文学部卒のド文系の社会人ですが、仕事の関係で地域でのAI利活用を進めるプロジェクトにアサインされてしまいました。AIを活用したサービスなどは日ごろの生活なかで触れるものについてはなんとなくわかるものの、どのような仕組みで成り立っているのかは詳しくはわからない状態でした。
そんな状態で技術活用の方法を考えたり人に勧めたりすることができるのだろうかと不安があり、通学が必要ないWebスクール形式のものを受講することを決意しました。いくつか比較してみた結果、すぐ始められるというところや給付金制度が活用できるというところでAidemyにしました。本投稿はその成果物という位置づけになります。
目次
・学習内容
・成果物内容
・反省
・今後の学習
学習内容
【概要】
AidemyのAIアプリ開発(3か月)コースにて、以下Pythonの基礎や周辺技術の基礎的内容を学習。その後、学習内容を踏まえモデルを作成。
【詳細】
- 各ライブラリ:「NumPy」(数値計算)、「Pandas 」(表計算)、「Matplotlib」(可視化)
- データクレンジング
- 機械学習概論、教師あり学習(分類)
- スクレイピング
- ディープラーニング:CNNを用いた画像認識、男女識別等
- Flask
- Git
上記学習と成果物作成、ブログの記載でだいたい120時間くらいの学習時間だと思います。
成果物
【概要】
サッカー選手の画像認識・識別を行うモデルの作成。メッシ、クリスティアーノ・ロナウド、ネイマール、エムバペというサッカーに興味がない方でも名前は聞いたことあるであろう4名の画像を認識し、識別を行うモデルを作成しました。
※どの選手も素晴らしいけれども、個人的には元スペイン代表ダヴィド・シルバ選手のような渋めなインテリジェンスに富む技巧派選手が好きですが、素材の収集の観点から上記4選手としました(余談)
【流れ】
①環境整備
②データ取得、前処理
③モデル構築
環境
- Google colab
- Google drive
- tensorflow
Google drive内階層構造:
FootBall_Player
Ltrain_images
LCR7
Lmbappe
Lmessi
Lneymar
①環境整備
Google colabを使用しました。画像ファイルはGoogle driveに格納し読みだせるようにしました。
#ドライブをマウント
from google.colab import drive
drive.mount('/content/drive')
%cd "/content/drive/MyDrive/footballplayer"
②データ取得
クローラーを使ってBingの画像を収集します。各選手だいたい750枚くらい集まりました。
downloader_threadsの数値を大きくするとたくさん集まりました。
※downloader_threadsの数値はハードの性能に依存するらしいので、実機でやっている方上げすぎると高負荷になると思われるので注意してください。
※この時点で特に写真を切り出し、選別することなくディープラーニングを行って精度を測ってみたところだいたい60%くらいでした。たぶんPSGのチームメイトである3人はそれぞれの写真に紛れ込んでいることが多かったり、同じユニホームをきていたり、背番号も10か7なんで混同する要素は多いように思います。(downloader_threadsの数値が低いと200枚くらいしか集まらなかったのですが、その場合は40%くらいの精度でした。)
# Bing用クローラーのモジュールをインポート
from icrawler.builtin import BingImageCrawler
# Bing用クローラーの生成
bing_crawler = BingImageCrawler(
downloader_threads=10, # ダウンローダーのスレッド数
storage={'root_dir': 'CR7'}) # ダウンロード先のディレクトリ名
# クロール(キーワード検索による画像収集)の実行
bing_crawler.crawl(
keyword="CR7", # 検索キーワード(日本語もOK)
max_num=1000) # ダウンロードする画像の最大枚数
③データの前処理
カスケード検出器を用いて取得した画像から選手の顔を検出し、切り出して保存します。
※カスケードファイルが別途必要です。ここがよくわからなくて躓きました。GitHubでダウンロードしたらたくさんファイルがあって困ったのですが、とりあえずドライブに全部アップロードして対処しました。
#顔の切り出し CR7
import os
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
#カスケードファイルを指定して、検出器を作成
cascade_file = "/content/drive/MyDrive/footballplayer/opencv-master/data/haarcascades/haarcascade_frontalface_default.xml"
cascade = cv2.CascadeClassifier(cascade_file)
path_CR7 = os.listdir("/content/drive/MyDrive/footballplayer/train_images/CR7")
for i in range(len(path_CR7)):
img = cv2.imread("/content/drive/MyDrive/footballplayer/train_images/CR7/" + path_CR7[i])
img_face = img
#画像の読み込んでグレースケール
img_gray = cv2.cvtColor(img_face, cv2.COLOR_RGB2GRAY)
#顔認識
face_list = cascade.detectMultiScale(img_gray, minSize = (150, 150))
#結果
if len(face_list) == 0:
print("失敗")
quit()
for (x,y,w,h) in face_list:
print("顔の座標 = ", x, y, w, h)
red = (0, 0, 255)
cv2.rectangle(img_face, (x,y), (x+w, y+h), red, thickness=20)
#切り取り
img_face= img[y:y+h, x:x+w]
plt.imshow(cv2.cvtColor(img_face, cv2.COLOR_BGR2RGB))
plt.show()
#保存
cv2.imwrite("/content/drive/MyDrive/footballplayer/train_images/CR7/" + path_CR7[i] , img_face)
こんな感じで各選手750枚のうち600枚くらいは顔らしきものが検出されました。
ただ写真のように顔でないものが顔として認識されてしまってたり、別の人だったり、全く同じ写真があったりするので目視確認が必要でした。
腹筋が顔だと認識されるクリロナ、転倒している画像ばかりで顔が認識されないネイマール、後ろ姿が多いメッシ、PSGのチームメイトであるネイマール、メッシが紛れ込むエムバペ...正直目視で写真見続けて不要なものを削除していくのがしんどかったです。
※重複している画像をハッシュ値を用いて検出する方法もあるらしいのですが、作業後に気づきました。次回からはやってみようかな…
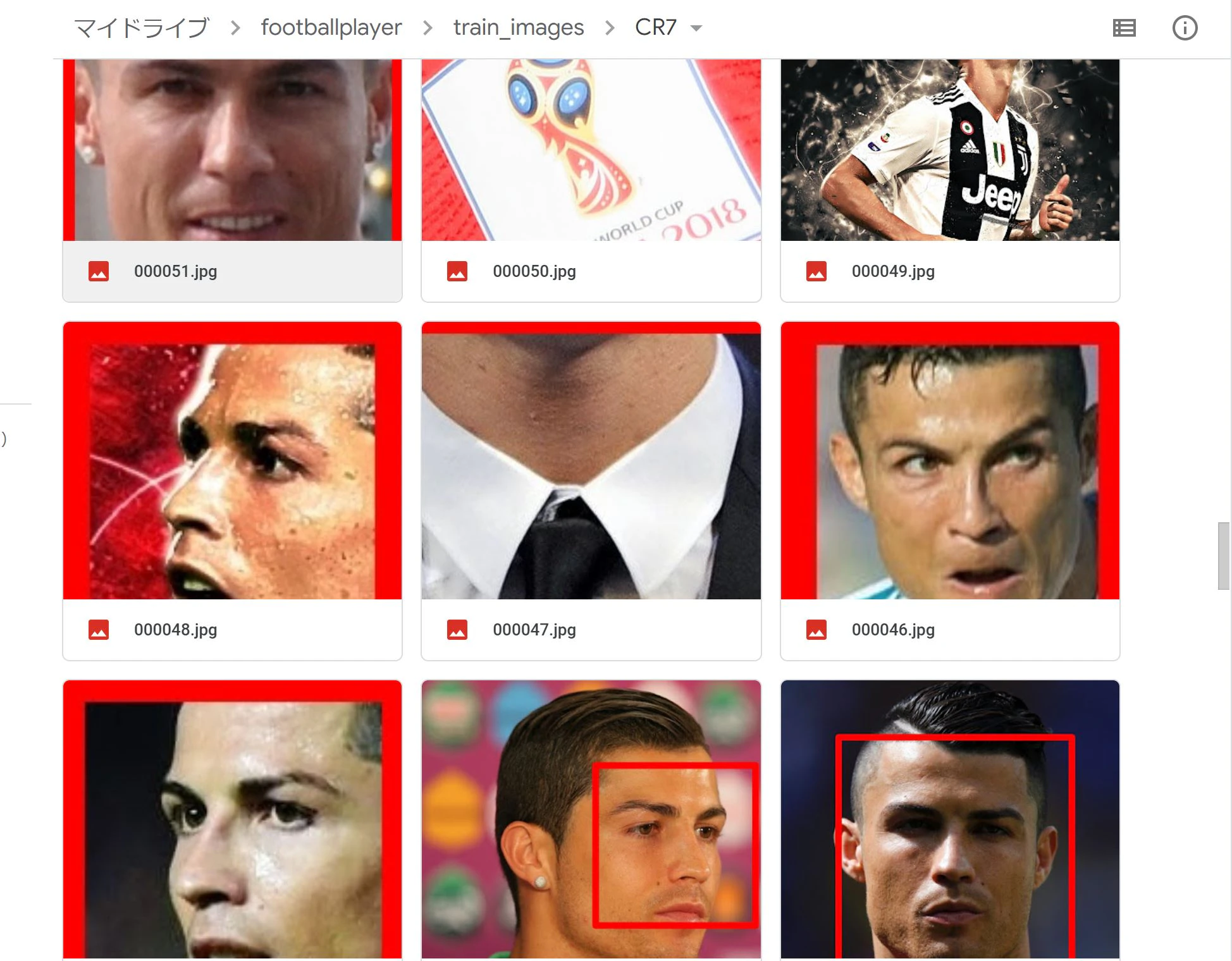
手作業の結果だいたい300枚くらいに絞り込まれましたが、枚数が少ないと精度が上がりません。各選手でだいたい1000枚くらいはあったほうがいいらしいという話を聞きました。なので水増しを行います。
④データ水増し
左右反転、閾値処理、ぼかし、モザイク、縮小が水増しで使われるおおよその手法かと思います。欲張って全部やってみたら300~400枚程度の写真がなんと
messi:11328
CR7:9056
mbappe:15552
neymar:15712
こんなことになってしまいました。ドライブが重くなるし、学習には時間がかかるしでいいことなしです。過ぎたるは猶及ばざるが如しとはまさにこのことかなと…
※今回のようなケースでは識別を行う際の画像データは鮮明なものが大半なのであんまりぼかしやモザイクなどはそれほど効果が大きくないかもしれないそうです。
import os
import glob
import numpy as np
import matplotlib.pyplot as plt
import cv2
# 左右反転の水増しのみ使用
def scratch_image(img, flip=True, thr=True, filt=True, resize=True, erode=True):
# 水増しの手法を配列にまとめる
methods = [flip, thr, filt, resize, erode]
# flip は画像の左右反転
# thr は閾値処理
# filt はぼかし
# resizeはモザイク
# erode は縮小
# をするorしないを指定している
#
# imgの型はOpenCVのcv2.read()によって読み込まれた画像データの型
#
# 水増しした画像データを配列にまとめて返す
# 画像のサイズを習得、ぼかしに使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
# 手法に用いる関数
scratch = np.array([
#画像の左右反転のlambda関数を書いてください
lambda x: cv2.flip(x, 1),
#閾値処理のlambda関数を書いてください
lambda x: cv2.threshold(x, 150, 255, cv2.THRESH_TOZERO)[1],
#ぼかしのlambda関数を書いてください
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
#モザイク処理のlambda関数を書いてください
lambda x: cv2.resize(cv2.resize(x,(img_size[1]//5, img_size[0]//5)), (img_size[1], img_size[0])),
#縮小するlambda関数を書いてください
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# doubling_imagesを用いてmethodsがTrueの関数で水増ししてください
for func in scratch[methods]:
images = doubling_images(func, images)
return images
# メンバー名
#player_name = "CR7"
player_name = "messi"
#player_name = "mbappe"
#player_name = "neymar"
# メンバーの画像フォルダのパス
path ="/content/drive/MyDrive/footballplayer/train_images/messi" # 画像のパス
# メンバーの画像フォルダの中の全画像のパスを取得して配列化
img_path_list = glob.glob(path + "/*")
print(len(img_path_list))
for img_path in img_path_list:
# 画像ファイル名を取得
base_name = os.path.basename(img_path)
print(base_name)
# 画像ファイル名nameと拡張子extを取得
name,ext = os.path.splitext(base_name)
print(name + ext)
# 画像ファイルを読み込む
img = cv2.imread(img_path, 1)
scratch_images = scratch_image(img)
# 画像保存用フォルダ作成
if not os.path.exists(player_name + "_scratch_images"):
os.mkdir(player_name + "_scratch_images")
for num, im in enumerate(scratch_images):
# まず保存先のディレクトリ"scratch_images/"を指定、番号を付けて保存
cv2.imwrite(player_name + "_scratch_images/" + name + str(num) + ext ,im)
print(num)
⑤モデルの構築
いよいよモデルの構築です。講座の課題をベースにしたものになっています。
VGG16の転移学習を行っています。
import os
import glob
import cv2
import numpy as np
import matplotlib.pyplot as plt
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from keras import optimizers
# 各メンバー配列格納
member_list = ["messi", "CR7", "mbappe","neymar"]
print(member_list)
print(len(member_list))
# 各メンバーの画像ファイルパスを配列で取得する関数
def get_path_member(member):
path_member = glob.glob('/content/drive/MyDrive/footballplayer/train_images/' + member +'/*')
return path_member
#リサイズ時のサイス指定
img_size = 64
# 各メンバーの画像データndarray配列を取得する関数
def get_img_member(member):
path_member = get_path_member(member)
img_member = []
for i in range(len(path_member)):
# 画像の読み取り、64にリサイズ
img = cv2.imread(path_member[i])
img = cv2.resize(img, (img_size, img_size))
# img_memberに画像データのndarray配列を追加していく
img_member.append(img)
return img_member
# 各メンバーの画像データを合わせる
X = []
y = []
for i in range(len(member_list)):
print(member_list[i] + ":" + str(len(get_img_member(member_list[i]))))
X += get_img_member(member_list[i])
y += [i]*len(get_img_member(member_list[i]))
X = np.array(X)
y = np.array(y)
print(X.shape)
# ランダムに並び替え
rand_index = np.random.permutation(np.arange(len(X)))
# 上記のランダムな順番に並び替え
X = X[rand_index]
y = y[rand_index]
# データの分割(トレインデータが8割)
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# one-hotベクトルに変換
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデル
input_tensor = Input(shape=(64, 64, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(len(member_list), activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
for layer in model.layers[:15]:
layer.trainable = False
# モデルの読み込み
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
model.summary()
history = model.fit(X_train, y_train, batch_size=64, epochs=50, validation_data=(X_test, y_test))
# モデルの保存
model.save('model.h5')
⑥精度の評価
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
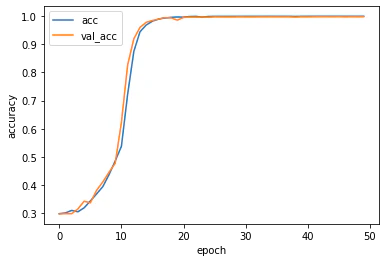
# acc, val_accのプロット
plt.plot(history.history['accuracy'], label='acc', ls='-')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
こんな感じになりました。これまで全然精度が出なかったのでびっくり!!過学習な感じはありますがまあ良しとします。
⑦実装
Flaskとモデルを実装したアプリにします。上記ではモデルが重たすぎて実装することがかないませんでした。
中途半端ですが以下に実装したもののリンクを掲載してみます。
参考URL
転移学習の参考:「ディープラーニングによる画像分類(VGG16の転移学習)」
過去受講生の近しい取組み:「機械学習でPerfumeの顔を分類してみた」
反省
職場との兼ね合いについて
仕事との両立がかなりしんどかったです(言い訳)。業務のスキルアップが目的であれば職場での理解を得ながら進めるほうが良いと思いました(今回はこっそり学習をしていました)。
達成度について
人のモデルを真似して書き替えることができて、どのような内容になっているかはコードを見ればある程度分かるようになったのは大きな成果だと思っています。一方で自身ではエラー内容に対処できない場合があり課題も残る状態です。
基礎能力について
- エラー内容を検索すれば何かしら手がかりがあることはわかりながらも日本語の記事が無かったりすると英語で読んだりしながら対処することが億劫になってしまいました。
-転移学習などでモデルを作れるようにはなったものの、基となる数理知識がないため本質的には理解できているわけではないと思いました。 - エラーの対処時に参照する公式ドキュメントはすべて英語です。大学受験で結構頑張っていたはずなのに、英語の文章を読むのが面倒なので極力関わらないように避けていたなと反省しました。
受講にあたって
- カウンセリングの仕組みやビジネスチャットを用いた質問受付などフォロー制度が厚めであったのに十分に活用できなかったと思っています。恥ずかしがらずに積極的に活用すればよかったと反省しています。
- 講座の終了2週間前くらいから成果物のサポートでカウンセリングの仕組みを活用し始めたら、チューターの手厚いサポート受けられることに気づきました。実際に自分の作成したモデルでつまずいているところを相談して都度解決するようになってから一気に習熟度が上がったと思います。
- プログラミングの学習にあたっては個人的にはAidemyやどこのスクールだと教材が優れているから受講するとかそういう問題ではないと思いました。最低限の知識を得たらどんどん手を動かして、相談に乗ってくれる上級者がいるような環境で学ぶのが楽しいし新しい知識も得られていいのではないかと思いました。そこは独学ではできないことだと思いました。
今後の学習について
直近での学習
- 精度向上に向けて引き続き挑戦
- 今回のモデルで使った周辺知識の定着
中長期での学習について
より深く幅広いPythonの知識の習得:
- 会社においては自分自身がシステムを構築するようなことはないとはいえ、どのような仕組みで動いているかという触りの部分は理解ができました。特に画像識別については、Googleフォトの人物認識やスマート自動販売機での年齢判定、OCRなどレベルは違えど同じような考え方で成り立っている仕組みであるということが理解できたため、あまり実感のもてなかったAI技術が身近になったと思っています。
- 今回は画像識別が主となったため、データ分析や自然言語処理などについても知識を広げたいと思っています。
基礎能力の向上:
- 数学的知識:数学から逃げ続けて私大文系の道を進んだもののより、高度なことをしようとすると避けては通れないであろうことを実感しました。機械学習と関係するところだけでも勉強に励まなければと思います。
- 英語力の向上:エラーが出ても公式のドキュメントをまず読んでみようと思えるくらいの気持ちが持てる程度には復習をしたいと思います。