はじめに
前回の記事
においてVisual Studio 2022のパフォーマンスプロファイラーを使ってコードを分析した結果を示しましたが、今回はホットスポットのひとつである平衡分布関数の計算について、実装方法の違いによる実行速度の比較を行いました。プログラムのベンチマーク測定にはgoogle benchmarkを使用しました。
コード
実行環境
OS:Windows 11 Pro
CPU:Intel Core i7-9700K 8C/8T 3.60GHz
コンパイラ:Visual Studio 2022
最適化オプション:O2
測定結果
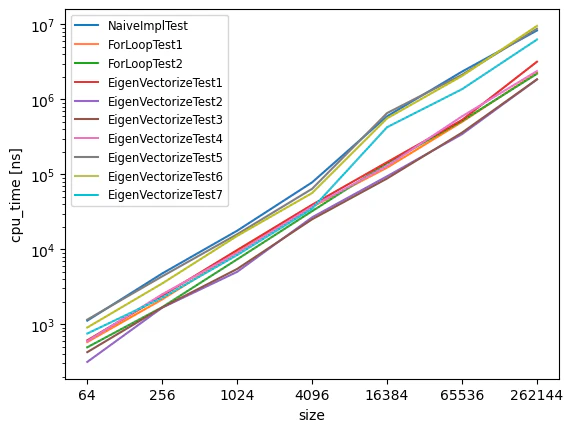
D2Q9格子の平衡分布関数を様々な実装方法で計算したプログラムについて、横軸にセル数、縦軸にCPU時間をとってプロットした結果を下図に示します。セル数が$262,144=512^2$の時、実行時間が最も短いEigenVectorizeTest2/EigenVectorizeTest3と最も長いもののひとつであるNaiveImplTestの間で約4.5倍の差がついており、実装方法に注意を払う必要があることがわかります。
ここでは一部のプログラムの詳細のみ紹介するので、その他はbenchmark/run_feq_benchmark.cppを参照してください。まずNaiveImplTestはEigenの機能を使って下記の様に素直に実装したプログラムです。
// u_ : velocity (2 x N)
// c_ : lattice vector (2 X 9)
// w_ : weight coeffs (9 x 1)
// feq_ : equilibrium distribution function (9 x N)
// rho_ : density (N x 1)
// N : number of cells
const Eigen::Matrix<double, 9, Eigen::Dynamic> cu = c_.transpose() * u_;
const Eigen::Matrix<double, 1, Eigen::Dynamic> u2 =
u_.colwise().squaredNorm();
feq_ = ((w_ * rho_.transpose()).array() *
(1.0 + 3.0 * cu.array() + 4.5 * cu.array().square() -
1.5 * u2.replicate<9, 1>().array())).matrix();
一方、EigenVectorizeTest2は下記の様にセルごとにforループで計算するようにしたプログラムです。
const Eigen::VectorXd u2 = u_.colwise().squaredNorm().transpose();
for (int i = 0; i < feq_.cols(); ++i) {
const Eigen::Matrix<double, 9, 1> cu = c_.transpose() * u_.col(i);
feq_.col(i) =
(rho_(i) * w_.array() *
(1.0 + 3.0 * cu.array() + 4.5 * cu.array().square() - 1.5 * u2(i)))
.matrix();
}
興味深いことに、EigenVectorizeTest2のfeq_.col(i) = ...の部分をforループを使って下記のように実装したForLoopTest2の実行時間はEigenVectorizeTest2の1.2倍かかりました。このようにEigenの機能をうまく使うと、コンパイラがコードを最適化してくれる場合があります。
for (int i = 0; i < feq_.cols(); ++i) {
const auto u2 = u_.col(i).squaredNorm();
const Eigen::Matrix<double, 9, 1> cu = c_.transpose() * u_.col(i);
for (int k = 0; k < 9; ++k) {
feq_(k, i) = w_(k) * rho_(i) *
(1.0 + 3.0 * cu(k) + 4.5 * cu(k) * cu(k) - 1.5 * u2);
}
}
その他
科学技術計算において実装方法に迷った場合、本記事のように特定の部分のみ切り出してベンチマーク測定し、最も実行速度の速いものを選択するといいでしょう。実行環境によっては、もっと高いパフォーマンスを出せる実装方法があると思うので、色々試してみてください。