概要
PointConvを題材に点群 (point cloud) を深層学習で扱う方法の歴史と画像 (密な離散座標データ) のCNNを点群 (疎な連続座標データ) に一般化した話です。論文ではもう少し計算効率化の話とかもあるんですが、それは省略します。
背景
点群とその特徴
wikipediaによると、点群とは「コンピュータで扱う点の集合のこと」であり「多くの場合、空間は3次元であり、直交座標 (x, y, z) で表現されることが多い」です。LiDARなんかで集められたデータです。
位置 (xyz) の他に色 (RGB) や法線の情報が載っていることもあるようです。
点群の特徴 (問題点) が後で紹介する PointNet の論文に述べられています。
- Unordered (順不同)
- Interaction among points (近い点同士の相互関連)
- Invariance under transformations (移動・回転など一定の変換に対して不変)
2 と 3 は点群でどうやってネットワークにその特徴を取り込むかという問題はあるものの、画像についても同じことが言えます。
厄介なのは 1 です。画像はデータの位置が近いものは実際の意味としても位置が近く、近くのデータをまとめることで 2 の特徴も取り込めます。しかし、点群はデータの並びに意味がなく、[[0.1, 0.1, 0.1], [0.2, 0.2, 0.2], [0.3, 0.3, 0.3]] と [[0.3, 0.3, 0.3], [0.1, 0.1, 0.1], [0.2, 0.2, 0.2]] は同じデータです。
また、後継のPointNet++では、 density (密度) についても問題にしています。LiDARなどで取得したデータは、計測機器の近くにあるものほど点の密度が高くなるということです。
畳み込みとカーネル密度推定
画像のCNN (畳み込みニューラルネットワーク) の初歩的な内容については今ではいろいろ情報もありますし知っているものとして、その他の後で必要になることをここで言及しておきます。(とは言っても統計や機械学習を大学とかで勉強していればやっているはずの内容ですが)
知っている人は飛ばしてください。
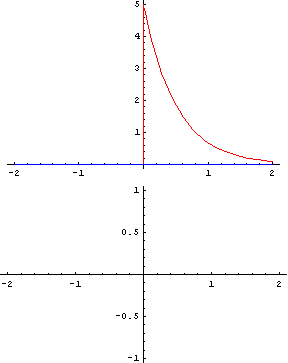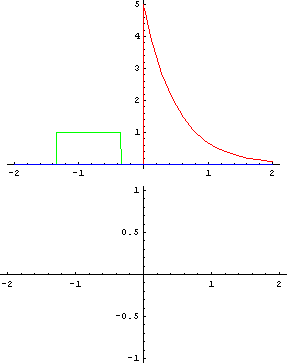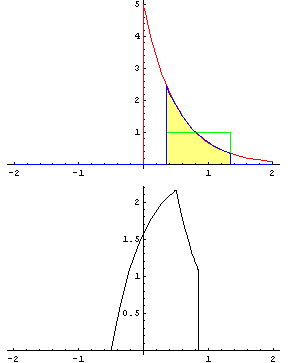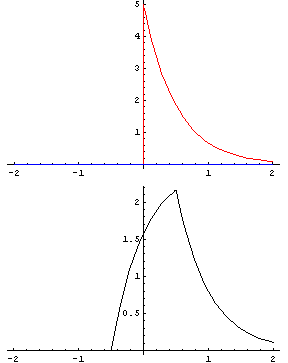
畳み込みとは「関数 g を平行移動しながら関数 f に重ね足し合わせる二項演算」です。何言ってるかよくわからないですが、wikipediaにあるアニメーションで見ればわかりやすいです。
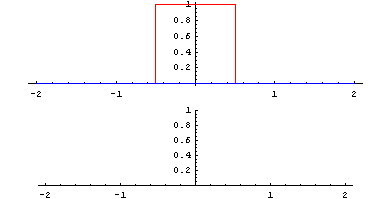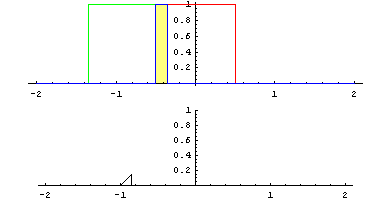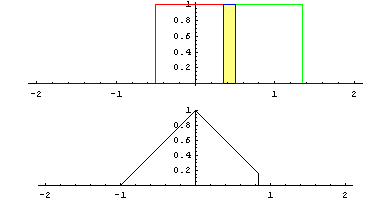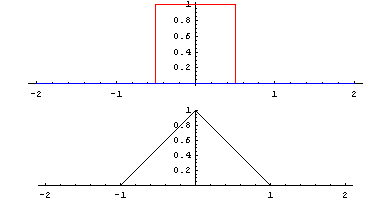
Lautaro Carmona - 投稿者自身による作品, CC 表示-継承 4.0, https://commons.wikimedia.org/w/index.php?curid=3066394による
緑が関数 g で赤が関数 f 、黄色い面積 (積分) がその地点における畳み込みの値で、下のグラフが全体の畳み込みを終えた結果と思ってください。
カーネル密度推定とは、「統計学において、確率変数の確率密度関数を推定するノンパラメトリック手法のひとつ」です。これだけで何言ってるかわかる人はいないはずですが、カーネル関数 g を各データ点に乗せたものを足し合わせてデータの母集団の確率密度関数を推定する手法です。

Patrick87 - Redone with source code from Parzen window illustration.png in MATLAB R2012a. Converted to SVG with Inkscape., パブリック・ドメイン, https://commons.wikimedia.org/w/index.php?curid=22613802による
実のところ、これも畳み込みです。
3Dを扱う方法の系統
画像を拡張する
画像の枚数 (アングルの違うもの) を増やすか画像のチャネル (RGB-D=深度) を増やす方法です。普通の画像のCNNとたいして変わらないので想像はできるかと思います。
CNNを拡張する
点群が存在する空間を等間隔に区切って、離散座標にデータを集約し、Conv3Dを適用する方法です。値は空間内の点の有無 (0, 1) や点の数 (密度) が入るんじゃないかと思います。VoxelとかVolumetricというのが入ってたら、たぶんこれです。
イメージはMinecraftやドラゴンクエストビルダーズみたいな世界にしてからCNNを適用するものです。
点群をそのまま扱う
上のような点群をなんとかCNNのパラダイムに押し込めて扱おうというところから、点群を点群として扱う方法を提案したのがPointNetです。
何をしたかというと、各点 (N個) に対して重み共有したMLP (多層パーセプトロン) を通し、各点ごとに1024個のノード (Nx1024) を出力します。そこにMaxPoolingをかけて全体の特徴 (1024) とし、認識 (分類) タスクならそこからMLPを通して推論します。(他にも変換に対する不変性を獲得する操作などあるけど省略します)
CNNをなんとなくしか理解していないとイメージがわかないかもしれないので、画像のCNNに例えると、RGBの代わりにxyzの値が入った画像に対して1x1 Convを繰り返して最終的に1024チャンネルの特徴マップにし、GlobalMaxPoolingをかけて特徴抽出したことと等価です。入力に座標しか使っていないので得られたベクトルの1024個の要素は、それぞれある狭い領域に点があるかないかを表すようなものではないかと思います。
こんな方法だけどうまくいったのがPointNetです。こちらのほうが解説詳しいです。
PointNet++ではもう少しCNNに寄せてきていて、点群全体にPointNetを適用するのではなく、局所領域に限定してPointNetを適用し (それを複数の局所領域で行う) 、局所的な特徴を抽出、さらにその特徴群の局所領域に限定してPointNetを (以下省略) して階層的に特徴抽出していくような構造になっています。
そして、本題のPointConvも点群をそのまま扱う方法です。
PointConv
PointConvが何なのかというのは、同じような時期に同じような名前で同じような内容を提案したConvPointのタイトルのほうがわかりやすいですが、点群処理のために連続値の畳み込みを適用するよって内容です。ある点をとったときに、その点からの相対座標で他の点を表し、そこにカーネル関数を適用して畳み込み完了です。 (カーネル関数?そんなものはMLP使ってデータから近似すればいいよね)
考えてみれば畳み込みはそもそも離散座標じゃなくてもいいというか、それが本来の姿で、画像に都合がいいから離散座標の特化型を作って使ってたわけです。
論文内では他にもカーネル密度推定を使って点群の密度による影響を取り除いたりとか、いくつか提案していますが、そちらは論文を読んでください。