はじめに
こんにちは、エス・エム・エスでSREとしてカイポケの開発・運用をしている小笠原です。この記事はエス・エム・エス advent calendarの23日目の投稿です。
年末になって今年の振り返りなどをやっていく時期ということで、今年流行ったものを思い出すとChatGPT(生成AI)が印象的ですよね。
ChatGPTが世に出てから早くも1年が経過しました。日本でも話題になってから普及するのは早かったですね。調べてみると 2023/12/13 時点でZennでは1294件のArticles、Qiitaでは4056件の記事が投稿されており注目されています。


ChatGPTについて振り返っていく
私自身も業務においてChatGPTにたくさんお世話になったという"印象"があるのですが、実際どのくらい活用したのかやどのくらい業務に役立てたのかというのは特に評価していないことに気づきました。それなりにデータ(会話数)も積もってきたのでこのタイミングで定量的に評価&考察していきたいと考えました。
利用するデータ
私のChatGPTの会話データを利用します。期間は2023年3月30日~2023年11月25日のものを対象としました。一部業務と関係ない会話はデータから除外しており、サンプル数は357です。
ChatGPTのバージョン
2023年4月〜8月はモデル4(有償版)を、それ以外の期間はモデル3.5(無料版)を利用しました。
データの取得方法
ChatGPTの管理画面でエクスポートして取得しました。全件取得できるのはありがたいですね。
ちなみにエクスポートの処理を進めるとメールでzipファイルが送られてきて、中身を見ると以下のようなファイルが入っています。
5a607ab5c3b3710b467cbf9e3e21697d8269a69f149a75d6b1dfca95b27169e4-2023-11-25-06-16-40
├── chat.html
├── conversations.json
├── message_feedback.json
├── model_comparisons.json
└── user.json
その中の conversations.json ファイルに会話に関する全情報が入っており、chat.htmlをブラウザで開くとChatGPT上でその会話を展開してやりとりを確認できるようになっています。
jsonデータの構造については公式サイトで説明を見つけられなかったのですが、読めばなんとなくわかります。
データの加工
分析するにあたって conversations.json を以下の手順に従って加工しました。
- 必要な情報に絞ってcsv化
- 無関係な会話の削除
- 会話の評価&分類
加工処理①: 必要な情報に絞ってcsv化
conversations.json を first question(会話の最初のユーザ質問の内容)、create_time(最初の会話の作成日時)、質問回数の項目を持つcsvに変換しました。

これでどのくらいの頻度で会話や質問回数を行ったか分析できるようになります。
なお、会話のIDではなくfirst questionを入れたのはchat.htmlをブラウザで開いて過去の会話を探すときに該当の会話が見つけやすかったためで、それ以外の意図はありません。
加工処理②: 無関係な会話の削除
基本的に業務に関する質問に使っていたものの、一部プライベートな会話が混じっていたのでデータから削除しました。全部で25件ありました。
加工処理③: 会話の評価&分類
会話の評価は役立ち度に応じて以下の5段階で評価しました。
| 会話の役立ち度 | 会話の役立ち度の定義 | 備考 |
|---|---|---|
| 1 | 全く役立たなかった | ChatGPTを使った結果、大きくミスリードされてしまった場合につける |
| 2 | あまり役立たなかった | ChatGPTを使った結果、ミスリードされた場合につける |
| 3 | どちらでもない | ChatGPTを使わなかった場合と差がほとんどなかった場合につける |
| 4 | 役立った | ChatGPTを使ったことで使わなかった場合と比べてメリットを感じた場合につける |
| 5 | 非常に役立った | ChatGPTを使ったことで使わなかった場合と比べて大きなメリットを感じた場合につける |
ほとんどが2〜4に収まるものの、例外ケースを識別するために↑のように分類しました。ただし、役立ち度の判断には主観が混じる点はご愛嬌です。
また、個人的にどういう技術分野でChatGPTに質問しているかを知りたかったので会話の主な技術分野をラベリングすることにしました。
加工後のデータ
スプシにまとめて以下のような具合です。

分析
スプシにまとめたのであとは分析するのみです。
会話数&質問数
まずは会話の総数や営業日あたりの数は以下のようになりました。なお営業日は2023年3月30日から11月25日の期間で計算し、休暇も含めました。
| 会話総数 | 質問総数 | 営業日総数(実績ベース) | 営業日当たり会話数 | 営業日当たり質問数 |
|---|---|---|---|---|
| 365 件 | 971件 | 156日 | 2.3 件 | 5.2 件 |
毎日2件以上、ChatGPTと会話していたようです。結構多いですね。
月別会話数推移
月別で会話数がどう推移したかを見てみましょう。

グラフを見ると4月と5月は会話数が少なかったり、6月だけ会話が多くなっていますが、その後の7月〜10月は安定して40〜50個の会話をしていたことがわかります。営業日ごとの会話数で見ると2件で安定してきているようです。
なお、破線はモデル4(有償版)を利用していた時期を表していますがモデルの違いで会話数に大きな違いはありません。
念のため、モデル3.5とモデル4の間で役立ち度に差が出たかどうかを確認してみます。

グラフでは会話数推移と会話別の平均役立ち度の推移を月別で出しています。このグラフを見る限りではモデルの違いによる役立ち度の違いはないようです。
ただ、これはモデル間における回答精度の問題というよりは私のChatGPTの使い方の意図的な変更による結果も反映されていると考えています。
というのも、そもそも私がモデル4からモデル3.5に切り替えた理由が「モデル4のレスポンスが遅かったこと」と「普段質問することの多くがモデル3.5でそれなりに良い回答が返ってくること」でした。モデルの切り替えに合わせて会話自体も内容が古いものに寄った(モデル4向けの質問はしなくなった)可能性があると考えています。
会話の役立ち度の割合
次に会話が実際にどれくらいに役立ったかを確認します。

ネガティブな「あまり役立たなかった」の割合は5.6%なので、使って損するケースはかなり少なかったようです。またChatGPTを使うことでメリットが出たもの(ポジティブなものの割合)は合わせて60.4%とそれなりに打率は高かったようです。
会話の技術分野
次に会話の主な技術分野の分布を確認します。
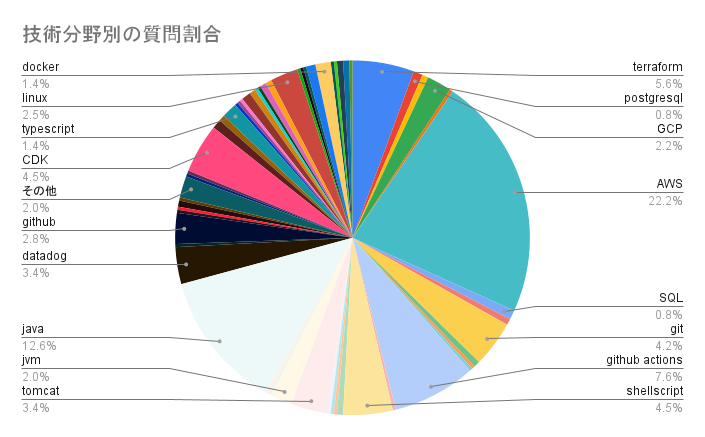
分野の分類が雑なこともありますが、様々な分野の質問をしていたことが伺えます。特に多かったのはAWS、java、github actions、terraformあたりで、自分の仕事の関心がそのまま反映されている印象です。
質問が多かった分野の役立ち度
会話数上位10件の技術分野別平均役立ち度は以下です。
| 会話数の多かった技術の役立ち度 | 件数 | 平均役立ち度 |
|---|---|---|
| AWS | 81 | 3.7 |
| java | 46 | 3.6 |
| github actions | 27 | 3.7 |
| terraform | 20 | 3.6 |
| shellscript | 16 | 3.5 |
| CDK | 16 | 3.6 |
| git | 15 | 3.8 |
| datadog | 13 | 3.4 |
| tomcat | 12 | 3.9 |
| github | 9 | 3.3 |
分野ごとに多少ばらつきがあり、最も役立ち度が低いのはgithubで3.3、最も役立ち度が高いのはtomcatで3.9となりました。
githubやdatadogのスコアが低くなったのはモデル3.5だと古いドキュメントやAPIに基づいた回答が多かったためだと思われます。一方、tomcatのスコアが高くなったのはモデル3.5でもカバーしている範囲の古いバージョンについて質問していたからだと思われます。業務で扱う分野によってモデル4を使うことで改善の余地がありそうです。
業務効率化度合いの推定
最後にChatGPTを使うことで実際業務はどのくらい改善したのかと言う評価もしておこうと思います。
そのために「業務効率化度」をChatGPTを導入したことで削減された業務時間として定義します。そして、会話の役立ち度に対して、業務効率化度(分)の項目を以下のように控えめな評価と高めの評価の2種類でマッピングします。
マッピング①: 控えめな評価
| 会話の役立ち度 | 業務効率化度(分) |
|---|---|
| 1 | -30 |
| 2 | -10 |
| 3 | 0 |
| 4 | +10 |
| 5 | +30 |
マッピング②: 高めの評価
| 会話の役立ち度 | 業務効率化度(分) |
|---|---|
| 1 | -60 |
| 2 | -15 |
| 3 | 0 |
| 4 | +15 |
| 5 | +60 |
マッピングの決め方について
2つのマッピングは主観に頼って決め打ちしました。ただ、それなりに役立ったなと思う会話で10~15分業務が効率化された、というのは大きく実体からずれてないと考えています。
集計
全期間の役立ち度別会話数は以下なので
| 会話の役立ち度 | 会話数 |
|---|---|
| 1 | 0 |
| 2 | 20 |
| 3 | 121 |
| 4 | 203 |
| 5 | 12 |
これをもとに集計すると、ChatGPTを利用した全期間(156営業日)を通して業務効率化度は以下のようになりました。
「控えめな評価」における業務効率化度(分): 2190分
「高めの評価」における業務効率化度(分): 3465分
営業日当たりに換算するとそれぞれ6分と10分となるため、1日8時間働くとして 1.3% ~ 2% の業務効率化ができた計算になります。想定よりも小さい値に収まった気がしますが、全体で平均するとそんなものかなと納得感もありました。
また、8時間働くと言いましたが技術的なことに携わって集中する時間というのは実際は少ないことを考えると、体感での業務効率化度合いとはまた違ってくるのかなとも思いました。
まとめと所感
ChatGPTを業務に導入すると、約8ヶ月で通算して1.3%から2%程度業務が効率化されたことがわかりました。また、毎日2回以上ChatGPTと様々な技術分野に関する会話を行ったことがわかり、通常よりも業務削減されるような生産的な会話の割合は全体で60.4%と高い水準であることもわかりました。
ChatGPTとの会話を振り返ってみると、一つ一つが劇的に業務を改善するというよりは小さな改善効果を積み上げていくというものだということがわかりました。会話の回答精度が今後上がっていくことも考えると、業務で活用する機会が増えることは間違いないと思います。
またこれまではモデル3.5とモデル4しか試してこなかったのですが、最近は新しいモデル(モデル4 Turbo)も出ているのでそちらも試して有用性を検証していきたいです。