最近、グローバル分散データベースや分散SQLの話題をよく見かけるようになりました。
データレジデンシ、高可用性、低レイテンシ、マルチリージョン、マルチクラウド、AI活用など、キーワードだけ見てもかなり強そうな世界です。
そんな中で、Oracle にも Globally Distributed Autonomous AI Database、略して GDAI というソリューションがあります。
つまり、グローバルに分散できて、自律運用できて、AI機能も備えたデータベースです。
Oracle Globally Distributed Autonomous AI Database (GDAI) は、Oracle Cloud Infrastructure (OCI)が提供するフルマネージドサービスであり、単一のユーザーインターフェース内で、グローバルに分散された統合データベース間でデータのシャーディングを可能にします。大規模でミッションクリティカルなアプリケーションをサポートするように設計されており、高い可用性、耐障害性、拡張性を備えたデータベースサービスです。これにより、組織は膨大な量のデータを高いパフォーマンスと信頼性で保存および処理できます。

GDAI は、Oracle Autonomous Database の自律型テクノロジーを基盤として構築されており、自己管理、自己保護、自己修復、自己最適化の考え方を取り入れた分散データベース・サービスです。
これにより、パッチ適用、チューニング、バックアップとリカバリなど、データベース管理に伴う多くの定型業務を自動化できるため、人為的ミスのリスクを軽減し、システムの稼働時間を向上させることができます。
グローバル分散DB、アクティブなグローバルアプリケーション構成、マルチリージョン高可用性、運用自動化といったテーマは、クラウドネイティブなアプリケーション設計でますます重要になっています。
この記事では、以下の流れで GDAI を整理します。
- GDAI とは
- どのような課題を解決するのか
- 分散データベースとしての技術要素
- 分散 SQL / グローバル分散DBとして見るときの観点
- @Hyperscaler での利用イメージ
- 構築方法の大きな流れ
- AI Vector Search / Select AI / RAG / Agentic AI との組み合わせ
- 想定ユースケース
GDAI の特徴は、Oracle Database の機能、Autonomous Database の自動運用、Oracle AI Database の AI 機能、Exadata 基盤、Oracle Multicloud を組み合わせられる点です。
特に Oracle Database の既存資産を持つシステムでは、Oracle Database のスキル、データモデル、アプリケーション資産を活かしながら、グローバル分散、データレジデンシ、高可用性、AI活用を検討できることが大きなポイントになります。
ということで今回は、まだ実際に環境を作成して確認できてはいないのですが、公開情報をもとに GDAI の概要と技術要素を整理してみてみます。
■ GDAI とは
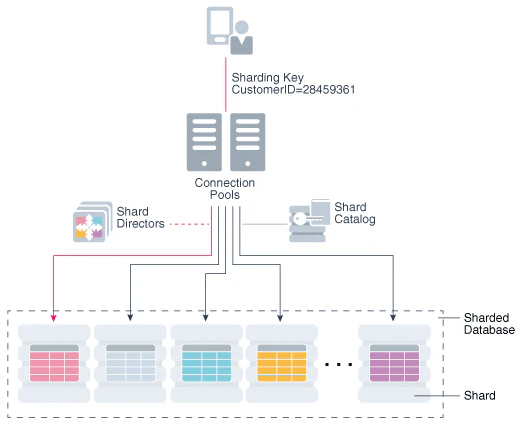
Oracle Globally Distributed Autonomous AI Database は、単一のユーザーインターフェースから、複数の database instance、つまり shard にまたがるデータセットをデプロイおよび管理できる、fully managed な OCI の分散データベース・サービスです。
アプリケーションからは 1 つの論理 Oracle AI Database として扱いながら、内部的には複数の Oracle AI Database shard にデータを分散配置します。これにより、データレジデンシ、高可用性、スケールアウト、グローバル低レイテンシといった要件に対応しやすくなります。

GDAI は single logical Oracle AI Database です。内部的には、複数の Oracle AI Database shards に分散され、それぞれの shard は論理データベースの一部のデータを保持する独立した Oracle AI Database インスタンスです。1

GDAI は次のようなソリューションです。
- アプリケーションからは 1 つの論理 Oracle AI Database として利用する
- 内部的には複数の shard にデータを分散配置する
- shard を複数の Availability Domain、リージョン、地理的ロケーションに配置できる
- Shard Catalog により、分散データベース全体の構成管理や multi-shard query を支える
- Shard Director により、アプリケーション接続を適切な shard へルーティングする
- Data Guard や Raft ベースのレプリケーションにより高可用性を実現する
- Autonomous Database の自動化により、運用負荷を下げる
- Select AI や AI Vector Search など、Oracle AI Database の機能と組み合わせられる
Application
|
| Single logical Oracle AI Database
v
Globally Distributed Autonomous AI Database
|
+-- Shard 1 : Oracle AI Database
+-- Shard 2 : Oracle AI Database
+-- Shard 3 : Oracle AI Database
|
+-- Shard Catalog
+-- Shard Director
GDAI のポイントは、単に複数のデータベースを並べることではありません。
データ分散、接続ルーティング、複製、高可用性、管理の自動化を組み合わせ、グローバル分散 DB を単一の論理データベースとして扱う ところにあります。
■ GDAI が解決する課題
GDAI が狙う主な課題は、次のようなものがあります。
データレジデンシ / データ主権

グローバルにサービスを展開すると、国や地域ごとにデータ保管・処理場所の制約が発生します。
例えば、以下のような要件です。
- 日本の利用者データは日本国内に置きたい
- EU のデータは EU 内で保管・処理したい
- 金融・公共・医療など、規制要件の強いデータを地域ごとに管理したい
- グローバル分析は行いたいが、データの所在は制御したい
Oracle 公式ページでは、GDAI のユースケースとして、分散データウェアハウスやデータレイクにおけるデータレジデンシ要件への対応が挙げられています。データ分散ポリシーと組み込みの自動化を組み合わせることで、データセットの保存と処理を必要な地理的ロケーションに保ちながら、集中管理を提供するという考え方です。1
グローバル低レイテンシ
グローバルアプリケーションでは、すべてのアクセスを単一リージョンに集約すると、遠隔地ユーザーのレイテンシが大きくなります。
GDAI では、データを複数地域に分散配置できます。利用者に近い場所にデータを置き、アプリケーションから適切な shard に接続できれば、ローカルアクセスに近い体験を提供しやすくなります。
User in Japan -> Japan / APAC side shard
User in US -> US side shard
User in EU -> EU side shard
高可用性と耐障害性

ミッションクリティカルなアプリケーションでは、リージョン障害、データセンター障害、ノード障害などを想定した設計が必要です。
shard を OCI Availability Domain やリージョンに分散することで高可用性を提供できます。
また、各 shard は高可用性のために Data Guard で複製します。1
さらに、GDAI は Raft consensus protocol による組み込みレプリケーション、および Oracle Data Guard のようなレプリケーション技術を利用できることが説明されています。2
スケールアウト
GDAI は shard による水平分散構成です。
データ量やトランザクション量が増えた場合に shard を追加し、分散データベース全体として処理能力を拡張する考え方になります。
ライフサイクル管理として Add Shards (Scale Out)、Remove Shards (Scale In)、Monitor the Deployment などの項目が用意されています。3
単一論理 DB としての管理性
分散データベースの難しさは、分散した DB 群をアプリケーションや運用者がどう扱うかです。
GDAI では、Shard Catalog が自動 shard deployment、集中管理、multi-shard query を支えます。Shard Director は、分散データベースへの高性能な接続ルーティングを提供します。
アプリケーションのリクエストは Oracle drivers と sharding key を利用して、対象 shard に直接ルーティングされます。1
この構成により、アプリケーションは分散配置されたデータを、単一の論理 DB として扱いやすくなります。
■ 分散データベースとしての技術要素
ここからは、GDAI を理解するうえで重要な技術要素を整理します。
Shard
Shard は、論理データベース全体のデータの一部を保持する独立した Oracle AI Database インスタンスです。
GDAI では、単一の論理データベースを複数の shard に分割します。各 shard は物理的に独立しており、同一リージョン、複数 Availability Domain、複数リージョン、複数地理ロケーションに配置できます。
Logical Database
|
+-- Shard A : Customer range A
+-- Shard B : Customer range B
+-- Shard C : Customer range C

設計時には、どの単位でデータを分散するかが重要です。
- 顧客 ID
- 国 / 地域
- テナント ID
- 事業部
- アプリケーション領域
- データ主権要件
グローバル SaaS であれば、テナント単位やリージョン単位での分散が候補になります。金融・公共・医療などでは、国や規制単位でのデータ配置が重要になる場合があります。
Shard Catalog
Shard Catalog は、分散データベース全体の管理を支えるコンポーネントです。
Shard Catalog は以下サポートします。1
- automated shard deployment
- centralized management
- multi-shard queries
- automated query coordinator
つまり、Shard Catalog は、分散データベースの管理プレーンとして重要です。
アプリケーションから見ると 1 つの論理 DB でも、内部では複数 shard に分散されています。その配置や状態を把握し、管理し、必要に応じて複数 shard にまたがる問い合わせを支えるのが Shard Catalog の役割です。
Shard Director
Shard Director は、アプリケーション接続を適切な shard にルーティングするコンポーネントです。
Shard Director は分散データベースのデータにアクセスするための高性能な接続ルーティングを提供します。さらに、アプリケーションリクエストは Oracle drivers と sharding key を使って shard に直接ルーティングされます。1
Application
|
| sharding key = customer_id
v
Shard Director
|
+-- customer_id in Japan -> Shard Japan
+-- customer_id in US -> Shard US
+-- customer_id in EU -> Shard EU
ここが、GDAI のアプリケーション設計で重要なポイントです。
アプリケーションが sharding key を適切に扱えると、リクエストは対象 shard に直接向かいやすくなります。これにより、分散 DB で懸念される不要なクロス shard アクセスを減らし、性能とスケーラビリティを高めやすくなります。
Raft ベース・レプリケーション

分散 DB では、データを分散するだけでは不十分です。
障害時にもデータを失わず、整合性を保ち、サービスを継続できる必要があります。
Oracle Database Insider の GDAI 記事では、GDAI の高可用性・スケーラビリティの文脈で、Raft consensus protocol による組み込みレプリケーションと Oracle Data Guard が説明されています。Raft は、分散システムで合意形成を行うための代表的なアルゴリズムです。2
GDAI における Raft ベース・レプリケーションは、以下のような観点で重要です。
- レプリカ間で整合性を保つ
- 障害時の切り替えを高速化する
- データ損失を防ぐ設計を支える
- アクティブなグローバル分散構成や高可用性構成を支える重要な技術要素になる
分散 DB では、性能だけでなく、整合性と可用性のバランスが重要です。Raft ベース・レプリケーションは、その中核にある技術要素の 1 つです。
グローバル分散アプリケーション構成

GDAI では、複数ロケーションに shard を分散配置し、Shard Director と Oracle drivers / sharding key により、アプリケーションから適切な shard へ接続をルーティングできます。
このため、グローバルに分散したユーザーやアプリケーションから、データの配置場所に近い shard へアクセスする設計を検討できます。
グローバル分散DBでは、複数ロケーションでアプリケーションを稼働させる Active-Active 型のアプリケーション構成を検討することがあります。その場合、GDAI の shard 配置、Shard Director による接続ルーティング、レプリケーション、フェイルオーバー / フェイルバック設計を組み合わせて考える必要があります。
Region A / Cloud A
Application A
Shard / Replica A
Region B / Cloud B
Application B
Shard / Replica B
Region C / Cloud C
Application C
Shard / Replica C
アクティブ-アクティブ構成では、以下を設計する必要があります。
- どのユーザーをどのロケーションにルーティングするか
- どのデータをどこに配置するか
- 書き込みがどの shard に向かうか
- 障害時にどこへ切り替えるか
- 復旧後にどうフェイルバックするか
- アプリケーションのリトライや接続プールをどう設定するか
GDAI は分散 DB の基盤を提供しますが、アプリケーション設計も重要です。
アプリケーション・ダイレクト・ルーティング

client application request は Oracle drivers と sharding key を使って shard に直接ルーティングされます。1
これをアプリケーション設計の観点で見ると、以下が重要になります。
- sharding key を明確に設計する
- SQL や API が sharding key を含む形にする
- 接続プールが shard-aware な接続を扱えるようにする
- 単一 shard で完結する処理を増やす
- cross-shard query が必要な処理を明確に分離する
分散 DB では、データの場所を意識せずに何でも実行できるように見えても、性能面では「どのデータがどこにあるか」が重要です。
GDAI では、Shard Director と Oracle drivers によるルーティングがこの部分を支えます。
アプリケーション・フェイルオーバー / フェイルバック

グローバル分散 DB では、DB 側の高可用性だけでなく、アプリケーション側のフェイルオーバー設計も重要です。
考えるべきことは以下です。
- 接続先が利用不可になったときに、どの接続先へ切り替えるか
- 接続プールが障害をどう検知するか
- トランザクション途中の失敗をどう扱うか
- リトライ可能な処理と、リトライしてはいけない処理をどう分けるか
- 復旧後に元のロケーションへ戻すか、戻さないか
- フェイルバック時にアプリケーション停止を伴うか
GDAI の技術要素である Shard Director、Data Guard、Raft ベース・レプリケーションは高可用性の基盤になります。アプリケーション側では、接続ルーティング、リトライ設計、例外処理、運用手順を合わせて設計する必要があります。
■ 分散 SQL / グローバル分散 DB として見るポイント
GDAI を分散 SQL / グローバル分散 DB として見る場合、重要なのは「単一論理 DB として見えること」と「実際のデータ配置を意識した設計」のバランスです。
sharding key を含む処理は対象 shard に直接ルーティングしやすく、性能を出しやすい一方、cross-shard query やグローバル集計は Shard Catalog / query coordinator の役割を理解したうえで設計する必要があります。
■ Oracle Multicloud / @Hyperscaler での利用を考える
GDAI を考えるうえで、Oracle Multicloud / @Hyperscaler との関係も重要です。

Oracle は、主要クラウド上で Oracle AI Database を利用するためのサービスとして、Oracle AI Database@Azure、Oracle AI Database@Google Cloud、Oracle AI Database@AWS を提供しています。
Oracle AI Database@Azure では、Azure data centers に colocated された Exadata infrastructure 上で Oracle workloads を実行でき、RAC、Oracle Data Guard、Maximum Availability Architecture によるエンタープライズ可用性が説明されています。
Oracle AI Database@Google Cloud では、OCI の Oracle AI Database services が Google Cloud で稼働し、Google Vertex AI などの Google Cloud サービスと Oracle AI Database を組み合わせたアプリケーション開発が説明されています。
Oracle AI Database@AWS では、Oracle Exadata Database Service on Dedicated Infrastructure や Oracle Autonomous AI Database on Dedicated Exadata Infrastructure を AWS 内で利用でき、Amazon SageMaker や Amazon Bedrock などとの組み合わせが説明されています。
このように、Oracle AI Database の利用場所は OCI だけに閉じません。
GDAI を検討する際も、Oracle AI Database のマルチクラウド展開と、データ配置、ネットワーク、レイテンシ、データレジデンシ、セキュリティをどう組み合わせるかが重要な検討ポイントになります。
ただし、実際に GDAI をどのクラウド、どのリージョン、どのサービス形態で利用できるかは、対象リージョン、サービス提供状態、Dedicated Infrastructure / Exadata Infrastructure の前提、ネットワーク、IAM、課金モデルを確認する必要があります。
OCI
+-- Oracle AI Database / Autonomous AI Database
+-- Exadata Infrastructure
Azure
+-- Oracle AI Database@Azure
+-- Exadata infrastructure colocated in Azure data centers
Google Cloud
+-- Oracle AI Database@Google Cloud
+-- OCI Oracle AI Database services running in Google Cloud
AWS
+-- Oracle AI Database@AWS
+-- Oracle AI Database services running on OCI in AWS
ここで重要なのは、単に「別クラウドに Oracle Database を置く」という話ではないことです。
Oracle AI Database@Azure / @Google Cloud / @AWS は、それぞれのクラウド環境のアプリケーションや AI サービスの近くで、Oracle AI Database を利用するための選択肢です。
そのため、以下のような構成を検討できます。
- Azure 上のアプリケーションから Oracle AI Database@Azure に低レイテンシ接続する
- Google Cloud の Vertex AI と Oracle AI Database@Google Cloud を組み合わせる
- AWS の Bedrock / SageMaker と Oracle AI Database@AWS を組み合わせる
- Oracle Database のデータを移動せずに、各クラウドの AI サービスと組み合わせる
- データレジデンシ要件に合わせて、利用リージョンや配置先を選ぶ
GDAI と @Hyperscaler を組み合わせる場合は、対象リージョン、サービス提供状態、Autonomous AI Database on Dedicated Exadata Infrastructure などサービスごとの Exadata 基盤、ネットワーク、セキュリティ、IAM、課金モデルを必ず確認する必要があります。
構成イメージ
GDAI の基本構成は、次のように考えられます。
+----------------------+
| Application |
+----------+-----------+
|
| Oracle drivers + sharding key
v
+----------------------+
| Shard Director |
+----------+-----------+
|
+-----------------+-----------------+
| | |
v v v
+----------------+ +----------------+ +----------------+
| Shard Japan | | Shard US | | Shard EU |
| Oracle AI DB | | Oracle AI DB | | Oracle AI DB |
+----------------+ +----------------+ +----------------+
\ | /
\ | /
v v v
+----------------------+
| Shard Catalog |
+----------------------+
各 shard は独立した Oracle AI Database インスタンスです。Shard Catalog が分散 DB 全体の管理や multi-shard query を支え、Shard Director がアプリケーション接続を適切な shard にルーティングします。
高可用性の観点では、shard は Data Guard などで複製されます。Raft ベース・レプリケーションも、分散 DB の高可用性と整合性を支える重要な要素です。
@Hyperscaler を含める場合のイメージは以下です。
Application on Azure
|
+-- Oracle AI Database@Azure
Application on AWS
|
+-- Oracle AI Database@AWS
Application on Google Cloud
|
+-- Oracle AI Database@Google Cloud
Application on OCI
|
+-- Oracle AI Database on OCI
Across locations
|
+-- Globally Distributed Autonomous AI Database design
+-- Shards / Replicas / Catalog / Directors
この構成では、アプリケーションが動作するクラウドの近くに Oracle AI Database を配置し、データ配置とレプリケーションを設計することで、低レイテンシ、高可用性、データ主権の要件を満たしやすくなります。
■ 構築方法のイメージ
ここでは、実際の画面操作ではなく、Oracle Docs の構成に沿って GDAI を作成する際の大きな流れを整理します。

Oracle Docs の Get Started ページには、以下の項目が用意されています。3
- Learn About the Service
- Set Up the Prerequisites
- Access the User Interface
- Define Policies
- Creation and Deployment Work Flow
- Add Shards (Scale Out)
- Remove Shards (Scale In)
- Stop and Start the Distributed Database
- Monitor the Deployment
- Manage Private Endpoints
これをベースにすると、構築の流れは以下のようになります。
1. サービス概要と提供条件を確認する
最初に、GDAI が対象リージョン、対象クラウド、対象テナンシで利用できるかを確認します。
確認ポイントは以下です。
- GDAI の提供リージョン
- 利用可能な Autonomous AI Database / Dedicated Infrastructure
- Exadata VM Cluster または Dedicated Infrastructure の前提
- @Hyperscaler 上で利用する場合の提供状態
- テナンシで有効化されているサービス
- 必要な IAM 権限
2. 前提条件を準備する
次に、ネットワーク、権限、基盤を準備します。
確認ポイントは以下です。
- VCN / subnet / routing
- private endpoint
- security list / network security group
- DNS
- IAM policy
- compartment
- vault / key management
- backup / recovery policy
- Exadata VM Cluster / Dedicated Infrastructure
GDAI は分散 DB なので、ネットワーク設計が非常に重要です。
同一リージョン内の DB 作成よりも、以下のような観点が増えます。
- shard 間の通信
- アプリケーションから Shard Director への接続
- 管理プレーンへのアクセス
- private endpoint の利用
- @Hyperscaler と OCI の境界
- 監視とログ取得
3. ポリシーを定義する
Oracle Docs では、Define Policies が Get Started の重要ステップとして用意されています。3
GDAI では、データベース作成だけでなく、分散構成の管理、shard の追加・削除、監視などが必要になります。
そのため、最小権限の原則に基づいて、以下を整理します。
- 誰が GDAI を作成できるか
- 誰が shard を追加・削除できるか
- 誰がネットワーク設定を変更できるか
- 誰が監視できるか
- 誰がバックアップ・リカバリ操作をできるか
- 誰がセキュリティ設定を変更できるか
4. GDAI の作成ワークフローを実行する
Oracle Docs には Creation and Deployment Work Flow が用意されています。3
実際の画面操作は環境により異なるため、ここでは大きな確認項目として整理します。
- distributed database name
- compartment
- database version
- workload type
- shard configuration
- shard placement
- replication configuration
- network configuration
- backup configuration
- admin credentials
- tags
GDAI は単一 DB 作成とは異なり、データをどのように分散するかが重要です。
そのため、作成前に以下を決めておく必要があります。
- sharding key
- shard 数
- shard の配置場所
- replica の配置場所
- data residency policy
- cross-shard query の必要性
- アプリケーション接続方式
5. アプリケーション接続を設計する
GDAI のアプリケーション接続では、Shard Director と sharding key が重要です。
確認ポイントは以下です。
- 接続文字列
- Oracle driver
- sharding key の渡し方
- 接続プール
- service name
- retry policy
- timeout
- failover / failback
- read / write の設計
- cross-shard query の扱い
とくに sharding key は、アプリケーションのデータモデルに深く関係します。
グローバル SaaS であれば tenant_id、グローバル EC であれば customer_id や region、金融であれば account_id や country などが候補になります。
6. スケールアウト / スケールインを確認する
Oracle Docs のライフサイクル管理には、Add Shards (Scale Out) と Remove Shards (Scale In) が含まれています。3
GDAI の検証では、最初に小さな構成を作成し、その後 shard の追加・削除を確認するのがよさそうです。
確認ポイントは以下です。
- shard 追加時のデータ再配置
- shard 追加時のアプリケーション影響
- shard 削除時の制約
- 監視メトリックの変化
- スケールアウト後の接続ルーティング
- コストの変化
7. 監視と運用を確認する
GDAI は分散 DB なので、監視観点も複数あります。
- distributed database 全体の状態
- shard 単位の状態
- replication 状態
- Shard Catalog の状態
- Shard Director の状態
- アプリケーション接続
- レイテンシ
- エラー率
- スループット
- backup / recovery 状態
- 監査ログ
Oracle Docs には Monitor the Deployment が含まれているため、GDAI の検証では、作成直後から監視項目を確認するのが重要です。3
■ 構築時に確認したいポイント
実際に GDAI を構築できる環境がある場合、以下を確認したいです。
サービス提供条件
- 利用可能リージョン
- 対応する Oracle AI Database / Autonomous AI Database の種類
- @Hyperscaler での対応状況
- Exadata VM Cluster / Dedicated Infrastructure の前提
- テナンシでのサービス有効化状況
データ分散設計
- sharding key
- shard 数
- データ配置ポリシー
- data residency 要件
- cross-shard query の必要性
- global query の実行パターン
高可用性設計
- Data Guard 構成
- Raft ベース・レプリケーション
- replica 配置
- 障害時の切り替え
- RTO / RPO
- failover / failback 手順
アプリケーション設計
- Oracle driver
- sharding key の指定
- connection pool
- retry policy
- timeout
- idempotency
- transaction boundary
- read / write routing
ネットワーク設計
- private endpoint
- VCN / subnet
- NSG / security list
- DNS
- OCI と @Hyperscaler 間の接続
- 監視・ログ取得経路
運用設計
- 監視メトリック
- アラート
- 監査ログ
- バックアップ
- パッチ適用
- スケールアウト / スケールイン
- コスト管理
■ AI 機能との組み合わせ
GDAI 上で AI Vector Search や Select AI を利用する場合、vector index、multi-shard query、データ配置、レイテンシ、検索対象 shard の範囲などは実機検証で確認したいポイントです。

GDAI は分散 DB ですが、名前の通り Autonomous AI Database の文脈で考えることが重要です。
つまり、GDAI は単にデータを分散配置するだけでなく、Oracle AI Database の AI 機能と組み合わせることで、グローバル AI アプリケーションの基盤になり得ます。
AI Vector Search

Oracle AI Vector Search は、Oracle AI Database 内でベクトル検索を実行する機能です。
AI Vector Search は、構造化データと非構造化データの両方を、意味や値に基づいて検索できます。また、LLM が RAG により、企業データを使ってより正確で文脈に合った結果を返すことを支援できます。4
Oracle AI Vector Search の特徴は、ベクトル専用 DB を別に用意するのではなく、Oracle AI Database の中で、リレーショナル、テキスト、JSON、Spatial、Graph などのデータと一緒に扱える点です。
GDAI と組み合わせると、以下のような構成が考えられます。
Global RAG Application
|
+-- Japan users -> APAC shard with local business data + vectors
+-- US users -> US shard with local business data + vectors
+-- EU users -> EU shard with local business data + vectors
これにより、ユーザーに近い場所で検索しながら、必要に応じてグローバルな分析や管理も行う構成を検討できます。
Select AI

Oracle Autonomous AI Database Select AI は、自然言語でデータを分析するための機能です。
Select AI は、自然言語による SQL query generation、RAG、AI agents、SQL / PL/SQL / Python インターフェース、さまざまな LLM / embedding model provider の選択などがあります。5
GDAI の公式ページでも、Select AI を使うことで、データがどこにあり、どのように構造化されているかを知らなくても、自然言語で分散データに問い合わせられるというユースケースが挙げられています。1
つまり、GDAI と Select AI を組み合わせると、以下のような世界観になります。
- データは複数の地域・shard に分散配置される
- 管理者や分析者は単一の論理 DB として扱える
- Select AI により自然言語で問い合わせできる
- RAG や AI agent により、業務データを活用した AI アプリケーションを構築できる
RAG / Agentic AI
GDAI は、グローバルに分散した業務データを AI アプリケーションに活用する基盤として有効です。
例えば、以下のようなユースケースが考えられます。
- 国ごとに保管場所を制御した顧客データを使った RAG
- 地域別の規制文書や契約書を対象にした文書検索
- グローバル SaaS の問い合わせ対応チャットボット
- 金融取引データを地域ごとに保持しながら、不正検知や類似検索を行う
- IoT データを地域ごとに保存しながら、グローバル分析を行う
- エージェントが地域ごとのデータを検索し、業務プロセスを自動化する
RAG は similarity search の結果を使い、LLM の回答精度や文脈関連性を高める手法です。4
■ 想定ユースケース
GDAI のユースケースは、Oracle 公式ページでもいくつか挙げられています。代表的なものを、実務観点で整理します。

データレジデンシが必要な分散データウェアハウス / データレイク
国や地域ごとのデータ保管要件を満たしながら、グローバルにデータを分析したいケースです。
例:
- 国ごとに販売データを保持するグローバル企業
- EU 内に個人データを保持する必要があるサービス
- 地域ごとの規制に対応する金融・公共・医療データ
クラウドスケールのトランザクション処理
大量ユーザー、大量トランザクションを処理するアプリケーションです。
例:
- グローバル EC
- 決済基盤
- モバイルアプリ
- サブスクリプションサービス
- グローバル SaaS
データをユーザーに近い場所に配置しながら、単一論理 DB として管理できる点が重要です。
ミッションクリティカル・アプリケーションの最大可用性
停止が許されないシステムでは、リージョン障害やデータセンター障害を前提にした設計が必要です。
例:
- 金融取引
- 決済
- 交通
- 通信
- 製造
- エネルギー
- 公共サービス
GDAI では、分散アーキテクチャ、Data Guard、Raft ベース・レプリケーション、Shard Director などを組み合わせて高可用性を設計できます。
分散データパイプラインと分析
大量データを分散配置し、地域ごとの処理とグローバル分析を両立するケースです。
例:
- IoT データ収集
- 製造設備ログ
- エネルギー管理
- クリックストリーム分析
- グローバル KPI 分析
Oracle 公式ページでは、分散クラウド内で巨大データセットをロード、処理、分析しつつ、データレジデンシ要件に対応するユースケースが紹介されています。1
自然言語によるグローバル分散データ分析
Select AI と組み合わせることで、分散データに対して自然言語で問い合わせるユースケースが考えられます。
例:
「日本、米国、欧州の今月の売上を地域別に比較して」
「過去 30 日間で障害率が高いリージョンを教えて」
「EU 顧客の問い合わせで多いトピックを要約して」
データがどこにあるかを意識せずに問い合わせできることは、分散データの活用において大きな価値になります。
グローバル AI アプリケーション
AI Vector Search、Select AI、RAG、AI agents と組み合わせることで、GDAI はグローバル AI アプリケーションの基盤になり得ます。
例:
- グローバル社内ナレッジ検索
- 多地域対応 RAG アプリケーション
- 顧客サポート AI agent
- 地域別コンプライアンス文書検索
- 分散配置された製品情報に対するセマンティック検索
- データレジデンシを満たす生成 AI アプリケーション
■ GDAI を検証するときのチェックリスト
実際に GDAI 環境を作成できるようになったら、以下を確認したいです。
作成前
- GDAI が対象リージョンで利用可能か
- @Hyperscaler で利用する場合、対象クラウドとリージョンで前提サービスが利用可能か
- Exadata VM Cluster / Dedicated Infrastructure が作成済みか
- 必要な IAM policy が設定されているか
- VCN / subnet / private endpoint が設計済みか
- sharding key が決まっているか
- データレジデンシ要件が整理されているか
- RTO / RPO が定義されているか
作成時
- distributed database 名
- compartment
- database version
- shard 数
- shard の配置
- replica の配置
- network configuration
- admin credentials
- backup policy
- tags
作成後
- Shard Catalog の状態
- Shard Director の状態
- shard の状態
- replication 状態
- アプリケーション接続
- sharding key による direct routing
- cross-shard query
- scale out / scale in
- failover / failback
- monitoring
- cost
■ 今回確認できていないこと
本記事では、実際の GDAI 環境作成は行っていません。
そのため、以下は未確認です。
- OCI Console での具体的な画面遷移
- 各入力パラメータの実名
- 作成にかかる時間
- 作成後の接続文字列
- Wallet / credential の取得方法
- shard 追加時の実際の挙動
- replication lag の実測
- failover / failback の実測
- アプリケーションからの direct routing の実測
- @Hyperscaler を含む構成での実作成可否
- 実際の課金
実際に触れる環境が用意できたら、次回は作成画面、構成パラメータ、接続、フェイルオーバー、AI Vector Search との組み合わせを検証したいです。
まとめ
GDAI は、Oracle AI Database をグローバルに分散配置し、単一の論理データベースとして利用するための分散データベース・サービスです。
Oracle 公式情報をもとに整理すると、GDAI は以下のような要件に対応するためのソリューションだと考えられます。
データレジデンシ / データ主権への対応
グローバルユーザー向けの低レイテンシ化
ミッションクリティカル・アプリケーションの高可用性
shard によるスケールアウト
Shard Catalog による集中管理と multi-shard query
Shard Director による接続ルーティング
Data Guard / Raft ベース・レプリケーションによる耐障害性
Autonomous Database による運用自動化
Select AI / AI Vector Search / RAG / Agentic AI との組み合わせ
特に、Oracle Database の既存資産やスキルを活かしながら、データ主権、グローバル分散、高可用性、AI 活用を同時に検討できる点は大きな特徴です。
今後、グローバル SaaS、金融・決済、公共、IoT、RAG / Agentic AI アプリケーションでは、「データをどこに置くか」「どこで処理するか」「どこから安全に利用するか」がより重要になります。
GDAI は、そのようなグローバル分散時代における Oracle AI Database 基盤として、かなり注目すべき技術です。
■ おまけ

■ 参考情報
Oracle Globally Distributed Autonomous AI Database / GDAI
- Oracle Globally Distributed Autonomous AI Database
- Oracle Globally Distributed Autonomous AI Database FAQ
- Globally Distributed Autonomous AI Database - Oracle Docs
- Achieve data residency, availability, and scale with Oracle Globally Distributed Autonomous Database - Oracle Database Insider Blog
- Analyst Report: Meeting the new reality for data sovereignty by dbInsight
Oracle AI Database / Autonomous AI Database
AI Vector Search / Select AI / RAG
- Oracle AI Vector Search
- Oracle AI Database Oracle AI Vector Search User's Guide, 26ai
- Announcing Select AI with Retrieval Augmented Generation (RAG) on Autonomous Database - Oracle Database Insider Blog
- Getting Started with AI Vector Search - Oracle LiveLabs
- AI Vector Search - 7 Easy Steps to Building a RAG Application using LangChain - Oracle LiveLabs
Oracle Sharding / Globally Distributed Database 関連
Oracle Multicloud / @Hyperscaler 関連
- Oracle Multicloud Solutions
- Oracle AI Database@Azure
- Oracle AI Database@Google Cloud
- Oracle AI Database@AWS
記事中の図を作成する際に参考にした公開資料
- GDAI How it works diagram
- Multi-region deployment diagram - Oracle Database Insider Blog
- Architecture - Globally Distributed Autonomous Database diagram - Oracle Database Insider Blog
- Select AI RAG vector store flow
- Select AI RAG process flow
参照
-
Oracle, “Globally Distributed Autonomous AI Database”
https://www.oracle.com/autonomous-database/distributed-autonomous-database/ ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 -
Oracle Database Insider, “Achieve data residency, availability, and scale with Oracle Globally Distributed Autonomous Database”
https://blogs.oracle.com/database/globally-distributed-autonomous-database ↩ ↩2 -
Oracle Docs, “Globally Distributed Autonomous AI Database - Get Started”
https://docs.oracle.com/en/cloud/paas/globally-distributed-autonomous-database/ ↩ ↩2 ↩3 ↩4 ↩5 ↩6 -
Oracle, “Oracle AI Vector Search”
https://www.oracle.com/database/ai-vector-search/ ↩ ↩2 -
Oracle, “Autonomous AI Database Select AI”
https://www.oracle.com/autonomous-database/select-ai/ ↩