqBDD を併用する Hybrid 手法も存在します.
- メモリ使用量: とにかくポインタを使用しまくる上に,ハッシュテーブルもガンガン活用するのでとてもメモリを使います.
- 実用的な実装の大変さ: SeqBDD の多くの演算などはシンプルな再帰関数の形で記述ができるのでとても実装しやすいけれど,最も基礎となるノードの管理はなかなかに面倒くさい.SeqBDD では複数の SeqBDD 間でノードを共有するため,不用意にノードの属性を書き換えたりしてしまうと思わぬところで問題が発生する可能性があります.そこで SeqBDD では新しいノードが必要になるたびにそれ用のメモリを確保するのですが,そうするとすぐにメモリが足りなくなる一方でもう使わないノードもメモリ上に残ったままになってしまう.そのため不要になったノードを適宜回収し再利用するというガベージコレクションが必要になりますが,これをきちんと実装するのはかなり骨です.
SeqBDD で遊ぶ
色々言いましたが,せっかくなので SeqBDD で遊んでみたいと思います.SeqBDD は文字列集合に関する問題を雑でいいから解きたい場合などにはけっこう便利です.ここでは7日目の記事にあった数式の回文を列挙してみます.
基本的には動的計画法でやっていきます.$F[L, V]$ を式の値が $V$,最左項の値が $L$ である数式全てからなる文字列集合とします.この $F$ を $V = 1$ から $V = 999$ まで順番に求めていくのが方針になります.こうすると複数の SeqBDD において,このノードから先には式の値が $c$ の文字列しか入っていない,といったことが頻出しそうなので SeqBDD を使う嬉しさがありそうです.演算結果の共有についても同様.あまり自明な回文を出力してもつまらないので,①式の値も回文②各項は非回文③できれば乗算が入っていてほしい,というものを求めていきましょう.かなり簡単なコードで実現することができます.最高効率を求める必要がなくてパパッと文字列集合で遊びたいときには SeqBDD は便利.
雰囲気コード
for(V = 1; V < 1000; ++V) {
for(L = 1; L <= V; ++L) {
for(C = 1; C + S < 1000; ++C) {
Cstr = integer_to_string(C);
if(!is_palindrome(Cstr)) F[C, S + C] += Concat(SeqBDD(Cstr ++ "+"), F[L, V]);
}
for(C = 1; C * L + S - L < 1000; ++C) {
Cstr = integer_to_string(C);
if(!is_palindrome(Cstr)) F[C * L, C * L + S - L] += Concat(SeqBDD(Cstr ++ "*"), F[L, V]);
}
}
}
for(V = 1; V < 1000; ++V) {
Vstr = integer_to_string(V);
if(is_palindrome(Vstr)) {
for(L = 1; L < 1000; ++L) {
Result[V] += F[L, V];
}
}
output Result[V];
}
上では C っぽいコードを書いていますが,実際には GitHub で公開している Erlang で書かれた SeqBDD モジュールを使って計算しました.そして 1000 までは計算ができたのですが,出力の前処理をするところでなぜかメモリを食いまくるという事態が発生してしまったので半端な式の値の回文までしか得られていません.(問題が解決したら追記します)ということで得られた回文をいくつか紹介して終わりにしたいと思います.
-
13 + 56 + 75 + 98 = 242 = 89 + 57 + 65 + 31
1 から 9 までの全ての数字が出現するものの中で最短かつ辞書順最小 -
12 * 21 = 252 = 12 * 21
条件を満たすもののなかで乗算が現れる最小のもの
式の値が 333 以下でかつそれぞれの値において最短の回文のリスト
33 12+21=33=12+21 44 12+32=44=23+21 13+31=44=13+31 21+23=44=32+12 55 12+43=55=34+21 13+42=55=24+31 14+41=55=14+41 21+34=55=43+12 23+32=55=23+32 24+31=55=13+42 66 12+54=66=45+21 13+53=66=35+31 14+52=66=25+41 15+51=66=15+51 21+45=66=54+12 23+43=66=34+32 24+42=66=24+42 25+41=66=14+52 31+35=66=53+13 32+34=66=43+23 77 12+65=77=56+21 13+64=77=46+31 14+63=77=36+41 15+62=77=26+51 16+61=77=16+61 21+56=77=65+12 23+54=77=45+32 24+53=77=35+42 25+52=77=25+52 26+51=77=15+62 31+46=77=64+13 32+45=77=54+23 34+43=77=34+43 35+42=77=24+53 36+41=77=14+63 88 12+76=88=67+21 13+75=88=57+31 14+74=88=47+41 15+73=88=37+51 16+72=88=27+61 17+71=88=17+71 21+67=88=76+12 23+65=88=56+32 24+64=88=46+42 25+63=88=36+52 26+62=88=26+62 27+61=88=16+72 31+57=88=75+13 32+56=88=65+23 34+54=88=45+43 35+53=88=35+53 36+52=88=25+63 37+51=88=15+73 41+47=88=74+14 42+46=88=64+24 43+45=88=54+34 99 12+87=99=78+21 13+86=99=68+31 14+85=99=58+41 15+84=99=48+51 16+83=99=38+61 17+82=99=28+71 18+81=99=18+81 21+78=99=87+12 23+76=99=67+32 24+75=99=57+42 25+74=99=47+52 26+73=99=37+62 27+72=99=27+72 28+71=99=17+82 31+68=99=86+13 32+67=99=76+23 34+65=99=56+43 35+64=99=46+53 36+63=99=36+63 37+62=99=26+73 38+61=99=16+83 41+58=99=85+14 42+57=99=75+24 43+56=99=65+34 45+54=99=45+54 46+53=99=35+64 47+52=99=25+74 48+51=99=15+84 121 23+98=121=89+32 24+97=121=79+42 25+96=121=69+52 26+95=121=59+62 27+94=121=49+72 28+93=121=39+82 29+92=121=29+92 32+89=121=98+23 34+87=121=78+43 35+86=121=68+53 36+85=121=58+63 37+84=121=48+73 38+83=121=38+83 39+82=121=28+93 42+79=121=97+24 43+78=121=87+34 45+76=121=67+54 46+75=121=57+64 47+74=121=47+74 48+73=121=37+84 49+72=121=27+94 52+69=121=96+25 53+68=121=86+35 54+67=121=76+45 56+65=121=56+65 57+64=121=46+75 58+63=121=36+85 59+62=121=26+95 242 46+98+98=242=89+89+64 47+97+98=242=89+79+74 48+96+98=242=89+69+84 48+97+97=242=79+79+84 49+95+98=242=89+59+94 49+96+97=242=79+69+94 56+89+97=242=79+98+65 57+87+98=242=89+78+75 57+89+96=242=69+98+75 58+86+98=242=89+68+85 58+87+97=242=79+78+85 58+89+95=242=59+98+85 59+85+98=242=89+58+95 59+86+97=242=79+68+95 59+87+96=242=69+78+95 59+89+94=242=49+98+95 64+89+89=242=98+98+46 65+79+98=242=89+97+56 67+78+97=242=79+87+76 67+79+96=242=69+97+76 67+86+89=242=98+68+76 68+76+98=242=89+67+86 68+78+96=242=69+87+86 68+79+95=242=59+97+86 68+85+89=242=98+58+86 68+87+87=242=78+78+86 69+75+98=242=89+57+96 69+76+97=242=79+67+96 69+78+95=242=59+87+96 69+79+94=242=49+97+96 69+84+89=242=98+48+96 69+86+87=242=78+68+96 74+79+89=242=98+97+47 75+78+89=242=98+87+57 76+79+87=242=78+97+67 78+78+86=242=68+87+87 78+79+85=242=58+97+87 79+79+84=242=48+97+97 252 12*21=252=12*21 303 102+201=303=102+201 313 102+211=313=112+201 112+201=313=102+211 323 102+221=323=122+201 112+211=323=112+211 122+201=323=102+221 333 102+231=333=132+201 112+221=333=122+211 122+211=333=112+221 132+201=333=102+231本記事を書くにあたって久しぶりに Erlang 版の SeqBDD を触ったのですが,もし万が一 SeqBDD に興味をもって,さらに Erlang 版を使ってみたいという人がいたらモジュールの整備や演算の追加をするかもしれません.
参考文献
- Elsa Loekito, James Bailey, and Jian Pei. A binary decision diagram based approach for mining frequent subsequences, Knowledge and Information Systems, vol. 24(2), pp. 235–268, 2009.
- Shuhei Denzumi, Ryo Yoshinaka, Hiroki Arimura, and Shin-ichi Minato, Sequence binary decision diagram: Minimization, relationship to acyclic automata, and complexities of Boolean set operations, Discrete Applied Mathematics, vol. 212, pp. 61–80, 2016.