ドーモ、引き続き、この記事もViibarアドベントカレンダーのとある1日の記事でございます。
ここ数日は少しだけデータ分析業をしているので、みんなだいすきJupyterからMySQLにつないでみます。
前提
- Mysqlサーバーがローカルにインストールしていて起動済み
- テストデータとしてdatacharmer/test_dbを使用
Jupyterインストール
miniconda3がよいとのことだったので使いたかったのですが、Pythonzはディストリビューション違いは含めたくないというポリシーらしく(ana|mini)condaがありません。なので、pyenvを使うことにしましたが、pyenvはよくわかりません。雑に使ってみます。
brew install pyenv
eval "$(pyenv init -)"
pyenv install miniconda3-3.18.3
.pyenv/versionsにインストールされます。
$ ls ~/.pyenv/versions
miniconda3-3.18.3
conda系はcondaコマンドでvirtualenv作成、依存性管理までするようです。なので、conda上でのjupyterを使いたい場合はpyenv-virtualenvはいらないようです。
pyenv global miniconda3-3.18.3
pyenv rehash
conda create -n test01 jupyter
$ ls ~/.pyenv/versions/miniconda3-3.18.3/envs/
test01
venvができました。
source ~/.pyenv/versions/miniconda3-3.18.3/envs/test01/bin/activate test01
jupyter notebook
notebookが起動すればOKです。source activate test01だとpyenvとぶつかるのでフルパスです。condaもpyenvも使わないで、普通に手動で依存関係をインストールしてもよかったな。
依存ライブラリインストール
MySQLドライバはpymysql、定番のpandas, matplotlibも入れます。
conda install pymysql
conda install pandas
conda install matplotlib
pip install ipython-sql
catherinedevlin/ipython-sqlだけはcondaに用意されてないのでpipからインストールです。
MySQLサーバーにJupyter notbookから接続
以下、notebookから実行です。
import pymysql
connection = pymysql.connect(host='localhost',
user='root',
password='',
db='employees',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
connection.commit()
cur = connection.cursor()
cur.execute('select count(*) from employees')
1
rows = cur.fetchall()
rows
[{'count(*)': 300024}]
cur.execute('select * from employees limit 100')
100
rows = cur.fetchall()
rows
[{'birth_date': datetime.date(1953, 9, 2),
'emp_no': 10001,
'first_name': 'Georgi',
'gender': 'M',
'hire_date': datetime.date(1986, 6, 26),
'last_name': 'Facello'},
{'birth_date': datetime.date(1964, 6, 2),
'emp_no': 10002,
'first_name': 'Bezalel',
'gender': 'F',
'hire_date': datetime.date(1985, 11, 21),
'last_name': 'Simmel'},
...
{'birth_date': datetime.date(1956, 5, 25),
'emp_no': 10099,
'first_name': 'Valter',
'gender': 'F',
'hire_date': datetime.date(1988, 10, 18),
'last_name': 'Sullins'},
{'birth_date': datetime.date(1953, 4, 21),
'emp_no': 10100,
'first_name': 'Hironobu',
'gender': 'F',
'hire_date': datetime.date(1987, 9, 21),
'last_name': 'Haraldson'}]
%%sqlを利用してのsql実行
次は、%%sqlを利用してMySQLに接続してみます。
%config SqlMagic.autopandas = True
%config SqlMagic.feedback = False
%load_ext sql
/Users/shirakawahiroyuki/.pyenv/versions/miniconda3-3.18.3/envs/test01/lib/python3.5/site-packages/IPython/config.py:13: ShimWarning: The `IPython.config` package has been deprecated. You should import from traitlets.config instead.
"You should import from traitlets.config instead.", ShimWarning)
/Users/shirakawahiroyuki/.pyenv/versions/miniconda3-3.18.3/envs/test01/lib/python3.5/site-packages/IPython/utils/traitlets.py:5: UserWarning: IPython.utils.traitlets has moved to a top-level traitlets package.
warn("IPython.utils.traitlets has moved to a top-level traitlets package.")
ここで警告でるの、import from traitlets directly instead of IPYthon by aebrahim · Pull Request #46 · catherinedevlin/ipython-sqlで、PR作ってくれてますが、マージされてません。
%%sql mysql+pymysql://root@localhost/employees?charset=utf8mb4
select * from employees limit 100;
| emp_no | birth_date | first_name | last_name | gender | hire_date | |
|---|---|---|---|---|---|---|
| 0 | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 1 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 2 | 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
| 3 | 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 |
100 rows × 6 columns
df = _
describeの意味が無いデータですがとりあえず。
df.describe()
| emp_no | |
|---|---|
| count | 100.000000 |
| mean | 10050.500000 |
| std | 29.011492 |
| min | 10001.000000 |
| 25% | 10025.750000 |
| 50% | 10050.500000 |
| 75% | 10075.250000 |
| max | 10100.000000 |
2回めからは接続の情報は不要です。
%%sql
select * from employees limit 1;
| emp_no | birth_date | first_name | last_name | gender | hire_date | |
|---|---|---|---|---|---|---|
| 0 | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
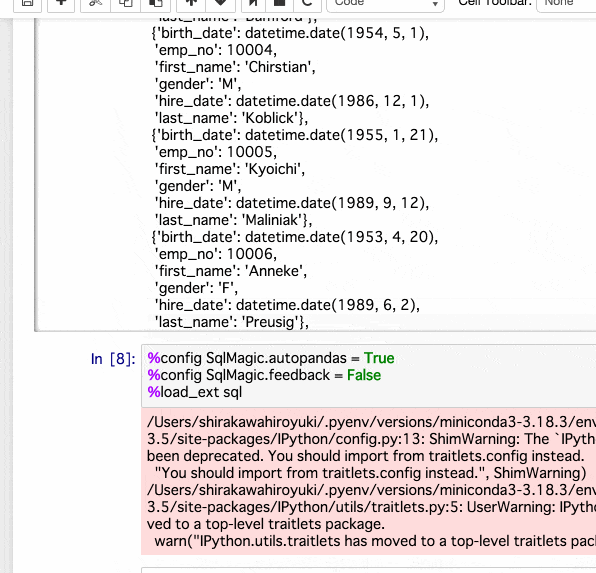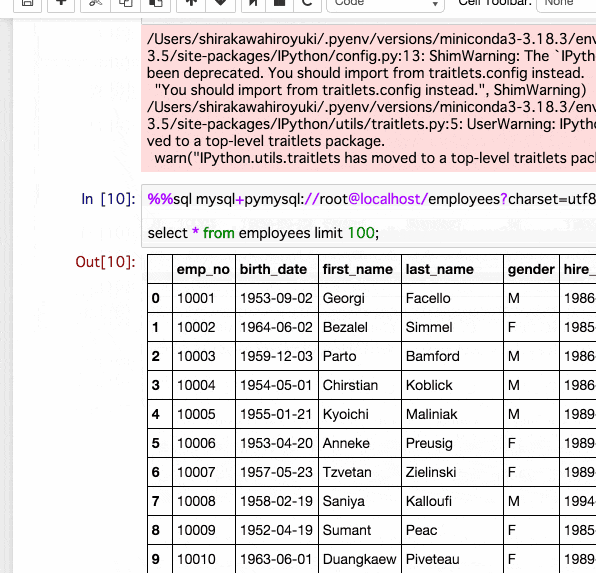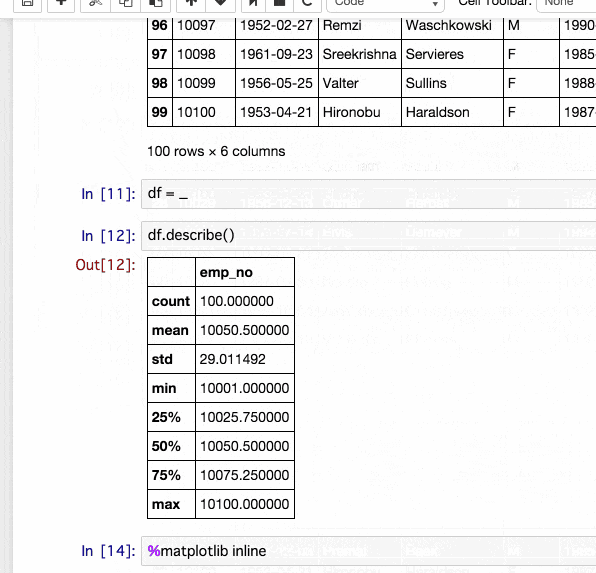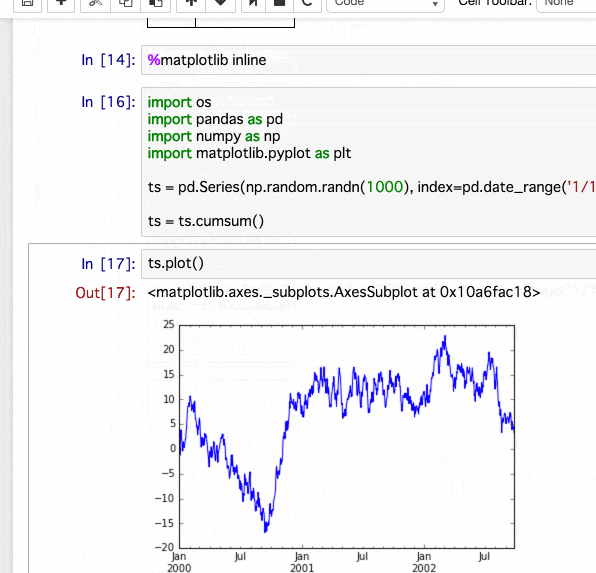
ついでによくあるpandasとmatplotlibのサンプルも出してみました。
%matplotlib inline
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x10a6fac18>
まとめ
SQLの実行クライアントは、昔はCSEとかNavicat for MySQL | MySQLに対応したDB管理・開発ツールとか使ってたんですが、Macにしてからあまりいい感じのクライアントに巡りあってませんでした。
自分の用途では、管理機能とかはそんな必要としてなくて、
- SQL文とその実行結果の保存
- SQL文のフォーマット
くらいができればよさげだったので、Jupyter notebookがまあまあちょうどいいのかもしれません。
SQL文のフォーマットについては、andialbrecht/sqlparse使えば、SQL文をきれいにフォーマットしてくれるので、それで。
いろいろPythonでやると幸せになれそうです。
以上です。