目次
1.はじめに
2.アプリの概要
3.画像収集のためのスクレイピング
4.集めた画像の下処理
5.モデル学習
6.アプリ作成
7.おわりに
1. はじめに
この記事では、プログラミング未経験の私がAidemy Premium PlanのAIアプリ開発コースを受講した成果物として作成した『Perfume の顔認識、分類アプリ』の製作の流れを書いていきます。
2. アプリの概要
顔画像をアップロードすると、Perfumeの3人のうちで誰に似ているかを教えてくれるアプリです。
3. 画像収集のためのスクレイピング
画像データの収集にはじめはFlickr APIやGoogle APIを使って収集しようとしていたのですが、短期間で十分な枚数が集められなかったので、icrawlerを使用して画像の収集にあたりました。
各画像の枚数 のっち628枚 かしゆか502枚 あーちゃん667枚
4. 集めた画像の下処理
集めた画像の中からこの段階で無関係な画像、ハッキリと顔が映っていない画像等を削除しました。こちらは自力で行いました。また、重複画像をハッシュの値が同じものを探り削除していきます。
これで、不要な画像を削除できたので次に残った画像をOpenCVのカスケード分類器を用いて、画像の中から顔部分をトリミングして保存を行っていきます。ただ、顔以外の部分も抽出されていましたのでその画像に関しても自力で削除していきます。
抽出前の画像

抽出した画像

この時点で集めた画像が のっち310枚 かしゆか175枚 あーちゃん80枚にまで減ってしまいました。
集めた画像だけではデータ数が少ないので、画像の水増しを行います。ただ、現時点で3人の画像枚数に偏りができていましたので、水増しを行う際にできるだけ均等になるようにそれぞれの水増し枚数を調整しました。
| のっち | あーちゃん | かしゆか | |
|---|---|---|---|
| 反転 | 〇 | 〇 | 〇 |
| 閾値 | 〇 | 〇 | 〇 |
| ぼかし | × | 〇 | 〇 |
| モザイク | × | 〇 | × |
| 水増し後 | 1240枚 | 1280枚 | 1400枚 |
import os
import glob
import numpy as np
import matplotlib.pyplot as plt
import cv2
# 左右反転の水増しのみ使用
def scratch_image(img, flip=True, thr=True, filt=True, resize=False, erode=False):
# 水増しの手法を配列にまとめる
methods = [flip, thr, filt, resize, erode]
# flip は画像の左右反転
# thr は閾値処理
# filt はぼかし
# resizeはモザイク
# erode は縮小
# をするorしないを指定している
#
# imgの型はOpenCVのcv2.read()によって読み込まれた画像データの型
#
# 水増しした画像データを配列にまとめて返す
# 画像のサイズを習得、ぼかしに使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
# 手法に用いる関数
scratch = np.array([
#画像の左右反転のlambda関数を書いてください
lambda x: cv2.flip(x, 1),
#閾値処理のlambda関数を書いてください
lambda x: cv2.threshold(x, 150, 255, cv2.THRESH_TOZERO)[1],
#ぼかしのlambda関数を書いてください
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
#モザイク処理のlambda関数を書いてください
lambda x: cv2.resize(cv2.resize(x,(img_size[1]//5, img_size[0]//5)), (img_size[1], img_size[0])),
#縮小するlambda関数を書いてください
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# doubling_imagesを用いてmethodsがTrueの関数で水増ししてください
for func in scratch[methods]:
images = doubling_images(func, images)
return images
# メンバー名
member_name = "k"
# member_name = "o"
# member_name = "n"
# メンバーの画像フォルダのパス
path ="./" + member_name + "_face " # 画像のパス
# メンバーの画像フォルダの中の全画像のパスを取得して配列化
img_path_list = glob.glob(path + "/*")
print(len(img_path_list))
for img_path in img_path_list:
# 画像ファイル名を取得
base_name = os.path.basename(img_path)
print(base_name)
# 画像ファイル名nameと拡張子extを取得
name,ext = os.path.splitext(base_name)
print(name + ext)
# 画像ファイルを読み込む
img = cv2.imread(img_path, 1)
scratch_images = scratch_image(img)
# 画像保存用フォルダ作成
if not os.path.exists(member_name + "_scratch_images"):
os.mkdir(member_name + "_scratch_images")
for num, im in enumerate(scratch_images):
# まず保存先のディレクトリ"scratch_images/"を指定、番号を付けて保存
cv2.imwrite(member_name + "_scratch_images/" + name + str(num) + ext ,im)
print(num)
5. モデル学習
これで下準備が整ったので、モデル学習を行えます。
その際には画像を学習しやすいように64×64サイズにリサイズを行い学習させます。
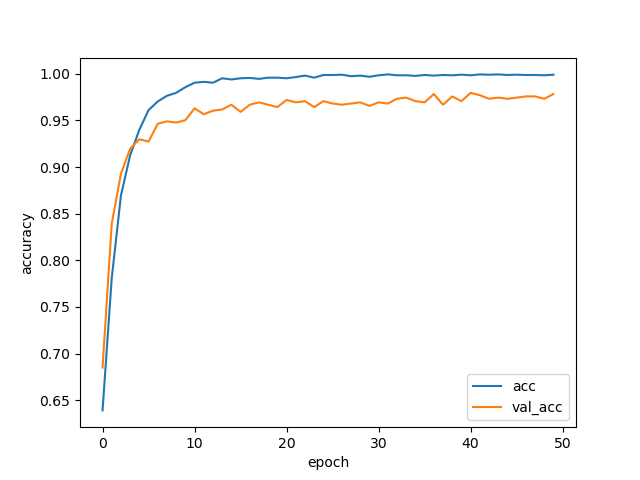
学習結果は以下のようにかなり高い精度をだせました。
Test loss: 0.10524305632119352
Test accuracy: 0.9783163265306123
import os
import glob
import cv2
import numpy as np
import matplotlib.pyplot as plt
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from keras import optimizers
# 各メンバー配列格納
member_list = ["o", "n", "k"]
print(member_list)
print(len(member_list))
# 各メンバーの画像ファイルパスを配列で取得する関数
def get_path_member(member):
path_member = glob.glob('./' + member + '_scratch_images/*')
return path_member
# リサイズ時のサイス指定
img_size = 64
# 各メンバーの画像データndarray配列を取得する関数
def get_img_member(member):
path_member = get_path_member(member)
img_member = []
for i in range(len(path_member)):
# 画像の読み取り、64にリサイズ
img = cv2.imread(path_member[i])
img = cv2.resize(img, (img_size, img_size))
# img_sakuraiに画像データのndarray配列を追加していく
img_member.append(img)
return img_member
# 各メンバーの画像データを合わせる
X = []
y = []
for i in range(len(member_list)):
print(member_list[i] + ":" + str(len(get_img_member(member_list[i]))))
X += get_img_member(member_list[i])
y += [i]*len(get_img_member(member_list[i]))
X = np.array(X)
y = np.array(y)
print(X.shape)
# ランダムに並び替え
rand_index = np.random.permutation(np.arange(len(X)))
# 上記のランダムな順番に並び替え
X = X[rand_index]
y = y[rand_index]
# データの分割(トレインデータが8割)
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# one-hotベクトルに変換
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデル
input_tensor = Input(shape=(64, 64, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(len(member_list), activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
for layer in model.layers[:15]:
layer.trainable = False
# モデルの読み込み
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
model.summary()
history = model.fit(X_train, y_train, batch_size=64, epochs=50, validation_data=(X_test, y_test))
# モデルの保存
model.save('model.h5')
# 精度の評価(適切なモデル名に変えて、コメントアウトを外してください)
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# acc, val_accのプロット
plt.plot(history.history['acc'], label='acc', ls='-')
plt.plot(history.history['val_acc'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
6. アプリ作成
最後に保存した学習データを用いて、flaskでウェブアプリケーションとして形にしていきます。
完成したページはこちら
https://perfumetest2.herokuapp.com/
では、実際に”のっち”に似ていると言われている久保田智子アナで試してみましょう。

期待していた結果が返ってきました。
ではもう一つ、”あーちゃん”と似ているらしいNiziUのニナで試してみます。

こちらも期待通りの結果がかえってきました。
import os
import cv2
from flask import Flask, request, redirect, url_for, render_template, flash
from werkzeug.utils import secure_filename
from keras.models import Sequential, load_model
from keras.preprocessing import image
import tensorflow as tf
import numpy as np
classes = ["のっち","あーちゃん", "かしゆか"]
num_classes = len(classes)
image_size = 64
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
# 顔を検出して顔部分の画像(64x64)を返す関数
def detect_face(img):
# 画像をグレースケールへ変換
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# カスケードファイルのパス
cascade_path = "./haarcascade_frontalface_alt.xml"
# カスケード分類器の特徴量取得
cascade = cv2.CascadeClassifier(cascade_path)
# 顔認識
faces=cascade.detectMultiScale(img, scaleFactor=1.1, minNeighbors=1, minSize=(10,10))
# 顔認識出来なかった場合
if len(faces) == 0:
face = faces
# 顔認識出来た場合
else:
# 顔部分画像を取得
for x,y,w,h in faces:
face = img[y:y+h, x:x+w]
# リサイズ
face = cv2.resize(face, (image_size, image_size))
return face
# 学習済みモデルをロードする
model = load_model('./model.h5')
graph = tf.get_default_graph()
@app.route('/', methods=['GET', 'POST'])
def upload_file():
global graph
with graph.as_default():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み
img = cv2.imread(filepath, 1)
# 顔検出して大きさ64x64
img = detect_face(img)
# 顔認識出来なかった場合
if len(img) == 0:
pred_answer = "顔を検出できませんでした。他の画像を送信してください。"
return render_template("index.html",answer=pred_answer)
# 顔認識出来た場合
else:
# 画像の保存
image_path = UPLOAD_FOLDER + "/face_" + file.filename
cv2.imwrite(image_path, img)
img = image.img_to_array(img)
data = np.array([img])
print(data.shape)
result = model.predict(data)[0]
print(result)
predicted = result.argmax()
pred_answer = classes[predicted] + " 似です"
message_comment = "顔を検出できていない場合は他の画像を送信してください"
return render_template("index.html",answer=pred_answer, img_path=image_path, message=message_comment)
return render_template("index.html",answer="")
if __name__ == "__main__":
app.run()
7. おわりに
学習結果に高い精度を出せたのは、おそらく本人たちの顔がはっきりと写っている有用な画像を多く集めることが出来たからなのではないかと思います。
Aidemyで機械学習を学んでいる際にも、学習データの重要性を何度も聞きましたが今回のアプリ製作を通じてそのことを実際に体感できました。また、環境構築については受講初期から最後まで苦労しました。この点についてはこれからも自身で調べながら取り組んでいきたいと思います。
Aidemyでの3ヵ月間は当初は分からないことだらけでチューターの方々の様々なアドバイスがなければ成果物を製作することは難しかったと思います。3ヵ月間、本当にありがとうございました!
今後も今回の経験を活かしてまた別のアプリ製作にも挑戦していきたいと思います!
※参考リンク
画像データをキーワード検索で効率的に収集する方法(Python「icrawler」のBing検索)
https://www.atmarkit.co.jp/ait/articles/2010/28/news018.html
Python ハッシュ - 同じ内容のファイルを見つける
https://ailog.site/2020/03/07/0307/
大量の画像から顔の部分のみトリミングして保存する方法
https://ai-coordinator.jp/opencv_face
ディープラーニングを使用して「あなたにそっくりな女優判別プログラム」を作ったおはなし
https://qiita.com/k_eita/items/a50a4cae0aa2598422e4
【Aidemy成果物】嵐のメンバーの画像認識アプリを作ってみた!
https://toge510.com/2019/12/13/madeappofimagerecognition/#i-7