はじめに
どうも、こんにちは。今回はlambdaとS3の連携について、AWS初心者が初心者なりに頑張って説明していきたいと思います。初心者が分からないことは、案外初心者にしか分からないものです。ある程度できるようになってくると、自分ができなかった頃の記憶が抜け落ちていきますからね~。ということで、簡単な実例を用いて、できる限りかみ砕いて説明していきたいと思います。
また、今回はWindowsユーザー寄りの記事になります(私がWindowsユーザーなので...)。途中で使用するコマンドが違ったりするかもしれませんが、あしからず。
AWS初心者である私の躓きポイントの1つが、Windowsユーザー向けの記事の少なさなんですよね。Macを使われている方の記事を参考にする際は、コマンドの違いなどから高確率で遠回りをすることになります。肩身が狭いですよね...
Macユーザーの方でも問題なく実行できるように、頑張って書きますので、最後までお付き合いいただけると幸いです。
私がつまづいたポイント
1. lambdaで外部ライブラリが使えない
2. lambdaにzipフォルダをアップロード
[3. S3へのアクセス権設定](#Amazon S3の設定)
システムの概要
今回は具体例として、一定の間隔でニュース記事を取得して、取得したニュース記事のデータをS3に格納していくようなシステムを実装していきたいと思います。
Pythonでニュースをクローリングする方法に関しては、以前記事を書きましたので、そちらの方も一度目を通していただけると、よりスムーズに理解できると思います。
以下は今回使用するソースコードです。それぞれ別のファイルに適当な名前を付けて保存してください(最後のlambdaの実行ファイルだけは、「lambda_function.py」というファイル名で保存してください)。
import feedparser
# ニュース記事のデータを取得するためのクラス
class CrawlingNews:
def __init__(self, rss_url):
self.rss_url = rss_url
def crawling(self):
# ニュース記事のRSSからタイトルと要約を取得してリストに格納する。
data = feedparser.parse(self.rss_url)
news = [[entry.title, entry.summary, entry.link] for entry in data.entries]
return news
import json
# クローリングしたニュースのデータをjson形式にしてフォルダーに格納するクラス
class ConvertNewsData:
def __init__(self, news_data, file_path):
self.news_data = news_data
self.file_path = file_path
def convert(self):
news_dict = {}
# 引数とした渡されたニュースデータの二次元配列の順番とデータを取得
for num, data in enumerate(self.news_data):
# 対象のニュースが何番目かという情報を辞書のキーとして利用
filename = f"news{num}"
# 空の辞書にニュースのタイトル、要約、リンクを追加していく
news_dict[filename] = dict((["title", data[0]],["summary", data[1]],["link", data[2]]))
# 辞書型のデータをjson形式に変換して、指定されたパスに格納する
with open(self.file_path , "w", encoding="utf-8") as f:
json.dump(news_dict, f, indent=4, ensure_ascii=False)
return news_dict
import boto3
import feedparser
# ここはコードが書いてあるファイル名に適宜変えてください
from ******** import CrawlingNews
from ******** import ConvertNewsData
import datetime
# RSS形式のニューズ記事のURL
URL = "https://www.news24.jp/rss/index.rdf"
# lambdaの実行ファイル
def lambda_handler(event, context):
try:
# ニュースデータを取得
news_data = CrawlingNews(URL)
news_list = news_data.crawling()
# ファイル名と保存先のパスを指定
datetime_now = datetime.datetime.now()
formated_time = datetime_now.strftime("%Y年%m月%d日%H時%M分%S秒")
file_name = f"{formated_time}.json"
file_path = f"/tmp/{file_name}"
# ニュースデータをjson形式に変換
json_data = ConvertNewsData(news_list, file_path)
json_data.convert()
# S3にデータを保存
client = boto3.client('s3')
Filename = f'/tmp/{file_name}'
Bucket = '*************'
Key = file_name
client.upload_file(Filename, Bucket, Key)
except Exception as e:
print(e)
raise e
ディレクトリの構成がこのようになっていれば大丈夫です。
root/
├ crawling.py
├ convert_json.py
└lambda_function.py
必要なライブラリの追加
それではプログラムを動かすのに必要なライブラリを追加していきましょう。今回、必要なライブラリはRSS形式のデータを解析・取得する「feedparser」と現在日時を取得するための「datetime」というライブラリの二つです。ローカルでS3にアクセスする際は、「boto3」というライブラリも追加する必要があるのですが、今回はlambdaで実行するだけなので追加しません。
そして、ここからが私の躓きポイントその1。lambdaでPythonの外部ライブラリを使用する際は、ライブラリの保存先をルートディレクトリに指定して、zipファイルでまとめ、実行ファイルなどと一緒にアップロードする必要があります。
ライブラリのインストール先を指定する方法は簡単です。pipでインストールするときに「-t パス」を付け足してあげるだけです。今回、作業するフォルダーまで移動したら、以下のコマンドを打ち込んでください。
pip install feedparser -t ./
pip install datetime -t ./
上手くいくと、このように色々なフォルダやファイルが追加されている状態になると思います。

フォルダをzip圧縮してlambdaにアップロード
ここからフォルダを圧縮してlambdaにアップロードしていくわけですが、私はここでも躓きました。躓きポイントその2です。
Macユーザーの方は下記のコマンドで問題なく圧縮できると思います。詳しくは公式ドキュメントを参照してください(私自身、Macを持っていないので確認できていません。申し訳ありません...)。
zip -r [圧縮後のフォルダ名].zip [圧縮したいフォルダ名/]
Windowsでも設定をいじってzipコマンドを使えるようにしたり、powershellのcompress-archiveコマンドを使ったりいくつか方法があるとは思いますが、今回はエクスプローラーを開いて右クリックで圧縮するという古典的な方法で行きたいと思います。こっちの方が確実です(単純に私の勉強不足でコマンドではうまくいきませんでした...)。
圧縮方法には公式ドキュメントで推奨されている7-zipを使います。7-zipをインストールしていないという方は、下記の記事を参考にインストールしてみてください。
7-zipをインストール出来たら、作業していたフォルダがある場所まで移動して、全選択からの右クリック・7-Zipを選んで、zipに圧縮しましょう。

lambdaにzipファイルをアップロード
それではlambdaにzipファイルをアップロードして関数を実行していきたいと思います。lambdaの基本的な使い方に関しては、別に記事を書きましたのでそちらの方を参照してください。
今回は「getNewsData」という名前のlambda関数を作成しました。アップロード元をクリックして「.zipファイル」を選択しましょう。そこから、先ほど作成したzipファイルをアップロードして保存をクリックしてください。

このようなフォルダ構成になっていれば無事にアップロードされています。そして、ここで1つ設定をいじる必要があります。

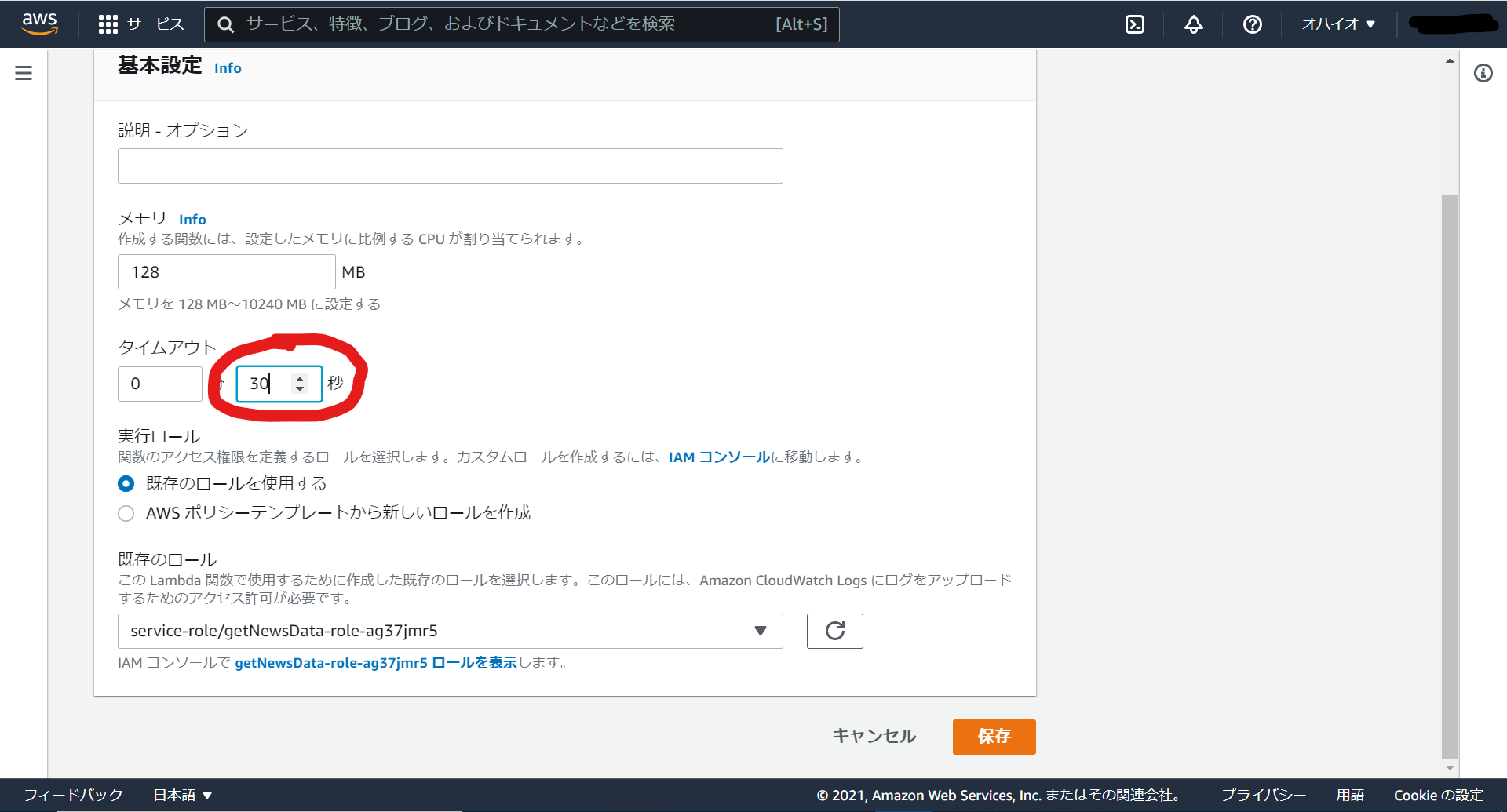
「設定」をクリックして、その中の「一般設定」からタイムアウトの秒数を変更します。

右上の「編集」をクリックして、タイムアウトの時間を30秒とかにしておきましょう。変更が出来たら保存します。
ここまで出来たら、しっかりとデプロイされていることを確認してください。確認出来たら、次にS3の設定に移ります。
Amazon S3の設定
検索バーでS3と検索して、S3のトップページに移動したら、「バケットを作成」をクリックします。適当なバケット名を付けて、バケットを作成してください。バケットが作成されていることを確認したら、一度バケットのアクセス許可設定をするので、作成したバケットをクリックしてください。
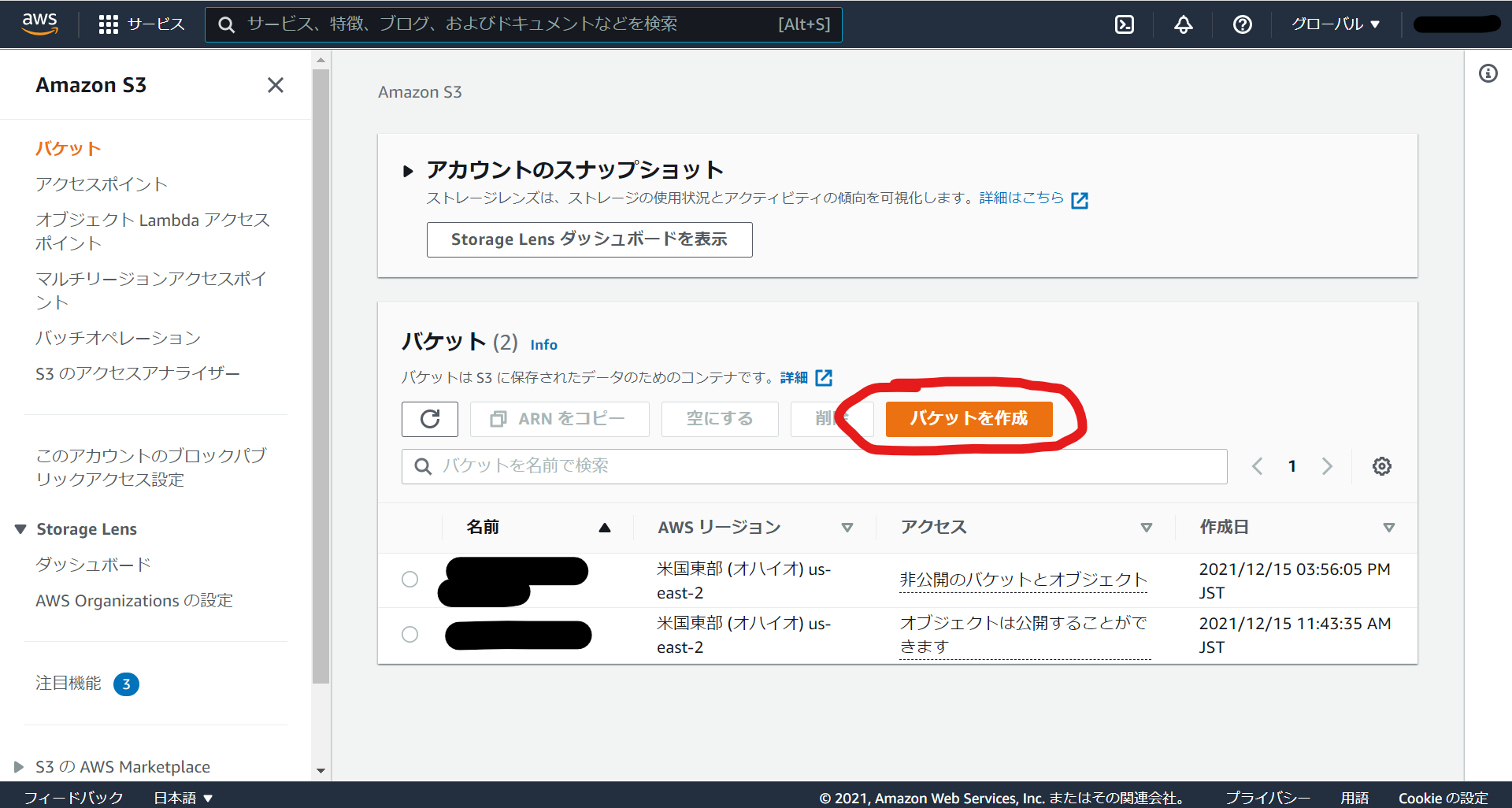
「アクセス許可」をクリックして「バケットポリシー」を編集していきます。ここが私の躓きポイントその3です。

バケットポリシーを開くとこのようなjson形式の文章が表示されると思うので、ここに必要事項を付け加えていきます。私は以下の記事を参考にして沼から抜け出しました。とても参考になるので、是非目を通してみてください。

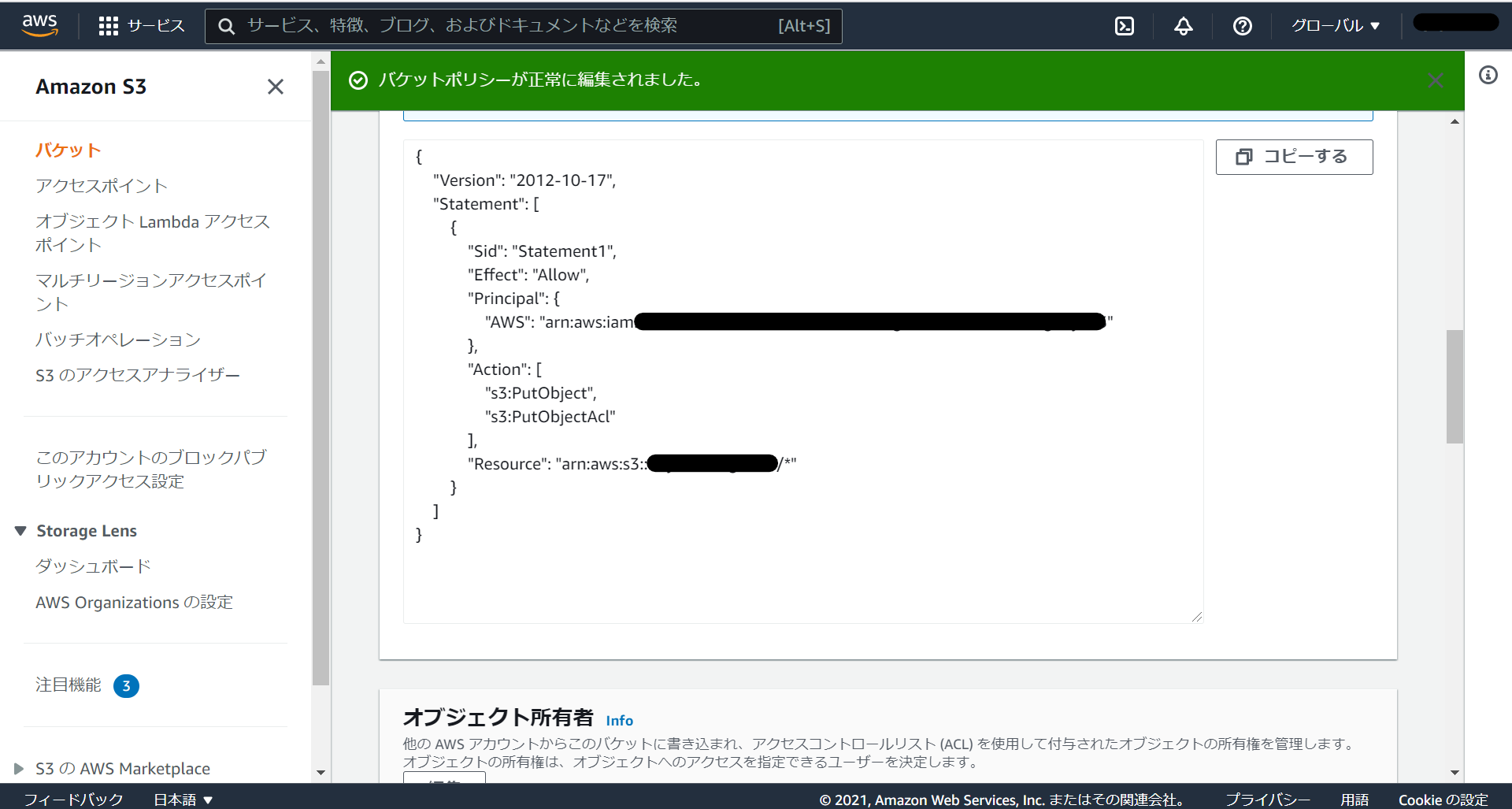
まず、"Action"という欄に「"s3:PutObject","s3:PutObjectAcl"」の2つを追加します。ここは用途に応じて適宜追加していってください。

次に"Resource"にS3のバケットARNを追加していきます。画面上部にある「バケットARN」をコピーして末尾に「/* 」をつけて、追加してあげてください。ダブルクォーテーションで括るのを忘れずに。 "Resource" : ["arn:aws:s3:::バケット名/* "] というような形になると思います。

最後に、"Principal"にAWSのロールを追加していきます。検索バーにIAMと入力して、IAMのトップページに移動します。移動したら画面左側の「アクセス管理」にある「ロール」をクリックします。

ロールの中に先ほど作成したlambda関数の名前がついているロールが存在していると思います。そのロールをクリックして中身を確認しましょう。

概要の中にある「ロールARN」の内容をコピーします。

コピーしたらポリシーの"Principal"の中に{"AWS" : "コピーしてきたロールARN"}というような形で書き込んで、変更を保存します。最終的にこのような構成になればOKです。
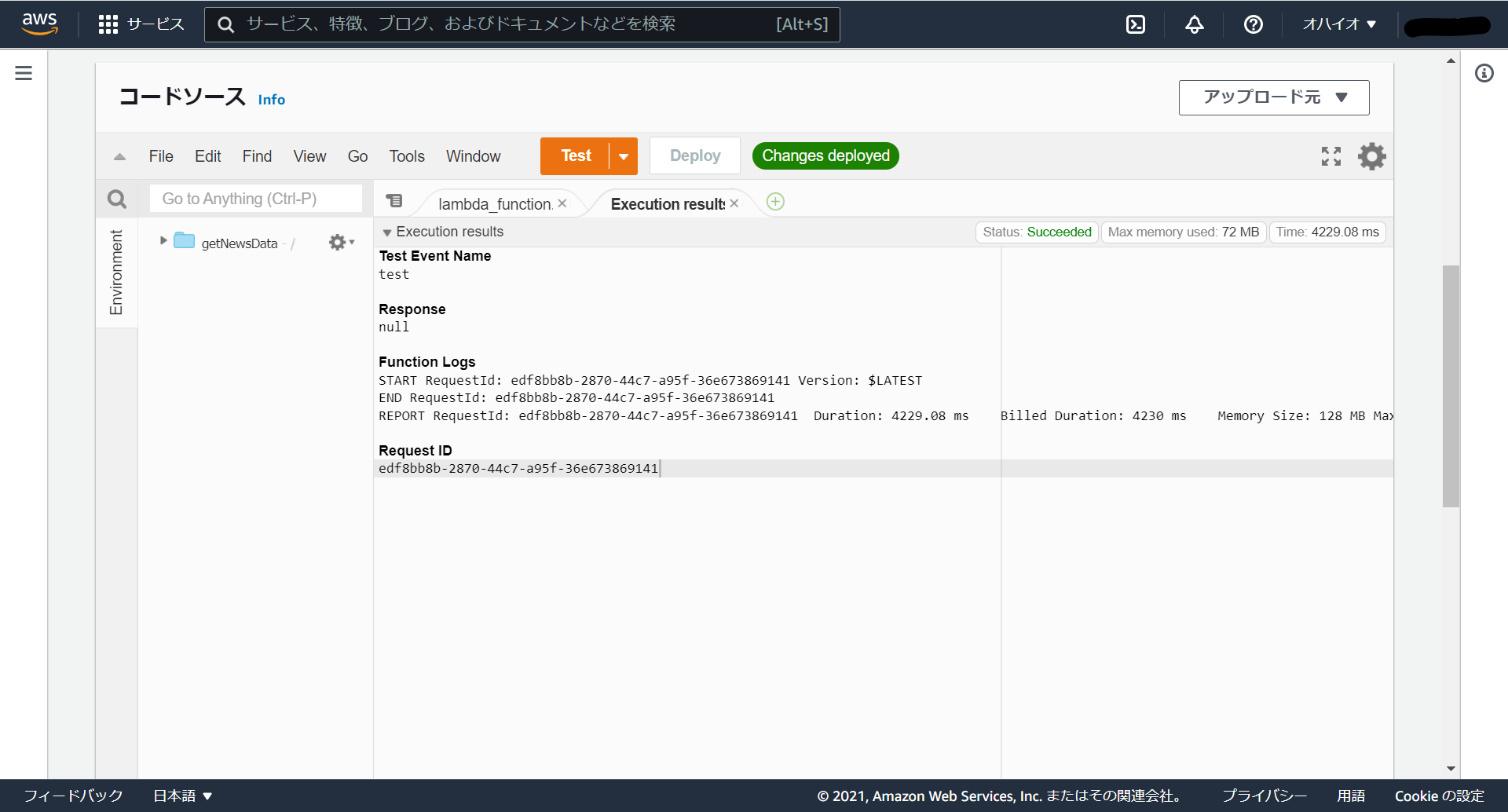
ここまで出来たら一度テストしてみましょう。テストをするにあたって、まずはlambda_function.py中にあるBucket変数のバケット名を、先ほど作成したバケットの名前に変更します。変更したら一度、デプロイをして、テストしてみましょう。

このような画面が表示されていれば、上手く実行できています。S3に移動してデータを見てみましょう。
S3のトップページに移動したら先ほど作成したバケットを選択します。しっかりとニュースデータが格納されていますね。
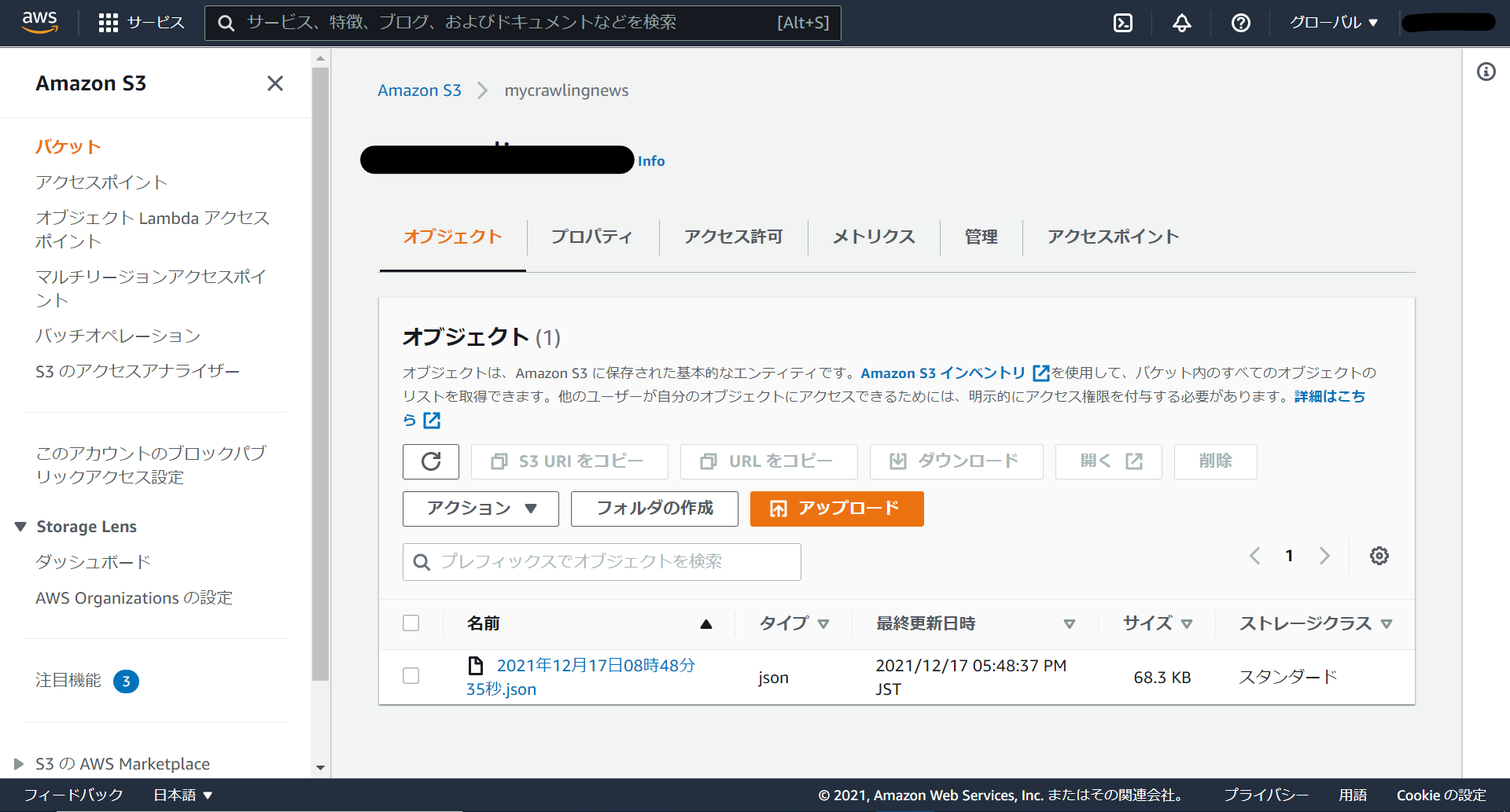
ニュースデータの中身まで確認したいという人は、作成されたデータをクリックして、画面上部にある「開く」から、データをダウンロードしてみてください。

CloudWatchを使って定期実行
ここまで来たらあともうひと踏ん張りです。検索バーからEventBridgeに飛んで、ルールを作成していきます。ルール名はなんでも大丈夫です。処理の間隔は1分(ここは任意の時間に変更してください)にします。

ターゲットの機能のところに今回作成したlambda関数を指定して、作成をクリックすれば完了です。
S3に移動して、定期的にデータが格納されているか確認してみましょう。しっかりと1分間隔でデータが格納されいますね。
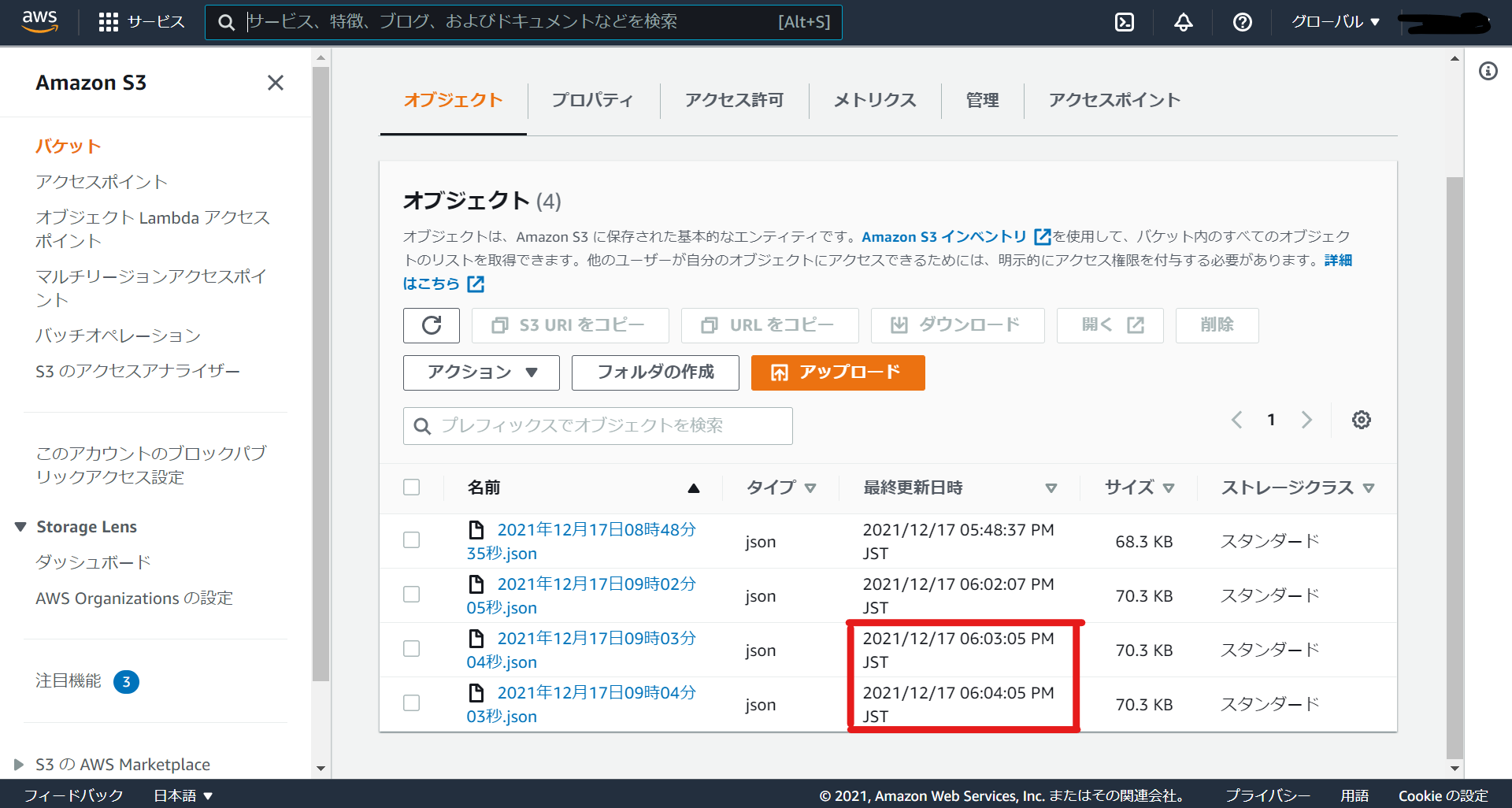
確認が済んだら定期実行の間隔を長くするなり、定期実行処理を無効化するなりしましょう。1分毎に処理を実行していたら請求額がすごいことになりそうなので...
最後に
以上で説明は終了になります。長々とお付き合いいただき、ありがとうございました。それにしてもAWSというのは奥が深いですね。前々からインフラ周りに興味を持っていて、最近大学の講義の関係で触り始めたのですが、一筋縄ではいかないことが殆どです。それでも、何か大きなことができるようになった気分(錯覚)になるのが、インフラ周りをいじる楽しさかなー、と思います。
今後も、定期的に記事を書いていこうと思いますので、目を通していただけると幸いです。
それでは、また。