はじめに
今回は、現場でわからなかったことがあったので、それをまとめておこうと思います。
実際あったこととしては、Lambdaでコード実装して、動作確認どうやろうとなった時に、デプロイをする(IaCで構築予定でした)んじゃなくてまずはローカル実行で動作確認してからデプロイしようと言われました。
自分自身、Lambdaをローカル実行できるような環境を作ったことがなく、こういう時、どうやってやるんだろうってのがわからなかったので、まとめていこうと思います。
Lambdaをローカルで実行するためには(概要)
結論から言いますと、AWSがLambdaをローカル実行するためのベースイメージをECSにあげてくれてるので、それを使ってコンテナ環境を作成することで達成できます。
レイヤー等含めたい場合などもやり方があるのでそちらについても書いていきます。
Lambdaをローカルで実行する手順
ここでは、実際にLambdaに簡単なPythonコードを書いて、そのコードをローカルで実行できるようにしようと思います。
-
フォルダ構成を以下のように組んでください。
ぶっちゃけここは自由ですが、自分は以下のように組みました。
あと、dockerの仕様上、dockerfileより階層が上のフォルダやファイルについては、dockerfile内でコピーしようとしても無理なのでそこだけ気をつけてください。. ├── dockerfile └── lambda └── lambda_function.py -
ECSのベースイメージを使って、以下のようなdockerfileを書く
CMDに書いている内容については、以下を合わせてください。- lambda_function=実行するコードのファイル名
- lambda_handler=コード内で実行する関数名
FROM public.ecr.aws/lambda/python:3.14 # コンテナ内に実行するLambdaのコードをコピー COPY ./lambda/lambda_function.py ${LAMBDA_TASK_ROOT} # コンテナ実行時にLambda関数を実行するためのコマンド CMD [ "lambda_function.lambda_handler" ] -
実行するLambdaにはサンプルとして以下のようなコードを書く
ぶっちゃけ実行させられるかどうかなので、ここもなんでもいいのですが、docker buildする前に記載してください。そうしないと、コンテナ内に以下の内容が反映されません。def lambda_handler(event, context): # 呼び出し元に返すレスポンス return { "message": "Hello from Lambda!", "status": "success" } -
記載したdockerfileを使ってdocker imageを作成する
以下コマンドを実行してください。
はなんでもいいです。docker build -t <image name> . -
手順3で作ったdocker imageからコンテナ作成
ローカルはポート9000で公開していますが、こちらもお好きなポートで大丈夫です。
コンテナ内の8080ポートについては変更しないでください。docker run -p 9000:8080 <image name> -
動作確認
別ターミナルを開いて、以下のコマンドを実行してください。curl -d '{}' http://localhost:9000/2015-03-31/functions/function/invocations以下の結果が返って来れば、成功です!
{"message": "Hello from Lambda!", "status": "success"}%
レイヤーを追加する
ここまでで、ローカルでLambda関数を実行できるようになりました。
ただ実務では、Lambdaを単に実行するだけではなく、自作の関数だったり、その他ライブラリを利用できるようにレイヤーを追加することが多いです。
レイヤーの役割や利点については、AWSの公式で以下の内容の記載がありました。
個人的には以下の中でも、ライブラリの利用や、デプロイパッケージのサイズを小さくするのが目的の場合が多いのかなと思っております。
Lambda レイヤーは、補助的なコードやデータを含む .zip ファイルアーカイブです。レイヤーには通常、ライブラリの依存関係、カスタムランタイム、または設定ファイルが含まれています。
レイヤーの使用を検討する理由は複数あります。
デプロイパッケージのサイズを小さくするため。関数コードとともにすべての関数依存関係をデプロイパッケージに含める代わりに、レイヤーに配置します。これにより、デプロイパッケージは小さく整理された状態に保たれます。
コア関数ロジックを依存関係から分離するため。レイヤーを使用すると、関数コードと独立して関数の依存関係を更新でき、その逆も可能となります。これにより、関心事の分離が促進され、関数ロジックに集中することができます。
複数の関数間で依存関係を共有するため。レイヤーを作成したら、それをアカウント内の任意の数の関数に適用できます。レイヤーがない場合、個々のデプロイパッケージに同じ依存関係を含める必要があります。
Lambda コンソールのコードエディターを使用するため。コードエディターは、関数コードの軽微な更新をすばやくテストするのに便利なツールです。ただし、デプロイパッケージのサイズが大きすぎる場合は、エディターを使用できません。レイヤーを使用すると、パッケージのサイズが小さくなり、コードエディターの使用制限を解除できます。
組み込み SDK バージョンをロックするため。AWS が新しいサービスや機能をリリースすると、組み込み SDK は予告なく変更される場合があります。SDK バージョンは、必要な特定のバージョンで Lambda レイヤーを作成することでロックできます。その後、サービスに組み込まれたバージョンが変更されても、関数は常にレイヤーのバージョンを使用します。
前提知識
Lambda(python)のローカル環境を用意する場合、レイヤーに格納するライブラリはコンテナ内の「/opt/python」直下におく必要があります。
今回は、ローカル環境のレイヤーを後にAWS環境のLambdaに追加することを考慮した以下の構成にしようと思います。
.
├── dockerfile
├── lambda
│ └── lambda_function.py
└── lambda_layers
├── pandas_layer
│ └── python
└── ○○_layer(layerを追加する場合)
└── python
上記レイヤーの利点は以下になります。
- 単一のレイヤーをLambdaに含みたいときは、-vオプションで〇〇_layer/を/opt/にマウントすれば即時レイヤーの追加が可能
- zip化する場合もレイヤーごとにフォルダが分かれているためコマンドで行いやすいし、レイヤーの分離が明確
このように、開発を行うときは、今回のような要件に限らず、必ず本番を想定して作ることが重要だと思いますので、この辺りも意識できると良いのかなと思います。
では早速、手順の方も書いていこうと思います!
※今回は手を動かすのを目的としているため、コマンドによる実行を中心に行なっておりますが、実運用では、以下のような方法が多いかと思います。
- dockerfile内でベースイメージを取得→pip installによるライブラリのフォルダへの保存を行う
- ライブラリのインストールはrequirements.txtから行う
-
ベースイメージをプルする
以下のコマンドを実行して、Lambda用pythonのベースイメージを取得します。docker pull public.ecr.aws/lambda/python:3.14また以下の点には注意してください。動かない原因となるので
- 今回は最新のPython3.14を利用しますが、Lambdaのランタイムに合わせてください。バージョン差異で動かなくなる可能性があるためです
- docker daemonが起動していないと上記のコマンドはエラーとなります。エラーが出た場合にはdockerが起動しているかご確認ください
-
手順1で取得したイメージからコンテナを起動し、bashを開きます。
--entrypointを「/bin/bash」にすることで、コンテナ内のbashをターミナルから開くことができます。
また、先ほどの前提知識でも言った通り、layerは「opt/python」におく必要があるため、必ず layerのマウント先は、「/opt/python」になるようにしてください。
今回は、pandas_layerをレイヤーとしてマウントします。docker run -it --entrypoint /bin/bash -v ./lambda_layers/pandas_layer/:/opt/ public.ecr.aws/lambda/python:3.14 -
インストールしたいライブラリをpipを使ってインストールする
「-t」で指定したフォルダにライブラリをインストールできます。
今回は、pandasをインストールします。pip install -t /opt/python/ pandasマウント元のフォルダに以下のようにpandasと依存関係のあるファイル一覧がインストールされていればOKです!
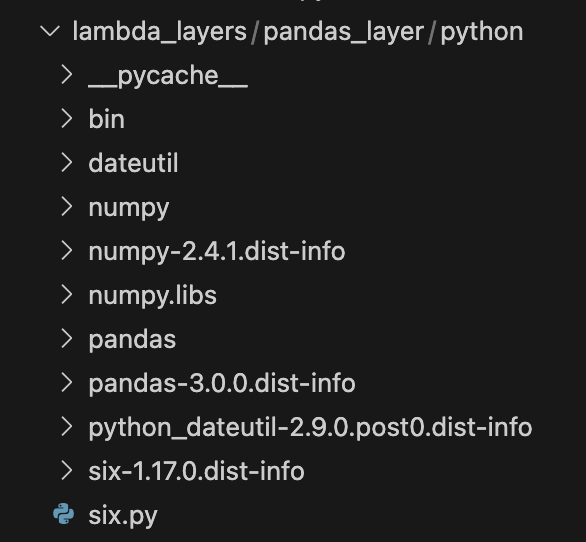
-
pandasを動かす用のサンプルファイルを記載する
今回は以下のコードを記載して、動くかどうか試そうと思います。import pandas as pd def lambda_handler(event, context): # 1. テスト用のデータを作成(配列/辞書) data = { 'Name': ['Alice', 'Bob', 'Charlie', 'David'], 'Score': [85, 92, 78, 95] } # 2. DataFrameの作成 df = pd.DataFrame(data) # 3. Pandasを使った簡単な操作(平均値の算出など) average_score = df['Score'].mean() max_score = df['Score'].max() # 4. 結果を文字列として出力 result_msg = f"Pandas is working! Average Score: {average_score}, Max Score: {max_score}" print(result_msg) return { 'statusCode': 200, 'body': { 'message': result_msg, 'dataframe_preview': df.to_dict(orient='records') } } -
Lambdaをローカルで実行する手順の4~6を実行してください。
※ただし、手順5については、-vオプションを使って以下のようにレイヤーをマウントしてください。docker run -p 9000:8080 -v ./lambda_layers/pandas_layer/:/opt/ <image name> -
実行結果を確認
以下の結果が返ってくれば無事レイヤー取り込みもできた状態で動いていることがわかります。
{"statusCode": 200, "body": {"message": "Pandas is working! Average Score: 87.5, Max Score: 95", "dataframe_preview": [{"Name": "Alice", "Score": 85}, {"Name": "Bob", "Score": 92}, {"Name": "Charlie", "Score": 78}, {"Name": "David", "Score": 95}]}}%
いかがでしたでしょうか。
今回は結構この記事書くの時間かかったので、しんどかったですが、知識としてだいぶ定着したんじゃないかなと思います。
また、何かミスがあれば教えてくださると嬉しいです!
もしよかったら、いいねや保存などしていただけると嬉しいです!