概要
実務で扱っているAurora Serverlessがダウンしてしまい、原因の調査で右往左往してしまったため、調査時に役立ったメトリクス、ログ等をまとめておきたいと思います。
serverlessのv1を前提に話しますが、v2でも基本的には同様かと思います。
Serverless(v1)は2024年末をもってサポート終了となるため、年内にv2へのアップデートが必要になるそうです。(参考URL)
調査フロー
0. 障害発生
RDSに何らかの異常があったことを知らせるエラー通知が飛んできました。
メトリクス EngineUptimeにて、RDSインスタンスの総稼働時間を確認できます。
正常に稼働していれば以下のように一直線に伸びていきます。
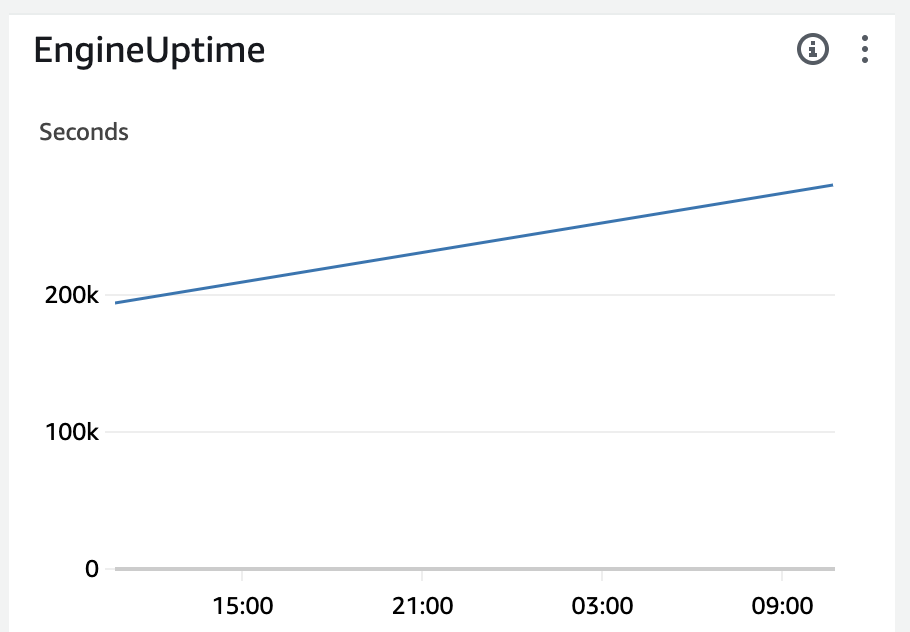
もし直線が一度0に落ちている(リセットされた)場合は、何か起きたのだという察しがつきます。
なおEngineUptimeがリセットされた=障害というわけではありません。以下の場合にも0に戻ります。
- ACUがオートスケールした場合
オートスケールしたかどうかは、ACUUtilizationやServerlessDatabaseCapacityというメトリクスから判断できます。 - 設定に基づき自動停止した場合
v1の場合、一定時間アクセスがない場合は自動停止してくれるオプションが存在します。自動停止した場合はWebコンソールの最近のイベント等で確認できます。
今回は上記に当てはまらず、障害起因でAuroraインスタンスがダウンしてしまったという前提で話を進めます。
1. まずはエラーログを確認
Aurora ServerlessのログをCloudWatchに出力することができます。
参考
障害発生時刻のエラーログを確認してみましょう。
例えば、以下のようなログが出力されている場合はメモリ不足に陥っていたことを示します。
Available memory is low. Trying to avoid OOM crash...(省略)
ここでは上記のエラーメッセージが出力されていたという前提で進めていきます。
2. エラー内容に応じてメトリクスを確認
エラー内容に応じて、Auroraのメトリクスを確認しましょう。例えばメモリの枯渇が怪しい場合は、FreeableMemoryでメモリの空き状況の推移を確認しましょう。
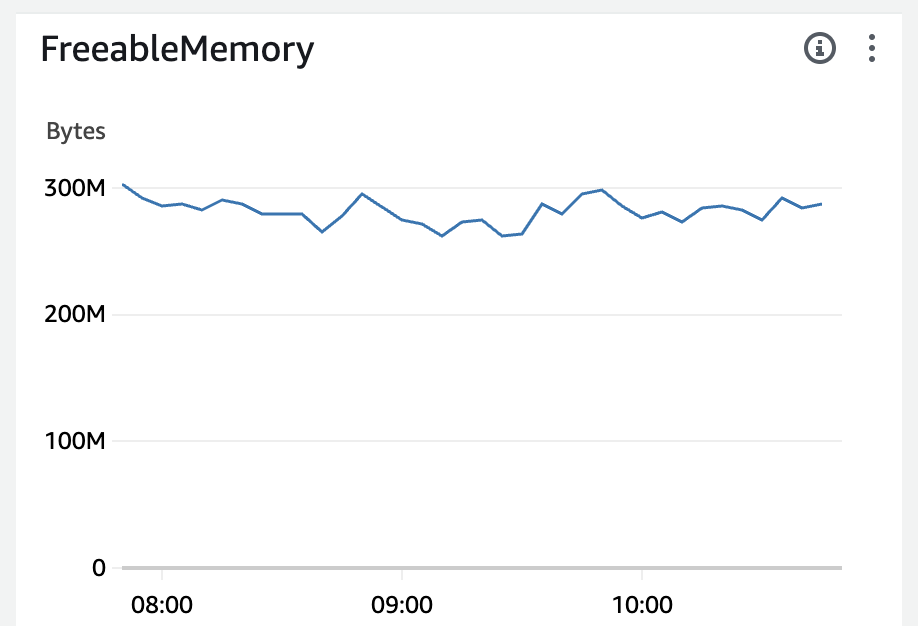
ここでは障害発生時に空きメモリが急激に減少していた(メモリの枯渇がAuroraのダウンを引き起こしてそうだ)という前提で進めます。
3. メモリ枯渇原因の調査
FreeableMemoryでは、メモリ枯渇の原因が何かまでは特定できません。
これを特定するのに役立つメトリクスが以下になります。
- ReadIOPS
- ReadThroughput
- WriteIOPS
- WriteThroughput
上記はそれぞれ文字通り読み込み、書き込みのIOPS、スループットを示します。
例えばメモリ枯渇と同時間帯にReadIOPSも急上昇している場合は、急激な読み込み回数の上昇に着いていけずメモリが枯渇してしまったのでは、といったような推測がつきます。
IOPSの上昇はなく、ReadThroughputやWriteThroughputが急上昇している場合は、大量の読み込み、書き込みを行う非効率な処理の実装が原因かもしれません。
AuroraServerlessはメモリ枯渇をトリガーにオートスケールしてくれない
メモリ枯渇が原因と分かった際に、ACUは最大までスケールアウトしているのか、その上でメモリが足りていないのかを確認しようとしました。(そうであればオートスケール設定の見直しが必要な可能性が高いため)
しかしACUは最小の状態で、一切スケールアウトした形跡もありませんでした。
調べたところ、どうやらACUのスケールアウトのトリガーにメモリの空き状況が含まれないようです。
最後に
以上、簡単ですが原因調査の流れと参考になったメトリクス、ログのまとめでした。(原因への対策についてはこれから検討していきます。)
もし何か他にも確認すべき項目等あればご教授いただけると幸いです!
ちなみにこの辺りの記事もモニタリングや障害調査時に役立ちそうです!
https://aws.amazon.com/jp/blogs/news/making-better-decisions-about-amazon-rds-with-amazon-cloudwatch-metrics/