これは AWS Analytics Advent Calendar 2022 の 8 日目の記事です。
1.はじめに
AWS re:Invent 2022 で Redshift の Streaming Ingestion 機能が GA 発表されました。Streaming Ingestion とは Amazon Kinesis Data Streams と Amazon Managed Streaming for Apache Kafka (MSK) からストリーミングデータを 直接 Redshift に リアルタイム で投入することができる機能です。
この機能が出るまで Redshift 上でリアルタイムにデータを入れるには、Amazon Kinesis Data Firehose を使って一旦データを S3 に保存し、そのデータを逐次的に Redshift の COPY 文を使って投入する必要がありました。逐次的に COPY 文を叩く仕組み、すでにロードした S3 上のファイルを除外する仕組みなど、様々な仕組みを実装・運用する手間がありました。
この機能によって、そういった実装・運用の手間から開放され、しかも従来の方法よりもよりリアルタイムに近い鮮度でデータを投入することができます。
この記事では、Amazon Kinesis Data Streams を利用した際の Streaming Ingestion の基本的な使い方と使う上での注意点をプロビジョニングされた Redshift を対象にまとめます。
2. 使い方
大まかな使い方は以下の通りです。
- Redshift のクラスターに関連付けされた IAM ロールに Amazon Kinesis Data Streams の stream へのアクセス権を付与する
- Redshift 上で Stream のデータを読み取るための Materialized View を作成する
- 定期的に Materialized View を更新して Stream からデータを取り込む
1. アクセス権の付与
Redshift から Amazon Kinesis Data Streams の stream にアクセスするために、Redshift のクラスターに関連付けされた IAM ロールに Kinesis へのアクセス権限を付与した IAM ポリシーをアタッチします。IAM ポリシーは以下の通りです。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadStream",
"Effect": "Allow",
"Action": [
"kinesis:DescribeStreamSummary",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:DescribeStream"
],
"Resource": "arn:aws:kinesis:*:0123456789:stream/*" ←ここに読み込み元の stream の ARN を記載する
},
{
"Sid": "ListStream",
"Effect": "Allow",
"Action": [
"kinesis:ListStreams",
"kinesis:ListShards"
],
"Resource": "*"
}
]
}
2. Materialized View の作成
注意するポイントとして Materialized View を作成する前に、Redshift のクラスターと Amazon Kinesis Data Streams がネットワーク的に導通できるかどうかを確認する必要があります。つまり、インターネットを経由しても良いのであれば、クラスターが属しているVPCのサブネットグループがインターネットゲートウェイや NAT ゲートウェイを利用してインターネットにアクセスできるか確認する必要があります。また、AWS内のネットワークに閉じたい場合は、 Kinesis interface VPC Endpoint を利用する必要があります。ここでは interface VPC Endpoint を作る解説を挟みます。
Interface VPC Endpoint の作成
[VPCダッシュボード]→左側のハンバーガーメニュー(三)をクリック→[エンドポイント]→[エンドポイントを作成]で VPC Endpoint を作成できます。
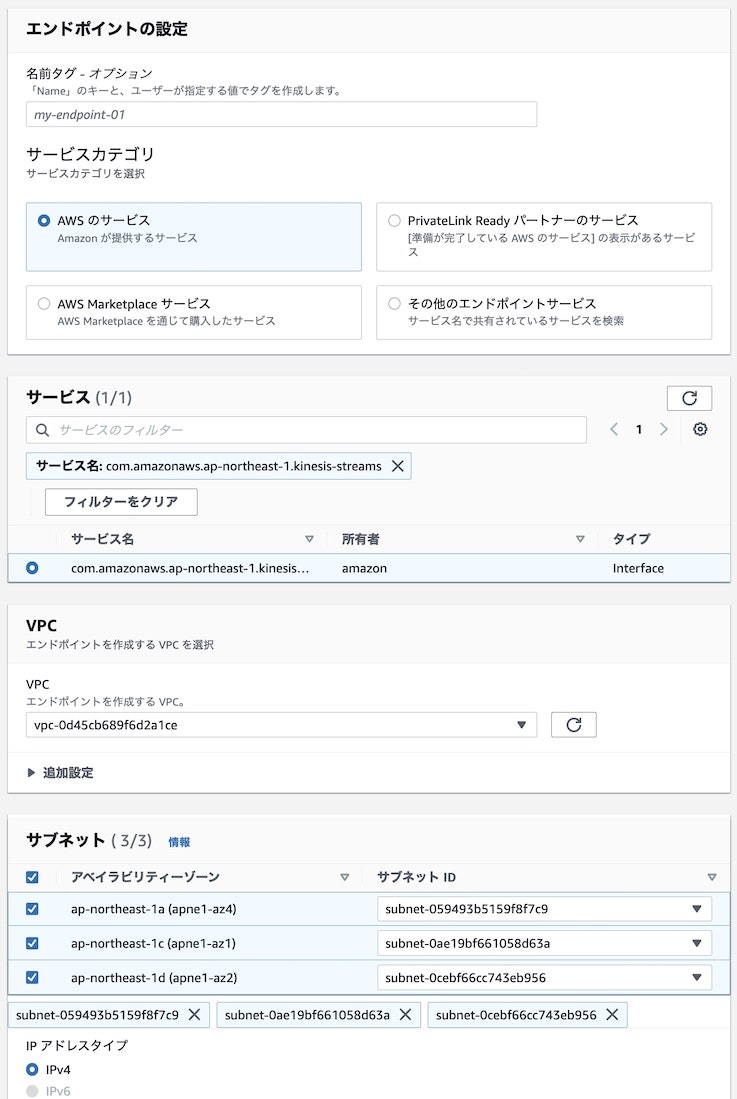
ポイントは以下の通りです。
- Amazon Kinesis Data Streams にアクセスするための Endpoint なのでサービスとして kinesis-streams を選択
- VPC は Redshift のクラスターが配置されている場所を選択
- サブネットはクラスターが配置されているサブネットグループに含まれるサブネットを選択
- サブネットグループについての詳細は Managing cluster subnet groups using the console のドキュメントを参考にしてください
Materialized View の作成
Redshift クエリエディタ (クエリエディタv2) から外部 SCHEMA を作ります。
CREATE EXTERNAL SCHEMA {外部 SCHEMA 名}
FROM KINESIS
IAM_ROLE 'iam-role-arn'; # デフォルト IAM ロールが設定されている場合は IAM_ROLE default でも可
その後、Materialized View を作成します。
CREATE MATERIALIZED VIEW {VIEW 名} AS
SELECT
... # ここでデータのマッピングを行う
FROM {外部 SCHEMA 名}.{stream 名};
{stream 名}には以下のメタデータが入っているので、そのメタデータを利用してテーブルのカラムにマッピングします。
| メタデータ名 | 型 | 説明 |
|---|---|---|
| approximate_arrival_timestamp | TIMESTAMP | 各レコードが Kinesis stream に投入されたおおよその時間 |
| partition_key | VARCHAR(256) | Kinesis stream に投入する時に指定した partition_key |
| shard_id | CHAR(20) | Kinesis stream 内の shard の id |
| sequence_number | VARCHAR(128) | shard 内で一意の値で、時間とともに増加 |
| kinesis_data | VARBYTE(1024000) | Kinesis stream に投入された実データ |
| refresh_time | TIMESTAMP | Materialized View が REFRESH を開始した時間 (= Redshift に取り込みを開始した時間) |
注意するポイントとして kinesis_data はバイナリで保存されているため、カラムにマッピングする際は from_varbyte 関数を利用してバイナリから文字列に変換します。加えて、stream に投入されたデータは json や csv 形式の物が多いため、json_extract_path_text 関数や split_part 関数を利用してカラムに分解します。例えば以下のような式になります。
json_extract_path_text(from_varbyte(kinesis_data, 'utf-8'), '{フィールド名}')::int as {カラム名}
3. Materialized View を更新してデータを取り込む
以下のクエリを実行することで、Materialized View を更新してデータを取り込みます。
REFRESH MATERIALIZED VIEW {VIEW 名};
このクエリは、前回の更新時点から現在の更新時点で増分されたデータのみを取り込みます。すでに取り込まれたデータは更新されません。また、前回の更新時点が無い初期の更新時は、stream に保存されているすべてのデータを取り込みます。そのため、View を DROP してしまった場合、stream に現時点で保存されているデータのみが取り込まれます。stream の保持期間を過ぎたものは再度取り込むことはできません。
定期的な Materialized View の更新
REFRESH で更新しない限りデータが取り込まれないため、リアルタイムで取り込むためには高頻度且つ定期的に更新を行う必要があります。プロビジョニングされた Redshift クラスターでは クエリのスケジュール設定 が利用できるので、こちらを利用することで、REFRESH 文を定期的に実行することができます。但し、このスケジューラーでは最小単位が分で、実行時に計算リソースを利用します。そのため、更新頻度はリアルタイム要件と計算リソースの許容度を加味して決める必要があります。
12/08追記
Materialized View の作成時に Materialized View の自動更新機能を使うことで、能動的に REFRESH をしなくても自動更新が可能です。その場合は以下の通りに Materialized View を作成するときに AUTO REFRESH YES を追加します。
CREATE MATERIALIZED VIEW {VIEW 名} AUTO REFRESH YES AS
SELECT
... # ここでデータのマッピングを行う
FROM {外部 SCHEMA 名}.{stream 名};
こちらの機能は手動での REFRESH と併用可能です。
注意するポイントとしてこの自動更新はAWS側のロジックで行われるため、更新を自身のロジックでコントロールできない点です。私が実際に使ってみた限りだと、データが stream に投入されてもすぐに更新が入るわけではなかったです(数分では更新されない模様)。高頻度で更新が必要な場合は、手動で REFRESH が必要になりそうです。
まとめ
プロビジョニングされた Redshift のクラスターでの Streaming Ingestion の基本的な使い方を説明しました。なお、Redshift Serverless でも Streaming Ingestion を利用することは可能ですが、更新時に RPU を消費する(ハズ)なのと、クエリのスケジュール設定が使えないので、Materialized View の自動更新機能を使わない場合は独自で Materialized View を更新する手段を用意する必要があります。
参考文献
- https://docs.aws.amazon.com/redshift/latest/dg/materialized-view-streaming-ingestion.html
- https://docs.aws.amazon.com/redshift/latest/dg/materialized-view-streaming-ingestion-getting-started.html
- https://docs.aws.amazon.com/redshift/latest/dg/materialized-view-refresh.html#materialized-view-auto-refresh
- https://aws.amazon.com/jp/blogs/aws/new-for-amazon-redshift-general-availability-of-streaming-ingestion-for-kinesis-data-streams-and-managed-streaming-for-apache-kafka/