というような疑問を浮かべてしまう、データチーム以外の方に向けた記事になります。
データ、すでにあるけど
昨今(に限らずですが)、データ(分析基盤)が大事と言われます。AI 利用のためにも、データ分析基盤を整えようと言われます。そんな中、次のような疑問が浮かぶ方はいないでしょうか?
データ分析基盤にデータを貯める? データは、アプリケーションのデータベースにすでにあるけど
「アプリケーションの データベース」という部分は、ログデータだとか、CRM だとか、Web の行動分析ツールなどと言い換えても構いません。データは既に存在しており、必要なデータは(少しスキルが必要だとしても)取得できることが多いです。プロダクトマネージャーが、仮説検証のためにソフトウェアエンジニアにデータ出しを依頼し、アプリケーションのデータベースに対して、SQL を書いてデータを取得して渡すという作業を行えば、分析は可能です。実際それで済む場合もあります。であれば、データ分析基盤がないと困る瞬間って、あまり思いつかなかったりしないでしょうか?
そしてそれならば、データエンジニアリングに携わっている人って、日々一体何をやっているんだろう?と疑問に浮かぶかもしれません。
データ分析基盤があることで...
データ分析基盤には、データが一元化されています。2つの意味に分けて説明してみると
一元化 = 見渡せる
組織内のデータは、基本的に散らばっています。プロダクトごとにデータベースが分かれているだけでなく、Web の行動分析ツール、CRM、ログ、CSV データ、議事録、などなど。これらのデータを見たくなったときに、どこになにがあるかわからないということもあるかと思います。データ分析基盤に、組織内のあらゆるデータが集約されていることで、ここを見れば良い、となります。
一元化 = 一緒に使える
また、単に集まっているだけでなく、同じ意味のデータを関連させることができます。例えば、Web の行動分析ツールだけであれば、そこからわかることは限定的かもしれません(例:あるユーザがある画面にアクセスした)。一方で、データ分析基盤に、そのユーザの所属する属性の情報、さらにその属性の特定の情報がそれぞれ格納されている場合、データ分析基盤から、複数の情報を横断的に一度で確認することができます(例:あるユーザがある画面にアクセスした、そのユーザは XX という部署に所属しており、その部署は xx という性質を持つ)。
データ分析基盤のために...
データ分析基盤、役に立つかも!と思えたでしょうか。... まぁそう思えるようになったとして、では、データ分析基盤のために、なにをすることがあるのでしょうか。それぞれのプロダクトやシステムから、データを引っ張ってきて、終わりなんじゃないの? なにすんの?
人が読めるように
まず、使い勝手を良くする必要があります。単純にデータを引っ張ってきただけで「用意しておいたんで使ってください」と伝えたとして、ビジネスサイドに近い方が使いこなすのは難しいと思われます。ここでは、基本的な考え方の違いを意識しないといけません。それは、アプリケーションのデータベースは性能を重視し、データ分析基盤(データウェアハウス)のデータはわかりやすさを重視する ということです。
アプリケーションのデータベースは、更新頻度が高く、書き込まれることに最適化するため、正規化されています。データの挿入に何秒もかかることを防げるなら、複数回 join することになるとしても、テーブルを分割します。一方で、データ分析基盤で使われるデータは、参照が前提であり、人がビジネスの観点から読めるように、整理されている必要があります。
人にとって読みやすいということは、例えば、明確で、関係性が単純で、誤解の余地が少ない ということです。テーブルの join は少ない方がいいです。これはすなわち、BI で使いやすい、AI が正しいクエリを生成しやすい、ということに繋がります。
で、なにしてんの
やっと、データ分析基盤のためにやっていることを説明する準備が整いました。
先ほど、データ分析基盤には、あらゆるプロダクトやシステム(データソースといいます)から、データを引っ張ってきている、と書きました。一方で、データを引っ張ってきただけでは、使ってもらうのは難しいので、人が読めるようにする必要があるとも書きました。ここの間を埋めないといけません。
データソース ---> (いい感じにする) ---> データマート
データマートと書きましたが、つまり、人が分析のためにそのまま使えるテーブルだと思ってください。データ分析基盤のためには、上記の(いい感じにする)をする必要があります。
レイヤー
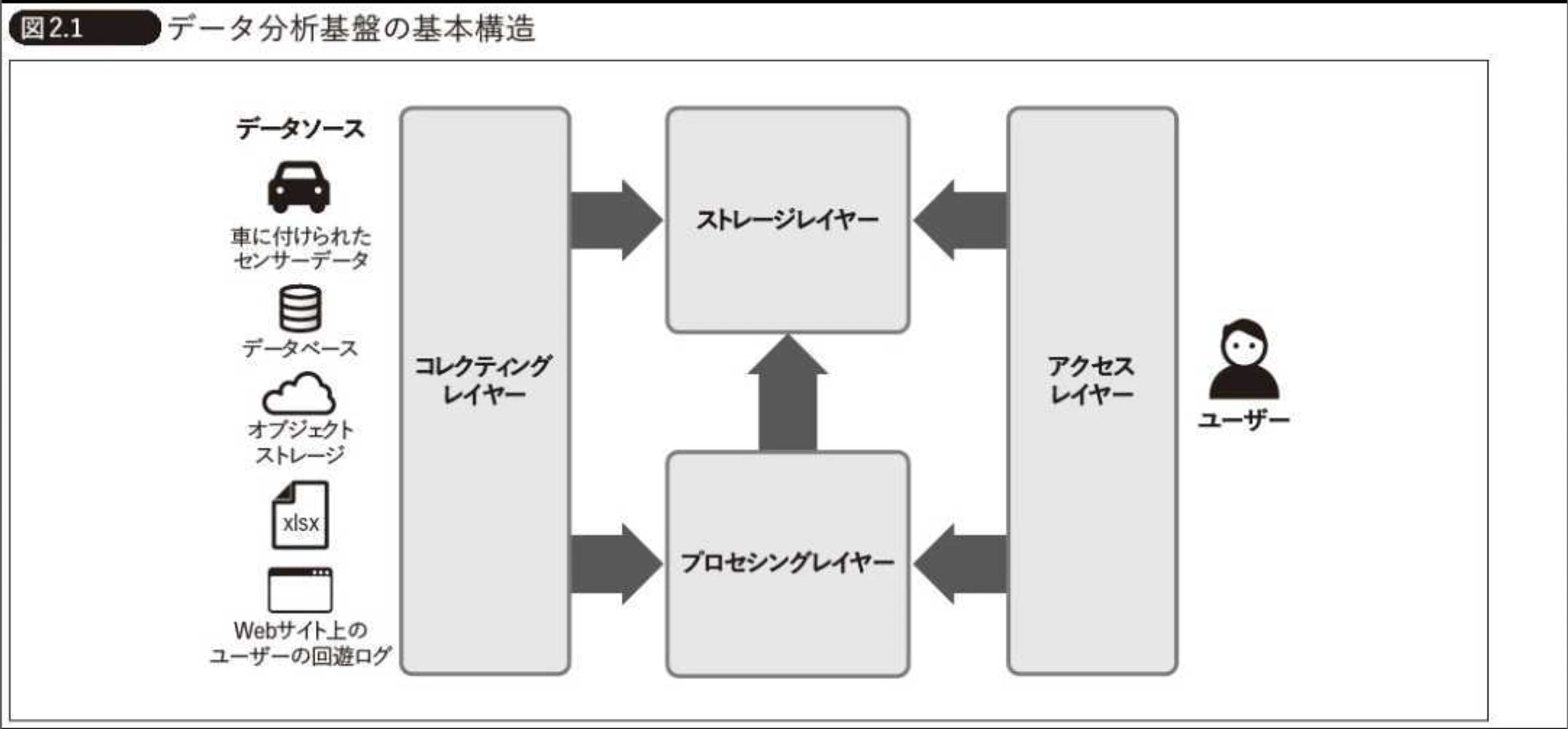
実際には、データ分析基盤は「一枚岩」ではありません。いくつかの役割に分かれたレイヤーで構成されています(おもしろいと思いませんか)。レイヤーの分け方は色々とありますが、データ分析基盤のアーキテクチャを構成する上での、主要なレイヤーを紹介してみます。一般的な話です。
(1)コレクティングレイヤー
様々なデータソース(アプリケーションデータベース、CRM、ログファイル)で常に発生しているデータを漏れなく集め、プロセシングレイヤーやストレージレイヤーに渡す。
(2)プロセシングレイヤー
コレクティングレイヤーによって取り込まれたデータを、分析しやすい構造に変換・加工・クレンジングする。ETL(またはELT)のTransform(変換)を担当。
(3)ストレージレイヤー
データやメタデータを保存する。各種レイヤーのアクティビティは、このレイヤーに対して行われる。
(4)アクセスレイヤー
ストレージに保管された処理済みのデータに対して、ユーザーやアプリケーションが直接アクセスし、データ価値を得る接点。
※ 改訂新版[エンジニアのための]データ分析基盤入門<基本編> の 2.2 節から図を利用させていただきました
頭のつかいどころ
レイヤーを考えることは、責務分離の観点が含まれます。利用しやすいテーブルを考えることは、データモデリングといった設計の観点が含まれます。データソース変更を追従するための変更耐性を考えたりします。エンジニアリングですね。
その他の仕事
代表的なことを書きましたが、他にもクエリの実行時間だとか、コストだとか、メタデータ管理であるとか、フリクション(提供されてから使うまでの時間)だとか、色々考えることはあったりします。
ときに地味ですが、ビジネスへの貢献(と自分たちのおもしろさ)のために、粛々と頭を捻ってます。