前提
- Shopify のデータは Bulk Operations で取得する物とします。詳しい方法は公式ドキュメントをご覧ください。
- BigQuery へのデータのエクスポートには google-cloud-bigquery gem を使用します。
実装
Gem
$ gem install google-cloud-bigquery
require "google/cloud/bigquery"
require "open-uri"
# Ref: https://googleapis.dev/ruby/google-cloud-bigquery/v1.37.0/file.AUTHENTICATION.html
Google::Cloud::Bigquery.configure do |config|
config.project_id = "プロジェクトIDを入力"
config.credentials = "サービスアカウント認証のjsonファイルへのパスを入力"
end
bigquery = Google::Cloud::Bigquery.new retries: 5, timeout: 600
dataset = bigquery.dataset "データセット名を入力"
table = dataset.create_table "テーブル名を入力"
bulk_operation_url = "Bulk Operation で得た URL を入力"
URI.open(bulk_operation_url) do |file|
load_job = table.load_job file do |config|
config.format = "json" # Bulk Operation の出力ファイルが jsonl 形式であるため。
config.autodetect = true # 当行を省略する場合は schema の事前指定が必須になります。
end
load_job.wait_until_done!
end
補足
- デフォルトだと60秒でタイムアウトするので、
execution expiredエラーが発生する場合は timeout の値を変更すると良さそうです。(上記実装例では600秒に設定。) -
load_job.failed?等を使用してエラー処理を書くことが出来ます。詳しくは Google::Cloud::Bigquery::Job の公式ドキュメントをご覧ください。 - load_job を使用するとエラー内容が分かりづらい場合があるので、うまく行かない場合は一旦 load を使ってみると失敗理由が分かる事があります。
-
dataset.create_tableの実行時に schema を事前指定 する事で、config.autodetect = trueを省略する事が出来ます。 - 環境にも依るかと思いますが、5GB程度の jsonl ファイルであれば数分で同期出来ました。
Schema の auto-detection
各カラムのデータ型を一つ一つ事前定義する必要があったら骨が折れるな〜と思っていたのですが、BigQuery が良い感じに schema を autodetect してくれました。
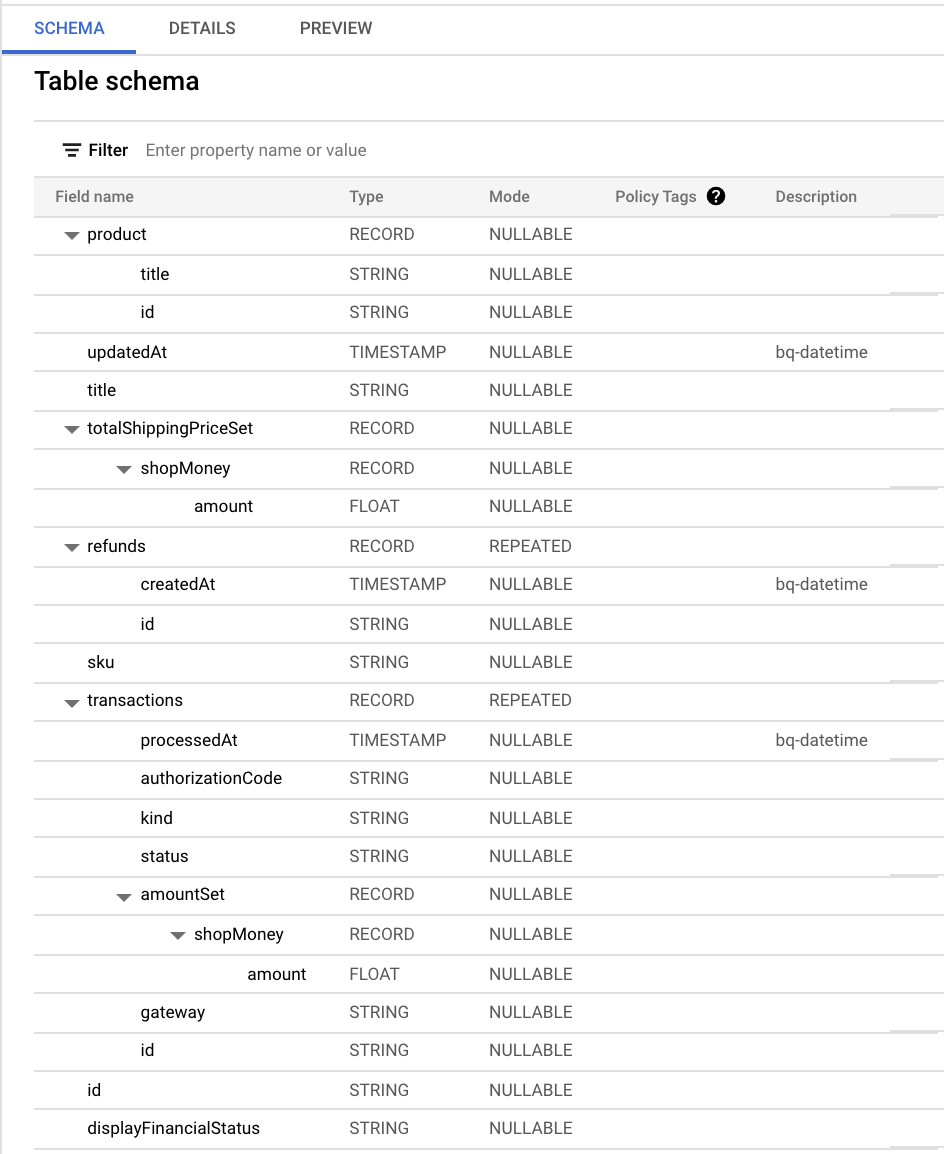
参照
- Perform bulk operations with the GraphQL Admin API | Shopify
- googleapis/google-cloud-ruby | GitHub
- Google Cloud BigQuery (OVERVIEW.md) | GitHub
- Batch loading data | Google Cloud
- Quotas and limits | Google Cloud
- Authentication | Google APIs
- Class: Google::Cloud::Bigquery::Table | Google APIs
- Class: Google::Cloud::Bigquery::Job | Google APIs