この記事の目的
- ネットで嫌なものを見なくて済むようにする
- 邪魔な広告を非表示にする(よくあるやつ)
- ニュースサイトで嫌なニュースだけ非表示にする(←特にこれ)
- 対象ブラウザ
- Google Chrome/Microsoft Edge(本記事で説明)
- Firefox, Operaとかでもできるらしい
- 対象ウェブサイト(リクエストあれば追加します)
- Googleニュース
- Yahoo! ニュース
- BBC News
- Gigazine
手っ取り早く読みたい方は、ここから読んでください。
背景
動機
ネットを見る時のストレスのかなりの部分は、「欲しい情報がない」ことよりも「欲しくない情報が見えすぎる」ことではないでしょうか。
特に、
- ぜんぜん要らない広告
- 悲しいニュース
など、自分にとってはけっこうストレスになってました。調子悪い時なんてもう・・・。だからって仕事上ネットを見ないわけにも行かず。
禅の修行とかしたら気にならなくなるかも(本気)ですが、ブラウザで簡単に設定できる方法があるので、良かったら見てってください。
UBOとは
オープンソースで開発されている広告ブロック用のブラウザー拡張機能です。
今回は、この機能を応用して「嫌なニュースを非表示にする」ようにしてみます。
※以前は同じような機能を持った「CustomBlocker」という拡張機能があったのですが、最近削除されてしまい、このタイミングで自分はUBOに引っ越しました。本記事はそのときのメモも兼ねてます。
他にも解説記事いっぱいあるけど?
既に素晴らしい記事が多々ありますが、いずれも今回の目的に応用しようとすると「高度すぎ」か「個別的すぎ」で、かゆい所に手が届きません。自分はこうなりました:
-
(Yahoo!ニュースへの応用)https://dsk.jp/ublock_ynews_filter/
よしGoogleニュースにも応用しよう・・・あれ?タグが合わない・・・ -
(公式)https://github.com/gorhill/uBlock/wiki/Resources-Library
しぬ。。。情報多すぎ。。。
まあ結局立ち直ったのですが、上の2つの間を埋めるような記事が日本語で見つけられなかったもので、メモついでに記事を書きました。
具体的な答え+どう考えたらそうなったのか、を示せればと思います。
初心者向けの解説(とりあえず使いたい!)
インストール
Chromeの拡張機能ストアでインストールしてください。
https://chrome.google.com/webstore/detail/ublock-origin/cjpalhdlnbpafiamejdnhcphjbkeiagm
僕は試してませんが、Chrome以外のブラウザにもインストールできるみたいです。
https://github.com/gorhill/uBlock
拡張機能ストアのページへ行くとこんな感じのが出てきますので、追加を押します。確認メッセージが出たらOKしていきましょう。
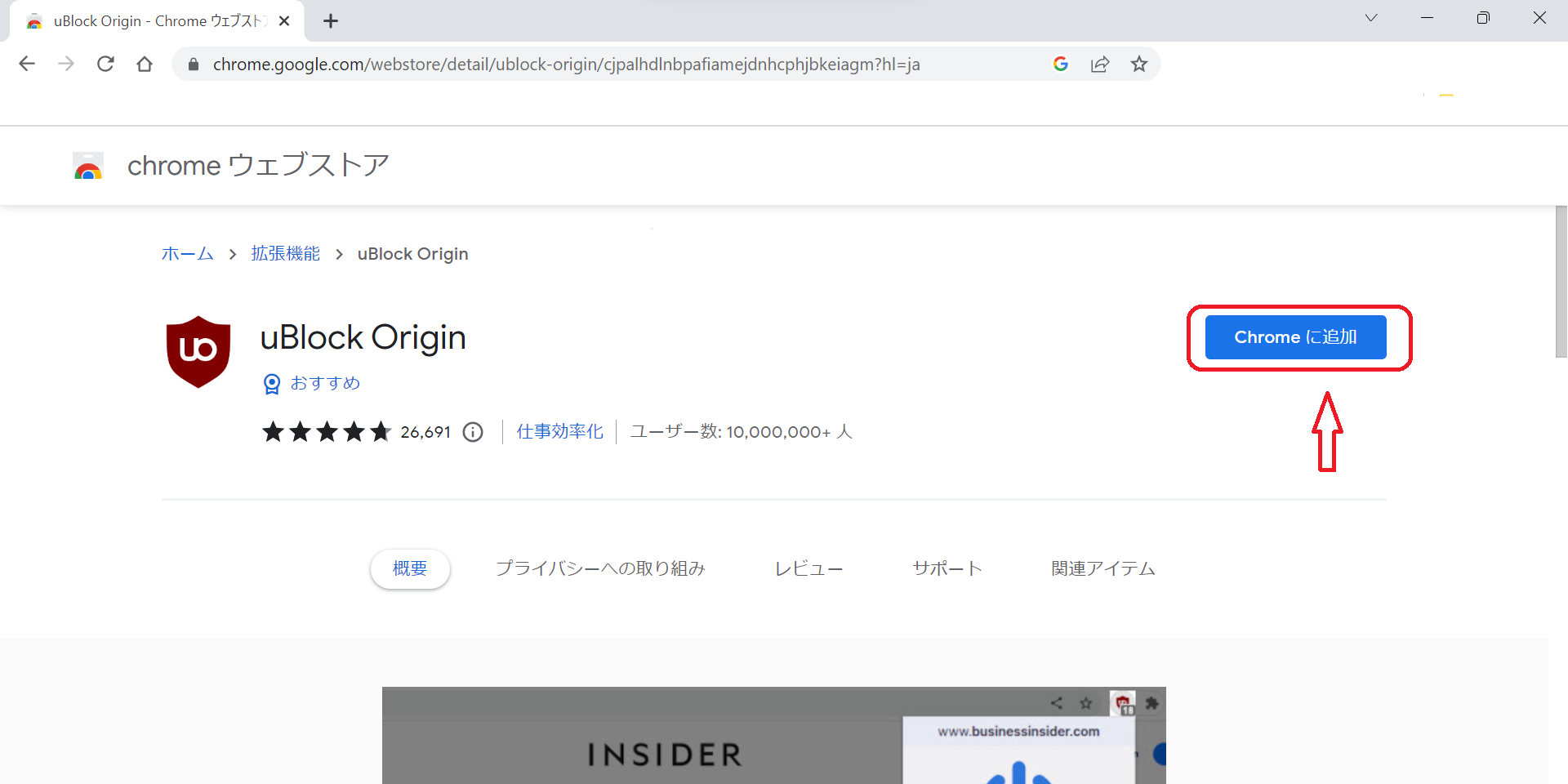
追加できたら、ジグソーパズルみたいな拡張機能アイコンをクリックし、"uBlock Origin"の横の虫ピンマークをクリックして青くなるようにします。こうすることで、uBlock Originのアイコンが常に表示されるようになります。
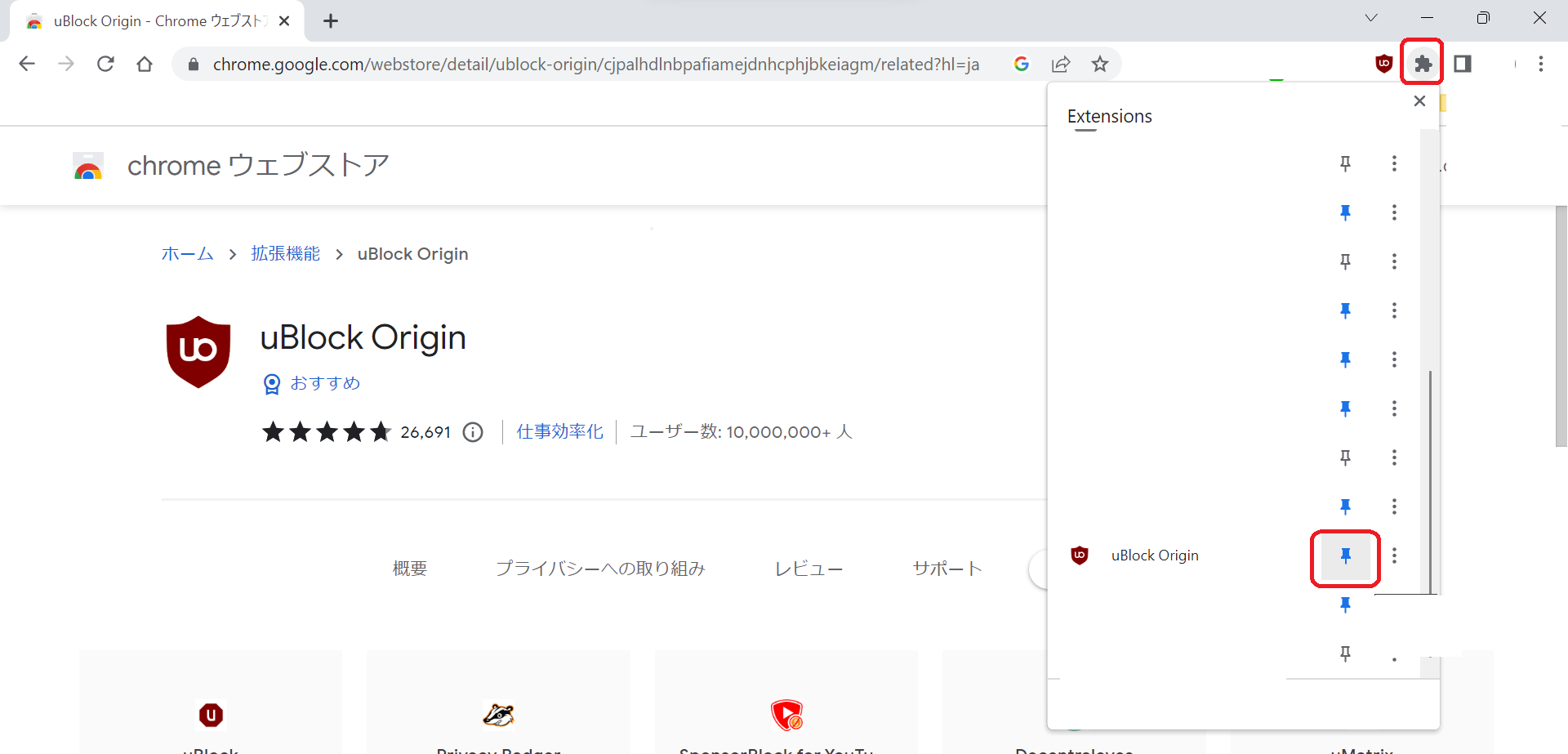
表示されたアイコンをクリックすると、こうなります

ここの電源ボタンみたいなアイコンを押すと、ON/OFFが切り替わります。ONが青塗りつぶし、OFFが白抜きです。ONにしましょう。
(参考:OFFのとき)

ではいよいよ、設定行ってみましょう。
設定
歯車マークを押すと詳細設定の画面が別タブで開きます。

初期状態では一番左のメニューが開いた状態になりますが、「マイフィルタ」をクリックしてください。

マイフィルタの設定はこんな画面です。

ここに色々なフィルタを自分で入力して設定できます。
まずはとりあえず下記をコピペしましょう。いやー酷い言葉が並んでますねえ。今度からこれが見えなくて済むと思ったら、まぁいいか・・・
! Google
news.google.com##article:has-text(/[恥辱死殺暴虐軍猥褻淫詐欺嘘偽疑逮負敗禁否悪]/)
news.google.com##article:has-text(/攻撃/)
news.google.com##article:has-text(/不安/)
news.google.com##article:has-text(/懸念/)
news.google.com##article:has-text(/除名/)
news.google.com##article:has-text(/被告/)
そうすると左上の「適用」アイコンが青くなるので、これを押せば反映されます。(Ctrl + Sでも同じです)

では一度、効果のほどを見てみましょう。
検証
上記はGoogleニュースのためのフィルターでした。ということで
https://news.google.com/
に行ってみましょう。
先程の電源ボタンアイコンでフィルターのON/OFFを切り替えると、一部の記事が非表示にされているのが分かります。
(OFFのとき)

(ONのとき)
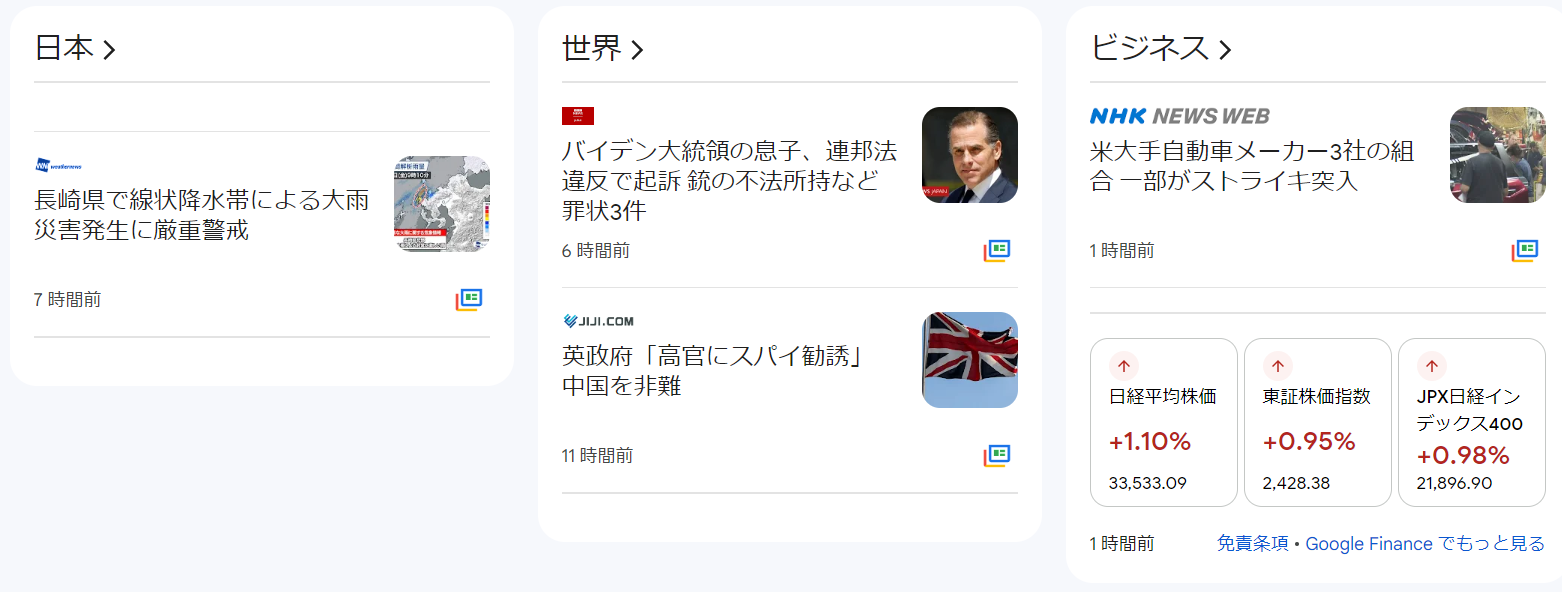
この場合は、先ほどしていしたフィルタのうち、「死」という文字が検出された記事ブロックを非表示にしています。今回は入れていませんが、「罪」とか「非難」とかで引っ掛ければ、さらに2列めの記事を非表示にできるでしょう。
好みに応じて、フィルタを追加・削除してみてください。
他の例
Yahoo! News
! Yahoo News
yahoo.co.jp##a:has-text(/[恥辱死殺暴虐軍猥褻淫詐欺嘘偽疑逮負敗禁否悪]/)
yahoo.co.jp##a:has-text(/攻撃/)
yahoo.co.jp##a:has-text(/不安/)
yahoo.co.jp##a:has-text(/懸念/)
yahoo.co.jp##a:has-text(/除名/)
yahoo.co.jp##a:has-text(/被告/)
BBC News
! BBC
www.bbc.com##article:has-text(/anger/i)
www.bbc.com##article:has-text(/arrest/i)
www.bbc.com##article:has-text(/dead/i)
www.bbc.com##article:has-text(/death/i)
www.bbc.com##article:has-text(/die/i)
www.bbc.com##article:has-text(/fraud/i)
www.bbc.com##article:has-text(/kill/i)
www.bbc.com##article:has-text(/outcr/i)
www.bbc.com##article:has-text(/profile/i)
www.bbc.com##article:has-text(/riot/i)
www.bbc.com##article:has-text(/victim/i)
www.bbc.com##article:has-text(/violen/i)
www.bbc.com##a:has-text(/anger/i)
www.bbc.com##a:has-text(/arrest/i)
www.bbc.com##a:has-text(/dead/i)
www.bbc.com##a:has-text(/death/i)
www.bbc.com##a:has-text(/die/i)
www.bbc.com##a:has-text(/fraud/i)
www.bbc.com##a:has-text(/kill/i)
www.bbc.com##a:has-text(/outcr/i)
www.bbc.com##a:has-text(/profile/i)
www.bbc.com##a:has-text(/riot/i)
www.bbc.com##a:has-text(/victim/i)
www.bbc.com##a:has-text(/violen/i)
www.bbc.com##.gs-c-promo:has-text(/anger/i)
www.bbc.com##.gs-c-promo:has-text(/arrest/i)
www.bbc.com##.gs-c-promo:has-text(/dead/i)
www.bbc.com##.gs-c-promo:has-text(/death/i)
www.bbc.com##.gs-c-promo:has-text(/die/i)
www.bbc.com##.gs-c-promo:has-text(/fraud/i)
www.bbc.com##.gs-c-promo:has-text(/kill/i)
www.bbc.com##.gs-c-promo:has-text(/outcr/i)
www.bbc.com##.gs-c-promo:has-text(/profile/i)
www.bbc.com##.gs-c-promo:has-text(/riot/i)
www.bbc.com##.gs-c-promo:has-text(/victim/i)
www.bbc.com##.gs-c-promo:has-text(/violen/i)
GIGAZINE
! Gigazine
gigazine.net##b:has-text(/[恥辱死殺暴虐軍猥褻淫詐欺嘘偽疑逮負敗禁否悪]/)
gigazine.net##b:has-text(/攻撃/)
gigazine.net##b:has-text(/不安/)
gigazine.net##b:has-text(/懸念/)
gigazine.net##b:has-text(/除名/)
gigazine.net##b:has-text(/被告/)
https://pbs.twimg.com/*
gigazine.net##.twitter-tweet
gigazine.net##b:has-text( - YouTube)
gigazine.net##.yt_iframe.lazyloaded
gigazine.net##script[data-src="youtube.*"]
もし他にも作って欲しかったら連絡ください笑
これらは、同じ「マイフィルタ」の設定の所に続けて書くことができます。(各行は独立に扱われ、どれにも当てはまらなかったもの要素が表示されます)
中級者向けの解説(使いこなしたい!)
フィルタについてもうちょっと説明
上の例で解説します。
news.google.com##article:has-text(/[恥辱死殺暴虐軍猥褻淫詐欺嘘偽疑逮負敗禁否悪]/)
news.google.com##article:has-text(/攻撃/)
www.bbc.com##article:has-text(/violen/i)
www.bbc.com##a:has-text(/dead/i)
www.bbc.com##a:has-text(/victim/i)
www.bbc.com##.gs-c-promo:has-text(/anger/i)
ドメイン
##の前に対象ドメインを指定します。news.google.comやwww.bbc.comがこれに当たります。
ドメインなので、たとえばGoogleニュースを開いた場合に自動で飛んでいくアドレスhttps://news.google.com/home?hl=ja&gl=JP&ceid=JP:ja全部ではなく、最初の//とその後の/に挟まれた部分のnews.google.comを指定します。
間違っていればエラーが出てくるので気づけます。
(上が正解、下が間違い)

要素
##の後、:の前に、フィルタにかけたいページ上の要素を指定します。どうやって要素を見つけるかは後で解説します。
-
news.google.comはarticleという要素で記事のサムネイルを配置しています。 -
www.bbc.comはもう少し複雑で、ページ上の位置によってarticleのこともあればa、あるいは.gs-c-promoだったりします。
テキストフィルタ
:の後に、フィルターの条件を指定します。基本的にはhas-text()で行けます。
-
has-text(/[恥辱死殺暴虐軍猥褻淫詐欺嘘偽疑逮負敗禁否悪]/)は、[]で囲むことで、その中の「いずれか」1文字にマッチした場合を捕捉します。 -
has-text(/攻撃/)では、「攻撃」という文字列全体にマッチした場合を捕捉します。 -
has-text(/violen/i)では、「violen」という文字列を、大文字/小文字の区別なく捕捉します。(暴力的violent、暴力violenceを狙っています)
フィルタについてもっと説明
Gigazineの方ではもう少しひねりを入れてみました。
https://pbs.twimg.com/*
gigazine.net##.twitter-tweet
gigazine.net##b:has-text( - YouTube)
gigazine.net##.yt_iframe.lazyloaded
gigazine.net##script[data-src="youtube.*"]
- 上の2行は自分があまり好きではないTwitterの引用とリンクを消すためのものです。1行目が画像、2行目がリンクテキストにマッチします。
- 下3行で、Youtubeへの引用とリンクを消しています。
要素の取得方法
比較的難しいのが、##と:の間に入れるべき「要素」の取得です。コツさえ掴めばそんなに難しくないのですが、これをきちんと解説しているページがなかなか見つからず。
やだなーと思った要素を右クリックし、「検証」を選びます。

するとソースコードの文字列のうち対応する部分が表示され、そこにマウスを持っていくと、ブラウザ内の対応する部分が青くハイライトされます。

ここで、<a class="WwrzSb"...とあります。クラス名あるいはその前のタグ名はUBOで要素として使えます。なので
-
news.google.com##.WwrzSb:has-text(/銃/)(クラス名はピリオドを前にいれる) -
news.google.com##a:has-text(/銃/)(タグ名はそのまま書く)
というフィルタを作ってもいいでしょう。
さて、このWwrzSbという文字列、なんか複雑すぎません?
このような場合高い確率で、読み込むたびに名前が自動生成されています。次回このページを読み込んだ時には別な文字列に変わってしまっており、捕捉できません。ですので、上の2つから選ぶのであればaの方を使いましょう。
ところで、先程の表示をもう一度注意して見ると、(別に良いといえば良いのですが)消したいニュースに対応するブロックの一部が捕捉しきれてないことが分かります。

Webページを記述するHTML言語は入れ子構造になっており、赤字で囲った部分も全部含むブロックが上位にあるかもしれません。
ということで、ソースコードを上の方に追っていきます。ひとつ上の<div class=...>の上にマウスを持ってくると・・・

まだあまり変わりませんね。そのさらに上はどうでしょう。

もうひとつ!

これでブロック全体を捕捉できました。名前もarticle(記事)、ピッタリそうです。
(なお、この上のレベルもさらに入れ子状になっていますし、そこのタグなどを捕捉するのもアリかもです)