この記事は 株式会社 ACCESS Advent Calendar 2019 18 日目の記事です。
やっはろー! @shotasakamoto です!!
ギリギリの投稿ですいません!!!!
もうすっかり冬な季節ですが、みなさま、いかがお過ごしでしょうか?
健康には気をつけましょう〜。(私は風邪ひきました・・涙)
ではでは、早速記事の内容に入っていきます。
今回は、お仕事でServing周りの調査で、TensorRT Inference Serverについて調査する機会があったので、今回少し紹介したいと思います。
TensorRT Inference Serverとは?
TensorFlow Serving(TFS)やTensorRT Inference Server(TRTIS)のような、Serving Frameworkは、
Deep Learningの機能をAPI提供できるような仕組みをある程度備えています。
MLOps(DevOpsのMachine Learning版)の機能を有しており、
昨今でDeep Learningをサービス運用する際には、上記のようなServing Frameworkを導入することにより、
大幅なコストダウンが見込める可能性があります。
TRTIS自体は、NVIDIAが公開しているServing Framework(OSS)となっています。
下記のリポジトリやdocumentを読むと、TRTISの詳細が分かるようになっています。
※あんまり日本語で詳細解説している記事は少ないような・・。
- githubリポジトリ
- https://github.com/NVIDIA/tensorrt-inference-server
- document
- https://docs.nvidia.com/deeplearning/sdk/tensorrt-inference-server-guide/docs/index.html
ちなみに本記事を書いている際のリポジトリのコミットハッシュは、
9fe48c19e6e8639d08d3e234f6233278ef7121d4 です。
※masterブランチを見てます。
また、TRTISの実装はC++になっています。(私のC++レベルが低すぎて、カスタマイズが中々大変・・涙)
具体的にどんな機能を持っているの?
上記をみるとわかりますが、軽く噛み砕いて説明してみます。
Multiple framework support
後述しますが、複数のDNNフレームワークのモデルをサポートしています。
Concurrent model execution support
複数モデル(もしくは同一モデル)を同時実行可能にする仕組みとなります。
※下記の図が分かりやすいです。
下記のようにインスタンスグループを設定することで、モデルの実行インスタンスを増加することが可能になっています。
Batching support
TFSでもサポートされていますが、入力データを複数重ねることで、
トータルのスループットを増加させる仕組みとなります。
※DNNで演算処理をする場合、基本的にまとめてデータを処理した方が演算速度が向上することが知られています。
ただし、データをまとめて処理するため、レイテンシ(遅延)も上がる可能性があります。
Batchingを行う際に、どのようなタイミングでバッチ化するか?というのをスケジューラーが決めていますが、
同一のクライアントからのリクエストに対しては、同一モデル(同一コンテキスト)で推論処理を行うようなステートフル対応を行えるスケジューラーもあります。(= Sequence Batcher)
Custom backend support
対応しているDNNフレームワークごとにBackendが用意されています。
※実装はこちら
ただし、対応していないフレームワークで、何か処理を実行させたい場合(ex. 画像のリサイズ、違うフレームワークでの推論処理など)に困ってしまいます。
そこで、TRTISでは、CustomBackendというBackendもあり、このBackendを使って、カスタマイズした処理をTRTIS側で実行可能です。
※詳細は後述します。
Ensemble support
TFSでは対応していませんが、TRTISでは、Ensembleモデルを構築することで、
モデル(やカスタマイズした処理)のパイプライン処理(= 処理を繋げる)が可能になります。
イメージとしては、こちらのensemble_schedulingを見るとイメージしやすいです。
この場合、2step(= 2つの処理)でモデルを構築しています。(上記のサンプルで実行されているのは下記です)
- 画像の前処理(= preprocessed_image)
- resnet50(= resnet50_netdef)
Multi-GPU support
単純に複数GPUを利用した推論処理が可能です。
Model Management
TRTIS(や他のServing Framework)ではモデルを利用するため、モデルのロード・アンロードタイミングを定める必要があります。
TRTISの場合、以下の3つの推論実行モードが選択できます。
※下記のパターンで、それぞれモデルのロード・アンロードのタイミングが異なります。
Model Control Mode NONE
- サーバー起動時にモデルを全てロードする。(ロードできないモデルはUNAVAILABLEとなる)
- サーバー起動中にモデルの変更処理は無視される。
Model Control Mode POLL
- サーバー起動時にモデルを全てロードする。(ロードできないモデルはUNAVAILABLEとなる)
- サーバー起動中にモデルの変更処理が可能。(ただし、pollingしてモデルを変更する。モデルに変更がある場合、ロード・アンロードを行う)
Model Control Mode EXPLICIT
このモードはまだ実験段階となっています。
- サーバー起動時にモデルはロードされない。
- モデルのロード・アンロードは全てModel Control APIを利用して、行う必要がある。
health endpoints
TRTISを稼働させている推論サーバーに対し、リクエストが可能か?を確認するためのHealth endpointが提供されています。
/api/health/live で 200 が返って来れば、リクエストが要求可能となっており、
それ以外だった場合サーバが初期化中か、なんらか方法で失敗してリスエストが処理出来なかったことを示します。
また、モデルのロード状況などはstatusのapiにアクセスして、取得可能となります。(下記のような感じ)
https://docs.nvidia.com/deeplearning/sdk/tensorrt-inference-server-guide/docs/run.html#checking-inference-server-status
Metrics
上記のように、GPUの利用率(メモリ利用率含む)などの情報をAPI経由で取得が可能になっています。
(メトリクスの内容としては、 Prometheusで取れるものになっています)
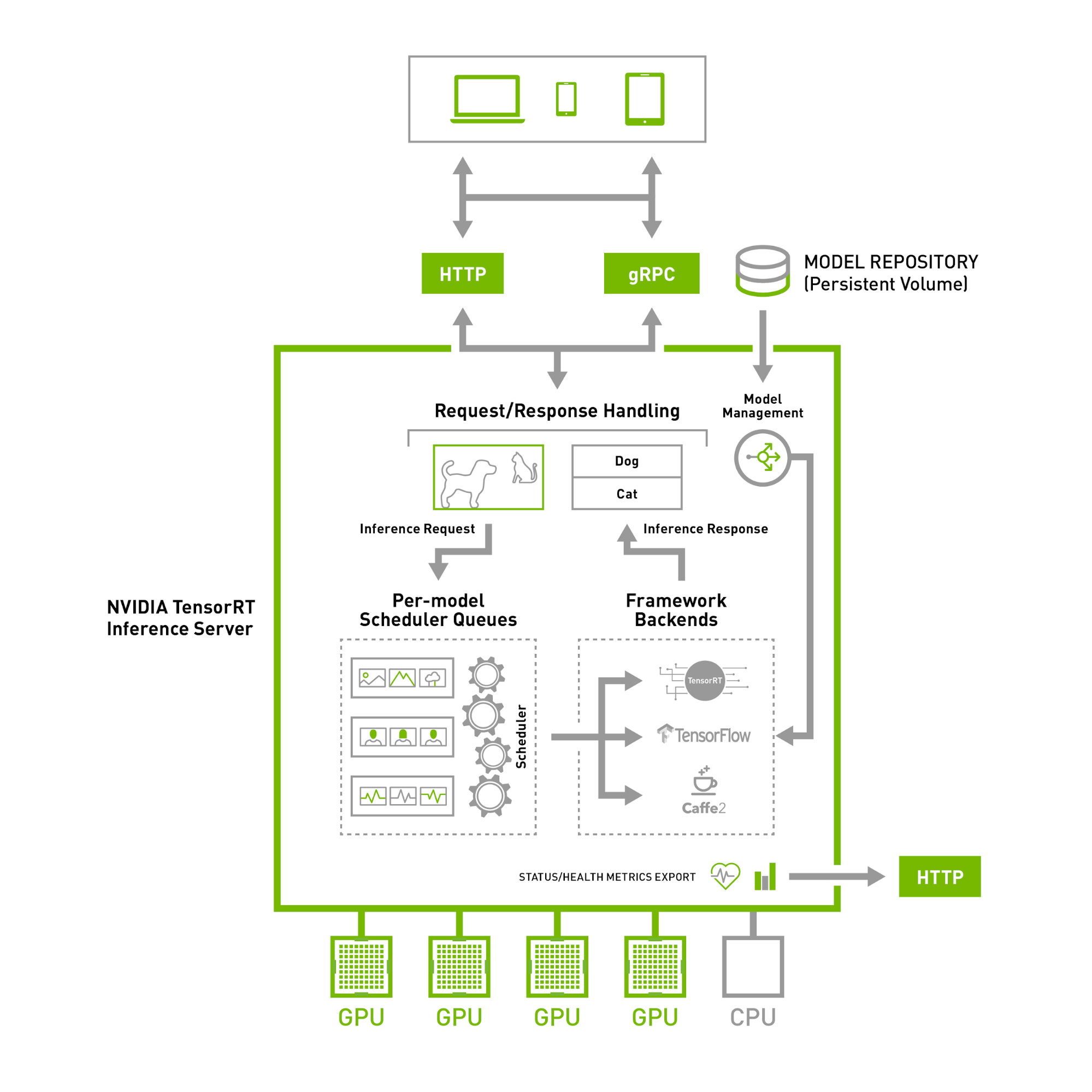
どんな構成なの?
https://docs.nvidia.com/deeplearning/sdk/tensorrt-inference-server-guide/docs/architecture.html#architecture
上記の図を見ると分かりやすいです。(本記事にも図を引用します)
試しに使ってみたい場合は?
DockerFileがあるので、Docker Imageを作って、docker runすれば良い。
※ただし、ビルドに結構時間がかかる・・。NVIDIAのGPUがあった方が動かしやすいが、CPUのみでも動かすことは可能。
(その場合、makeする際のオプションをいじった方が良い)
DockerFileを利用する場合
TRTISでは、マルチステージビルドを使っているため、各ビルドでタグを付けた方が、
後々良かったりします。
※特に、ソースを実際にビルドするためのイメージとかはタグを付けた方が、追加でビルドしたい時とかは便利です。
CMake経由でビルドする場合
こちらはより細かくビルドオプションを設定したい場合に見ておいた方がいいです。
対応フレームワークは?
対応しているDeep Learningフレームワークは下記となります。
こちら を見ると、分かります。
- caffe2
- onnx
- pytorch
- tensorflow
- tensorRT
他フレームワークのモデルを利用したい場合は?
以下の二つの手法があります。(多分・・)
- InferenceBackendを継承して、フレームワークに合わせたBackendを作成する
- CustomInsntaceを継承して、CustomBackend経由でフレームワークの推論処理を動作させる
前者については、Caffe2のBackend実装やONNXのBackend実装が参考になります。
後者については、前処理/後処理を動かしたい場合にも関連するため、
後述いたします。
前処理/後処理をサーバー側で実行する場合は?
CustomBackend経由で、処理を呼び出すやり方を採用するのが良さそうです。
CustomBackendからは、CustomInstanceを継承したインスタンスが呼び出し可能になっています。
よって、CustomInstanceを継承したクラスを実装し、xx.soファイルとしてモデル登録をすれば良い、となります。
ここは、サンプルで実装されているimage_preprocessの中身を見ると、イメージがつきやすくなります。
ちなみに、CustomInstanceで実装すべきAPIはcustom_instance.hで定義されています。
※主な処理はExecuteに書く感じですね。
本当はサンプル実装したCustomInstanceを自分のリポジトリにあげたかったですが、ちょっと間に合ってないので、
今回の記事としてはここまでになります・・涙
最後に
いかがでしたでしょうか?
TRTIS自体は中々使い勝手の良さそうなServingフレームワークですが、いまいち知名度がない感じがしています。
(なので、もっと知名度上がって欲しい)
知名度の高いTFS(Tensorflow Serving)と比較すると、TRTISは「使い勝手が良さそう+機能性も多そう」、な印象ですが、実際どうなんでしょうかねぇ?
まだまだここら辺は勉強中です(ツッコミ大歓迎!)
次は、 @aym さんの記事になります!乞うご期待!