はじめに
乃木坂46の一期生であり、絶対的エースである齋藤飛鳥と、ドラマにCMに引っ張りだこのKis-My-Ft2の人気メンバーである玉森裕太が似ていると思ったのでCNNで分類するアプリを作成しました。


開発環境
・MacOS Monterey バージョン12.6
・Python 3.9
・Atom バージョン1.60.0
手順
1.画像収集
2.顔抽出
3.データセット作成
4.モデルの構築・学習
5.テスト画像で動作確認
6.アプリ開発
7.アプリの動作確認
1.画像収集
画像の収集にはicrawlerを使いました。これまでに何度か使用してきましたが、あらゆる検索エンジンで画像を収集できるという利点があることを知ることができたので、今回も使用することにしました。キーワードはシンプルに齋藤飛鳥と玉森裕太で指定して、画像を収集しました。さらに画像のサイズは300x300にリサイズしました。コードは下記の通りです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from icrawler.builtin import BingImageCrawler
import os
import re
from PIL import Image
import glob
# 画像を収集するメソッド
# 引数は画像を保存するパスpath、検索ワードkeyword、収集する枚数num
def scraping(path, keyword, num):
bing_crawler=BingImageCrawler(
downloader_threads=4,
storage={'root_dir': path}
)
#検索ワードにkeywordを入れたときに得られる画像をnum枚収集
bing_crawler.crawl(
keyword=keyword,
max_num=num
)
print(f'{keyword}: scraping completed!')
#ファイルの形式はjpegなので、ファイル名には必ず拡張子.jpgがつく
asuka_path='./images/figure0/*.jpg'
tama_path='./images/figure1/*.jpg'
keywords=['齋藤飛鳥','玉森裕太']
num=600
scraping('./images/figure0/', keywords[0], num)
scraping('./images/figure1/', keywords[1], num)
# """
# 画像をリサイズするメソッド
# 引数は保存したいパスpath=フォルダ名+フォーマット名、変更後のサイズの幅と高さw,h
#
# *リサイズしたい画像はパスで指定される
# """
def resize_image(path, w, h):
img_paths=glob.glob(path)
for img_path in img_paths:
#画像ファイルに変換
img=Image.open(img_path)
#指定したサイズでリサイズをする
img_resized=img.resize((w,h))
#リサイズした画像を上書き保存、同じパスを指定
img_resized.save(img_path)
print(f'{path}: resized!')
#サイズは300x300で指定
width=300
height=300
resize_image(asuka_path, width, height)
resize_image(tama_path, width, height)
収集してリサイズした齋藤飛鳥の画像はfigure0, 玉森裕太の画像はfigure1に保存しました。
2.顔抽出
収集した画像から顔の部分を抽出します。ここではDlibを使いました。顔抽出できない画像が所々ありましたが、データを収集することができました。コードは下記の通りです。
#Dlibで顔部分を切り抜き
import cv2, dlib, sys, glob, pprint
#入力ディレクトリ指定
in_dir1="./images/figure0/"
in_dir2="./images/figure1/"
#出力ディレクトリ指定
out_dir1="./images/face0/"
out_dir2="./images/face1/"
#画像のID
fid=1000
#入力画像をリサイズするか
flag_resize=False
#Dlibを始める
detector=dlib.get_frontal_face_detector()
#顔画像を取得して保存
def get_face(fname):
global fid
img=cv2.imread(fname)
#サイズが大きければリサイズ
if flag_resize:
img=cv2.resize(img, None, fx=0.2, fy=0.2,)
#顔検出
dets=detector(img, 1)
for k,d in enumerate(dets):
pprint.pprint(d)
x1=int(d.left())
y1=int(d.top())
x2=int(d.right())
y2=int(d.bottom())
im=img[y1:y2, x1:x2]
#64x64にリサイズ
try:
im=cv2.resize(im, (64,64))
except:
continue
#保存
out=out_dir2+"/"+str(fid)+".jpg"
cv2.imwrite(out, im)
fid+=1
#ファイルを列挙して繰り返し顔検出
files=glob.glob(in_dir2+"/*")
for f in files:
print(f)
get_face(f)
print("ok")
顔抽出した齋藤飛鳥の画像はface0,玉森裕太の画像はface1に保存しました。
3.データセット作成
画像を収集したもののどうやってデータセット作ったらいいのか全くイメージできなかったので、地味に時間がかかりました。しかし、下記の記事を参考にすることでデータセットの作成ができました。データセットはnpzファイルとして保存しました。
Pythonでデータセットを作る方法とデータセットの中身を確認する方法(npz編)
ポイントは画像データを配列データに変換してラベルをつけることです。コードは下記の通りです。
#画像ファイルを読んでNumpy形式に変換
#画像にラベルをつけて保存
import numpy as np
from PIL import Image
import glob, os, random
#保存ファイル名
outfile="./images/dataset.npz"
#利用する画像枚数
max_photo=200
#画像サイズ
photo_size=64
#画像データ
x=[]
#ラベルデータ
y=[]
def main():
#各画像フォルダを読む
glob_files("./images/face0/", 0)
glob_files("./images/face1/", 1)
#ファイルへ保存
np.savez(outfile, x=x, y=y)
print("データセットの作成完了:"+outfile, len(x))
#path以下の画像を読み込む
def glob_files(path, label):
#画像ファイルを読む
files=glob.glob(path+"/*.jpg")
random.shuffle(files)
#各ファイルを処理
num=0
for f in files:
if num>=max_photo: break
num+=1
#画像ファイルを読む
img=Image.open(f)
#色空間をRGB
img=img.convert("RGB")
#サイズ変更
img=img.resize((photo_size, photo_size))
img=np.asarray(img)
img=img/255
x.append(img)
y.append(label)
if __name__=='__main__':
main()
うまくデータセットができているかどうかの確認もしてみました。
#画像とそのラベルの確認
import matplotlib.pyplot as plt
#画像データ読み込み
photos=np.load("./images/dataset.npz")
x=photos['x']
y=photos['y']
#開始インデックス
idx=0
#pyplotで出力
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.title(y[i+idx])
plt.axis('off')
plt.imshow(x[i+idx])
plt.show()

開始インデックスを変更することで、他の画像も確認することができます。
3.モデルの構築・学習
保存したnpzファイルを読み込んで、モデルの構築と学習を行います。モデルの構築・学習に関しては、Google Colaboratory上で行いました。
データの分割
"""
データの分割
"""
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val=train_test_split(x, y, test_size=0.2, random_state=810317)
print(x_train.shape, y_train.shape)
print(x_val.shape, y_val.shape)
データの水増し
顔抽出したオリジナル画像データのみだと学習データが少なかったので、下記のパターンで水増しを行いました。
・オリジナル画像データを左右反転させた画像データ
・オリジナル画像データを回転させた画像データ
・オリジナル画像データを回転させてから、左右反転させた画像データ
・オリジナル画像データにぼかし処理を加えた画像データ
水増しをしたことで、学習用データを233枚から11184枚に増やすことができました。
"""
データの水増し
0:オリジナル、1:回転、2:ぼかし
"""
import cv2
x_new=[]
y_new=[]
for i, xi in enumerate(x_train):
yi=y_train[i]
for ang in range(-30, 30, 5):
#オリジナル左右反転
xi0=cv2.flip(xi, 1)
x_new.append(xi0)
y_new.append(yi)
#回転
center=(32, 32)
mtx=cv2.getRotationMatrix2D(center, ang, 1.0)
xi1=cv2.warpAffine(xi, mtx, (64,64))
x_new.append(xi1)
y_new.append(yi)
#回転と左右反転
xi10=cv2.flip(xi1, 1)
x_new.append(xi10)
y_new.append(yi)
#ぼかし
xi2=cv2.GaussianBlur(xi,(5,5),0)
x_new.append(xi2)
y_new.append(yi)
x_train=np.array(x_new)
y_train=np.array(y_new)
print(len(y_train))
モデルの構築
・入力層:64x64x3(顔部分抽出画像)
・畳み込み層:3x3のバッチサイズ32, 活性化関数はReLU
・畳み込み層:3x3のバッチサイズ32, 活性化関数はReLU
・プーリング層:Max-Pooling,2x2
・ドロップアウト:0.25
・畳み込み層:3x3のバッチサイズ32, 活性化関数はReLU
・畳み込み層:3x3のバッチサイズ32, 活性化関数はReLU
・プーリング層:Max-Pooling,2x2
・ドロップアウト:0.25
・平坦化層:1次元配列に変換
・全結合層:256,活性化関数はReLU
・ドロップアウト:0.25
・出力層:1, 活性化関数はsigmoid(0ならば齋藤飛鳥、1ならば玉森裕太)
from keras.layers.pooling.base_pooling2d import Pooling2D
"""
モデルのアーキテクチャ
"""
in_shape=(64, 64, 3)
model=Sequential()
#ブロック1
model.add(Conv2D(32, kernel_size=(3,3), activation='relu', input_shape=in_shape))
model.add(Conv2D(32, kernel_size=(3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
#ブロック2
model.add(Conv2D(64, kernel_size=(3,3), activation='relu'))
model.add(Conv2D(64, kernel_size=(3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
#全結合層
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(1, activation='sigmoid'))
モデルの学習
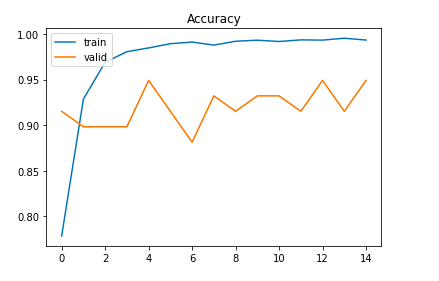
エポック数は1000としていますが、早期終了ありで学習させました。エポック数が15で学習が終了しました。
"""
モデルの構築(コンパイル)
"""
es_cb=EarlyStopping(
patience=10,
restore_best_weights=True
)
model.compile(
loss='binary_crossentropy',
optimizer=Adam(),
metrics=['accuracy']
)
"""
モデルの学習
"""
hist=model.fit(
x_train,
y_train,
batch_size=16,
epochs=1000,
verbose=1,
validation_split=0.2,
callbacks=es_cb,
validation_data=(x_val, y_val)
)
学習の様子
Epoch 1/1000
699/699 [==============================] - 13s 7ms/step - loss: 0.4494 - accuracy: 0.7785 - val_loss: 0.3467 - val_accuracy: 0.9153
Epoch 2/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.1834 - accuracy: 0.9286 - val_loss: 0.4637 - val_accuracy: 0.8983
Epoch 3/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0850 - accuracy: 0.9692 - val_loss: 0.5623 - val_accuracy: 0.8983
Epoch 4/1000
699/699 [==============================] - 4s 6ms/step - loss: 0.0552 - accuracy: 0.9807 - val_loss: 0.4959 - val_accuracy: 0.8983
Epoch 5/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0447 - accuracy: 0.9848 - val_loss: 0.2875 - val_accuracy: 0.9492
Epoch 6/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0311 - accuracy: 0.9894 - val_loss: 0.5917 - val_accuracy: 0.9153
Epoch 7/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0252 - accuracy: 0.9912 - val_loss: 0.8384 - val_accuracy: 0.8814
Epoch 8/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0362 - accuracy: 0.9879 - val_loss: 0.3873 - val_accuracy: 0.9322
Epoch 9/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0246 - accuracy: 0.9921 - val_loss: 0.5092 - val_accuracy: 0.9153
Epoch 10/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0214 - accuracy: 0.9933 - val_loss: 0.4361 - val_accuracy: 0.9322
Epoch 11/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0285 - accuracy: 0.9919 - val_loss: 0.7183 - val_accuracy: 0.9322
Epoch 12/1000
699/699 [==============================] - 5s 7ms/step - loss: 0.0197 - accuracy: 0.9937 - val_loss: 0.4424 - val_accuracy: 0.9153
Epoch 13/1000
699/699 [==============================] - 5s 6ms/step - loss: 0.0227 - accuracy: 0.9934 - val_loss: 0.7068 - val_accuracy: 0.9492
Epoch 14/1000
699/699 [==============================] - 5s 7ms/step - loss: 0.0123 - accuracy: 0.9954 - val_loss: 1.0430 - val_accuracy: 0.9153
Epoch 15/1000
699/699 [==============================] - 5s 7ms/step - loss: 0.0176 - accuracy: 0.9935 - val_loss: 1.0459 - val_accuracy: 0.9492
精度の確認で混同行列も確認しました。
"""
混同行列
"""
from sklearn.metrics import confusion_matrix
y_pred=model.predict(x_val)
y_pred=y_pred.reshape(-1)
y_pred1=[]
for i,x in enumerate(y_pred):
if x<0.5:
y_pred1.append(0)
else:
y_pred1.append(1)
print(confusion_matrix(y_true=y_val, y_pred=y_pred1))
2/2 [==============================] - 0s 116ms/step
[[27 3]
[ 0 29]]
玉森裕太の分類はうまくいっているものの、齋藤飛鳥の分類がうまくいっていないことがわかりました。
"""
誤分類の確認
"""
import japanize_matplotlib
labels=["齋藤飛鳥", "玉森裕太"]
for i in range(len(y_pred1)):
if y_pred1[i]!=y_val[i]:
plt.title("予測結果:"+labels[int(y_pred1[i])])
plt.imshow(x_val[i])
plt.axis("off")
plt.show()


4.テスト画像で動作確認
本記事の冒頭に掲載した画像でモデルによる予測の確認を行います。
#モデル読み込み
from keras.models import load_model
model=load_model('./images/model_asutama.h5')
#テスト画像で検証
def detection(file):
labels=["齋藤飛鳥", "玉森裕太"]
#元の画像
test_img=cv2.imread(file)
test_img=cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)
#元画像から顔部分切り取った画像
face_img, d=get_face_rect(file)
face_img=cv2.cvtColor(face_img, cv2.COLOR_BGR2RGB)
plt.imshow(face_img)
plt.axis('off')
plt.show()
#データの型変換
x_test=np.asarray(face_img)
x_test=x_test.reshape(-1, 64, 64, 3)
#元画像に顔部分の矩形を描画
x1=int(d.left())
y1=int(d.top())
x2=int(d.right())
y2=int(d.bottom())
cv2.rectangle(test_img, (x1, y1), (x2, y2), color=(255,0,0), thickness=5)
plt.imshow(test_img)
plt.axis('off')
plt.show()
#モデルでの予測
pred=model.predict(x_test)[0]
print(pred[0])
if pred[0]<0.5:
print("予測結果:", labels[0])
else:
print("予測結果:", labels[1])
import glob
fname=glob.glob("./images/*.jpg")
for f in fname:
print(f)
detection(f)


顔部分の検出と分類ができていることが確認できました。
5.アプリ開発
モデルの保存ができていることと、分類ができていることを確認できたので、JupyterNotebook上で行っていたシステムをFlaskを使ってアプリ化しました。
アプリ化する流れに関しては下記のサイトを参考にしました。
【保存版】30分でFlask入門!Webアプリの作り方をPythonエンジニアが解説
今回はデプロイはせずにローカルの環境で動かせるところまでやりました。(デプロイできたけどアプリを動かすことはできませんでした、、、)
import os, shutil
from flask import Flask, request, redirect, url_for, render_template, Markup
from werkzeug.utils import secure_filename
from keras.models import Sequential, load_model
from PIL import Image
import numpy as np
import cv2
from face_rectangle import get_face_rect
UPLOAD_FOLDER = "./static/images/"
ALLOWED_EXTENSIONS = {"png", "jpg", "jpeg", "gif"}
labels = ["齋藤飛鳥","玉森裕太"]
app = Flask(__name__)
app.config["UPLOAD_FOLDER"] = UPLOAD_FOLDER
def allowed_file(filename):
return "." in filename and filename.rsplit(".", 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route("/", methods=["GET", "POST"])
def index():
return render_template("index.html")
@app.route("/result", methods=["GET","POST"])
def result():
if request.method == "POST":
# ファイルの存在と形式を確認
if "file" not in request.files:
print("File doesn't exist!")
return redirect(url_for("index"))
file = request.files["file"]
if not allowed_file(file.filename):
print(file.filename + ": File not allowed!")
return redirect(url_for("index"))
# ファイルの保存
if os.path.isdir(UPLOAD_FOLDER):
shutil.rmtree(UPLOAD_FOLDER)
os.mkdir(UPLOAD_FOLDER)
filename = secure_filename(file.filename) # ファイル名を安全なものに
filepath = os.path.join(UPLOAD_FOLDER, filename)
file.save(filepath)
#元の画像
test_img=cv2.imread(filepath)
test_img=cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)
#元画像から顔部分切り取った画像
face_img, d=get_face_rect(filepath)
face_img=cv2.cvtColor(face_img, cv2.COLOR_BGR2RGB)
#データの型変換
x_test=np.asarray(face_img)
x_test=x_test.reshape(-1, 64, 64, 3)
#元画像に顔部分の矩形を描画
x1=int(d.left())
y1=int(d.top())
x2=int(d.right())
y2=int(d.bottom())
test_img=cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)
#モデルでの予測
model = load_model("./images/model_asutama_new.h5")
pred=model.predict(x_test)[0]
print(pred[0])
if pred[0]<0.5:
cv2.rectangle(test_img, (x1, y1), (x2, y2), color=(255,255,0), thickness=5)
cv2.imwrite(UPLOAD_FOLDER+filename, test_img)
file_path_new=UPLOAD_FOLDER+filename
result=labels[0]
else:
cv2.rectangle(test_img, (x1, y1), (x2, y2), color=(0,255,255), thickness=5)
cv2.imwrite(UPLOAD_FOLDER+filename, test_img)
file_path_new=UPLOAD_FOLDER+filename
result=labels[1]
return render_template("result.html", result=Markup(result), filepath=file_path_new)
if __name__ == "__main__":
# app.run(debug=True)
app.run()
HTMLファイルはtemplateフォルダに用意して、classifier.pyをターミナル上で実行しました。http://127.0.0.1:5000/
をブラウザで開くとアプリを起動させることができます。

6.アプリの動作確認
実際に画像をアップロードして、アプリの動作確認を行いました。
・齋藤飛鳥の画像

・玉森裕太の画像

まとめ
過去に投稿した記事では画像を収集してきて特に前処理をしないで予測させるモデルを構築していたので、いまいち高い精度を出すことができませんでした。しかし、顔抽出とデータの水増しをおこなったことで比較的高い精度の人物の顔分類器を作成することができました。アプリ化することはできたものの、デプロイして公開することが原因不明のエラーでできなかったのが悔しかったところです。そこは次回以降、リベンジしたいところです。
【ソースコード】
【参考資料】
・Pythonでデータセットを作る方法とデータセットの中身を確認する方法(npz編)
画像データを使ってモデルの学習する際に必要なデータセットの作り方がまとめられています。
・PyTorchを使って日向坂46の顔分類をしよう!
今回はPyTorchは使っていませんが、データの水増し方法など手順がしっかりまとめられています。私自身おひさま(日向坂46ファンの呼称)なので読んでいて楽しい内容です。
・【Python】dlibで顔検出
顔検出のソースコードはもちろん、検出した部分を画像に描画する方法までまとめてられています。OpenCVとの顔抽出精度の比較も記載されています。
・【保存版】30分でFlask入門!Webアプリの作り方をPythonエンジニアが解説
はじめてFlaskを学習するには超おすすめの内容です。アプリができるまでの流れが一から丁寧に解説されています。
・H10 - App crashed (アプリがクラッシュしました)
アプリがデプロイできたものの、URLにアクセスしても使えなかったときのエラーです。