
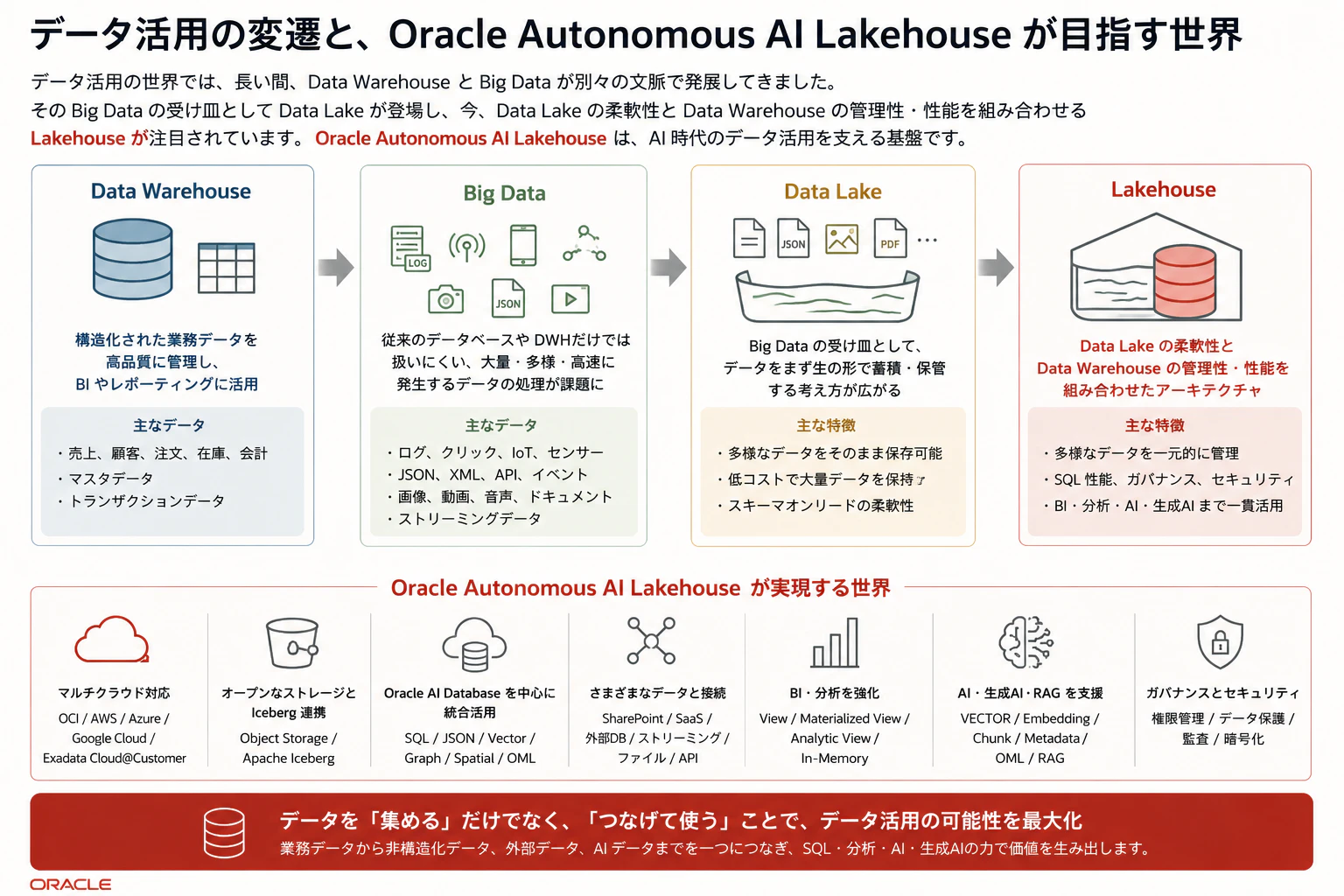
データ活用の世界では、長い間、Data Warehouse と Big Data が別々の文脈で発展してきました。
Data Warehouse は、構造化された業務データを高品質に管理し、BI やレポーティングに使うための基盤です。
一方で Big Data は、ログ、センサーデータ、Webアクセス、JSON、画像、ドキュメントなど、大量・多様・高速に発生するデータを扱うための文脈で広がりました。
その Big Data の受け皿として、データをまず生の形で蓄積する Data Lake が登場しました。
そして現在は、Data Lake の柔軟性と Data Warehouse の管理性・性能を組み合わせる Lakehouse が注目されています。
Lakehouse は、Data Lake の柔軟性と Data Warehouse の管理性・性能を組み合わせるアーキテクチャです。特に Oracle Autonomous AI Lakehouse の文脈では、単に「Object Storage にデータを置く」だけではなく、Oracle AI Database を中心に、Iceberg、Object Storage、外部表、Database Link、SharePoint、SaaS、Vector Search、BI、AI をつなげて使うところに大きな意味があります。
ということで、本稿では、Oracle Autonomous AI Lakehouse を軸に、Lakehouse で扱うデータ、Oracle AI Database から見た Lakehouse、そして実際に「どこに何を置くべきか」を整理します。
1. Lakehouse で扱うデータ
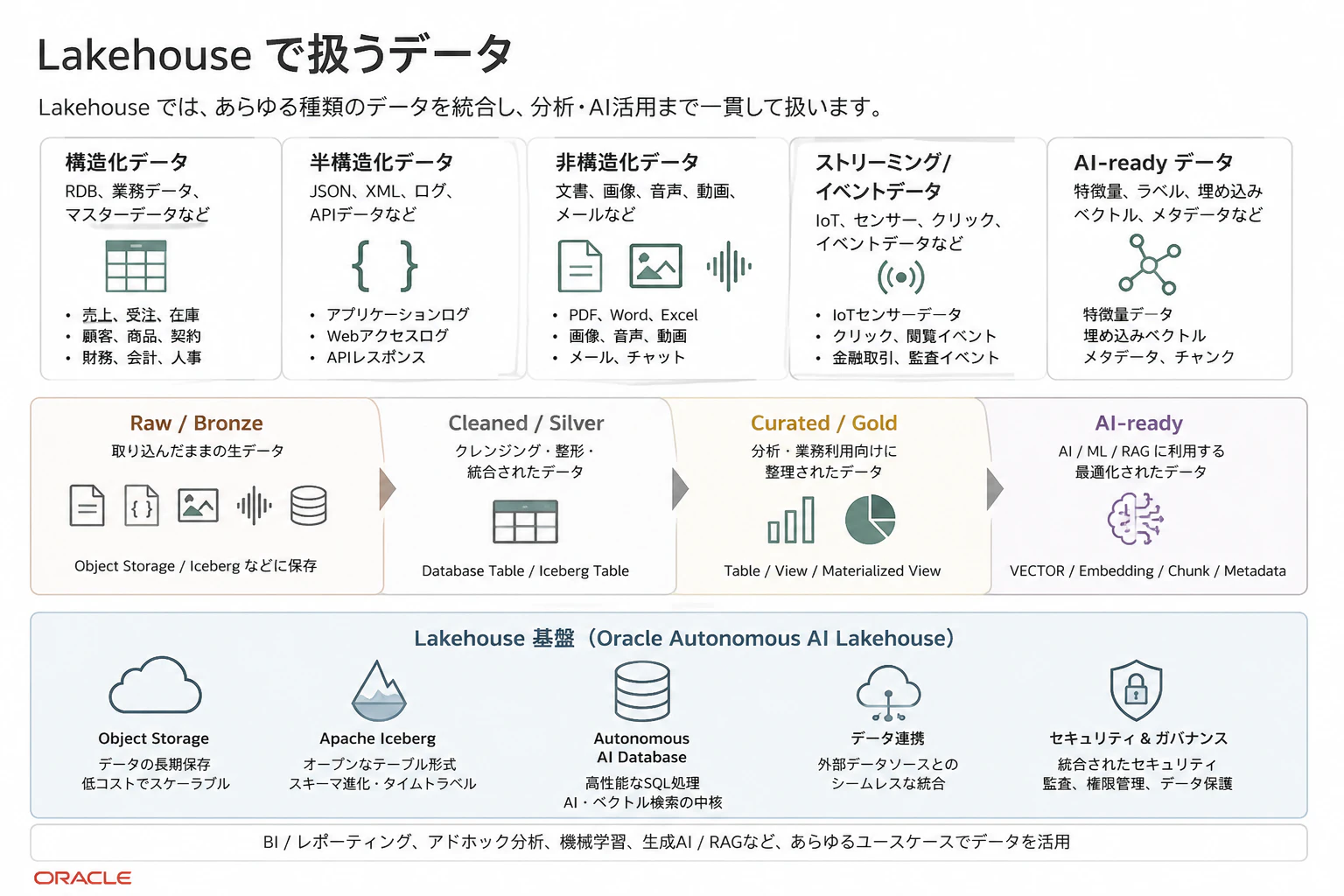
Lakehouse で扱うデータは、一言でいうと かなり幅広いです。
従来の Data Warehouse では、売上、顧客、注文、在庫、会計などの構造化データが中心でした。一方で Lakehouse では、構造化データに加えて、JSON、ログ、PDF、画像、音声、動画、IoT、イベント、Embedding なども扱います。
Oracle のドキュメントでも、Lakehouse は CSV や Parquet、Iceberg などのオープンなファイル・テーブル形式を利用し、構造化、半構造化、非構造化データを格納・処理するものとして説明されています。また、PDF、Word、画像などの非構造化データも Lakehouse の対象として挙げられています。
参考: Autonomous AI Lakehouse - Oracle Documentation
ここではまず「データの形」として、構造化・半構造化・非構造化の3つに分けます。
そのうえで、実務でよく登場するデータを用途別に整理すると、次のようになります。
データの形 → 構造化 / 半構造化 / 非構造化
実務上の分類 → 業務データ / ログ / IoT / 外部データ / 文書 / AIデータ
データの成熟度 → Bronze / Silver / Gold / AI-ready
- データ種別
| データ種別 | 具体例 | 主な用途 |
|---|---|---|
|
構造化データ 表形式で管理しやすいデータ |
売上、顧客、注文、在庫、会計、人事 | BI、KPI、レポート、業務分析 |
|
半構造化データ ある程度構造はあるが表に固定されないデータ |
JSON、XML、API レスポンス、アプリログ | イベント分析、アプリ分析、データ統合 |
|
非構造化データ 表形式にしにくいデータ |
PDF、Word、画像、音声、動画、メール | 検索、要約、RAG、AI 分析 |
Lakehouse の特徴は、この3種類をまとめて扱える点です。従来の DWH は構造化データが中心でしたが、Lakehouse ではログ、ファイル、画像、AI向けデータなども対象になります。
- 実務でよく使われるデータの種類
| 種類 | 具体例 | 主な用途 |
|---|---|---|
| 業務データ | 受注、売上、請求、顧客、契約、在庫 | BI、レポート、経営分析 |
| マスタデータ | 商品マスタ、顧客マスタ、組織マスタ、拠点マスタ | データ統合、名寄せ、分析の基準 |
| トランザクションデータ | 注文履歴、決済履歴、出荷履歴、予約履歴 | 需要分析、不正検知、顧客分析 |
| ログデータ | アプリログ、Webアクセスログ、監査ログ、システムログ | 障害分析、セキュリティ分析、利用状況分析 |
| イベントデータ | クリック、閲覧、検索、カート投入、アプリ操作 | 行動分析、レコメンド、マーケティング |
| IoT・センサーデータ | 温度、圧力、振動、位置情報、稼働状況 | 予兆保全、設備監視、リアルタイム分析 |
| ストリーミングデータ | Kafkaイベント、CDC、リアルタイム取引 | リアルタイムダッシュボード、即時検知 |
| 外部データ | 天気、市場データ、人口統計、SNS、パートナーデータ | 需要予測、リスク分析、補助データ |
| ドキュメントデータ | PDF、契約書、仕様書、問い合わせ文面 | 検索、要約、生成AI、ナレッジ活用 |
| 画像・音声・動画 | 製品画像、監視カメラ、通話録音、検査画像 | AI分析、品質検査、音声認識 |
| 地理空間データ | GPS、住所、配送ルート、店舗位置 | 商圏分析、物流最適化、移動分析 |
| AI・機械学習用データ | 特徴量、ラベル、学習データ、推論結果、埋め込みベクトル | モデル学習、MLOps、生成AI/RAG |
ここで重要なのは、データの種類だけでなく、データの成熟度も分けて考えることです。
Lakehouse の世界では、Bronze / Silver / Gold というレイヤーでデータを整理する考え方がよく使われます。Databricks の Medallion Architecture では、Bronze は Raw、Silver は validated、Gold は enriched というように、データ品質の段階として説明されています。
参考: Databricks Medallion Architecture
Oracle Autonomous AI Lakehouse で考える場合も、この整理は非常に使いやすいです。
Bronze / Silver / Gold + AI-ready のレイヤー
「Bronze / Silver / Gold という3層に、AI活用では Feature / AI-ready を加えて考えます。
| レイヤー | 内容 | Oracle でのイメージ |
|---|---|---|
| Raw / Bronze | 取り込んだままの生データ | Object Storage、Iceberg、Parquet、CSV、JSON、PDF、ログ |
| Cleaned / Silver | クレンジング、型変換、重複排除、結合済みデータ | Database Table、External Table、Iceberg Table |
| Curated / Gold | BI や業務利用向けに整理されたデータ | Table、View、Materialized View、Analytic View |
| Feature / AI-ready | AI / ML / RAG で使いやすい形にしたデータ | VECTOR 列、Embedding Table、Chunk Table、Metadata Table |
つまり Lakehouse では、単に「いろいろなデータを置ける」だけでは不十分です。
生データ → 整形済みデータ → 分析用データ → AI活用データ
のように段階的に管理することが多いです。
大切なのは、
生データを保持すること、
分析しやすい形に整えること、
業務で使える意味のあるデータにすること、
そして AI が使える形に変換することです。
まとめると、こう考えると整理しやすいです
Lakehouse で利用されるデータは、細かく見ると無数にあります。
ただし、実務上は次のようにまとめると十分です。
Lakehouse では、業務システムの構造化データ、ログやJSONなどの
半構造化データ、文書・画像・音声などの非構造化データを一元的に蓄積し、
BI・分析・機械学習・生成AIに活用する。
さらに短く言うと、
Lakehouse は、DWH 的な業務データと、Data Lake 的な多様な生データをまとめて扱う基盤です。
2. Oracle AI Database から見る Lakehouse
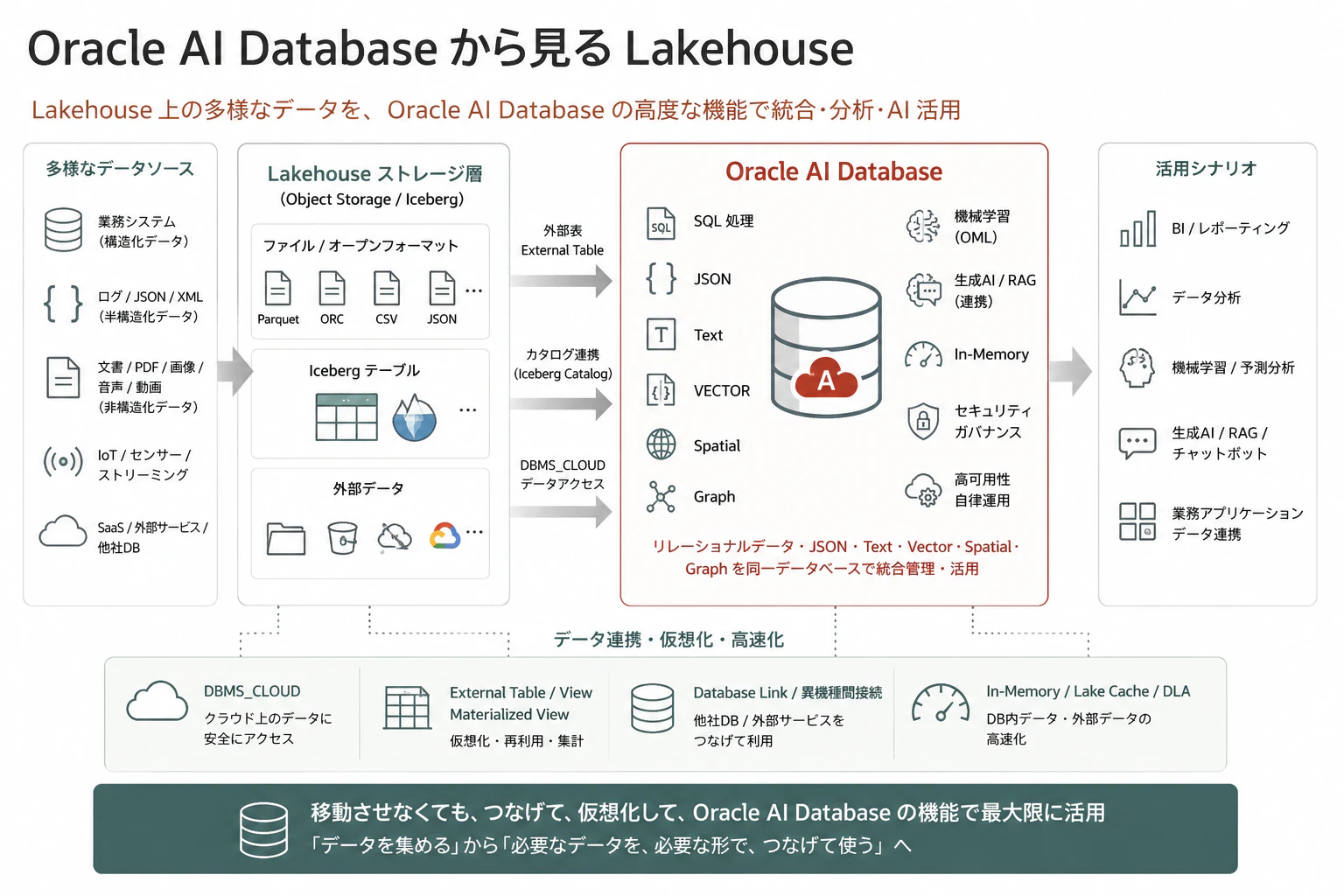
Oracle AI Database から Lakehouse を見ると、少し面白い見方ができます。
一般的な説明では、Lakehouse は Object Storage や Iceberg のようなストレージ層を中心に語られることが多いです。しかし Oracle の場合、Database 側が非常に強力です。Oracle Autonomous AI Database は、JSON、Graph、Vector、Oracle Machine Learning、Spatial などを扱える統合的なデータ基盤として位置づけられています。
参考: Autonomous AI Lakehouse - Oracle Documentation
つまり、Oracle AI Database は単なる「構造化データを入れる箱」ではありません。
Oracle AI Database では、リレーショナルデータだけでなく、JSON、Text、Vector、Spatial、Graph などを同じ Database の中で扱えます。特に JSON については、トランザクション、索引、宣言的な SQL クエリ、View などのリレーショナルデータベース機能と組み合わせてネイティブに扱えます。さらに、JSON データをリレーショナルデータと JOIN したり、外部表上の JSON を Database 内から問い合わせたりできます。
参考: JSON in Oracle AI Database
AI の観点では、Oracle AI Vector Search が重要です。Oracle AI Database 26ai では VECTOR データ型により、Embedding を業務データと同じ Database 内に格納できます。非構造化データを Embedding に変換し、セマンティック検索や RAG に利用できます。
参考: Oracle AI Vector Search Overview
この点が、Oracle らしい Lakehouse の特徴です。
一般的な Lakehouse では、
- Lake にデータを置く
- 別のエンジンで分析する
- 別の Vector DB に Embedding を置く
というように、複数のコンポーネントを組み合わせることが多くなります。
一方で Oracle AI Database を使う場合は、次のように考えられます。
Object Storage / Iceberg / 外部データ
↓
External Table / DBMS_CLOUD / Catalog / Database Link
↓
Oracle AI Database
↓
SQL / JSON / Text / Vector / Spatial / Graph / ML / BI / RAG
もちろん、すべてのデータを Database 内にコピーする必要はありません。Object Storage 上のファイルは外部表として問い合わせられます。Autonomous AI Database では、DBMS_CLOUD.CREATE_EXTERNAL_TABLE を使って Cloud 上のファイルに対する外部表を作成でき、OCI Object Storage、Azure Blob / ADLS、Amazon S3、Google Cloud Storage 互換ストレージなどが対象に含まれます。
参考: Query External Data with Autonomous Database
そのため、Oracle AI Database から見る Lakehouse は、次のように捉えると分かりやすいです。
Lakehouse ストレージ上のデータを、Oracle AI Database の SQL、ガバナンス、View、Materialized View、JSON、Vector、Text、Graph、Spatial、AI 機能で活用するアーキテクチャ
性能面では In-Memory も重要です。Oracle AI Database の Database In-Memory は、リアルタイム分析や混在ワークロードの性能改善を目的とした機能で、テーブル、パーティション、サブパーティション、Materialized View、さらに外部表も In-Memory 化の対象として説明されています。
参考: Use Database In-Memory with Autonomous Database
そのため、In-Memory は「保存先」ではなく、高速化レイヤーとして考えることができます。
また、Oracle Autonomous AI Database では、Lakehouse を高速化する機能 Lake Cache / Data Lake Accelerator (DLA) があります。
Lake Cache と Data Lake Accelerator は、オブジェクトストレージ(OCI Object Storage、AWS S3、Azure Blob、GCPなど)上の外部データを高速にスキャン・クエリするためのコア機能です。両者は「データレイクハウス環境のクエリ高速化」という目的は同じですが、アプローチが異なります。
・高速化レイヤー
| 機能 | 主な役割 | 仕組み | 適したユースケース |
|---|---|---|---|
| In-Memory | Database 内データの分析高速化 | Table、Partition、Materialized View、外部表などを In-Memory Column Store に列形式で保持する | Database 内のホットデータ、繰り返し実行される分析クエリ、集計、JOIN |
| Lake Cache | 外部データの繰り返しアクセス高速化 | 外部表や Mounted Catalog Table の頻繁に使われるデータを Autonomous AI Database 内にローカルキャッシュする | 定期ダッシュボード、定型レポート、同じ外部データを繰り返し参照する分析 |
| Data Lake Accelerator | 大規模な外部データスキャンの高速化 | Oracle-managed VM cluster 上の追加コンピュートにより、外部データの scan / filtering / projection / decompression をオフロードする | 大規模履歴データ、アドホック分析、TB〜PB級の広範囲スキャン |
3. Oracle Autonomous AI Lakehouse とは何か
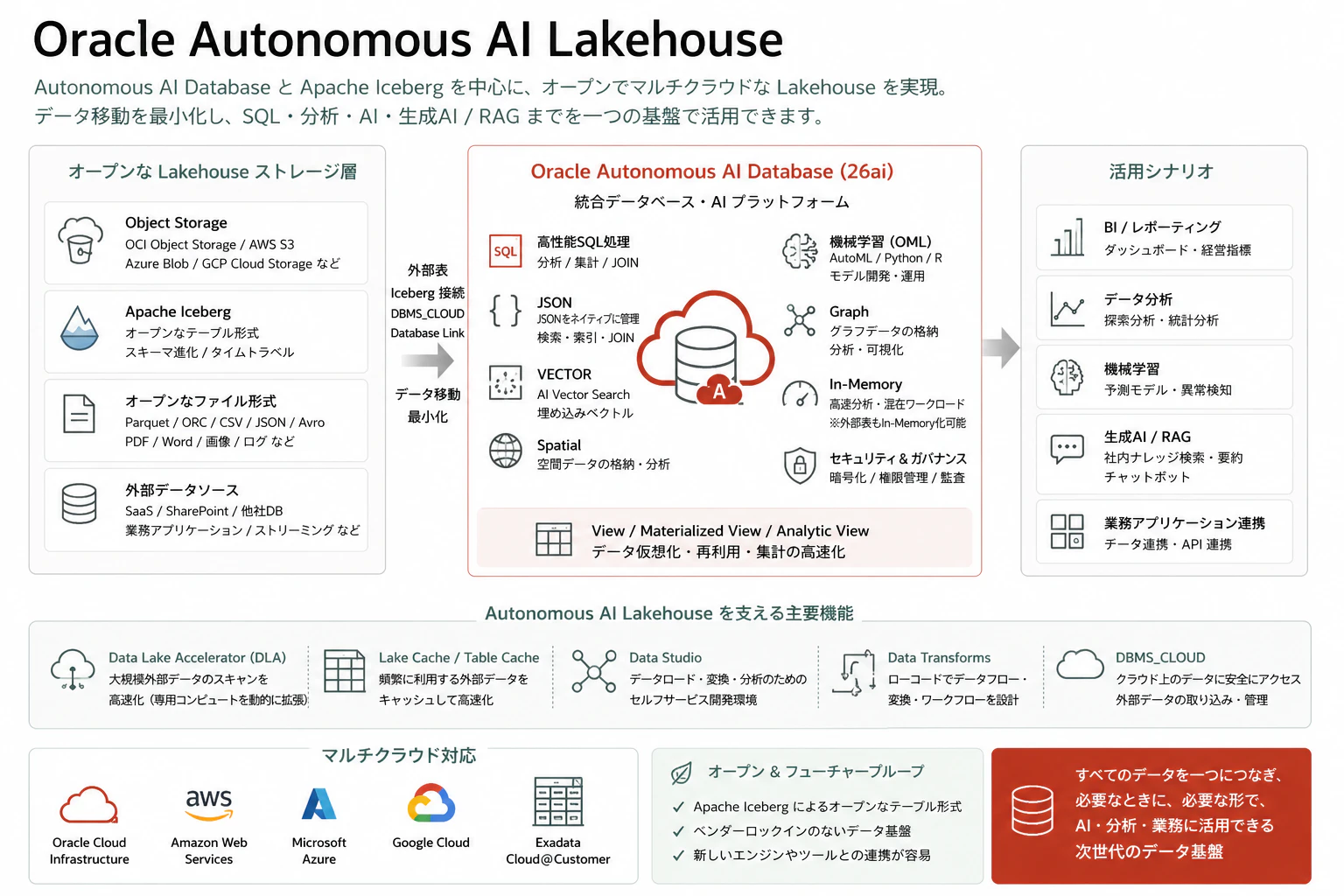
Oracle Autonomous AI Lakehouse は、Oracle Autonomous AI Database と Apache Iceberg を組み合わせた、オープンでマルチクラウド対応の Lakehouse プラットフォームとして位置づけられています。Oracle の製品ページでは、Autonomous AI Database とベンダー非依存の Apache Iceberg を組み合わせ、OCI、AWS、Azure、Google Cloud、Exadata Cloud@Customer 上のデータに対して AI と分析を実行できると説明されています。
参考: Oracle Autonomous AI Lakehouse
この説明で重要なのは、Iceberg です。
Apache Iceberg は、オープンなテーブル形式です。データを特定ベンダーの閉じた形式に閉じ込めるのではなく、複数のエンジンから読み書きしやすい形で管理するための重要な技術です。
Oracle Autonomous AI Lakehouse では、Iceberg テーブルをその場で問い合わせることができます。Oracle のドキュメントでは、Autonomous AI Database が Apache Iceberg テーブルの問い合わせをサポートしており、AWS Glue、Snowflake Polaris、Databricks Unity Catalog、JSON metadata などの構成にも触れられています。
参考: Query External Data in Apache Iceberg Format
Oracle の製品ページでは、Autonomous AI Lakehouse は Iceberg を通じて各クラウド上のオープンデータプラットフォームと統合し、Oracle AI Database 26ai の AI、機械学習、Graph、Spatial などをデータ移動なしで利用できると説明されています。また、Data Lake Accelerator や table caching により、外部データアクセスの性能向上も図れるとされています。
参考: Oracle Autonomous AI Lakehouse
さらに、Oracle Autonomous AI Lakehouse で注目したいのが、Iceberg REST Catalog との統合です。
Autonomous AI Database では、DBMS_DCAT PL/SQL 26ai パッケージにより、Databricks Unity Catalog や Polaris などの Iceberg REST 互換カタログに接続し、外部表として同期・問い合わせできるようになっています。
これは非常に重要です。
なぜなら、Lakehouse の世界では、単に Parquet や Iceberg ファイルを Object Storage に置くだけでなく、「どのテーブルがどこにあり、どのスキーマで、どの権限で、どのエンジンから使えるか」を管理する Catalog が重要になるためです。
Iceberg REST Catalog に対応することで、Oracle Autonomous AI Lakehouse は、他ベンダーの Lakehouse エコシステムと同じ足並みで、オープンなテーブル形式とカタログ管理に参加できます。
つまり、Oracle AI Database から見る Lakehouse は、Oracle 内に閉じたデータ基盤ではなく、Databricks、Snowflake、AWS、OCI、Object Storage、Iceberg Catalog などとつながる、よりオープンなデータ活用基盤として考えることができます。
ここから見えてくるのは、Autonomous AI Lakehouse が単なる「データ保管場所」ではないということです。
むしろ、次のような役割を持ちます。
オープンな Lakehouse ストレージ
- Object Storage
- Apache Iceberg
- Parquet / ORC / CSV / JSON
- PDF / Word / 画像 / ログ
Oracle Autonomous AI Database
- SQL
- JSON
- Text
- Vector Search
- Machine Learning
- Graph
- Spatial
- View / Materialized View
- In-Memory
- Data Studio
- Data Transforms
利用先
- BI
- レポート
- データ分析
- 機械学習
- 生成 AI
- RAG
- 業務アプリケーション
つまり、Oracle Autonomous AI Lakehouse は、次のように考えるとよいと思います。
Open Lakehouse Storage と Oracle AI Database の統合により、分散したデータを SQL、BI、AI、RAG で活用するための基盤
4. Autonomous AI Database で広がるデータ接続
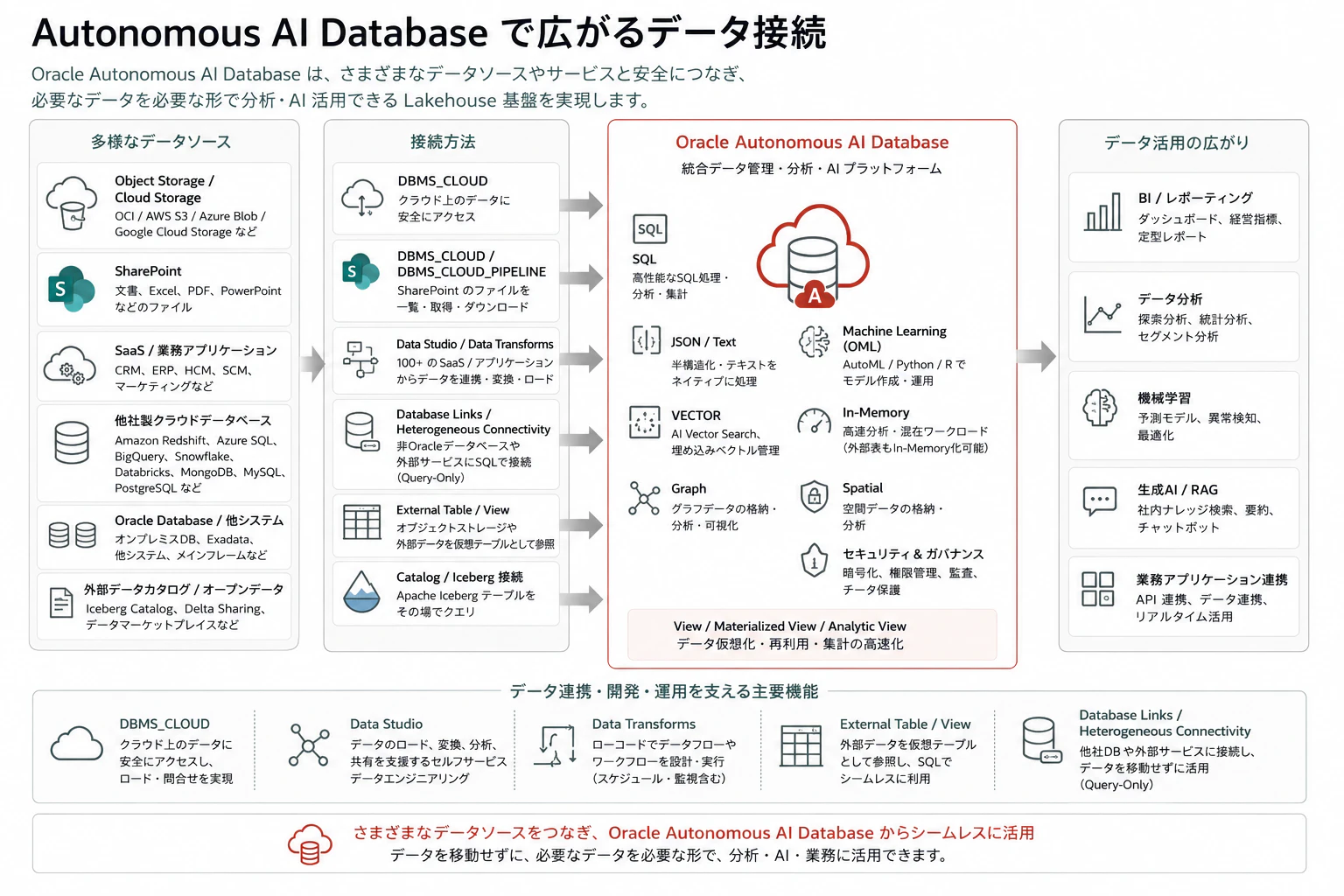
Oracle Autonomous AI Lakehouse の面白さは、Object Storage や Iceberg だけではありません。
Autonomous AI Database を中心に見ると、接続できるデータの範囲がかなり広がります。
対象は、クラウドストレージ、SharePoint、SaaS、業務アプリケーション、他社製クラウドデータベース、Oracle Database、外部データカタログなど、多岐にわたります。
さらに、Autonomous AI Database では Oracle-managed heterogeneous connectivity により、
非Oracleデータベースや一部の外部サービスに対して Database Link 経由で問い合わせる構成を取ることができます。
Oracle の製品ページでも、Autonomous AI Lakehouse はオープンテーブル形式や多数のデータベース・アプリケーションソースに接続し、構造化、半構造化、非構造化データをネイティブにサポートする統合分析プラットフォームとして説明されています。
参考: Oracle Autonomous AI Lakehouse
Object Storage / Cloud Storage
まず基本となるのは Object Storage です。
Raw / Bronze のデータ、つまり生ログ、CSV、JSON、Parquet、ORC、Avro、PDF、画像などは、Object Storage に置くのが自然です。Autonomous AI Database からは、外部表や DBMS_CLOUD を通じてこれらのデータを参照できます。
すべてのデータを最初から Database にロードする必要はありません。
必要に応じて、外部表として問い合わせる、ロードして Database Table にする、Materialized View で集計する、といった選択ができます。
SharePoint
業務データ活用で非常に面白いのが SharePoint 連携です。
多くの企業では、重要な情報がデータベースではなく、SharePoint 上の Word、Excel、PDF、PowerPoint に存在しています。従来、これらは分析基盤から見ると扱いにくいデータでした。
Autonomous AI Database では、DBMS_CLOUD と DBMS_CLOUD_PIPELINE を使って Microsoft SharePoint 上のファイルにアクセスできます。Oracle のドキュメントでは、SharePoint 上のファイルを list / retrieve し、外部コンテンツをダウンロードして後続の分析や索引作成に利用できると説明されています。さらに、DBMS_CLOUD_AI.CREATE_VECTOR_INDEX を使って SharePoint ファイルから直接 Vector Index を作成する例も示されています。
参考: Use DBMS_CLOUD with Microsoft SharePoint
これは Lakehouse の文脈ではかなり重要です。
なぜなら、SharePoint 上の文書を単なるファイルとして放置するのではなく、抽出テキスト、チャンク、Embedding、Metadata として Oracle AI Database 側に取り込み、RAG やセマンティック検索につなげられるからです。
SaaS / 業務アプリケーション
SaaS や業務アプリケーションとの接続も重要です。
Oracle Autonomous AI Lakehouse の Data Studio は、データのロード、変換、分析、共有を支援するセルフサービスのデータエンジニアリング機能として位置づけられています。Oracle の製品ページでは、Data Studio により、100 以上のアプリケーション、クラウドサービス、データベースソースと統合できると説明されています。
参考: Oracle Autonomous AI Lakehouse
また Data Transforms は、Autonomous AI Database 向けにデータロード、データフロー、ワークフローをローコードで設計するための機能です。データロード、結合、フィルタ、集計、マッピング、スケジュール、監視などを GUI ベースで扱えるため、SaaS データや業務アプリケーションデータを Lakehouse に取り込む際の実装手段になります。
参考: About Data Transforms
他社製クラウドデータベース / 異機種間接続
さらに、Autonomous AI Database では Oracle-managed heterogeneous connectivity により、非 Oracle Database への Database Link を作成できます。
Oracle のドキュメントでは、Amazon Redshift、Microsoft SQL Server、Azure SQL、Azure Synapse Analytics、Databricks、Google BigQuery、MongoDB、MySQL、PostgreSQL、Salesforce、ServiceNow、Snowflake、SharePoint などが db_type の例として挙げられています。ただし、この Oracle-managed heterogeneous connectivity は remote database に対して query-only で、更新はサポートされない点に注意が必要です。
参考: Create Database Links to Non-Oracle Databases with Oracle-Managed Heterogeneous Connectivity
この機能により、すべてのデータを物理的に移動しなくても、Oracle AI Database から他社製データベース上のデータを参照し、Oracle 側のデータと組み合わせて分析できます。
これは Lakehouse の考え方を広げます。
従来は、
データを集めてから分析する
という考え方が中心でした。
しかし Autonomous AI Lakehouse では、
必要なデータを、必要な形で、Oracle AI Database からつなげて使う
という発想ができます。
5. どこに何を置くべきか
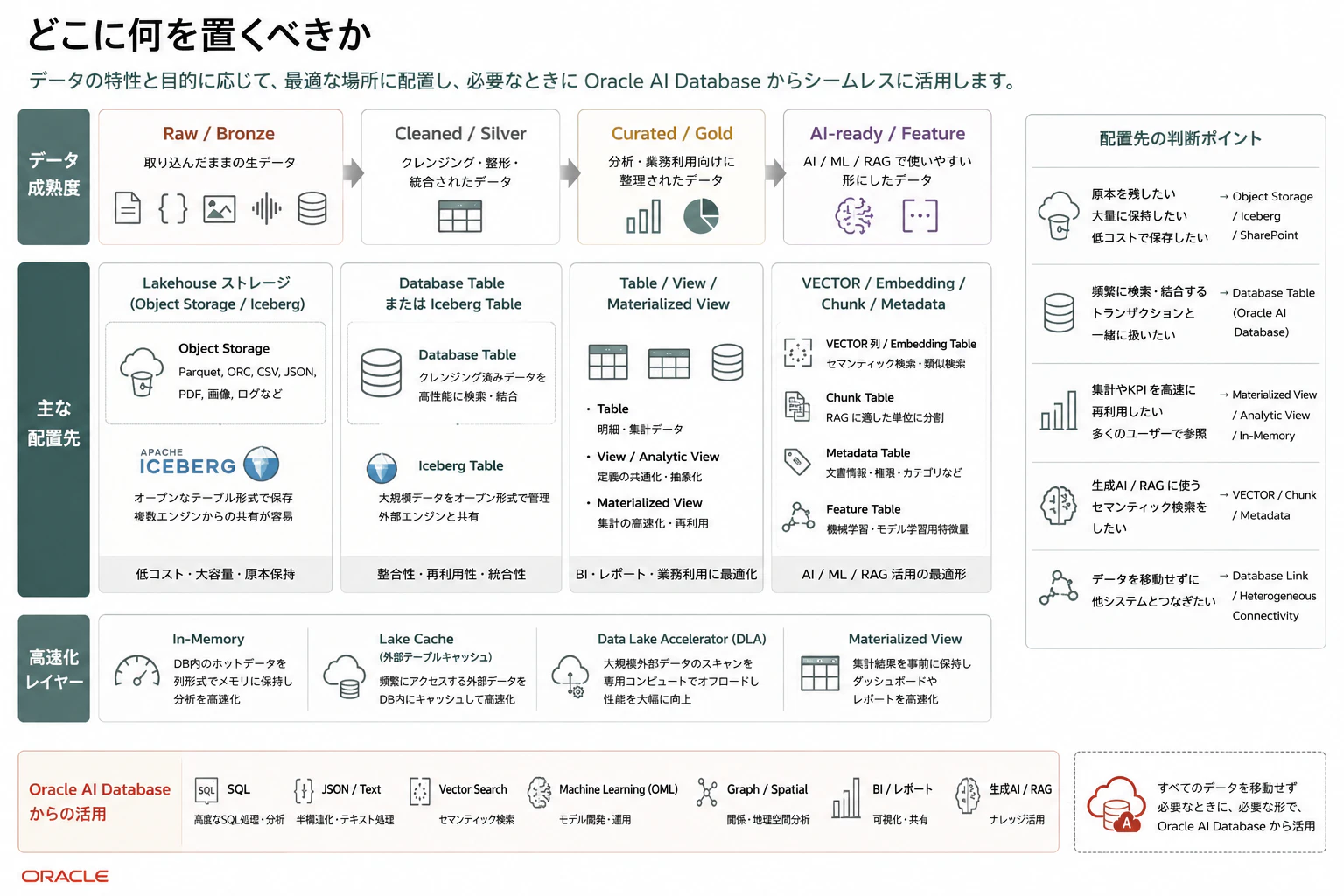
ここまで見てくると、扱えるデータと接続先がかなり広いことが分かります。
では実際に、どこに何を置くべきでしょうか。
私の整理では、Oracle Autonomous AI Lakehouse におけるデータ配置は、次の考え方が分かりやすいです。
| データ / レイヤー | 推奨配置 | 理由 |
|---|---|---|
| Raw / Bronze | Object Storage、Iceberg、Parquet、CSV、JSON、PDF | 原本性、低コスト、大量保存、再処理に向く |
| 生ログ / イベント / 履歴データ | Object Storage、Iceberg | 増え続けるデータをそのまま保持しやすい |
| 半構造化 JSON の原本 | Object Storage または External Table | まず原本を残し、必要に応じて構造化する |
| 頻繁に JOIN / 検索する JSON | Oracle AI Database の JSON 列 / Table | SQL、索引、View、トランザクションと組み合わせやすい |
| Cleaned / Silver | Database Table または Iceberg Table | 品質保証済みデータとして再利用しやすい |
| Curated / Gold | Table、View、Materialized View、Analytic View | BI、KPI、業務レポートに使いやすい |
| 高頻度分析データ | In-Memory、Materialized View、Lake Cache / Table Cache | レスポンス改善、ダッシュボード高速化 |
| PDF / Word / 画像などの原本 | SharePoint、Object Storage | 原本管理、監査、再処理に向く |
| 抽出テキスト | Database Table / CLOB | 検索、要約、チャンク化の元データ |
| チャンク | Database Table | RAG の検索単位として管理 |
| Embedding | VECTOR 列を持つ Database Table | 業務データと一緒にセマンティック検索できる |
| Metadata | Database Table | ファイル名、URL、権限、作成日、部門などを管理 |
| Feature / AI-ready | Feature Table、VECTOR Table、View、Materialized View | ML、AI、RAG、推論で再利用しやすい |
| 他社 DB の参照データ | Database Link / Heterogeneous Connectivity | 移動せずに参照・結合できる |
| SaaS データ | Data Studio / Data Transforms でロードまたは連携 | 定期連携、変換、業務データ化に向く |
この表をさらにシンプルにまとめると、次のようになります。
Raw / Bronze
→ Object Storage / Iceberg / SharePoint / 外部ストレージ
Cleaned / Silver
→ Database Table または Iceberg Table
Curated / Gold
→ Table / View / Materialized View / Analytic View
Performance Layer
→ In-Memory / Lake Cache / Table Cache / Materialized View
AI-ready
→ VECTOR / Embedding / Chunk / Metadata / Feature Table
ここでのポイントは、構造化データだから必ず Database、非構造化データだから必ず Object Storage と固定しないことです。
より実践的には、次の基準で考えるとよいです。
原本・大量・低頻度アクセスのデータは Lakehouse ストレージへ
ログ、履歴ファイル、PDF 原本、画像、JSON 原本、Parquet ファイルなどは、Object Storage や Iceberg に置くのが自然です。
これらは、あとで再処理したり、監査用に残したり、別のエンジンからも使う可能性があるため、オープンな形式で保持しておく価値があります。
品質保証済み・再利用されるデータは Database Table または Iceberg Table へ
クレンジング済み、型変換済み、重複排除済み、業務キーで結合済みのデータは、Silver レイヤーとして扱います。
Oracle AI Database で高速に JOIN、検索、AI 処理したい場合は Database Table にするのが自然です。一方で、複数エンジンから共有したい大規模分析データであれば Iceberg Table として管理する選択もあります。
BI・KPI・ダッシュボード用データは Gold として整理する
経営指標、部門別売上、顧客セグメント、在庫回転率、SLA、利用状況など、業務利用されるデータは Gold レイヤーとして整理します。
ここでは、Table、View、Materialized View、Analytic View が候補になります。高頻度に使われる集計は Materialized View、低頻度だが定義を共通化したいものは View、性能要件が高いものは In-Memory などを検討します。
AI-ready データは Database 側に寄せると扱いやすい
生成 AI / RAG で使う場合、原本ファイルそのものよりも、次のような派生データが重要になります。
| AI-ready データ | 内容 |
|---|---|
| Extracted Text | PDF や Word から抽出したテキスト |
| Chunk | RAG で検索しやすい単位に分割したテキスト |
| Embedding | Chunk や文書をベクトル化したもの |
| Metadata | 文書名、URL、権限、カテゴリ、作成日、部門 |
| VECTOR Index | セマンティック検索用の索引 |
| Text Index | キーワード検索・全文検索用の索引 |
| Access Control Metadata | 部門、所有者、閲覧権限、SharePoint URL、公開範囲 |
Oracle AI Database では、Embedding を VECTOR データ型として業務データと同じ Database に格納できます。これにより、セマンティック検索だけでなく、顧客、契約、製品、問い合わせ、権限情報などの構造化データと組み合わせた RAG を設計しやすくなります。
参考: Oracle AI Vector Search Overview
たとえば、SharePoint 上の技術文書を RAG 化する場合は、次のような配置が考えられます。
SharePoint
- Word
- PDF
- Excel
- PowerPoint
↓ DBMS_CLOUD / DBMS_CLOUD_PIPELINE
Oracle AI Database
- Document Metadata Table
- Extracted Text Table
- Chunk Table
- Embedding Table with VECTOR column
- Vector Index
- Text Index
↓
Select AI / RAG Application / Chatbot / BI / Search
この構成では、SharePoint は文書原本の置き場であり、Oracle AI Database は検索・分析・AI 活用のための実行基盤になります。
6. まとめ:Lakehouse は「集める基盤」から「つなげて使う基盤」へ
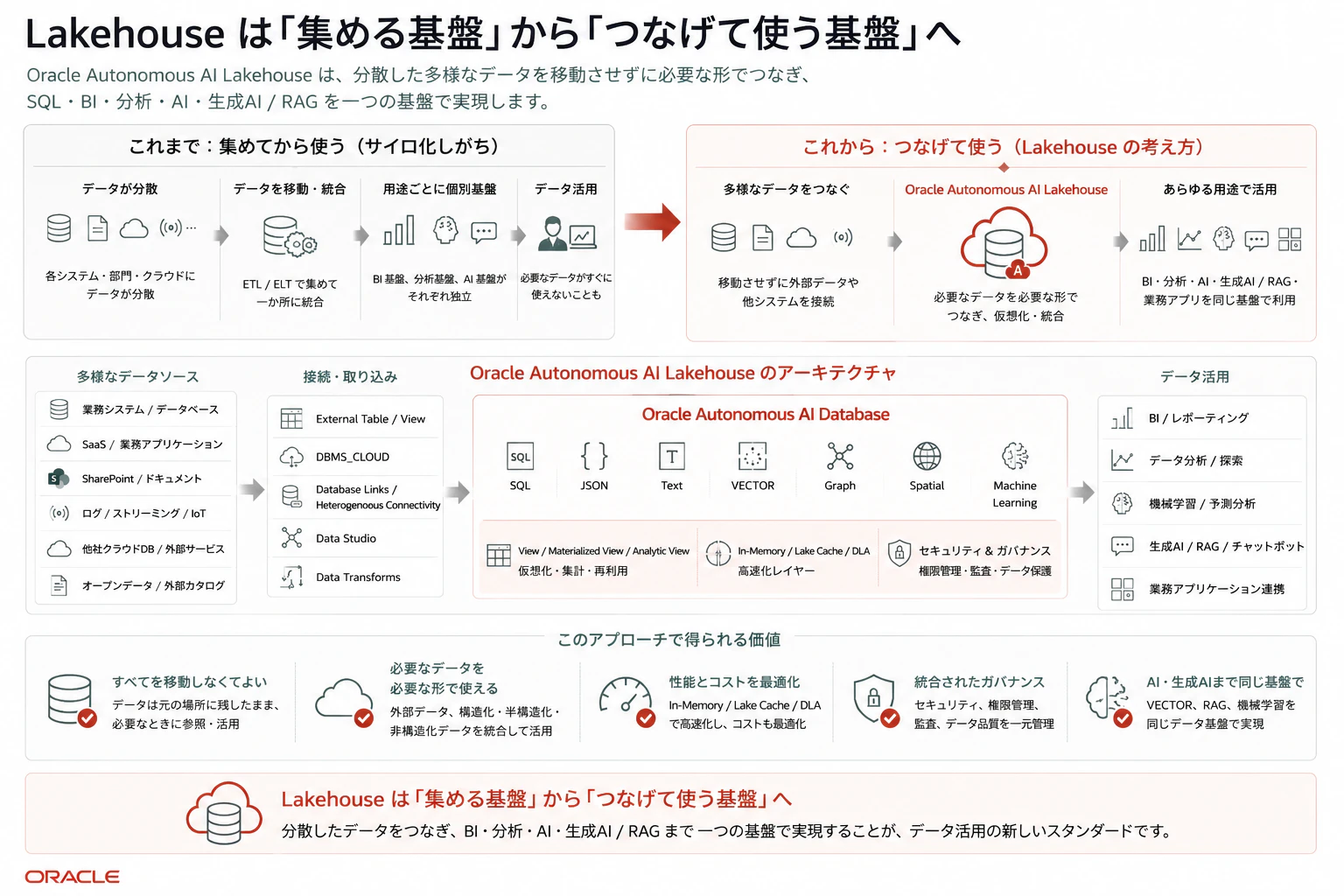
Lakehouse というと、最初は「Data Lake と Data Warehouse を組み合わせたもの」と説明されることが多いです。
しかし、Oracle Autonomous AI Lakehouse の文脈で見ると、それだけでは少し物足りません。
Oracle Autonomous AI Lakehouse の面白さは、Object Storage や Iceberg にデータを置けることだけではありません。Oracle AI Database を中心に、構造化データ、半構造化データ、非構造化データ、SharePoint、SaaS、他社製クラウドデータベース、外部表、Database Link、Vector Search、BI、AI、RAG をつなげて使えるところにあります。
従来の発想では、分析するためにはまずデータを 1 か所に集める必要がありました。
もちろん、今でもデータを集めて整えることは重要です。特に Curated / Gold や AI-ready のように、品質と再利用性が求められるデータは、Oracle AI Database 側に整理しておく価値があります。
しかし、すべてのデータを無理に移動する必要はありません。
原本は Object Storage や SharePoint に置く。
大規模なオープン分析データは Iceberg に置く。
業務で頻繁に使うデータは Database Table に置く。
BI 用のデータは View や Materialized View にする。
高速化したいデータは In-Memory や Cache を使う。
生成 AI で使うデータは Chunk、Embedding、Metadata として AI-ready にする。
このように考えると、Lakehouse は単なる「データを集める基盤」ではなくなります。
Lakehouse は、分散したデータを必要な形でつなぎ、SQL、BI、分析、AI、生成 AI / RAG から使えるようにする基盤である。
Oracle Autonomous AI Lakehouse は、その考え方を Oracle AI Database の強みと組み合わせて実現しようとしているアーキテクチャです。
特に Oracle ユーザーにとっては、既存の Oracle Database 資産、SQL、View、Materialized View、セキュリティ、ガバナンス、In-Memory、JSON、Spatial、Graph、Vector Search を活かしながら、Object Storage、Iceberg、SharePoint、SaaS、他社製データベースへ広げていける点が大きな魅力です。
これからのデータ活用では、構造化データだけを見ていては足りません。
PDF、文書、ログ、イベント、SaaS、外部 DB、Embedding まで含めて、どのデータをどこに置き、どのタイミングで Database に寄せ、どの形で AI-ready にするかが重要になります。
Oracle Autonomous AI Lakehouse は、そのための選択肢を広げてくれる基盤だと言えます。
最後に:配置方針のまとめ
最後に、この記事の要点を一枚でまとめると次のようになります。
| 判断軸 | 配置先 |
|---|---|
| 原本を残したい | Object Storage / SharePoint / Iceberg |
| 大量データを低コストで保持したい | Object Storage / Iceberg |
| 複数エンジンで共有したい | Iceberg / Open Table Format |
| SQL で頻繁に JOIN したい | Oracle AI Database Table |
| JSON を業務データと一緒に扱いたい | Oracle AI Database JSON |
| BI / KPI に使いたい | View / Materialized View / Analytic View |
| 高速化したい | In-Memory / Lake Cache / Table Cache |
| RAG に使いたい | Chunk Table / VECTOR Table / Metadata Table |
| 他社 DB を参照したい | Database Link / Heterogeneous Connectivity |
| SaaS データを取り込みたい | Data Studio / Data Transforms |
| SharePoint 文書を検索したい | DBMS_CLOUD / DBMS_CLOUD_AI / Vector Index |
Oracle Autonomous AI Lakehouse を考えるときのキーワードは、
「集める」だけでなく「つなげて使う」 です。
そして Oracle らしいポイントは、
つなげた先で Oracle AI Database の SQL、AI、Vector、JSON、Graph、Spatial、ガバナンスを使えること
にあります。
■ 参考資料
■ おまけ
