文書の中に含まれる表やフォームをパースして構造化データを抽出するクラウドサービスがあります。 具体的に挙げると、Textract(AWS), FormRecognizer(Azure), DocumentAI(Google)、rossum.ai, tabula(java), camelot(python), CascadeTabNet(深層学習), その他なのですが、AdobeがあらたにPDF Extract APIというサービスを公開したそうなので早速使ってみました
Adobe PDF Extract APIにはPDFに関連する様々な機能があるのですが、興味がないので割愛。構造化データを抽出する機能のみを使っています。
Java版のプログラムをダウンロードし、マニュアル通りにインストールしてビルド。割愛。
テスト1 サンプル文書中の表
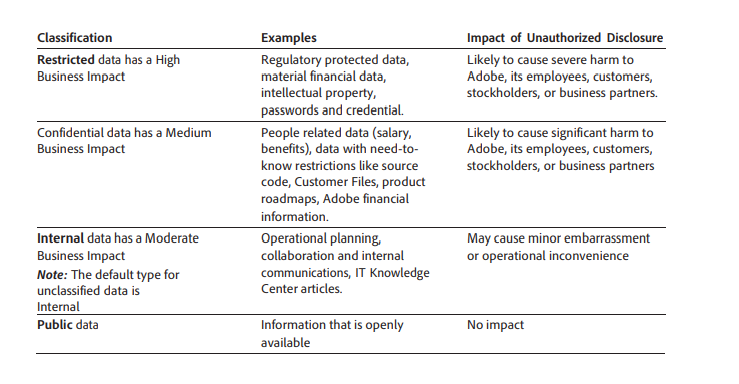
結果1
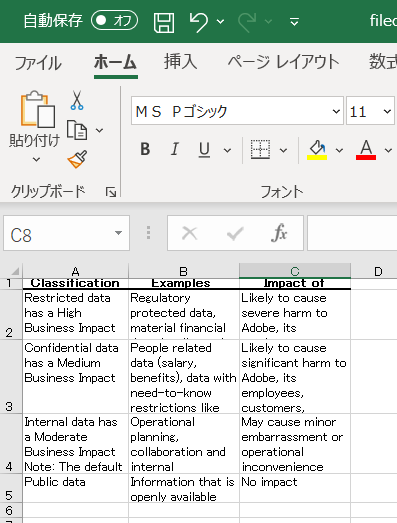
評価1
あたりまえのようにパーフェクト。ヘッダーが認識できているように見える。
テスト2 日本語罫線一部なし

結果2

評価2
日本語が通る。ヘッダーとして認識されるとExcel変換時にBoldになるつまり
ヘッダーを認識しようとしている。テーブル外のフッターやヘッダーは無視なのか。
テスト3 複数行カラム

結果3

評価3
複数行カラムは苦手のよう
テスト4 縦に複数テーブル
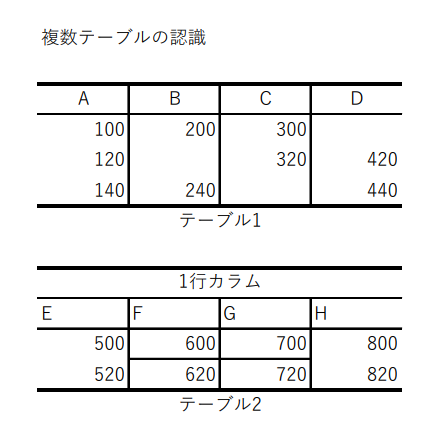
結果4

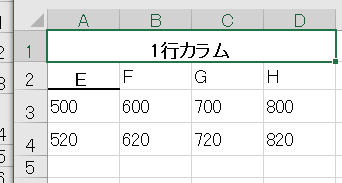
評価4
複数のテーブルの認識は可能。セルの検出が間違ってる。テキストのアラインメントも一部間違っているけれども拾っている。
テスト5 横に複数のテーブル

結果5

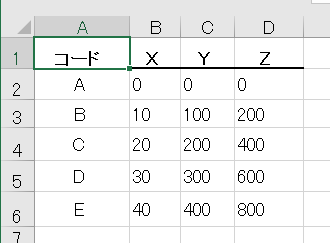
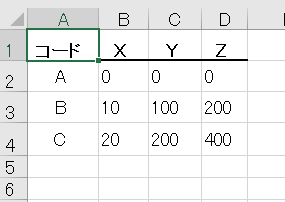
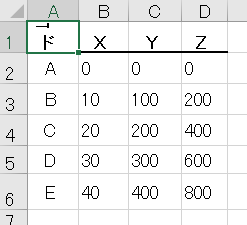
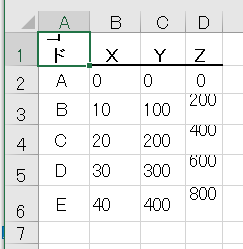
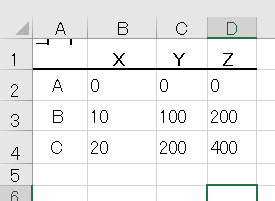
評価5
6つのテーブルを正しく認識できている。
テスト6 点線
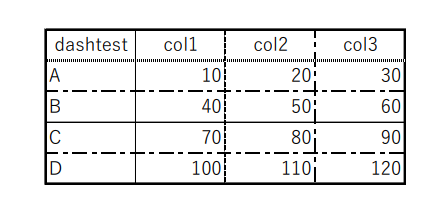
結果6
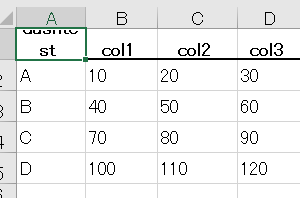
評価6
認識は正確。テストが良くない。点線の検出にはなっていないかも。
テスト7 罫線なし列挙型
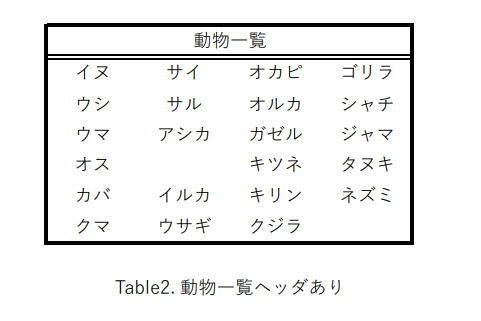
結果7

評価7
罫線なしでもセルを認識できる(1行なら)。枠外のテキストは拾わない仕様のようだ。
テスト8 テキストテーブル現実版
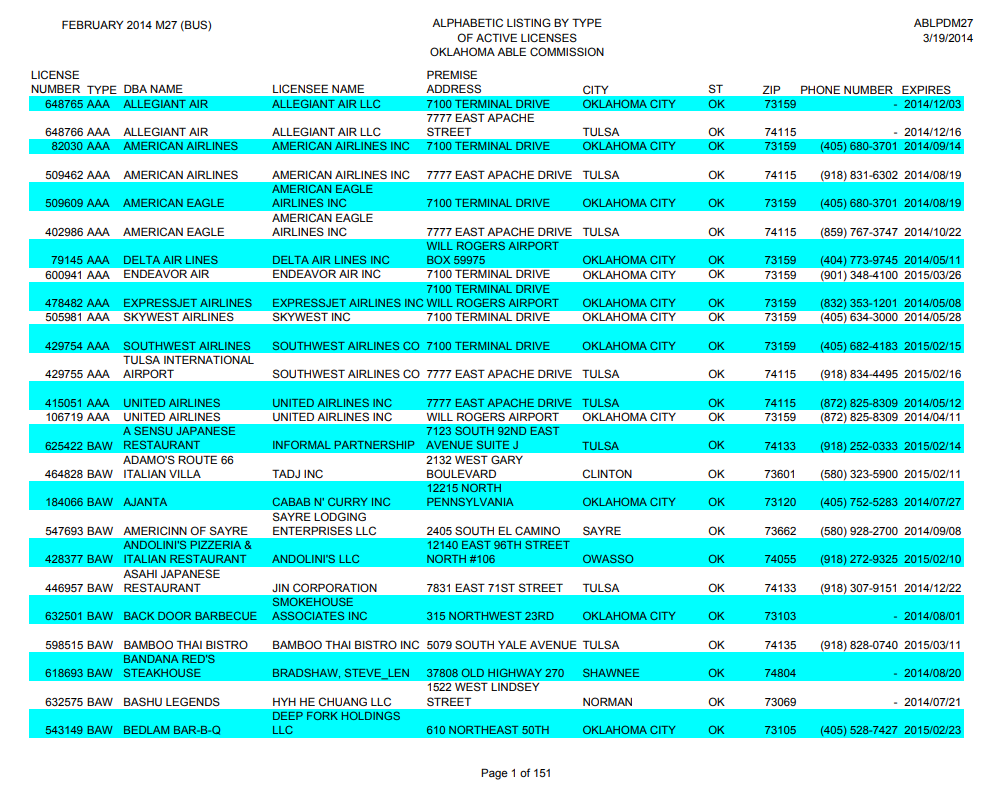
結果8
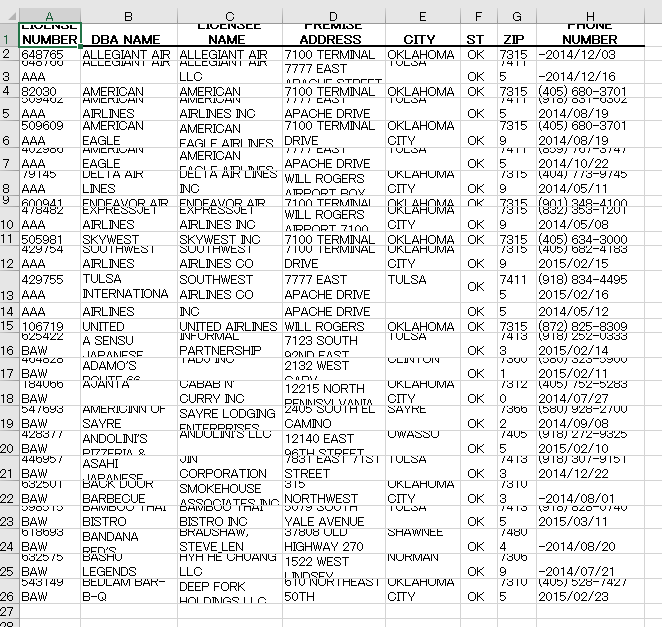
評価8
カラムの認識が間違っている。惜しい!
テスト9 日本の現実バージョン
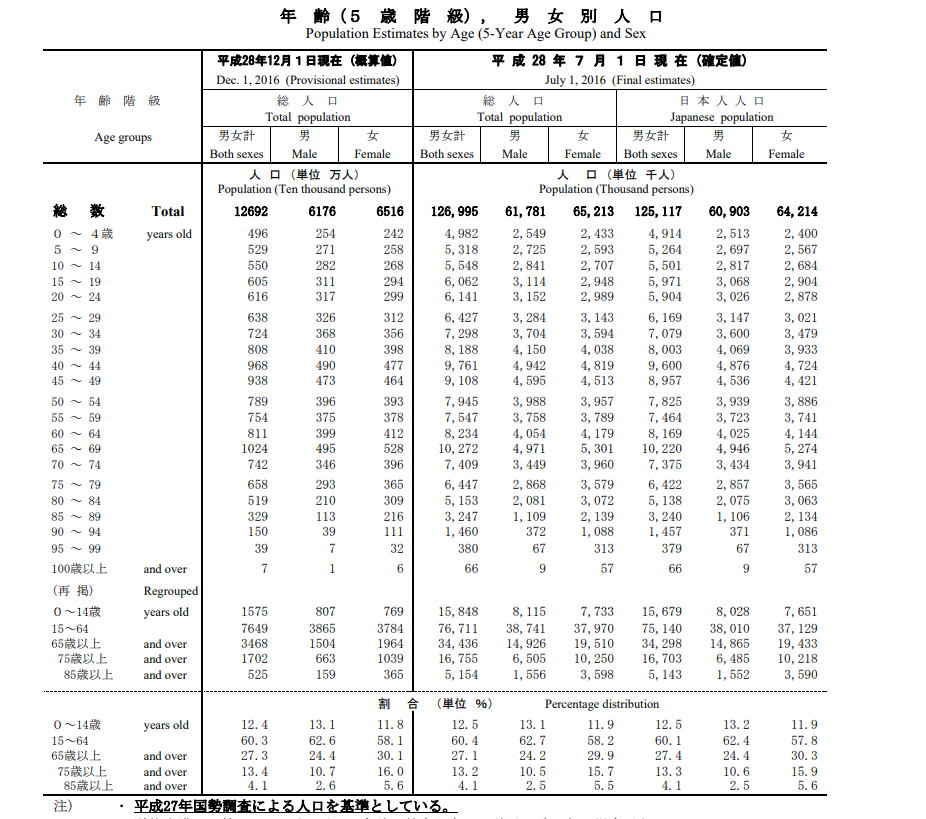
結果9

評価9
一部カラムがおかしいが、それは元の表がこれなので仕方ない。よくやってるほう。
テスト10 個票現実バージョン

結果10

評価10
パーフェクト。
まとめ
他社の競合サービスよりも性能が良い。完全ではないが十分使いものになる。負けました。