論文紹介(T5)
はじめに
今回は、社内勉強会向けにT5(Text-to-Text Transfer Transformer)の論文を読んだので、
その内容について少し解説したいと思います。
※私の乏しい英語力 + ページの多さに圧倒されて、対していまとめられていないですが、参考になれば幸いです涙
あとツッコミ所、誤りなどあれば、(コメントなどで)ご指摘いただけると大変助かります。。
基本情報
また、前提知識として、Transformerの知識は合ったほうが良いです。
こちらの記事はとても良くTransformerについてまとまっているので、(Transformer良くわからん!という方は)ぜひご一読してみてください!
概要
自然言語処理領域においても、近年では、事前学習モデルを利用したfine-tuningにより、
各種タスク(質疑応答、要約、翻訳など)の精度向上を行っています。
※これを、「転移学習(Transfer Learning)」と呼びます。
有名なモデルで言えば、BERT、XLNet、ALBERTなどが挙げられます。
※これ以外も多くモデルが提案されています。
T5の論文では以下の点について、特に触れています。
- 各種タスクで、fine-tunineをしやすくするために、Text-to-Text(inputもoutputもTextとする)の統一したフォーマットとした。
- 既存の手法・設定値(以下)の比較を行うために、各種実験を行った。
- モデル構造(ベースはTransformer)
- 教師なし学習の手法(事前学習の手法)
- 教師なしのデータセット
- Fine-tuning
- バッチサイズ、トレーニングステップなど、その他のハイパーパラメーター
T5とは?
T5は、Text-to-Text Transfer Transformerの略語となります。
T5自体は、「入力も出力もテキストにして、どのタスクにおいても統一し(= Unified)、転移学習を行う」という題目が重要で、
内部のモデル構造・学習手法については色々と変更して実験を行っています。
※ここは多分合ってるはず・・。
論文中にある以下の図を見ると、(T5の入出力が)イメージしやすいかと思います。

どのタスク(分類、質疑応答、要約、翻訳など)においても、入力も出力もTextで返しておるのが特徴的です。
※Text-to-Text自体は参考にしている論文がありそうですが、様々なタスクで統一しているフォーマットで行なっているのはT5が初っぽい?
どのタスクか?をモデル側に理解するために、タスク内容を入力文章にPrefixで与えています。
参考までにBERTでfine-tuningする場合の図を下記に載せます。
※タスクに応じて、出力の形態(分類系ならばラベルを返すし、質疑応答のような場合は文章を返すし)

既存手法の色々まとめ、精度比較
T5では、Text-to-Text(= Unifiedなinput, output)に拘っていますが、
他のモデル構造、データセット、教師なし学習時の手法などについてはパラメーターとみなして、
(どれが重要かを見るために)色々な手法を試して実験をしています。
下記に各種情報をまとめていきます。
モデル構造
ベースはBERT、XLNetなどと同様にTransformerとなりますが、
近年ではTransformerのEncoderのみやDecoderのみを使ったモデルも多く、
どのモデル構造が精度に貢献するか?を確認していきます。
モデル構造としては以下の3つのパターンに分類されます。
- Encoder-Decoder
- Language Model
- Prefix LM
他論文を読んでなかったため、PrefixLMは今回初めて知りましたが、以下の図を見るとイメージしやすいです。

Encoder-DecoderはオリジナルのTransformerで採用された方式となります。
※Encoderにソース文、Decoderにターゲット文(例えば、翻訳先の文章とか)を入れて、学習処理を回しています。
※Encoderは各単語が入力のどの単語と依存があるか(= Attentionが強いか)を入力単語全てで見れるのに対し(= fully-visible masking)、Decoderは予測するために未来単語は見れないようにmaskされています。(= Causal masking)
Language ModelはTransformerのDecoder(= Causal masking)を使ったモデルが該当すると思います。
PrefixLMは、Prefix部分のみはmaskをしませんが、Prefix以降は未来単語を見せないようにmaskが入ります。
論文ではAttentionのイメージを以下のように図にしています。

また、目的関数(= Objective)を以下の二つを候補として、精度比較をしています。
※後半の比較でもう少し細かい目的関数設定が入りますが、前半では大雑把に以下です。
- Denoising(= 単語をマスクしたり、Dropしたり)
- LM(= 通常の言語モデルでの予測)
以下に比較結果を載せます。
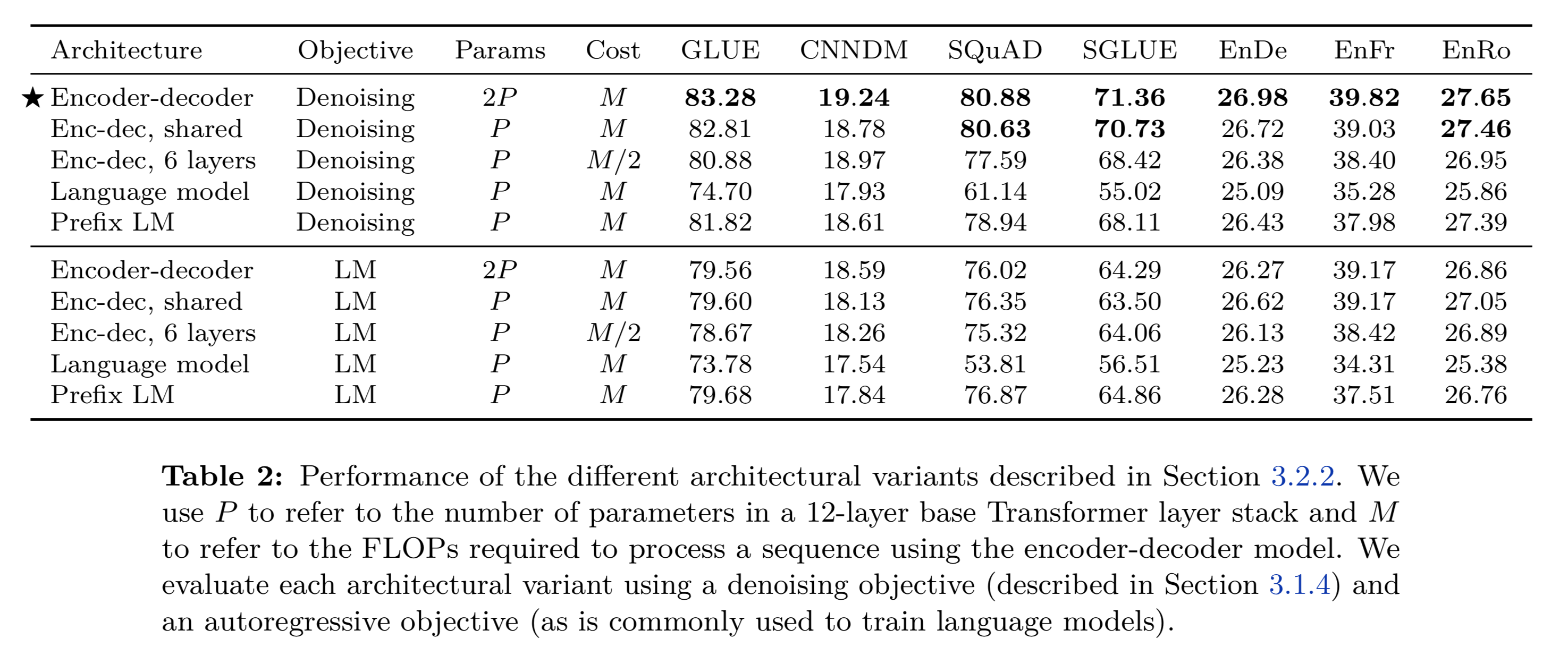
実は、モデルの構造としては、Encoder-Decoder(Transfomerのオリジナル)で目的関数をDenoisingにしたケースが最も精度が高くなっています。
※BERTやGPTなどはEncoder、Decoder単独で使ってますが、目的関数をマスクして(= MLMみたいな)、マスク部分を求めるタスクにすると、精度を上回ってしまう、ということですね。
ちなみにここで言う「Denoising」のイメージは下記の図がわかりやすいです。
※BERTのMLMのように、マスクした箇所を求める感じですね。

教師なし学習の手法
前述のモデル構造で少し触れましたが、「教師なし学習」の目的関数について、
もう少し深掘りして、パターンを模索します。
High-Level Approaches and Corruption Strategies
以下の表に目的関数のパターンを記載しています。

目的関数に対して、Inputと求めるTargetが例としてあげられています。
※上記では元となる文章は「Thank you for inviting me to your party last week.」となります。
Targetsに「original text」と記載されているのは、元の文章を予測する、という意味です。
※なので、mask tokensとreplace spansでは同じ穴埋めですが、前者は元の文章を全文出すのに対し、後者はマスクされた箇所のみの予測になっています。
BERT-Styleの場合、xx%の単語をマスクするか・ランダムな単語に入れ替えるか、という処理を行なっています。
※後述する実験結果のMASS StyleもBERT-Styleと似ているようですが、詳細はこちらの論文を読む必要があります。
各目的関数での精度は下記結果にまとまっています。
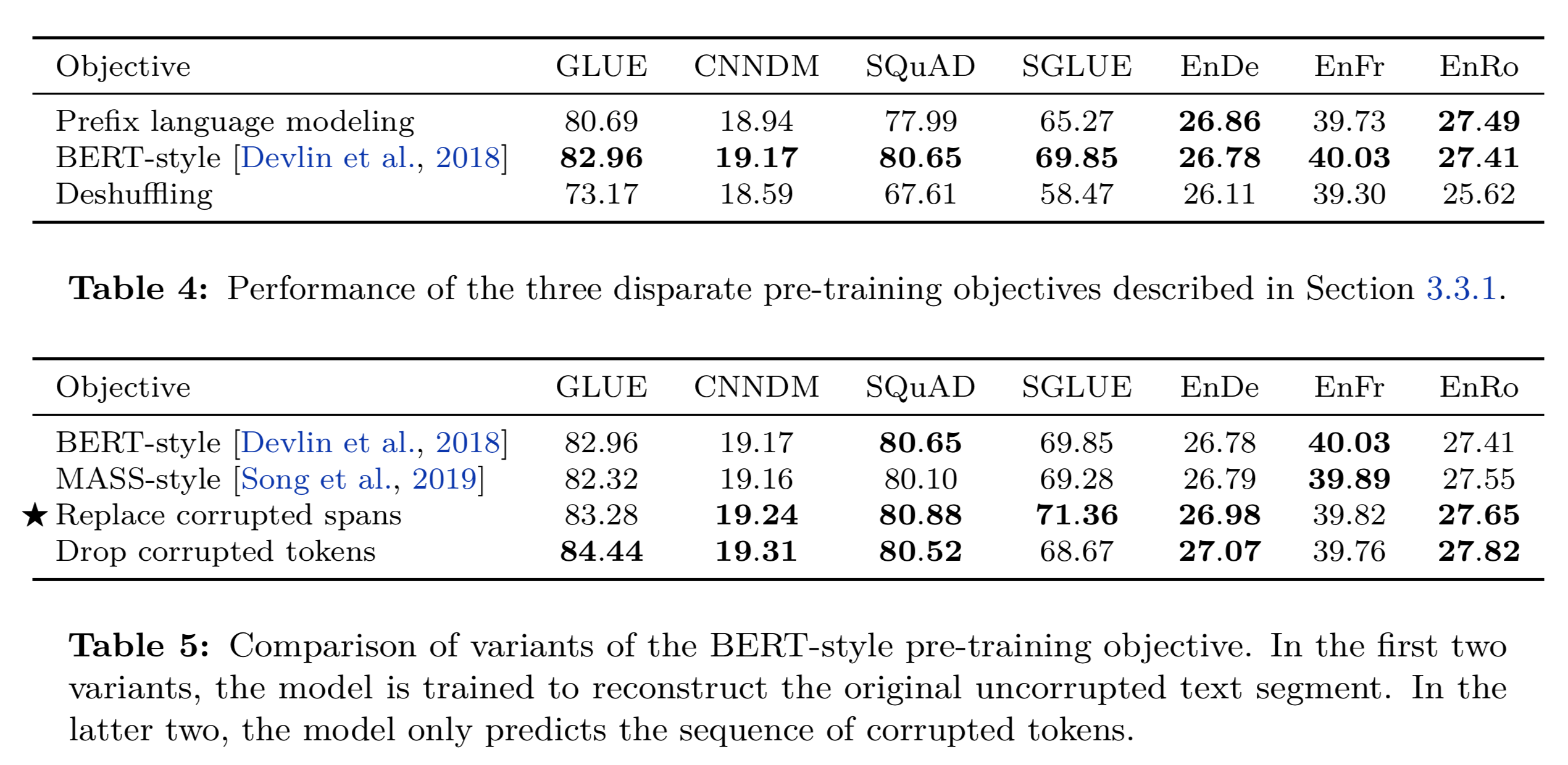
Table5では、BERT-Styleのマイナーチェンジ(Maskのみだったり、単語をDropしたり)をメインで精度比較しています。(それは、Table4でBERT-StyleのMLMが最も精度が良かったためです)
上記のTable5を見ると、ReplaceかDropのパターンが精度が高い事が分かります。
ただし、DropではSuperGLUEの精度がReplaceと比べて結構低くなっているため、本論文ではReplaceを最も精度の良い事前学習手法として捉えています。
Corruption Rate
次にMaskする割合(ここでは、Corruptionと言っている)を変更して、精度をみていきます。
精度結果が下記です。

実は前段のTable5の結果では、Corruption Rateを15%で固定にしていたのですが、Table6(Replaceを利用)の結果から、Rateは15%が最も精度が良い事が分かります。
Corrupted Span Length
更に、マスクするトークン毎の平均長(= average span length)を変えることにより、どのように精度に影響がでるかを検証します。
※例えば、500個の単語列に対し、Corruption Rateを15%にした場合、500×0.15=75単語がマスク対象となります。ここで、(マスクされる)平均トークン長を2,3,5,10とすることにより、どのように精度が変わるかを検証している、ということになります。
検証結果は下記となります。
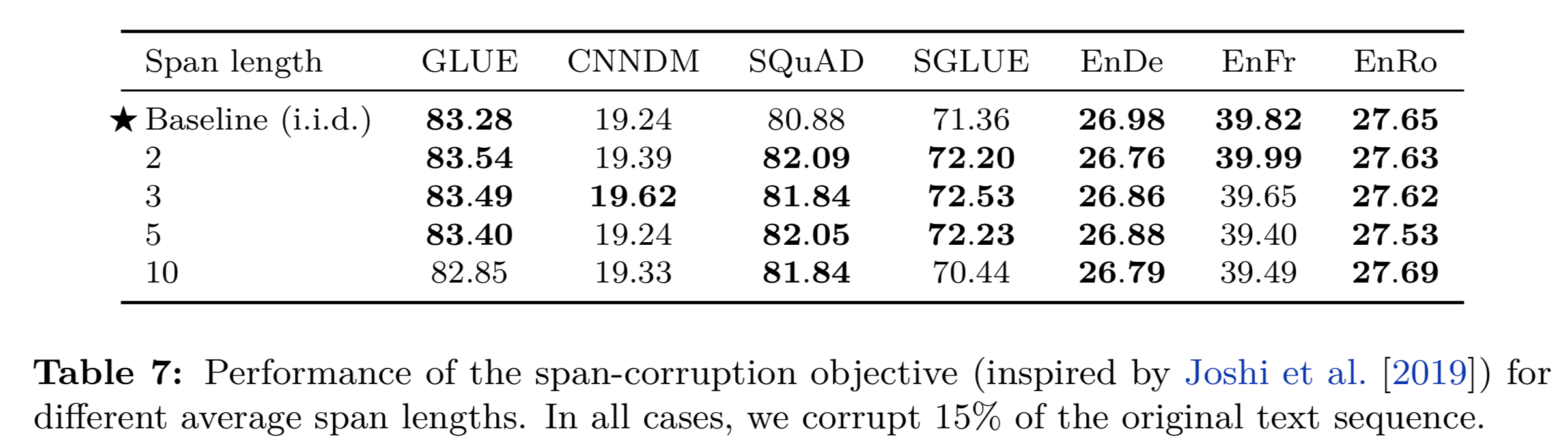
上記結果から、Average Span Lengthとしては、3が良さそう、ということが分かります。
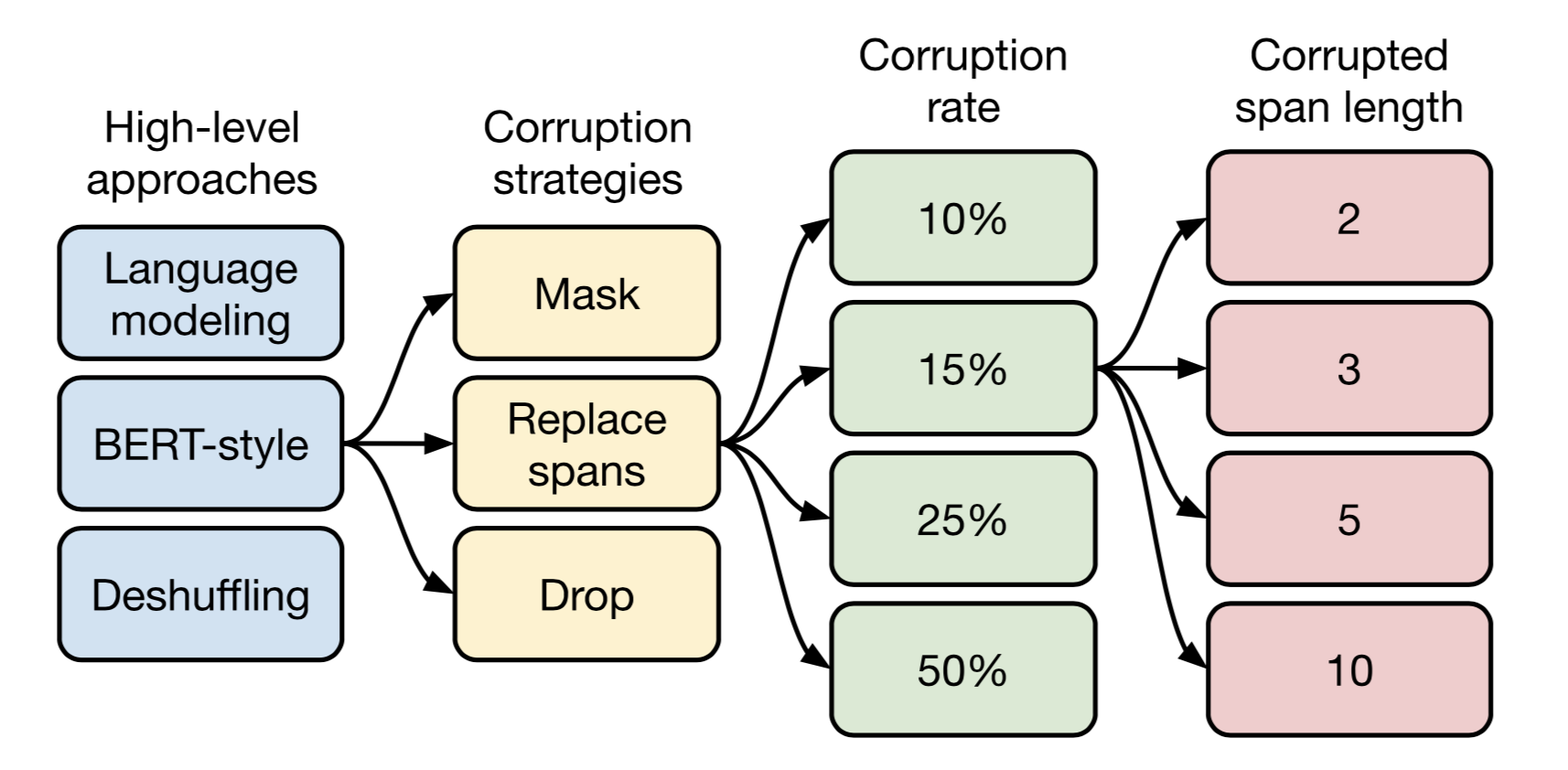
まとめ(教師なし学習手法)
最終的にまとめると、以下のようなフローになります。
事前学習に利用するデータセット(Pre-training dataset)
検証に利用するデータセットと精度結果については、下記表にまとまっています。
※事前学習は教師なし学習(unlabeled dataset)となります。

T5では、[C4(Colosal Clean Crawled Corpus)](Webページをクローリングしたデータセット)を前処理を行い、データセットとして主に使います。
※前処理をしていない場合のC4を便宜上「C4, unfilterd」としています。
※前処理の内容についての詳細は論文をご覧ください・・。
ここの結果からわかることは、以下です。
- 単純にデータサイズが多いだけでは精度は上がらない
- ドメイン固有(タスクに適した)のデータセットで学習した方が精度が高くなりやすい(C4のデータの多様性を凌駕する)
割と当然といえば当然ですが、改めて検証をしている、と言った感じですね。
また多様性と繰り返し学習のどちらが良いのか?というのを下記の検証で行なっています。
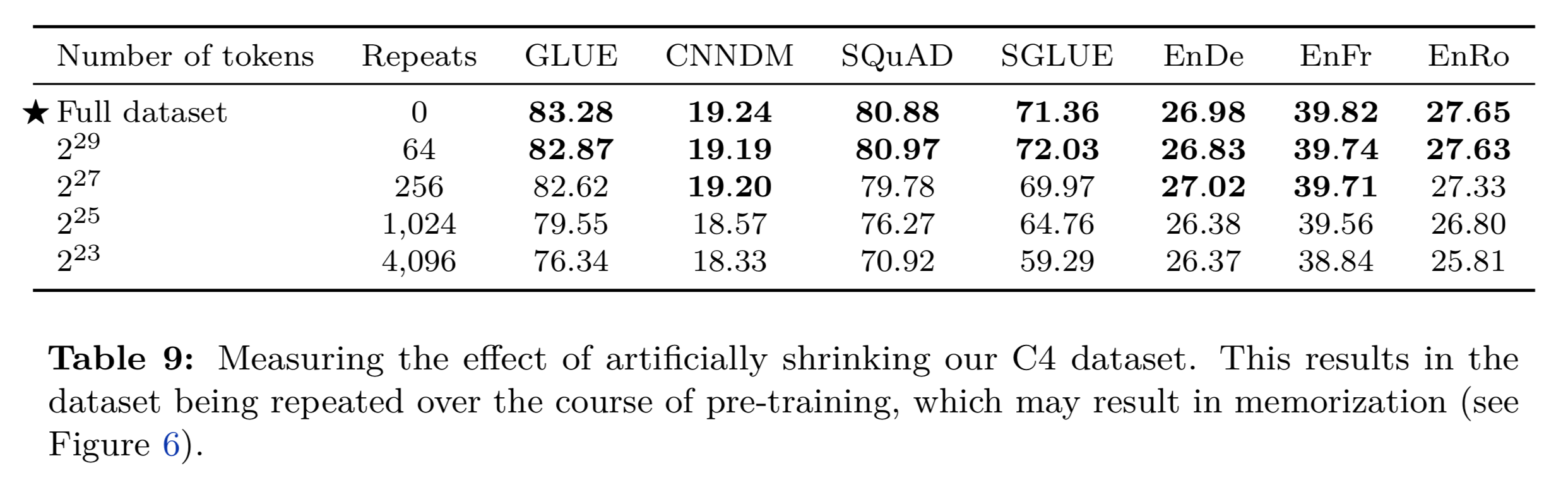
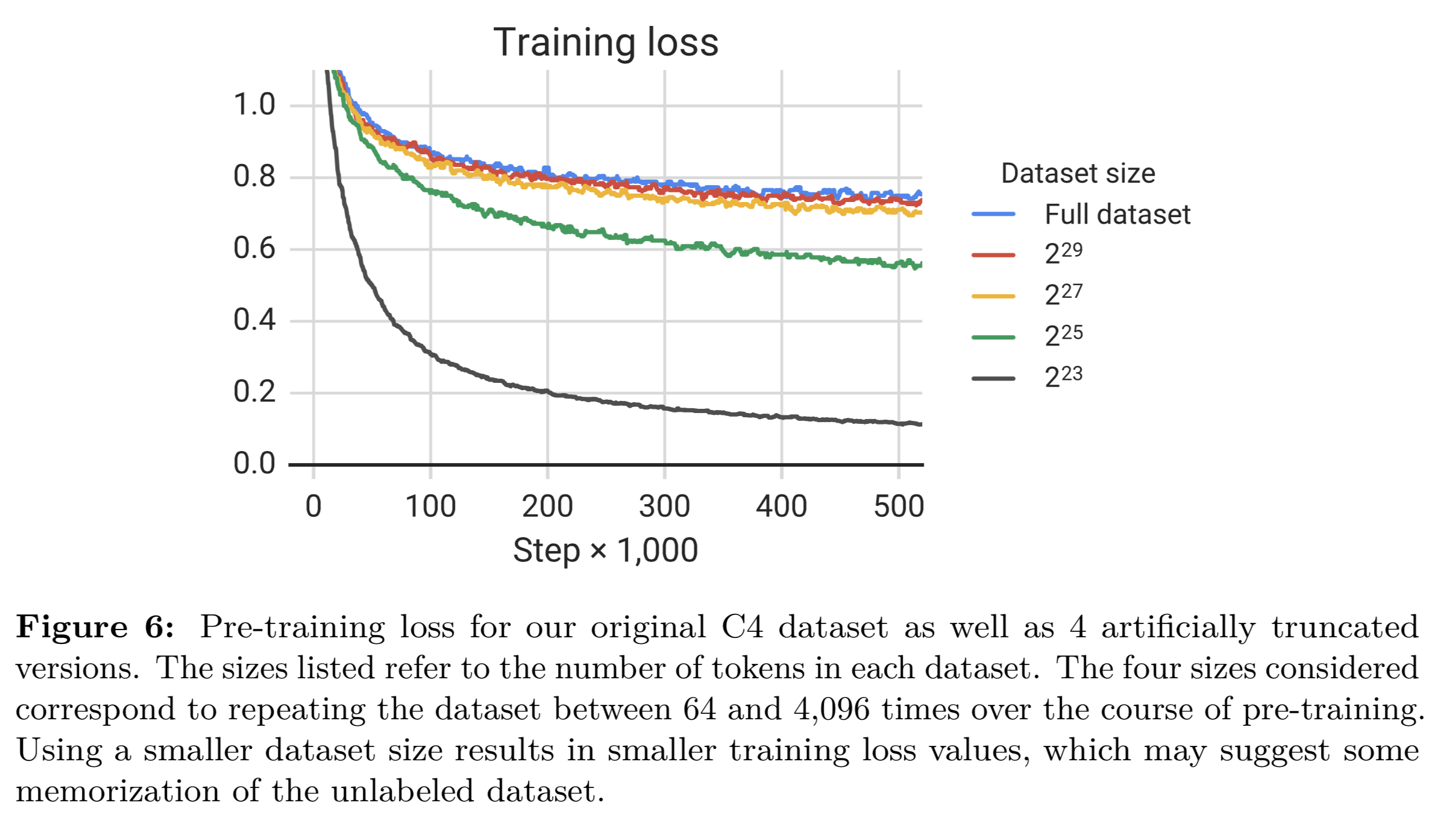
結論から言うと、(モデルのパラメーターサイズに大きく依存すると思いますが)
- 多様なデータで学習した方が最終的な精度は高い
- 少ないデータセットだと学習のロスは収束するが、精度は低くなる。(過学習状態)
Fine-tuning
Fine-tuningの手法について、いくつか試しています。
まずは、Fine-tuning時にどのパラメーターを変更するか?という観点です。

- Adapter LayersはDense + ReLU + Denseの層で構成されています。(最終層に追加される)
- Adapter Layers以外はチューニング対象とならず、Freezeされます。
- Gradual unfreezingは(学習ステップ数に応じて)徐々にチューニング対象のパラメーターを増やす手法です。
- All Parametersはモデルの全てのパラメーターをチューニング対象とします。
結論としては、全パラメーターをチューニングした方が精度が高い、という事です。
※Adapterを入れるのを試したのは、事前学習モデルの状態をなるべく保持した方が精度が高いのでは?という仮説を立てたため、だと思います。
ちょっと(力が尽きてきたので、、)省略しますが、最終的な(Fine-tuningに関する)比較結果は下記となります。
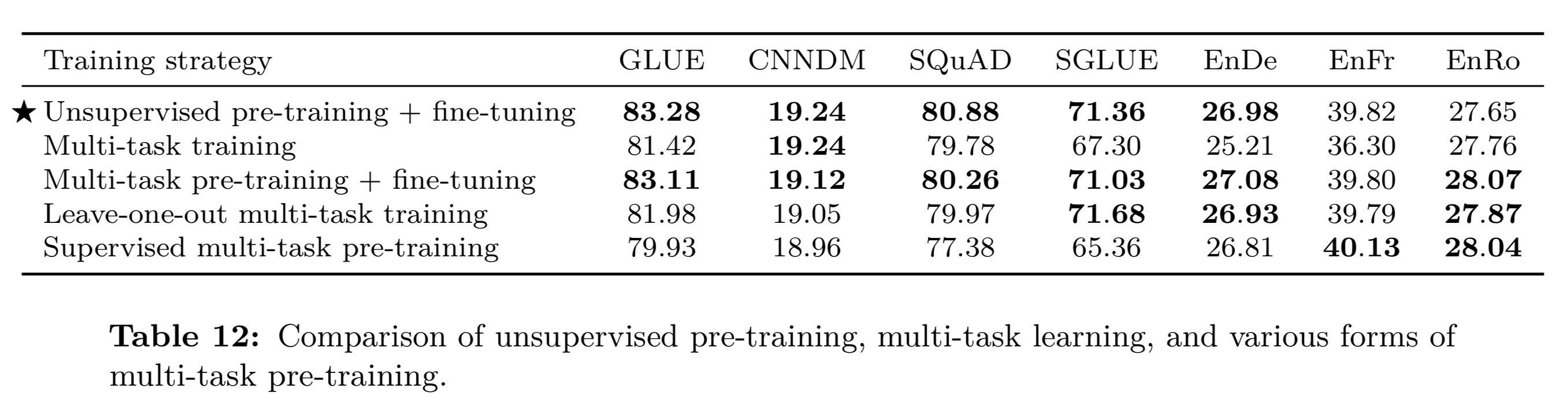
通常は「事前学習+fine-tuning(タスク毎)」の組み合わせですが、タスクによっては「Multi-task pre-training + fine-tuning」(複数タスクで事前学習をおこなって、該当タスクでfine-tuningする)が上回ることがあります。
その他パラメーター(Scaling)
ここでは、パラメーター数・バッチサイズ・学習ステップ数(training steps)・アンサンブル(事前学習モデルを複数使う)を変更して、精度の推移を検証していきます。
結果を下記に記載。
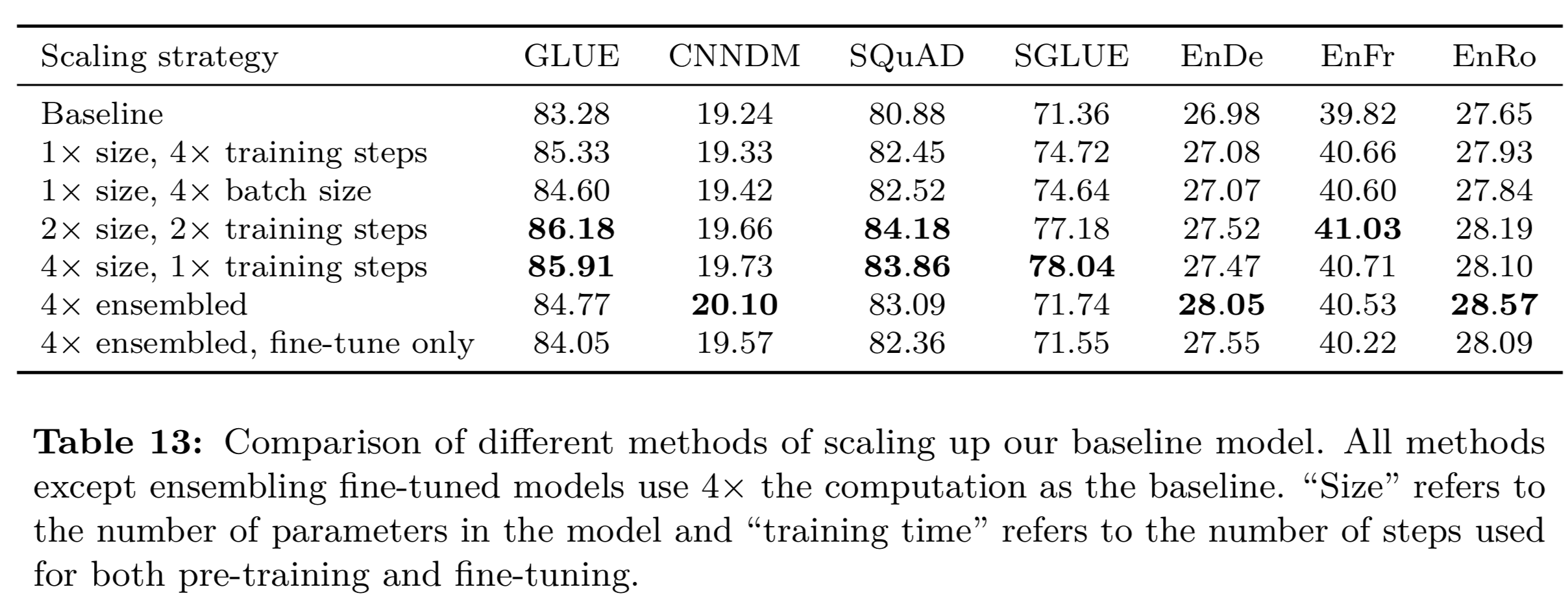
結果は想定している感じもしますが、各種値をあげた方が精度は基本的に向上する印象(ベースラインと比較)です。
実験(これまでの結果を受けて)
「既存手法の色々まとめ、精度比較」の各種結果を受けて、パラメーターやモデル構造・事前学習に利用するデータセットなどをFixして、各種タスクでSoTAなモデルと比較した結果が下記となります。

パラメーター数ですが、以下のようになります。
- T5-Base : 220million
- T5-small : 60million
- T5-Large : 770million
- T5-3B : 2.8billion
- T5-11B : 11billion
また、パラメーター数に応じて、事前学習するデータセットサイズも変更しているようです。
上記の結果を見ると、以下がわかります。
- パラメーター数とデータセットサイズは正義!
- 翻訳タスクについては、SoTAに及ばない。(これは、事前学習で英語コーパスのみを使ったからではないか?という話が問題としてあがっていました)
- Back TranslationによるData Augmentation手法を取り入れる必要があるかも?と記載が論文にありました。(Back Translationは端的に言うと、英語->ドイツ語->英語、と戻した際に元に戻るように学習させる手法、となります)
まとめ
途中、もはや力尽きた記載になってきましたが、この論文を読んだ所感としては、、
- やはりモデルサイズ(+ それに適したデータセット数)は正義!
- マルチタスクに対応する手法として、UnifiedなText-to-Textはシンプルなアイディアだけど、効果的(従来のようにタスク特化なレイヤー追加が不要)
- リソースが乏しい空間では以前として、最適なモデル検証が必要。(これは著者も述べている)
参考サイトなど
- https://lib-arts.hatenablog.com/entry/nlp_dl26
- https://lib-arts.hatenablog.com/entry/nlp_dl27
- https://lib-arts.hatenablog.com/entry/nlp_dl28
- https://lib-arts.hatenablog.com/entry/nlp_dl29
- https://lib-arts.hatenablog.com/entry/nlp_dl30
- https://medium.com/syncedreview/google-t5-explores-the-limits-of-transfer-learning-a87afbf2615b
- https://towardsdatascience.com/t5-a-model-that-explores-the-limits-of-transfer-learning-fb29844890b7
- BERTの論文
- BERTやTransformerの理解を助けるサイト