今回は「MinimalRNN」の論文を読んだので、前述した内容について触れていきたいと思います。
※読み足りていないところが多々あるので、後で加筆していきます。
この論文の要約
本論文での主題は以下です。
- MinimalRNNは既存のRNNのモデル(Vanilla RNN、GRU、CFN)と比較して、効率的に学習し、精度は同等の精度を実現することが可能。
- 入出力にヤコビアンを利用して、既存のRNNのモデルよりも長期の記憶能力を実現することが判明。
RNN?
RNN(Recurrent Neural Network)は再帰的なニューラルネットワークのことです。
通常のNNでは時系列データを扱うことが出来ないですが、RNNを利用すれば、時系列データを扱うことが可能となります。
利用されるシーンとしては、言語モデリング、要約、翻訳、音声認識などが挙げられます。
※このRNNで利用されるモデルがいくつか存在するため、後述します。
RNNの種類
Vanilla RNN
最もシンプルなRNNのモデル。
図は以下となります。
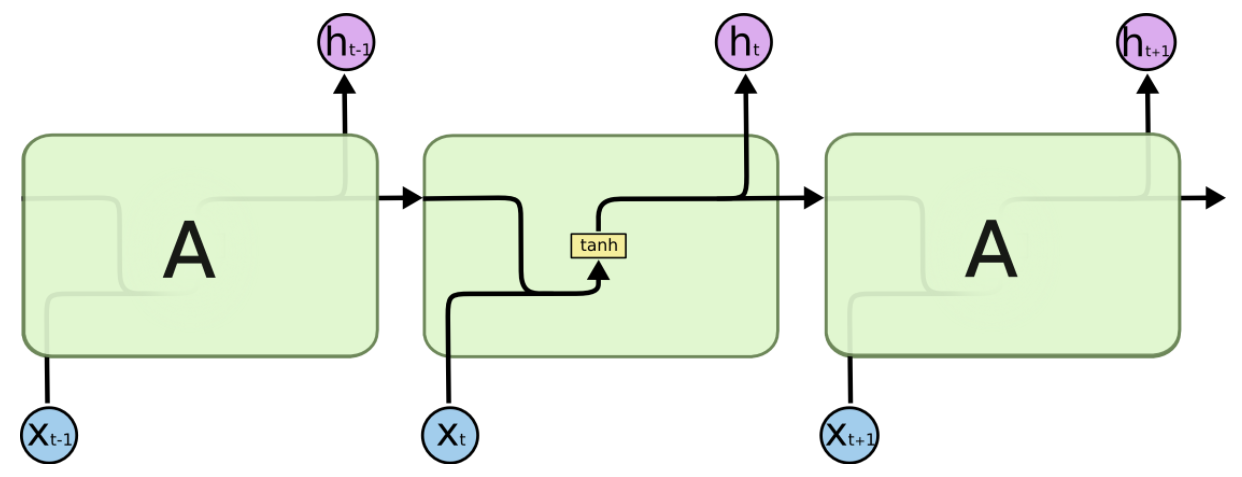
時刻tの入力をXt、t-1の隠れ層をhtをすると、以下の式で隠れ層htが更新される。
h_t = \tanh(WX_t + Uh_{t-1})\\
LSTM
前述したVanilla RNNでは勾配爆発や消失の問題が発生し、
過去の状態を長く保持できない問題があります。
そのため、新しくLSTM(Long Short Term Memory)というRNNのモデルを考えました。
以下の図となります。
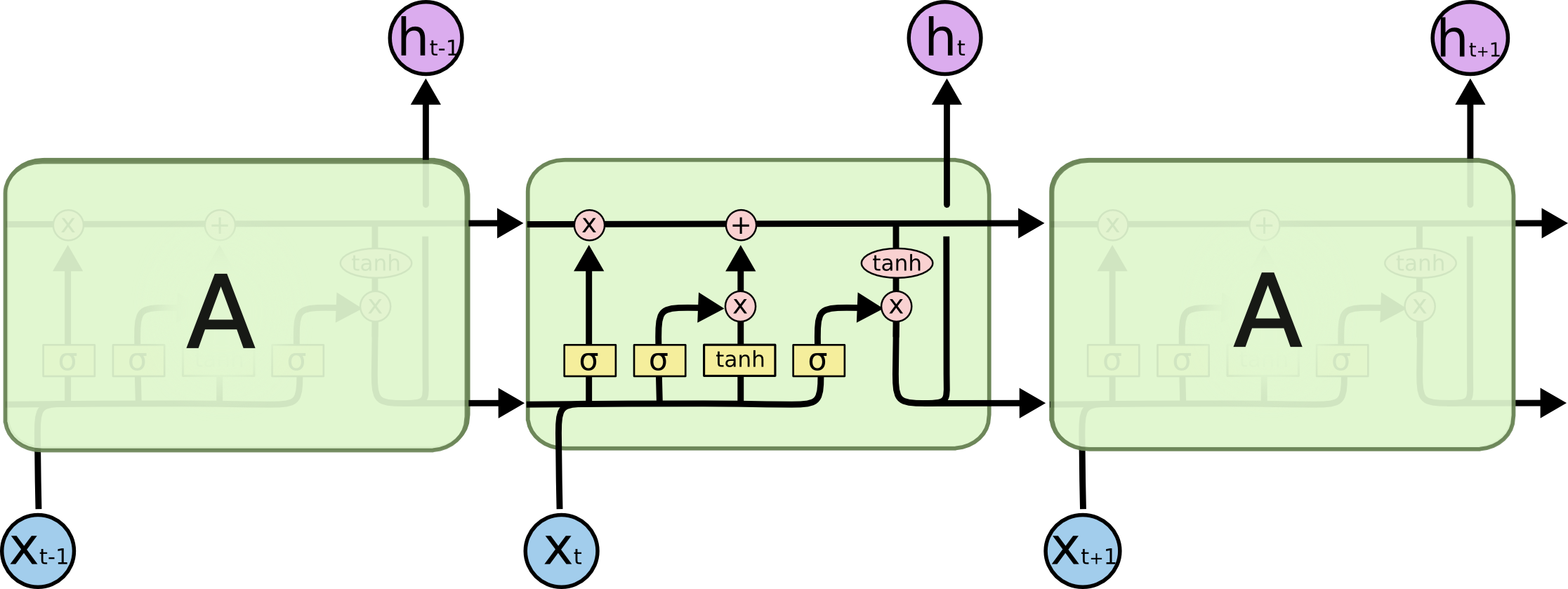
LSTMではVanilla RNNと比較すると、構造が複雑になっています。
LSTM上部のセル状態(Ct)を管理することにより、長期記憶を可能にしています。
LSTMの詳細な式はこちらをご覧下さい。
GRU
GRU(Gated Recurrent Unit)はLSTMの入力ゲートと忘却ゲートを更新ゲートとしてまとめたRNNのモデルとなります。LSTMよりも簡素な構造になっています。
図は以下です。

MinimalRNNの論文では以下のような更新式で隠れ層が定義されています。
※この記事に載せた図と少し違っていて、以下が変わっています。
- (1-)の素子の位置がずれている
- ztがutになっている(更新ゲートのこと)
h_t = u_t\cdot h_{t-1} + (1-u_t) \cdot \tanh(W_h (r_t \cdot h_{t-1}) + W_x x_t + b_h)
※精度についてはケースバイケースでLSTMが精度の良いケースもあれば、GRUの方が精度の良いケースがあるようです。
CFN
CFN(Chaos Free Network)はVanilla RNN、GRUやLSTMの問題点を取り除くために考案されたモデルとなります。(元の論文はこちら)
どのような問題点かというと、外部からの干渉が無くても、内部状態(初期状態)によっては意図しない点に収束する問題があるという話です。
※隠れ状態の更新に問題があり、CFNでは上記の計算処理をなくしています。
CFNの隠れ層の更新式は下記となります。
h_t = u_t \cdot \tanh(h_{t-1}) + i_t \cdot \tanh(W_x x_t + b_x)
GRUと比較すると、以下の式が無くなっています。
W_h (r_t \cdot h_{t-1})
上記の式により隠れ層に複数の次元の計算が生じるとのことで、予期せぬポイントに収束(Chaotic Behavior)をするケースがあるとのこと。
(ちょっとこの話についてはCFNの論文を読んでみて、また記事を別途記載したいと思います)
上記の問題点があったため、CFNでは隠れ層の計算について制限をかけることにより、Chaotic Behaviorを防いでいます。
MinimalRNN
MinimalRNNはCFNの構造に影響され、さらに簡素化したモデルになります。
以下のようなモデルになります。

ポイントとなるのは、入力に対して一度NNのような素子を通していること。
※このΦは柔軟に関数を選べるということで下記のようなフリーコネクトなNN以外のケースも考えられるのだと思います。(本論文ではΦは下記の式となります)
\Phi (X_t) = \tanh(W_x X_t + b_z)
隠れ層の更新式は下記となります。
h_t = u_t \cdot h_{t-1} + (1 - u_t) \cdot z_t
GRUと比較しても、計算式や図が簡素化していることがわかります。
※上記により計算効率があがっていることが論文にも記載されています。
Latent representation
後で加筆します。
Trainability
後で加筆します。
各RNNの精度、効率比較
各RNN(VanillaRNN、GRU、CFN、MinimalRNN)において、精度や効率を比較しています。
実験の目的としては、「ユーザーの履歴から、該当ユーザーが興味あるアイテムを提案すること」となっています。(レコメンドシステムですね)
※上記のレコメンドシステムの学習モデルをRNNを使って構築しています。(ユーザー履歴は時系列データのため、RNNが適切なのかと思います)
そのRNNのモデルをVanillaRNN、GRU、CFN、MinimalRNNで置き換えて、各計測を行います。
データセット
億単位のデータセット(1つのデータにitemId、pageId、timeが含まれる)があるが、
履歴情報としては直近数カ月の500データのみにフォーカスしています。
また、レコメンド対象となるアイテムは過去48時間のうちの500万アイテムに限定しています。
効率
効率に関する計測結果を下記に示します。
※縦軸はmean-average-precision(平均適合率)の値となります。

VanillaRNNは勾配が爆発した結果、適合率が全く上がっていないですね・・。
CFNやGRU、MinimalRNNは似たような値に落ち着きますが、一番右端の結果を見ると、
MinimalRNNの方が早めに適合率が上がっていることがわかります(つまり効率が良いということ)
Latent Representation
後で加筆します。
Trainability
後で加筆します。
※この実験でMinimalRNNが他のRNNモデルと比較して、より長い過去の記憶を保持できることが結果として出ています(って書かれているはず)
結論
実験結果から他のRNNモデルと比較して、効率的かつ長い記憶を保持することはわかりましたが、他のタスクにおいては有用かは同様かは不明です。(そのため実験がまだ必要ということ)
Φはシンプルな1層なフリーコネクトレイヤーとなっていますが、他の複雑なレイヤーを試してみるのも興味深いといえます。
所感
後で加筆します。
最終日は@pankona さんからGo言語に関するお話となります!