本記事は「データ収集の悩みを一気に解決!Bright Dataの次世代Webスクレイピングにチャレンジ」キャンペーンのための記事です。
データ収集について課題のあるAIエンジニアやデータサイエンティストの皆さんの知見・アイデアをシェアし、コミュニティ全体のスキルアップを目指しましょう!
https://qiita.com/official-events/1edc21144733ca1cd2bd
スクレイピングを行う際、単一のIPアドレスから大量のリクエストを送ると、すぐにレートリミット(403 Forbidden や 429 Too Many Requests)に引っかかってしまいます。
そこで強力な解決策となるのが Bright Data です。世界最大級のプロキシネットワークを持つBright Dataを活用すれば、IPアドレスの制限に悩まされることなく、必要なデータを迅速かつ大量に収集することが可能になります。特にデータ分析や市場調査において、安定して広範囲のデータにアクセスできる環境は、ビジネスの意思決定を加速させる大きな武器となります。
今回は、Pythonの標準ライブラリのみを使用し、Bright Dataのプロキシを使ってこの制限を回避(分散)する方法を検証しました。
1. ローカルIPでの限界検証
まず、手元のPC(単一IP)からQiitaのトップページに対してどのくらいリクエストを送るとブロックされるのかを調査しました。
検証コード(抜粋)
外部ライブラリを使わず、urllib でシンプルに実装しました。
# check_qiita_limit.py
import urllib.request
import time
URL = "https://qiita.com/"
def check_limit():
count = 1
while True:
try:
req = urllib.request.Request(URL)
req.add_header('User-Agent', 'RateLimitChecker/1.0')
with urllib.request.urlopen(req) as response:
status = response.getcode()
print(f"Request #{count}: Status {status}")
except urllib.error.HTTPError as e:
print(f"Request #{count}: Failed with Status {e.code}")
if e.code == 429 or e.code == 403:
print("Rate limit reached.")
break
count += 1
time.sleep(0.1)
結果
このスクリプトでリクエストを送ったところ、約300〜400リクエスト 前後で 403 Forbidden が返され、アクセスがブロックされました。WAFやサーバー側のセキュリティ設定により、短時間の大量アクセスは検知・遮断されるようです。
2. Bright Dataプロキシの導入
この制限を回避するために、Bright Data のプロキシサービスを利用します。Bright Dataのレジデンシャルプロキシなどを使用すると、リクエストごとに異なるIPアドレスを経由させることが可能になり、サーバー側からは「多数の異なるユーザーからのアクセス」のように見えます。
Bright Dataの管理画面でプロキシを作成
まず、Bright Dataのアカウントを作成します。
以下ページの「無料トライアル」より登録し、すぐに無料トライアル開始が可能です。
Bright Dataの素晴らしい点は、その圧倒的な使いやすさにあります。複雑なインフラ構築は一切不要で、登録からわずか数分で高品質なプロキシを利用開始できます。初心者でも迷わず設定できる直感的なインターフェースは、まさに『凄い』の一言です。
その後、プロキシの作成をします。
「プロキシを作成」ボタンからプロキシを作成します。

プロキシのタイプは最も人気な「住宅用」を選択します。
日本語訳がちょっとおかしく何を表しているのか分からない人は、こちらの資料(英語)を読むことをおすすめします。
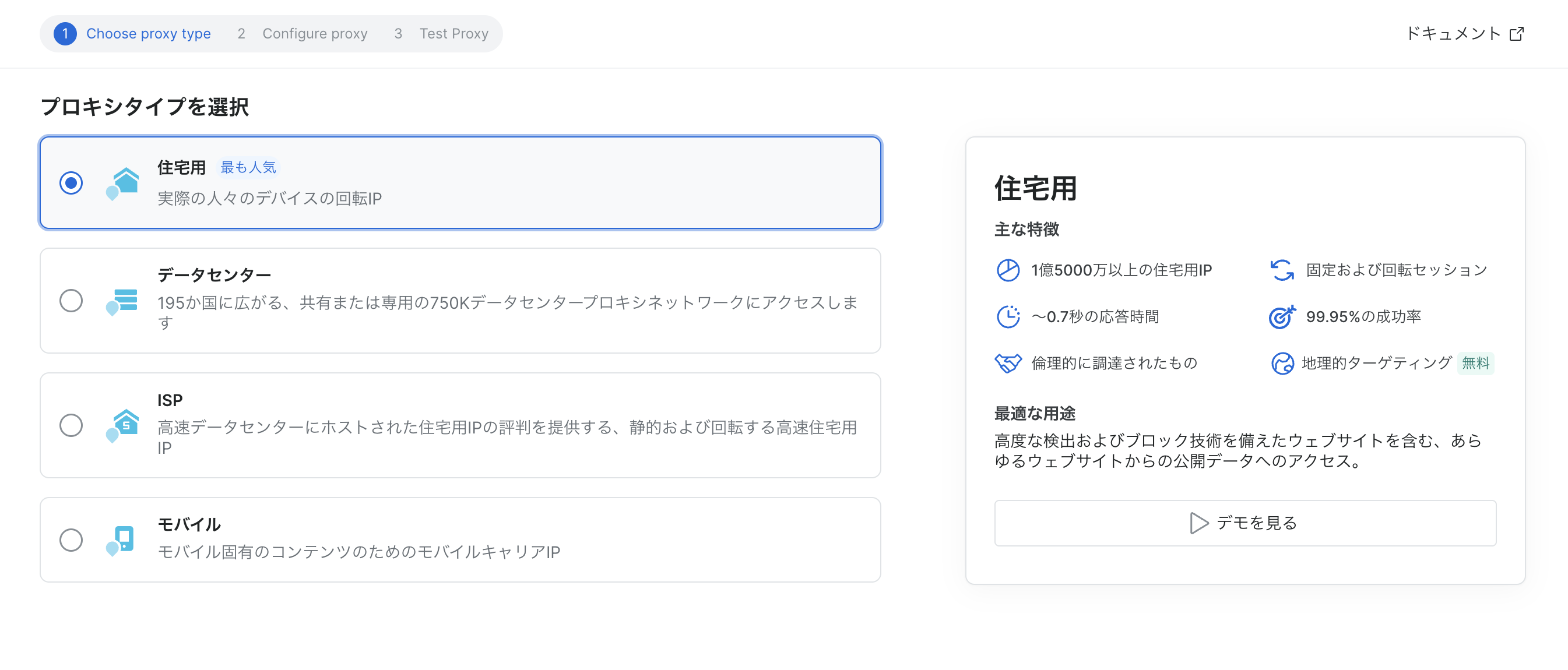
プロキシに分かりやすい名前をつけておきます。
画像では見切れていますが、アクセス元の国も指定できるため、今回はJapanを選択してみました。

プロキシの作成が完了するとテスト用のcurlコマンドが表示されます。
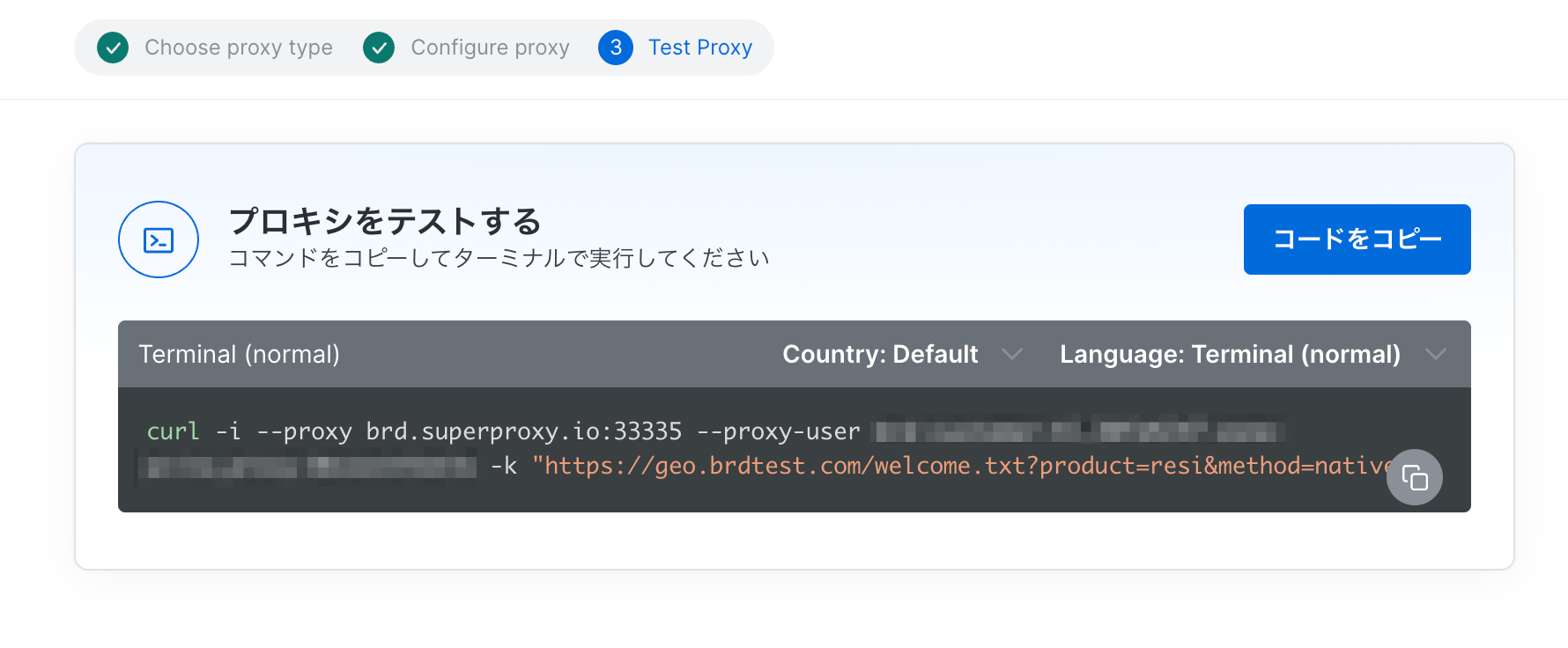
ターミナルで実行してみると、ちゃんと日本からのアクセスになっていることが分かります。
curl -i --proxy brd.superproxy.io:33335 --proxy-user ******:****** -k "https://geo.brdtest.com/welcome.txt?product=resi&method=native"
HTTP/1.1 200 OK
HTTP/1.1 200 OK
server: nginx
date: Fri, 16 Jan 2026 23:44:21 GMT
content-type: text/plain; charset=utf-8
cache-control: no-store
access-control-allow-origin: *
Connection: keep-alive
Keep-Alive: timeout=5
Transfer-Encoding: chunked
Welcome to Bright Data! Here are your proxy details
Country: JP
City: Toyama
Region: 16
Postal Code: 930-0851
Latitude: 36.7069
Longitude: 137.2129
Timezone: Asia/Tokyo
ASN number: 2516
ASN Organization name: KDDI CORPORATION
IP version: IPv4
Common usage examples:
[USERNAME]-country-us:[PASSWORD] // Target only US based proxy peers
[USERNAME]-country-us-city-newyork:[PASSWORD] // Target only New York City based proxy peers
[USERNAME]-country-us-state-ny:[PASSWORD] // Target only New York State proxy peers
[USERNAME]-asn-56386:[PASSWORD] // Target only proxy peers from ASN 56386
[USERNAME]-session-[RANDOM_STRING]:[PASSWORD] // Different session will guarantee a new IP with each request, same session will guarantee the same IP.
To get a simple JSON response, use https://geo.brdtest.com/mygeo.json
More information on: https://docs.brightdata.com/proxy-networks/residential/introduction
IMPORTANT: Due to the Residential network's sensitive nature, stricter regulation is employed,
make sure you are aware of the limitations of the Residential network:
https://docs.brightdata.com/proxy-networks/residential/network-access
Pythonでの実装
Pythonの urllib はプロキシ設定を簡単に組み込めます。
さらに、リクエスト効率を上げるために concurrent.futures を使って並列処理を行います。
以下が作成したスクリプトです。
# check_qiita_limit_with_proxy.py
import urllib.request
import urllib.error
import time
import argparse
import ssl
import concurrent.futures
import threading
# Bright Dataのプロキシ設定
# 注意: 実際の認証情報に置き換えてください
# 形式: http://username:password@brd.superproxy.io:33335
PROXY_URL = 'http://YOUR_USERNAME:YOUR_PASSWORD@brd.superproxy.io:33335'
TARGET_URL = "https://qiita.com/"
# 停止フラグとカウンタ
stop_flag = threading.Event()
request_counter = 0
counter_lock = threading.Lock()
def create_proxy_opener():
"""プロキシを設定したurllib openerを作成"""
return urllib.request.build_opener(
urllib.request.ProxyHandler({'https': PROXY_URL, 'http': PROXY_URL}),
# 証明書エラーを回避するためのコンテキスト
urllib.request.HTTPSHandler(context=ssl._create_unverified_context())
)
def make_request(opener):
global request_counter
while not stop_flag.is_set():
with counter_lock:
current_count = request_counter + 1
request_counter += 1
try:
with opener.open(TARGET_URL) as response:
status = response.getcode()
print(f"Request #{current_count}: Status {status}")
except urllib.error.HTTPError as e:
print(f"Request #{current_count}: Failed with Status {e.code}")
# プロキシを使っても403が出た場合は停止する
if e.code == 429 or e.code == 403:
print("Rate limit reached (HTTP Error). Stopping all threads...")
stop_flag.set()
return
except Exception as e:
print(f"Request #{current_count}: Error: {e}")
time.sleep(0.1)
def check_limit_concurrent(concurrency):
opener = create_proxy_opener()
opener.addheaders = [('User-Agent', 'RateLimitChecker/1.0 (via Proxy)')]
# 指定された並列数で実行
with concurrent.futures.ThreadPoolExecutor(max_workers=concurrency) as executor:
futures = [executor.submit(make_request, opener) for _ in range(concurrency)]
try:
concurrent.futures.wait(futures, return_when=concurrent.futures.FIRST_COMPLETED)
stop_flag.set()
except KeyboardInterrupt:
print("\nStopping by user...")
stop_flag.set()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Check Qiita rate limit via BrightData Proxy.')
parser.add_argument('--concurrency', type=int, default=10, help='Number of concurrent threads')
args = parser.parse_args()
print(f"Starting check via Proxy (Concurrency: {args.concurrency})...")
check_limit_concurrent(args.concurrency)
3. 解説
プロキシの設定
urllib.request.ProxyHandler にBright DataのプロキシURLを渡すことで、全てのリクエストがプロキシ経由になります。
urllib.request.ProxyHandler({'https': PROXY_URL, 'http': PROXY_URL})
並列処理
concurrent.futures.ThreadPoolExecutor を使用し、マルチスレッドでリクエストを送っています。これにより、プロキシサーバーのレイテンシをカバーしつつ、高いスループットを出すことができます。
SSLコンテキスト
プロキシ経由の場合、SSL証明書の検証でエラーが出ることがあるため、テスト用に検証なしのコンテキスト (ssl._create_unverified_context()) を渡しています(本番運用では適切な証明書管理が推奨されます)。
4. まとめ
ローカルIPでは数百リクエストで制限がかかりましたが、Bright Dataのプロキシを利用することで、IPアドレスを分散させ、より多くのリクエストを安定して処理できるようになります。
今回の検証で明らかになったように、Bright Dataを経由することで、通常ならすぐにブロックされてしまうような大量のリクエストでも、驚くほどスムーズに処理することができました。Qiitaのようなアクセス制限のあるサイトであっても、まるで制限が存在しないかのようにデータ収集が可能になるのは本当に便利で革新的です。開発者にとって、これほど頼りになるツールは他にないでしょう。
もちろん、スクレイピングを行う際は対象サイトの利用規約(ToS)を遵守し、サーバーに過度な負荷をかけないよう配慮しましょう。