Online Feature Storeとは・・・?
Feature Storeとはデータサイエンスチームが特徴量を共有するためのリポジトリです。DatabricksにおけるFeature Storeの説明はこちらをご参照ください。
日次のバッチ推論のようなジョブであれば単純にDatabricksのメタストアからテーブルを呼び出せば良いのですが、REST APIによるリアルタイム推論のように高速なレスポンスが求められるケースがあります。
Databricks on AWSではFeature Storeに登録したテーブルをAmazon DynamoDB、Amazon Aurora(MySQL互換), Amazon RDS(MySQL)のテーブルとして発行することができ、これををOnline Festure Storeと呼んでいます。Online Feature Storeによって、低レイテンシで推論用の特徴量を供給することが可能になります。(ドキュメント)
概要
本記事はこちらで紹介されているノートブックをウォークスルーした内容です。
Databricks Feature Storeを使用して、オンラインストアに特徴量を公開し、リアルタイムのサービングエンドポイントと自動化された特徴量ルックアップを行う方法を説明します。ここではケーススタディとして、様々な静的なワインの特徴とリアルタイムの入力を持つMLモデルを使用して、ワインの品質を予測します。
具体的にはID とリアルタイムの特徴であるアルコール度数(ABV)が与えられたワインのボトルの品質を予測するエンドポイントを作成します。
このQiitaは以下のように構成されています。
- 特徴量テーブルを用意する
- DynamoDBをセットアップする
- DynamoDBに特徴量を発行します
- モデルの学習とデプロイをします
- 自動特徴量ルックアップでリアルタイム推論を行います
- クリーンアップ
データセット
ワインの品質データセットを使用します
要件
- Databricks Runtime 10.4 LTS for Machine Learning またはそれ以上
- AWSのDynamoDBにアクセスできること
- このノートブックでは、オンラインストアとしてDynamoDBを使用し、シークレットの生成とDatabricksへの登録方法を案内します。
特徴量テーブルを用意する
例えば、 wine_id だけでワインの品質を予測するエンドポイントを作成する必要があるとします。その際、エンドポイントが wine_id からワインの特徴を検索できるような、Feature Storeに保存された特徴量テーブルが必要です。今回のデモでは、まずこの特徴量テーブルを自分たちで用意する必要があります。手順は以下の通りです。
- 生データをロードし、クリーニングする。
- 特徴量とラベルを分離する。
- 特徴量をFeature Storeのテーブルに保存する。
生データの読み込みとクリーニング
生データには、11個の特徴量と quality カラムを含む12個のカラムが含まれます。quality カラムは 3 から 8 までの整数である。目標は quality の値を予測するモデルを構築することです。
raw_data_frame = spark.read.load("/databricks-datasets/wine-quality/winequality-red.csv",format="csv",sep=";",inferSchema="true",header="true" )
display(raw_data_frame.limit(10))
# Have a look at the size of the raw data.
raw_data_frame.toPandas().shape
生データにはいくつかの問題があります。
- 列名にスペース(' ')が含まれています。これは特徴量ストアと互換性がありません。
- IDを生データに追加して、オンライン特徴量がポストされてきた際に一意なIDで静的な特徴量を検索できるようにする必要があります。
以下のセルは、これらの問題を解決するためのものです。
from sklearn.preprocessing import MinMaxScaler
from pyspark.sql.functions import monotonically_increasing_id
def addIdColumn(dataframe, id_column_name):
columns = dataframe.columns
new_df = dataframe.withColumn(id_column_name, monotonically_increasing_id())
return new_df[[id_column_name] + columns]
def renameColumns(df):
renamed_df = df
for column in df.columns:
renamed_df = renamed_df.withColumnRenamed(column, column.replace(' ', '_'))
return renamed_df
# Rename columns so that they are compatible with Feature Store
renamed_df = renameColumns(raw_data_frame)
# Add id column
id_and_data = addIdColumn(renamed_df, 'wine_id')
display(id_and_data)
特徴量テーブルの作成
次に、データベースを新規に作成し、データ id_static_features を特徴量テーブルに保存します。
%sql
create database if not exists online_feature_store_example;
from databricks.feature_store.client import FeatureStoreClient
fs = FeatureStoreClient()
fs.create_table(
name="online_feature_store_example.wine_static_features",
primary_keys=["wine_id"],
df=id_static_features,
description="id and features of all wine",
)
- 左サイドバーの Feature Store をクリックします。表示されていない場合は、Machine Learning ペルソナ (ドキュメント)に切り替えてください。
-
online_feature_store_example.wine_static_featuresという特徴量テーブルをクリックします
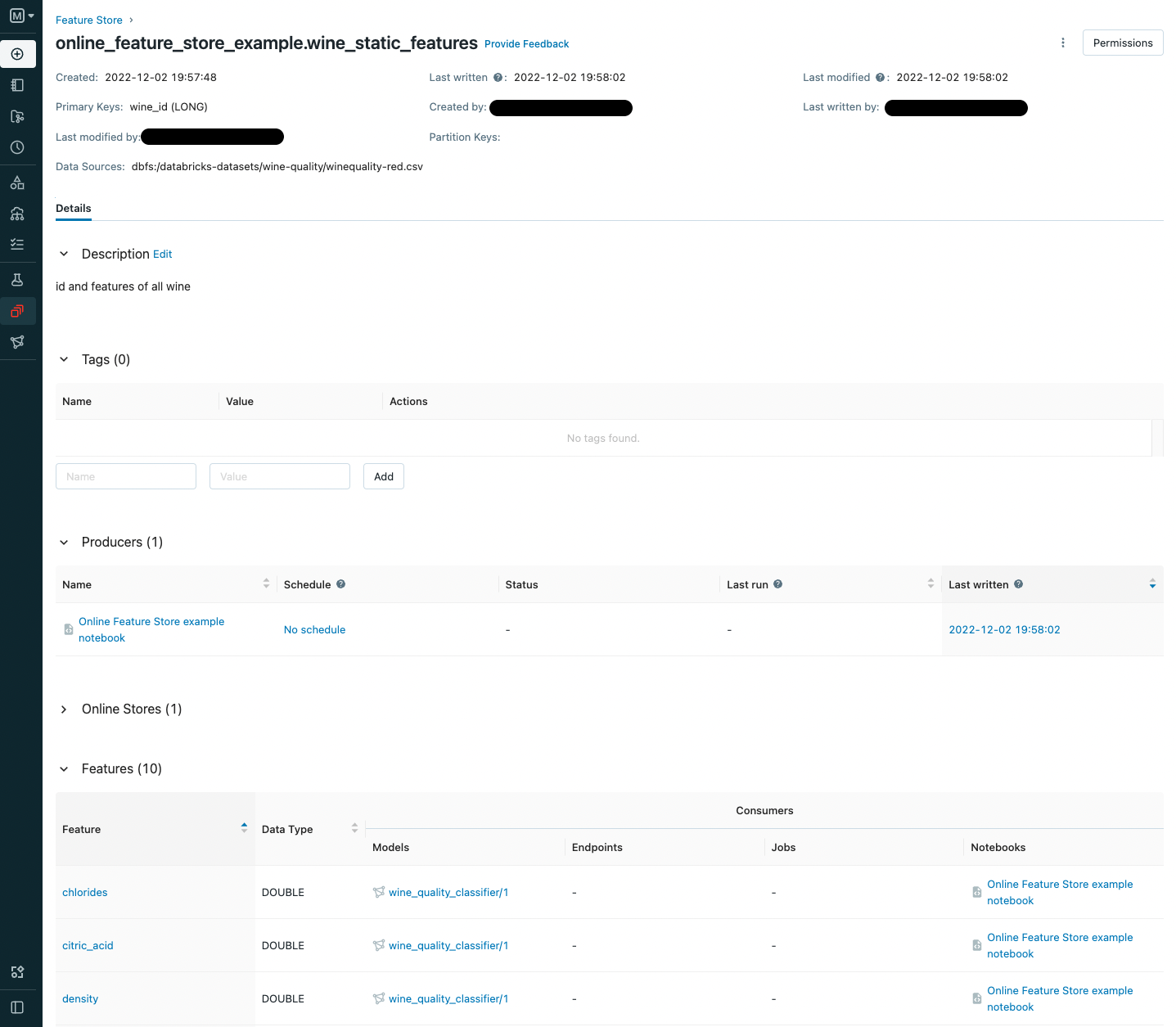
データがFeature Storeに格納されました。次はAWSのDynamoDBにアクセスするための設定を行います。
DynamoDBアクセスキーのセットアップ
このセクションでは、このノートブックからDynamoDBにアクセスできるようにするために手動でいくつかの手順を実行する必要があります。Databricksは、DynamoDBがFeature Storeと連携できるように、DynamoDBテーブルを作成および更新します。以下のステップでは、必要な権限を持つ新しいAWS IAMユーザーを作成します。また、既存のユーザーまたはロールを使用することもできます。
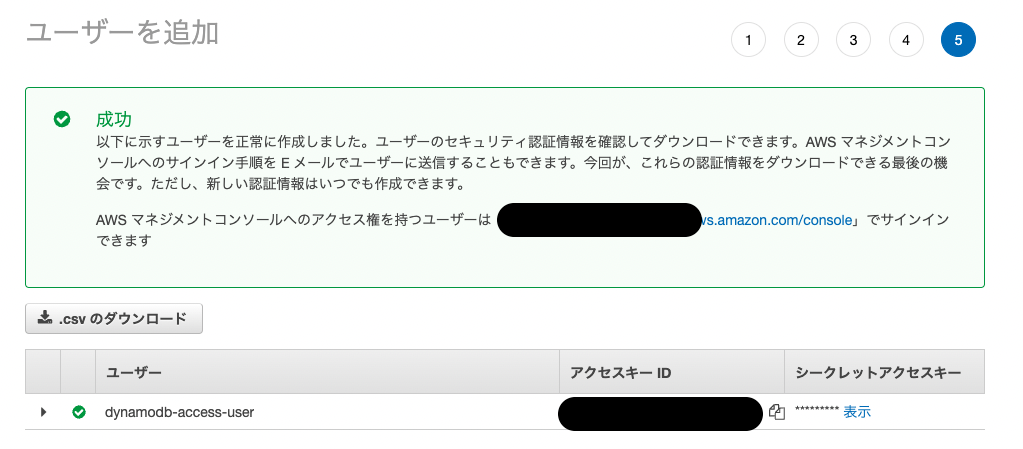
AWS IAMユーザーの作成とsecretsのダウンロード
- AWS コンソール http://console.aws.amazon.com にアクセスし、IAM に移動して、「ユーザー」をクリックします。
- ユーザーの追加をクリックし、ユーザ名の入力、AWS認証情報タイプをアクセスキー - プログラムによるアクセスを選択します
- [次へ]をクリックし、ポリシーAmazonDynamoDBFullAccessを選択します。
- ユーザーが作成されるまで、[次へ]をクリックします。
- アクセスキーID、シークレットアクセスキーをダウンロードします!
Databricksのsecretsを使ってオンラインストアのクレデンシャルを提供する
Note: 簡単のために、以下のコマンドはScopeとSecretに定義済みの名前を使用しています。独自のスコープとシークレット名を選択するには、Databricksのドキュメントにある手順に従ってください。databricks CLIの使い方についてはこちらの記事をご参照ください。
2つのSecret Scopeを作成します。
$ databricks secrets create-scope --scope feature-store-example-read
$ databricks secrets create-scope --scope feature-store-example-write
ScopeにSecretを作成します。
$ databricks secrets put --scope feature-store-example-read --key dynamo-access-key-id
$ databricks secrets put --scope feature-store-example-read --key dynamo-secret-access-key
$ databricks secrets put --scope feature-store-example-write --key dynamo-access-key-id
Note: --keyはそれぞれ <prefix>-access-key-id と <prefix>-secret-access-key という形式である必要があります。ここでも、簡単のために、これらのコマンドはあらかじめ定義された名前を使用しています。コマンドを実行すると、Secretをエディタにコピーするように促されるので、ダウンロードしたアクセスキーIDとシークレットアクセスキーをそれぞれコピペしてください。
これで、Databricks Secretsに認証情報が保存されました。以下、オンラインストアを作成する際に使用します。
Online Feature Storeに特徴量を公開する
これにより、Feature Storeは特徴量テーブルとオンラインストレージに関するリネージ情報を追加することができます。そのため、モデルがリアルタイムのクエリを提供する際に、オンラインストアから特徴量を参照することができ、パフォーマンスが向上します。
from databricks.feature_store.online_store_spec import AmazonDynamoDBSpec
# Specify the online store.
# Note: these commands use the predefined secret prefix. If you used a different secret scope or prefix, edit these commands before running them.
online_store_spec = AmazonDynamoDBSpec(
region="us-west-2",
write_secret_prefix="feature-store-example-write/dynamo",
read_secret_prefix="feature-store-example-read/dynamo",
table_name = "feature_store_online_wine_features"
)
# Push the feature table to online store.
fs.publish_table("online_feature_store_example.wine_static_features", online_store_spec)
- 左サイドバーの Feature Store をクリックします。表示されていない場合は、Machine Learning ペルソナ (ドキュメント)に切り替えてください。
- online_feature_store_example.wine_static_featuresという特徴量テーブルをクリックします
-
Online Storesのタブを展開すると、DynamoDBのテーブルとして公開されていることを確認できます

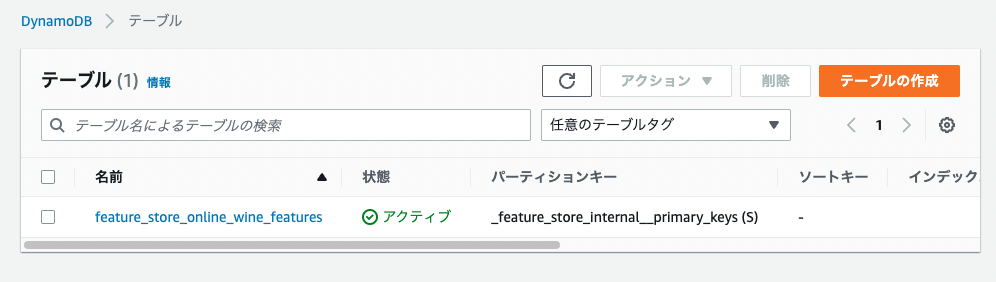
またAWSのコンソールからDynamoDBのテーブルを開くと、feature_store_online_wine_featuresというテーブルが登録されていることを確認できます
モデルの学習とデプロイ
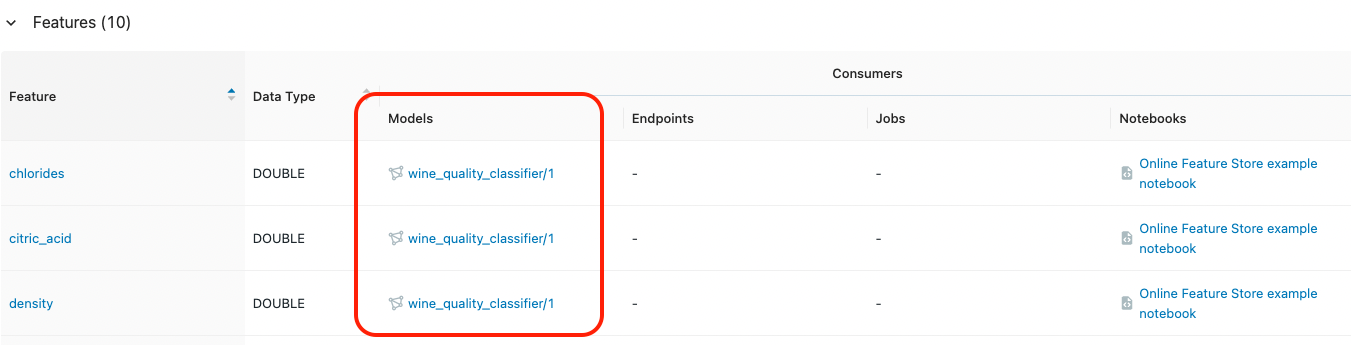
では、Feature Store にある特徴量を用いて分類器を学習します。主キーを指定するだけで、Feature Store が必要な特徴量を取得してくれます。
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import logging
import mlflow.sklearn
from databricks.feature_store.entities.feature_lookup import FeatureLookup
まず、TrainingSet を定義します。トレーニングセットには feature_lookups リストを渡すことができ、各項目は Feature Store 内の特徴量テーブルにあるいくつかの特徴量を表しています。この例では wine_id をルックアップキーとして、テーブル online_feature_store_example.wine_features からすべての特徴量を取得します。
training_set = fs.create_training_set(
id_rt_feature_labels,
label='quality',
feature_lookups=[
FeatureLookup(
table_name=f"online_feature_store_example.wine_static_features",
lookup_key="wine_id"
)
],
exclude_columns=['wine_id'],
)
# Load the training data from Feature Store
training_df = training_set.load_df()
display(training_df)
RandomForestClassifierモデルを学習します。
X_train = training_df.drop('quality').toPandas()
y_train = training_df.select('quality').toPandas()
# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train.values.ravel())
学習したモデルを log_model を用いて保存します。log_model はモデルと特徴量の間のリネージ情報も保存することができます(training_setを通して)。そのため、モデルには、ルックアップキーを使ってどこの特徴量を取得すればよいかが自動的に分かります。
fs.log_model(
model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="wine_quality_classifier",
extra_pip_requirements=["mlflow==1.*"]
)
自動的な特徴量ルックアップでリアルタイムのクエリを提供する
log_model を呼び出した後、新しいバージョンのモデルが保存されます。サービングエンドポイントをプロビジョニングするには、以下のステップに従います。
- 左サイドバーの Models をクリックします。表示されていない場合は、Machine Learning ペルソナ (ドキュメント)に切り替えてください。
-
wine_quality_classifierというモデルに対してサービングを有効にします。詳しくはDatabricksのドキュメントを参照してください(ドキュメント)。
クエリを送信する
サービングページでは、モデルを呼び出すための3つのアプローチがあります。以下のように、JSON形式のリクエストで「ブラウザ」アプローチを試すことができます。しかし、ここではプログラム的な方法を説明するために、Pythonのアプローチをコピーペーストしています。
# Databricksのアクセストークンの値を入力してください。
# Note: 新しいDatabricksアクセストークンを生成するには、左サイドバーの "Settings" > "User Settings" > "Access Tokens" にアクセスするか、databricks-cliを使用する必要があります。
import os
os.environ["DATABRICKS_TOKEN"] = "<DATABRICKS_TOKEN>"
assert os.environ["DATABRICKS_TOKEN"] != "<DATABRICKS_TOKEN>"
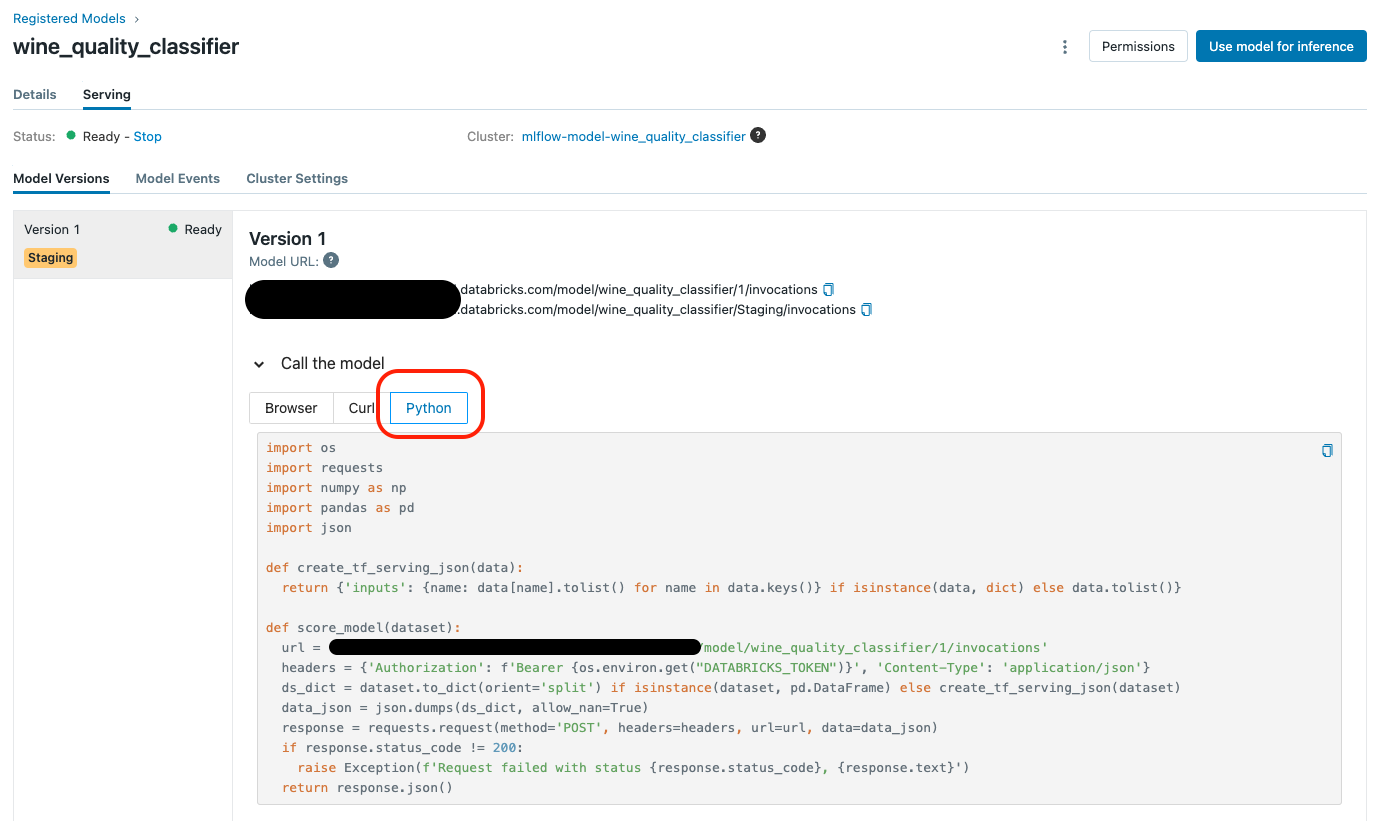
# Call the modelのPythonタブのコードをコピペします
import os
import requests
import numpy as np
import pandas as pd
import json
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(dataset):
url = '<URL>'
headers = {'Authorization': f'Bearer {os.environ.get("DATABRICKS_TOKEN")}', 'Content-Type': 'application/json'}
ds_dict = dataset.to_dict(orient='split') if isinstance(dataset, pd.DataFrame) else create_tf_serving_json(dataset)
data_json = json.dumps(ds_dict, allow_nan=True)
response = requests.request(method='POST', headers=headers, url=url, data=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()
さて、ワインのボトルを開けて、そのボトルから現在のアルコール度数ABVを測定するセンサーがあったとします。このモデルとリアルタイムに提供される自動特徴量ルックアップを使用すると、測定されたABV値をリアルタイムの入力alcoholとして使用して、ワインの品質を予測することができます。
new_wine_ids = pd.DataFrame([(25, 7.9), (25, 11.0), (25, 27.9)], columns=['wine_id', "alcohol"])
print(score_model(new_wine_ids))
上記コマンドを実行するとレスポンスが返ってきました。id=25の同一ワインですが3種類のレコードに対する推論をリクエストしたので、ちゃんと動いていそうです。

クリーンアップ
このチェックリストに従って、このノートブックで作成されたリソースをクリーンアップしてください。
- AWSのDynamoDBテーブル
- AWSのコンソールに移動し、DynamoDBに移動します。
- テーブル
feature_store_online_wine_featuresを削除します。
- AWSユーザーとアクセスキー
- AWSコンソールからIAMに移動します。
- 新しく作成されたユーザーを検索し、クリックします。
- ユーザーを削除するか、アクセスキーの "Make Inactive "をクリックして、アクセスを無効にします。
-
- Databricks Secretsにシークレットを保存します。
databricks secrets delete-scope --scope `を実行します。
- Databricks Secretsにシークレットを保存します。
- Databricksのアクセストークン
- Databricksの左サイドバーから、"設定" > "ユーザー設定" > "アクセストークン"