概要
はじめて「robots.txt」に触れる方が概要把握できるよう、下記の流れでまとめました。
①(前提知識となるSEOにおける)「クローラー」とは?
②「robots.txt」とは
③実際の使用例と書き方
①「クローラー」とは?

WEB上のファイル、画像等を収集するためのプログラム(ロボットとも呼びます)のことで、Googleなどのロボット型検索エンジンが利用しています。クローラーがWEB上のファイルを集めることを**「クローリング」**といいます。
Google等の検索エンジンは、集められたファイルの情報を元にして検索データベース(以下DB)を作成します。このDBの情報を元に、普段私たちが検索した時の表示順番は決められています。
ちなみに、上記のDBに登録することを**「インデックス化」、DBに登録されたデータを「インデックス」**といいます。
また、クローラーは2個の特徴を持っています。
1.ファイル(ページ)のリンクを辿って巡回すること
2.巡回できるファイル(ページ)の数には、ドメイン毎に限りがあること
①をまとめると、以下のようになります。
| 用語 | 説明 |
|---|---|
| クローラー | ・WEB上のファイルを収集→DB作成するためのプログラム ・ファイルのリンクを辿って巡回する ・ドメイン毎に巡回できるファイル数は有限 |
| クローリング | WEB上を巡回してファイルを集めること |
| インデックス | DBに登録されたデータ |
| インデックス化 | DBに登録すること |
②「robots.txt」とは?

クローラーに対して、WEB上のファイルへのアクセスを制御するためのテキストファイルのことです。
このフォルダ配下はアクセスNG、このファイルのみアクセスOK等具体的に指示をすることができます。
サイトの規模が大きくなると、前述した「ドメイン毎に巡回できるファイル数は有限」により、「新しく公開したページがなかなかインデックスされない」といった問題が発生します。
そこで、アクセスが不要なフォルダ・ファイルをあらかじめ指定 → クローラーのサイト回遊効率上昇を目的として、「robots.txt」は作成されます。
実際に設置する際は、テキストエディタ(メモ帳など)で、ファイル名を「robots.txt」とすればOKです(名称にsが入ることにご注意ください)。保存先は、ルートディレクトリ直下(一番上の階層)になります。
②をまとめると、以下のようになります。
| 項目 | 説明 |
|---|---|
| 何か | クローラーのアクセス制御 |
| 何のために作るか | クローラーの回遊効率向上 |
| どう作るか | テキストエディタで作成(具体的な記述は③で解説) |
| どこに保存するか | ルートディレクトリ直下(一番上の階層) |
③実際の使用例と書き方
実際に「ZOZOTOWN」で使用している「robots.txt」の内容を例に解説します。
下記のURLを指定・アクセスすることで、表示可能です。
▼URL
[https://zozo.jp/robots.txt](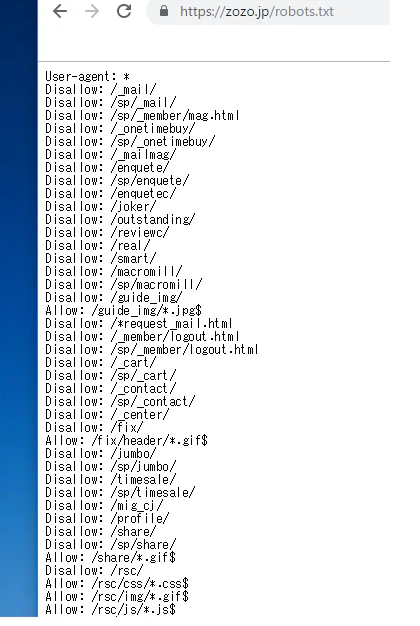
https://zozo.jp/robots.txt)
▼表示の一部
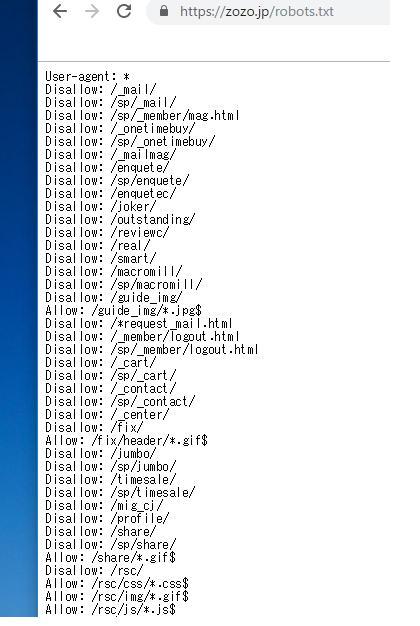
上記から基本的な書き方となる例文をいくつか抜粋・解説します。
User-agent : * ※全てのクローラーが対象
「User-agent」で制御するクローラーを指定します。「*」は「全クローラー」を意味しており、個別でUser-agentを指定することも可能です。
User-agent : Googlebot ※Googlebotのみ対象
User-agent : Baiduspider ※百度のみ対象
User-agent : Bingbot ※bingのみ対象
<文の意味>
全クローラーを制御する
Disallow: /_mail/
「Disallow」は「クロールをブロックするディレクトリ・ファイル」の指定時に使用します。
<文の意味>
「/_mail/」配下のフォルダ・ページは、クロールNG
Allow: /_mail/*.jpg$
「Allow」は、クロールをブロックするファイル群の中に、「例外的にクロールさせたいファイル」がある時に使用します。
また、robots.txtは正規表現を一部使用可能なため、複数ページをまとめて指定する際に活用します。
「*」は0個以上の有効な文字を示し、「$」はURLの末尾を示しており、下記いずれののファイルにもマッチするような指示です。
/_mail/a.jpg$
/_mail/bb.jpg$
/_mail/ccc.jpg$
<文の意味>
「_mail/」配下で、「.jpg」の記述が含まれるファイルは、クロールOK
Sitemap: https://zozo.jp/sitemapindex.xml
「Sitemap」は、「sitemap.xml」の保存先を指定する時に使用します
*「sitemap.xml」はサイト内のURLが記述されたファイルで、クローラーがサイト内を巡回する際の参考となるものです。
指定することで、クローラーがsitemap.xmlにアクセスしやすくなり、クロールの効率が上がります。
<文の意味>
Sitemapの保存先は「https://zozo.jp/sitemapindex.xml」
上記で出てきた語句を個別にまとめます。
| 記述内容 | 意味 |
|---|---|
| User-agent | 制御したいクローラーを指定 |
| * | 全クローラー、の意味 |
| Disallow | クロールをブロックするディレクトリ・ファイルを指定 |
| Allow | クロールをブロックするファイル群の中に、「例外的にクロールさせたいファイル」がある時に指定 |
| * (正規表現) |
0個以上の有効な文字 |
| $ (正規表現) |
URLの末尾 |
| Sitemap | sitemap.xmlの保存先を指定 |
参考ページ
▼語句や使用例など
https://developers.google.com/search/reference/robots_txt?hl=ja
https://www.seohacks.net/basic/terms/robots_txt/
▼文中のイラストは下記サイトからDLさせて頂きました。著作権フリーです。
https://illustimage.com/
https://www.irasutoya.com/