概要
- low-codeで、機械学習ができるライブラリのPyCaretがついに、v1.0になりました。
- 機械学習モデルの 可視化 が便利なので、モデルの可視化 に着目し、まとめてみます。
- ソースを確認すると、部分的に内部でYellowbrick@HP(Yellowbrick@qiita)を利用しているようです。
- なお、QiitaでもPyCaretタグの下記で取り上げられています。
やること
列挙してみると下記の通りですが、pycaretの自動化により数行で実行できます。
- ①データ(クレジットカードのデフォルト)をロード
- ②前処理
- ③モデル比較(アルゴリズム間の性能比較)
- ④パラメータチューニング
- ⑤モデルの可視化(★ここがメインなので、冒頭でここを説明★)
やってみる(⑤モデルの可視化)
- 手順上は 1番最後 なのですが、この記事の目的が可視化なので、最初 に扱いたいと思います。
⑤モデルの可視化
- 出来上がったモデル(tuned_model)に対してモデルの特性を可視化していきます。
- evaluate_model関数に、出来上がったモデルを渡すことで、下記のメニューが表示されます。
- tuned_modelがどう出来上がったか?は後述します。まずは可視化を説明。
evaluate_model(tuned_model)
- クリックするだけで、ROC曲線、学習曲線、混同行列等々、様々なプロットが可能です。
- 気になったものを取り上げて、一つ一つ見ていきたいと思います。
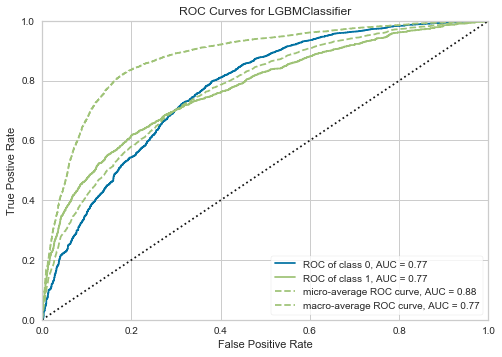
AUC (ROC曲線)
- AUCとは書いてありますが、ROC曲線を描画できます。
- 2クラス分類だったので、Positive/Negativeクラスに対して2種類描画されます。
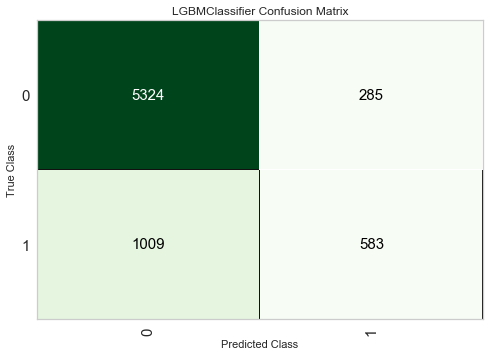
Confusion Matrix
-
こちらもよく見る混同行列です。ヒートマップで出力されます。
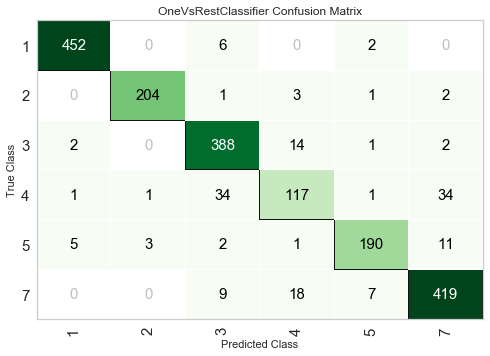
-
二値分類だと見栄えが寂しいですが、多値分類になると色々な間違え方が見えてきます。
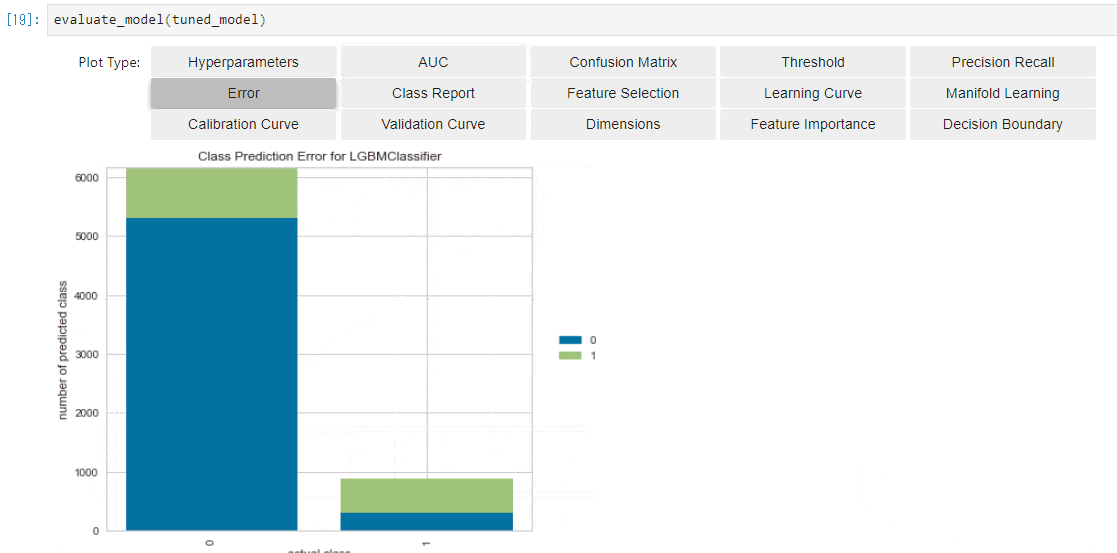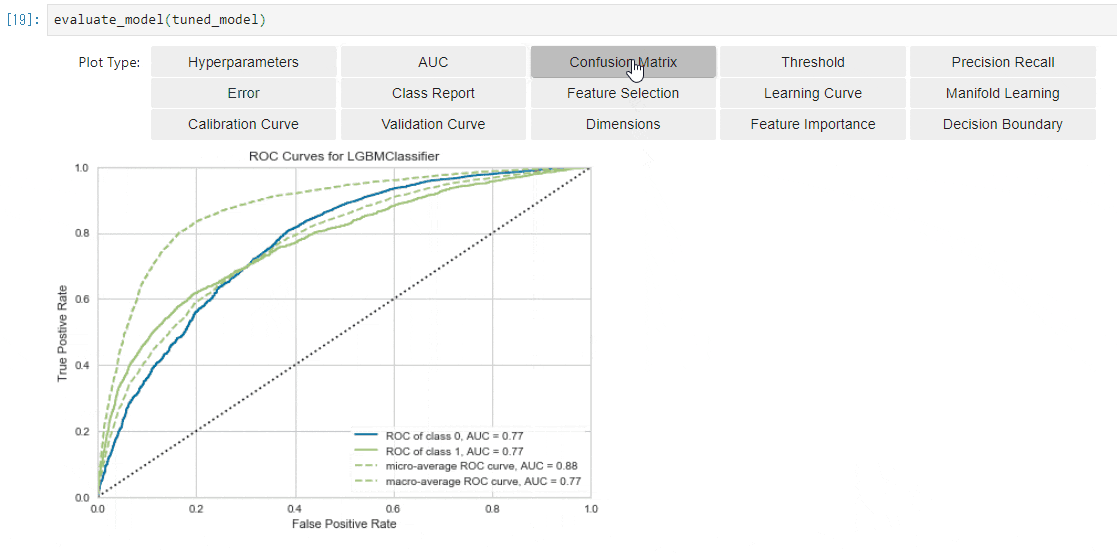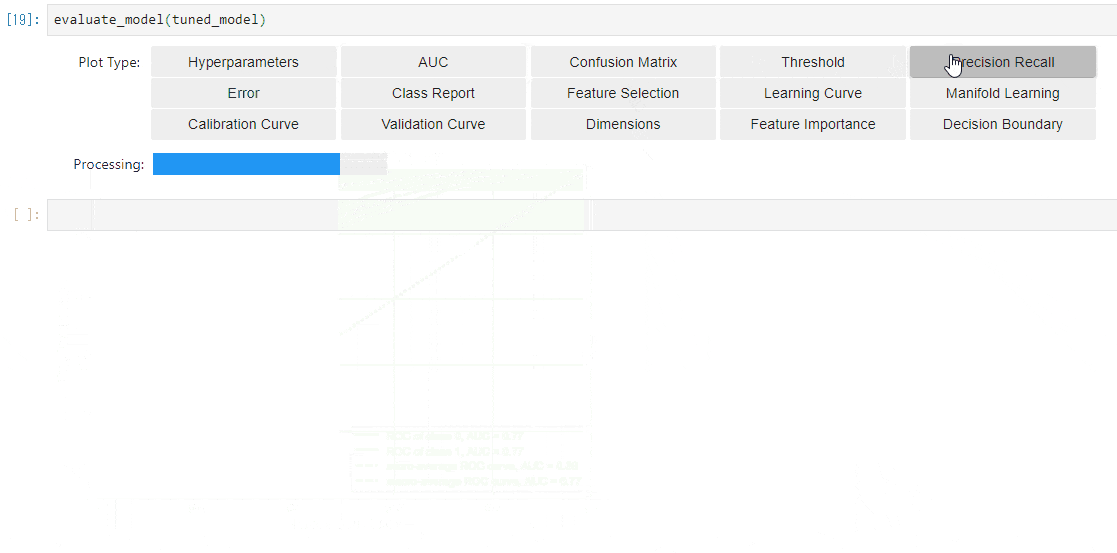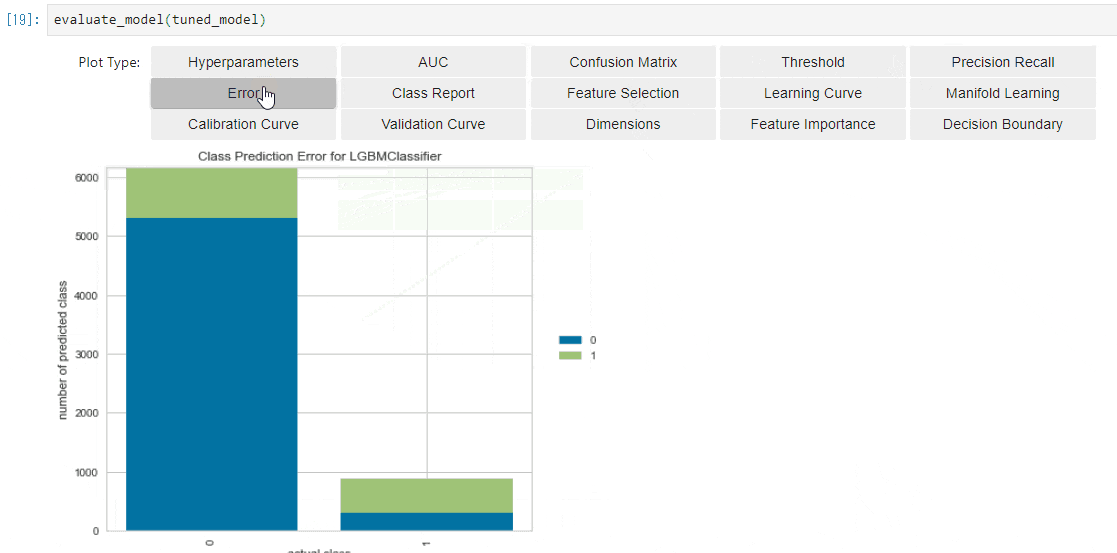
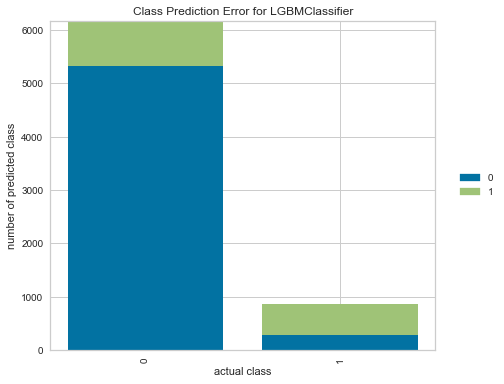
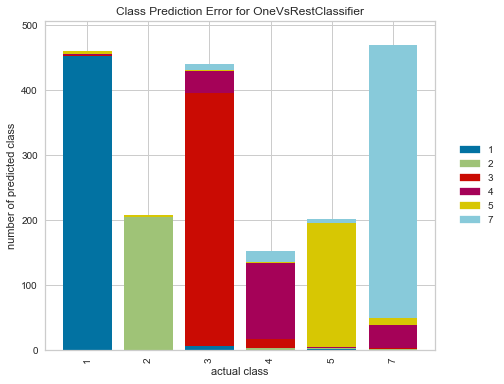
Error
-
実際のクラス毎に、Positive/Negativeのどちらに予測をしたか?が表示されます。
-
こちらも多値分類だと、より有用性を感じることができます。
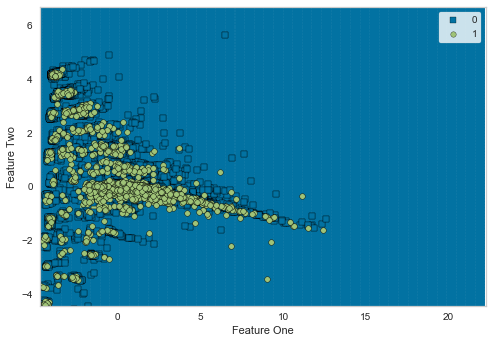
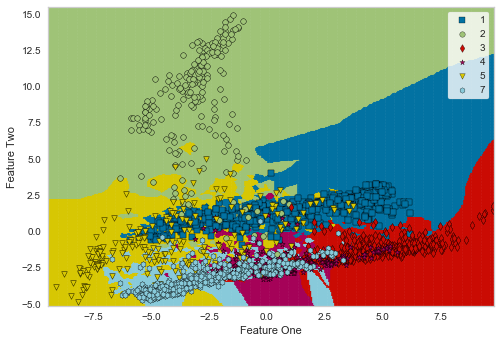
Dicision Boundary
-
決定境界です。Creditデータセット は、「デフォルトか、否か?」の不均衡データです。
-
よって、Positiveクラスが ごく少数 なので、境界が見えづらいですね。
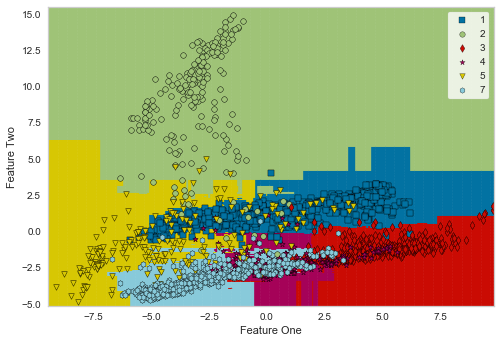
-
多値分類ですが、均衡性がある程度とれたデータセットでは、決定境界を確認できます。
-
以下は、lightGBMの決定境界なので、Treeベースアルゴリズムのギザギザ とした境界が確認できます。
-
なお、こちらはおまけですが、決定境界を比較することでアルゴリズムの特徴を理解可能です。
| # | Logistic Regression |
K Nearest Neighbour |
Gaussian Process |
|---|---|---|---|
| 境界 | 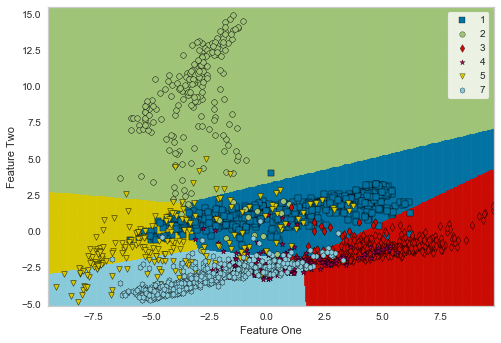 |
 |
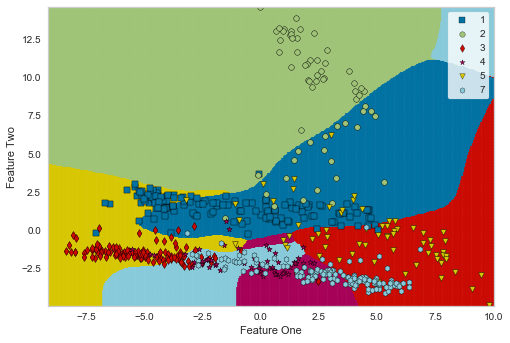 |
| 特徴 | 線形アルゴリズムの為 決定境界もまっすく |
近傍点をグルーピング するような境界 |
ベルカーブを意識させる 滑らかな曲面 |
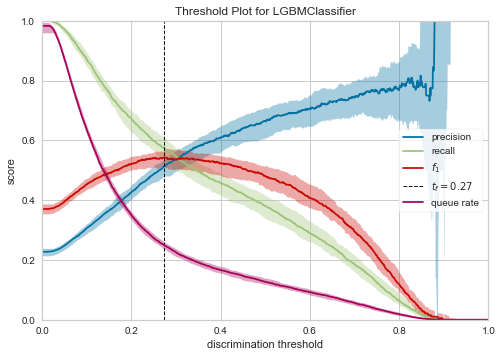
Threshold
- しきい値毎の、precision/recall/f-measureが出力されます。
- 求められる予測特性に対して、しきい値をどの程度に設定すればいいかの検討に利用できます。
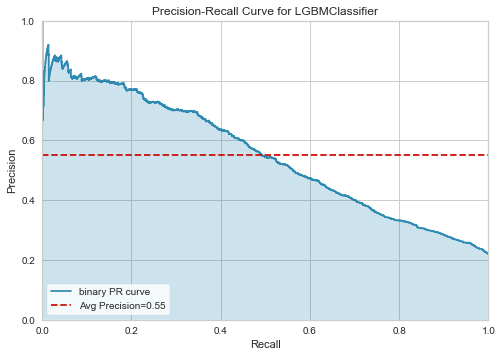
Precision Recall
- 同じく予測特性の議論に利用できるのが、Precision-Recallのグラフです。
- PrecisionとRecall共に、どの程度のしきい値であれば、予測特性を満たすか?の検討
に利用できます。
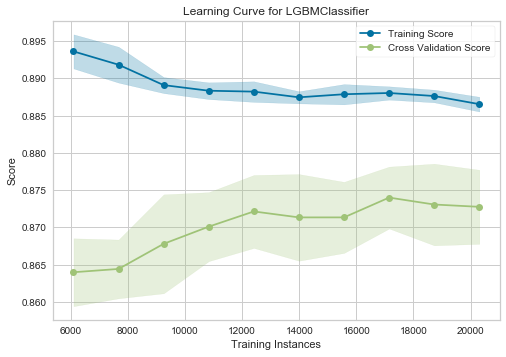
Learning Curve
- 学習曲線(学習の回数 vs 精度)が表示されます。
- TrainとCVセットに対してスコアが表示されるので、Underfittng/Overfittingの判断に利用できます。
- 学習曲線とunder/overfittingの判断については、StanfordのAndrewNg先生の資料が参考になります。
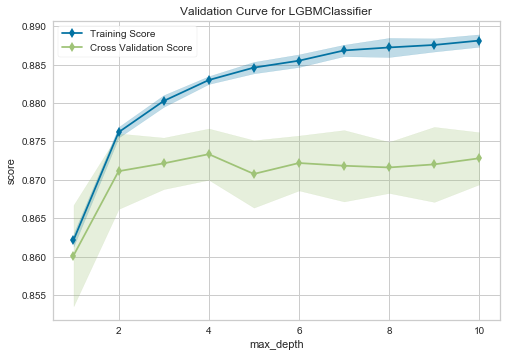
Validation Curve
-
モデル毎の正則化パラメータに対する、Trainセット/CVセットのスコアが表示されます。
-
LightGBMの場合は、max_depth(木の深さを制御する)パラメータを横軸に取ります。
-
このモデルの場合、
- max_depth=4のときに、汎化性能(CVスコア)が高い。
- それ以上のときは汎化性能は上昇しない一方、Trainセットに対して(若干)過学習している。
- よって、max_depthを制御したほうが良さそう。
-
といった判断に利用できます。
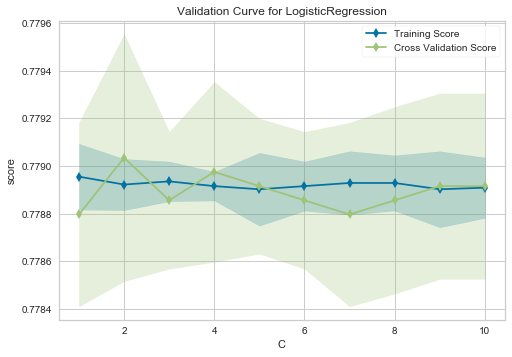
-
正則化を制御するパラメータはモデルにより異なるため、横軸はアルゴリズム毎に異なります。
-
例えばロジスティック回帰では、正則化のパラメータは C なので、横軸はCとなります。
-
各アルゴリズムで、横軸になるパラメータを下記にまとめておきます。
-
詳細は、ソースコードを参照。なお、LDAは未サポートです。
| アルゴリズム | 横軸 | アルゴリズム | 横軸 |
|---|---|---|---|
| Decision Tree Random Forest Gradient Boosting Extra Trees Classifier Extreme Gradient Boosting Light Gradient Boosting CatBoost Classifier |
max_depth | Logistic Regression SVM (Linear) SVM (RBF) |
C |
| Multi Level Perceptron (MLP) Ridge Classifier |
alpha | AdaBoost | n_estimators |
| K Nearest Neighbour(knn) | n_neighbors | Gaussian Process(GP) | max_iter_predict |
| Quadratic Disc. Analysis (QDA) | reg_param | Naives Bayes | var_smoothing |
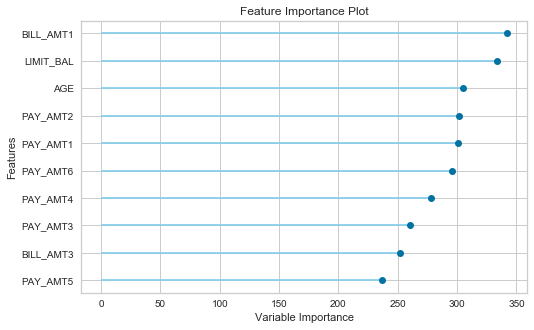
Feature Importance
- このモデルがどの特徴量を重要視しているか?が表示できます。
Manifold Learning
- t-SNEを利用した多様体学習(次元圧縮)の結果を表示します。
- モデルというよりは、用いている特徴量、データ自体に分解能があるのか?
- 2値分類の場合、Positive/Negativeに分離可能なのかが確認できます。
- 今回のデータでは、前処理で24列->90列まで特徴量を増やしている(後述)なので、90列を次元圧縮により2次元にし、その結果を可視化しています。
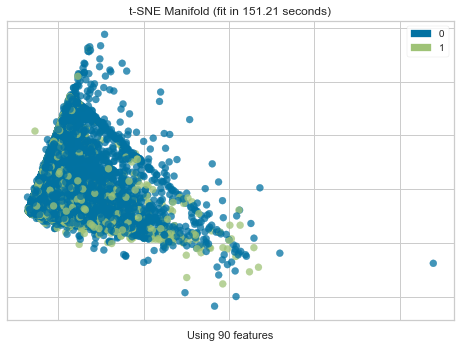
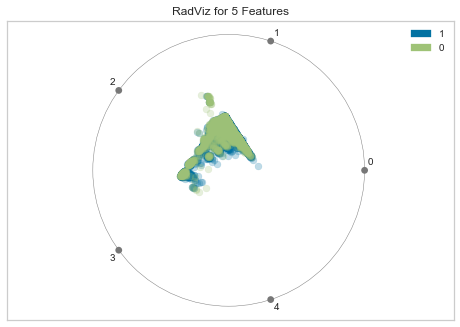
Dimensions
- こちらも、データ自体の可視化で、[RadViz Visualizer]
(https://www.scikit-yb.org/en/latest/api/features/radviz.html)の結果を表示します。
やってみる(①データロード~④チューニング)
①データロード
- pycaretには、様々なデータが搭載されています。詳細は、Getting Data - PyCaretを参照。
- 今回はクレジットカードのデフォルトを予測してみたいと思います。
from pycaret.datasets import get_data
# creditデータセットをロードします。
# profileオプションをTrue指定すると、pandas-profilingによるEDAが走ります。
data = get_data('credit',profile=False)
②前処理
- creditデータセットは、2値分類(予測対象は、 default列)です。
- よって、分類のライブラリをインポートし、targetにdefaultを指定します。
from pycaret.classification import *
exp1 = setup(data, target = 'default')
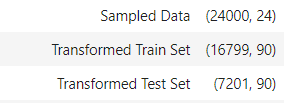
- 様々な前処理が自動で走ります。
- このデータセットの場合は、24列→90列まで特徴量が展開されます。
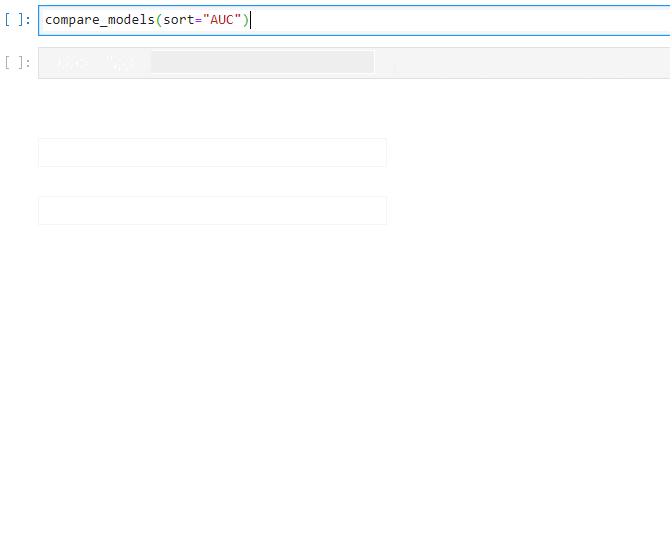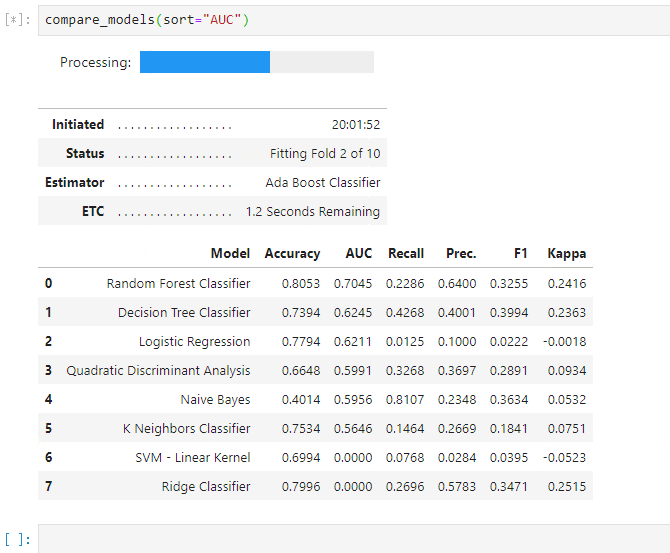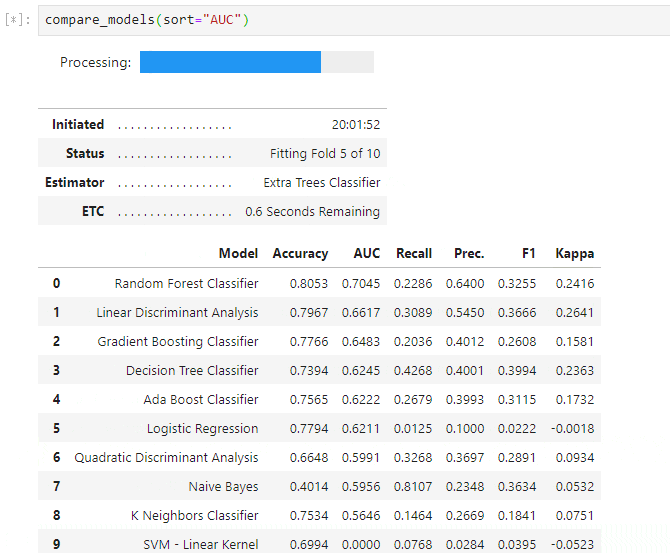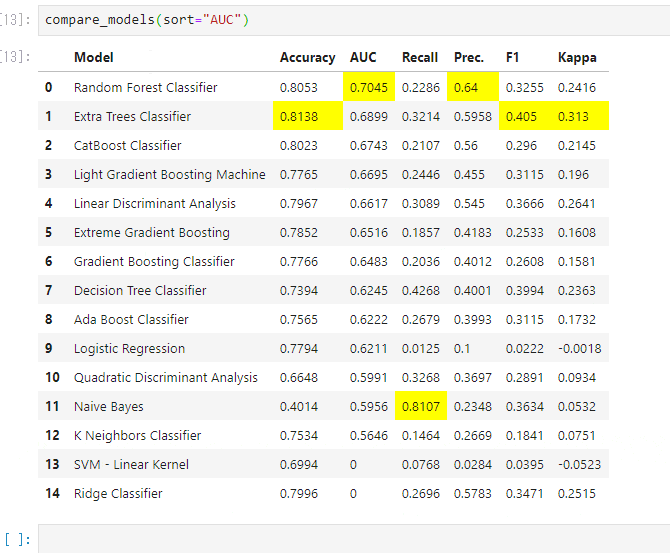
③モデル比較
- 下記で、複数の分類アルゴリズムに対するモデリングが可能です。
- 求める予測の特性にもよりますが、まずは、AUCで並べておきます。
compare_models(sort="AUC")
- GBM、XGB、CatBoost、LightGBM等が並びます
④パラメータチューニング
- AUCが一番良かったRandom Forestでも良いのですが、比較的計算の早いlightGBMで試してみます。
tuned_model = tune_model(estimator='lightgbm')
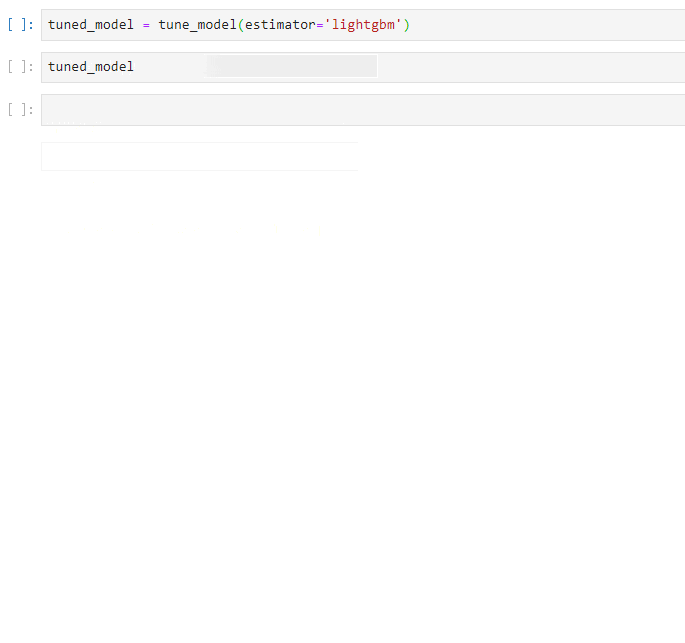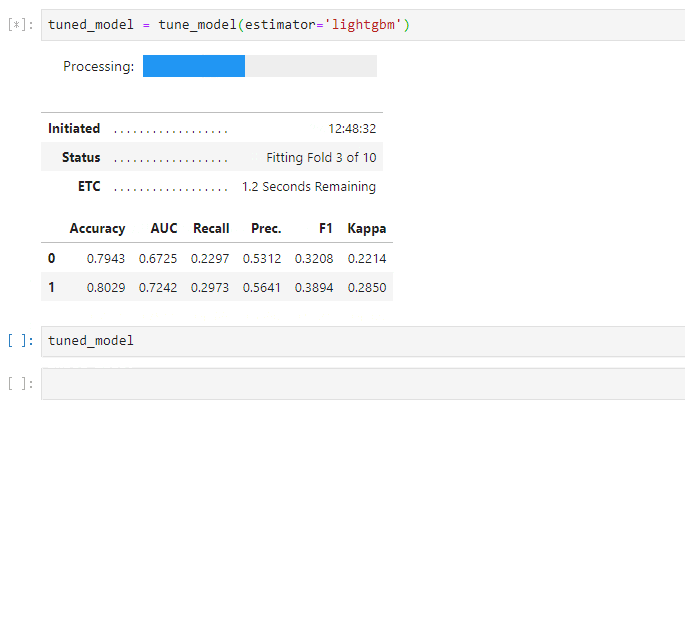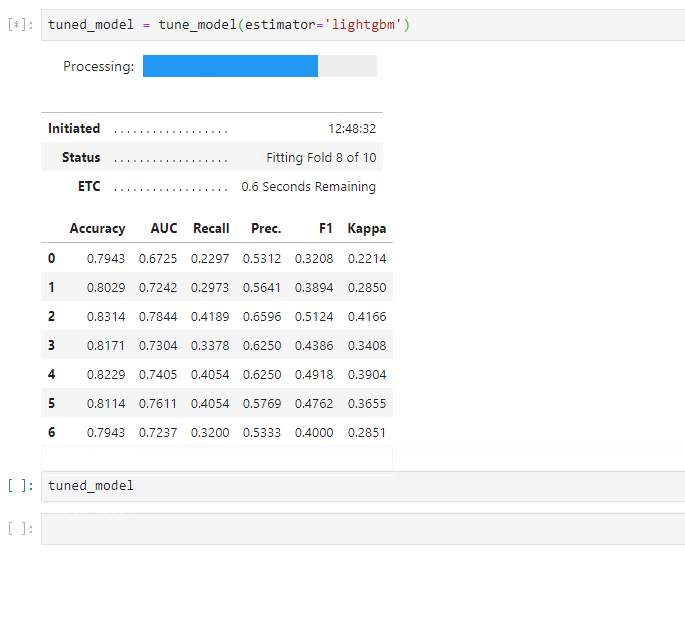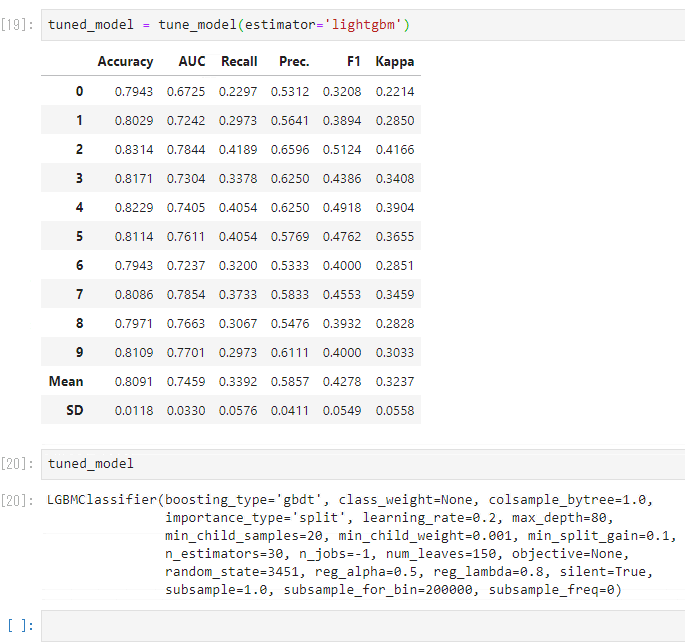
- 指定できるアルゴリズムは下記の通りです。docstringでも確認できます。
| アルゴリズム | estimatorの指定 | アルゴリズム | estimatorの指定 |
|---|---|---|---|
| Logistic Regression | 'lr' | Random Forest | 'rf' |
| K Nearest Neighbour | 'knn' | Quadratic Disc. Analysis | 'qda' |
| Naives Bayes | 'nb' | AdaBoost | 'ada' |
| Decision Tree | 'dt' | Gradient Boosting | 'gbc' |
| SVM (Linear) | 'svm' | Linear Disc. Analysis | 'lda' |
| SVM (RBF) | 'rbfsvm' | Extra Trees Classifier | 'et' |
| Gaussian Process | 'gpc' | Extreme Gradient Boosting | 'xgboost' |
| Multi Level Perceptron | 'mlp' | Light Gradient Boosting | 'lightgbm' |
| Ridge Classifier | 'ridge' | CatBoost Classifier | 'catboost' |
まとめ
- モデルの可視化の方法をバラバラと書いてしまったので、最後に用途毎に整理して終えたいと思います。
- 入力データ→モデリング→結果を想定し、下記5用途でグルーピングしてみたいと思います。
- A) 入力データや特徴量自体を理解する。
- B) モデルが見ている特徴量を理解する。
- C) モデルの学習状況(学習が足りない、過学習)を判断する。
- D) モデルの予測特性や、目的が達成できるしきい値を検討する。
- E) モデルの予測性能や予測結果を理解する。
| 用途 | 観点 | 可視化手段 |
|---|---|---|
| A)入力データや特徴量自体を理解する。 | 正/負のデータが分離可能か |
Manifold Learning
|
| 同上 |
Dimensions
|
|
| B)モデルが見ている特徴量を理解する。 | どの特徴量が重要か |
Feature Importance
|
| C)モデルの学習状況(学習が足りない、過学習)を判断する。 | 予測性能向上を学習回数増で実現できるか |
Learning Curve
|
| 正則化により過学習をおさえられているか |
Validation Curve
|
|
| D)モデルの予測特性や、目的が達成できるしきい値を検討する。 | 求める予測特性に対応するしきい値はどれか |
Threshold
|
| PrecisionとRecallの関係性はどうか |
Precision Recall
|
|
| E)モデルの予測性能や予測結果を理解する。 | AUC(予測性能)はどの程度か。 |
AUC
|
| 結果の境界線を理解する |
Decision Boundary
|
|
| 予測の間違い方を理解する |
Confusion Matrix
|
|
| 同上 |
Error
|
最後に
- 長文に、お付き合い頂きありがとうございました。
- よろしければ、いいね、シェア、してもらえると嬉しいです。
- ある程度、反響があったら、使いこなし編(パラメータ説明等)も書いてみようと思います。
関連記事