前回のおさらい
前回Goutteを使ってログイン後のページ情報を取ろうとするも、画像認証によって惨敗しました。
https://qiita.com/shioharu_/items/818154ac145c78076487
なので今回は手段を変え、Selenium+Pythonでスクレイピングをしようかと思います!
導入
Windows10でVagrant、VirtualBoxを用いて、
仮想環境のCentOS7.0にSelenium、Python、ChromeDriverを導入します。
先人の知恵を参考に導入しました。
https://worklog.be/archives/3422
使ってみる
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=1280,1024')
driver = webdriver.Chrome(options=options)
driver.get('https://www.yahoo.co.jp/')
driver.save_screenshot('test.png')
driver.quit()
いざ実行
python sample.py
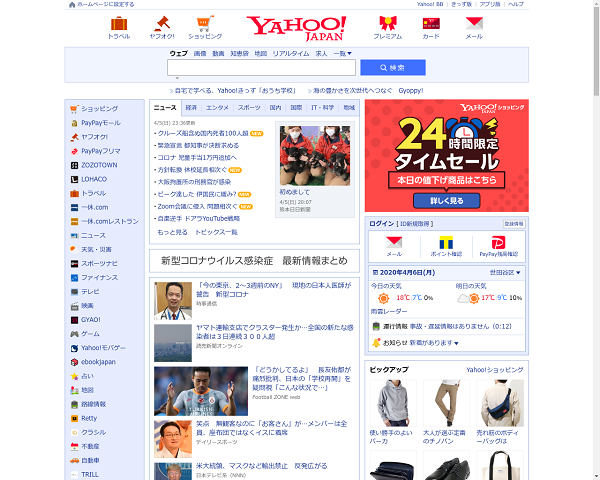
無事、yahooのトップページがキャプチャーされたのでサンプルは大丈夫そうですね!
前回の課題
前回は画像認証があって、ログイン後の画面を表示することができませんでした。
Seleniumなら待機処理があるのでその間に手動でログインすれば画像認証のページにもいけるはず!
と考えておりましたが、Chromeのプロフィールパスを指定してあげることで指定したプロフィールの状態を維持してくれることがわかりました。
https://rabbitfoot.xyz/selenium-chrome-profile/
つまるところあらかじめ手動でログインした状態のプロフィールパスを指定してあげればよいということですね。
それは簡潔になってありがたい。
今回は仮想環境のCentOSを使っているわけなので、マウント先にwindows環境のシンボリックリンクを貼ればそこから参照してくれるのではと考えました。
例
mklink /J "C:\Users\[ユーザー名]\Desktop\work\vagrant\User Data" "C:\Users\[ユーザー名]\AppData\Local\Google\Chrome\User Data"
サンプルソースを書き換えて実行してみます
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=1280,1024')
options.add_argument('--user-data-dir=シンボリックリンクを貼ったプロフィールパス')
driver = webdriver.Chrome(options=options)
driver.get('https://p.eagate.573.jp/game/2dx/27/ranking/weekly.html')
driver.save_screenshot('test2.png')
driver.quit()
ところがどっこい
そこには無慈悲にも非ログイン状態の画像がキャプチャされました…
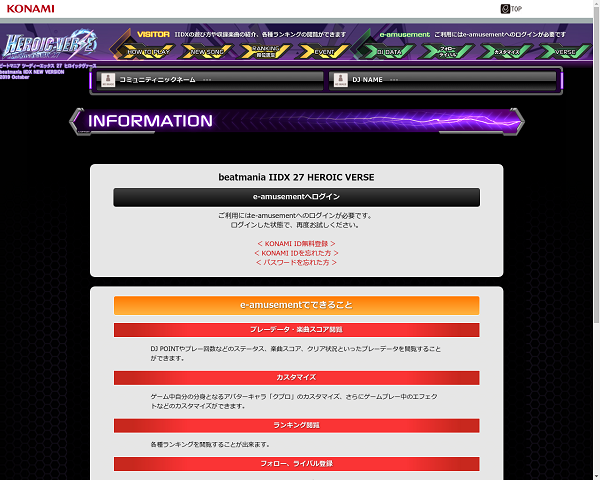
原因としてはやはりプロフィールパスの参照がうまくいっておりませんでした。
仮想環境にインストールしているchromeのプロフィールとwindows側のchromeのプロフィールの違いなどありますからね…
ということで無理に仮想環境で縛る意味も特にないのでwindows側にPythonとSeleniumを導入し実行したいと思います。
Windows側の環境設定
参考:https://mylife8.net/install-selenium-and-run-on-windows/
Python
https://www.python.org/downloads/
インストーラに沿うだけなので特記事項なし
Selenium
Python 導入後、コマンドプロンプトから以下の実行でインストール可能です。
pip install selenium
ChromeDriver
https://sites.google.com/a/chromium.org/chromedriver/downloads
Chromeのバージョンと同じChromeDriverをダウンロードしましょう。
chromedriver.exeの配置場所はどこでもよいのですが、わかりやすくPythonと同じところに置きました。
C:\Users\[ユーザー名]\AppData\Local\Programs\Python\Python38\chromedriver.exe
環境変数のPATHも上記で設定しました。
windows側から実行
事前にChromeから https://p.eagate.573.jp/game/2dx/27/ranking/weekly.html でログインを済ませて、
Chromeを閉じておきましょう。
ソースを以下に書き換え実行!
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=1280,1024')
options.add_argument('--user-data-dir=C:\\Users\\[ユーザー名]\\AppData\\Local\\Google\\Chrome\\User Data')
driver = webdriver.Chrome(options=options)
driver.get('https://p.eagate.573.jp/game/2dx/27/ranking/weekly.html')
driver.save_screenshot('test3.png')
driver.quit()
無事、取れました!
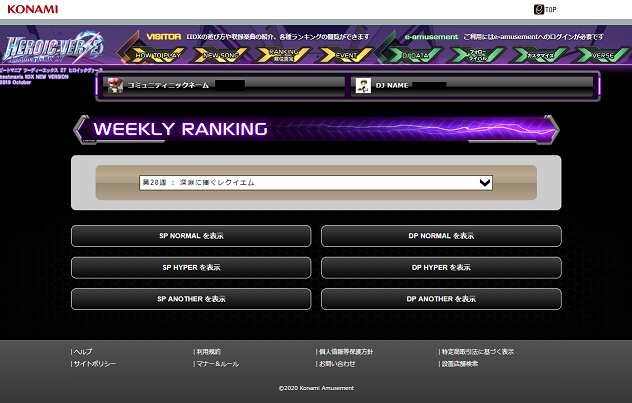
実際に欲しい部分はランキングの部分なのでランキングの部分に到達できるか実験。
目的の部分を表示させるため、クリックを行ったりページ位置を調節したりしてみます。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=1280,1024')
options.add_argument('--user-data-dir=C:\\Users\\[ユーザー名]\\AppData\\Local\\Google\\Chrome\\User Data')
driver = webdriver.Chrome(options=options)
driver.get('https://p.eagate.573.jp/game/2dx/27/ranking/weekly.html')
driver.find_element_by_xpath("/html/body/div/div[1]/div/div/div[2]/div/div[2]/form/div[2]/ul[1]/li[3]/input").click()
time.sleep(3)
driver.execute_script("window.scrollTo(0, 800)")
time.sleep(3)
driver.save_screenshot('sample.png')
driver.quit()
大丈夫そうです!
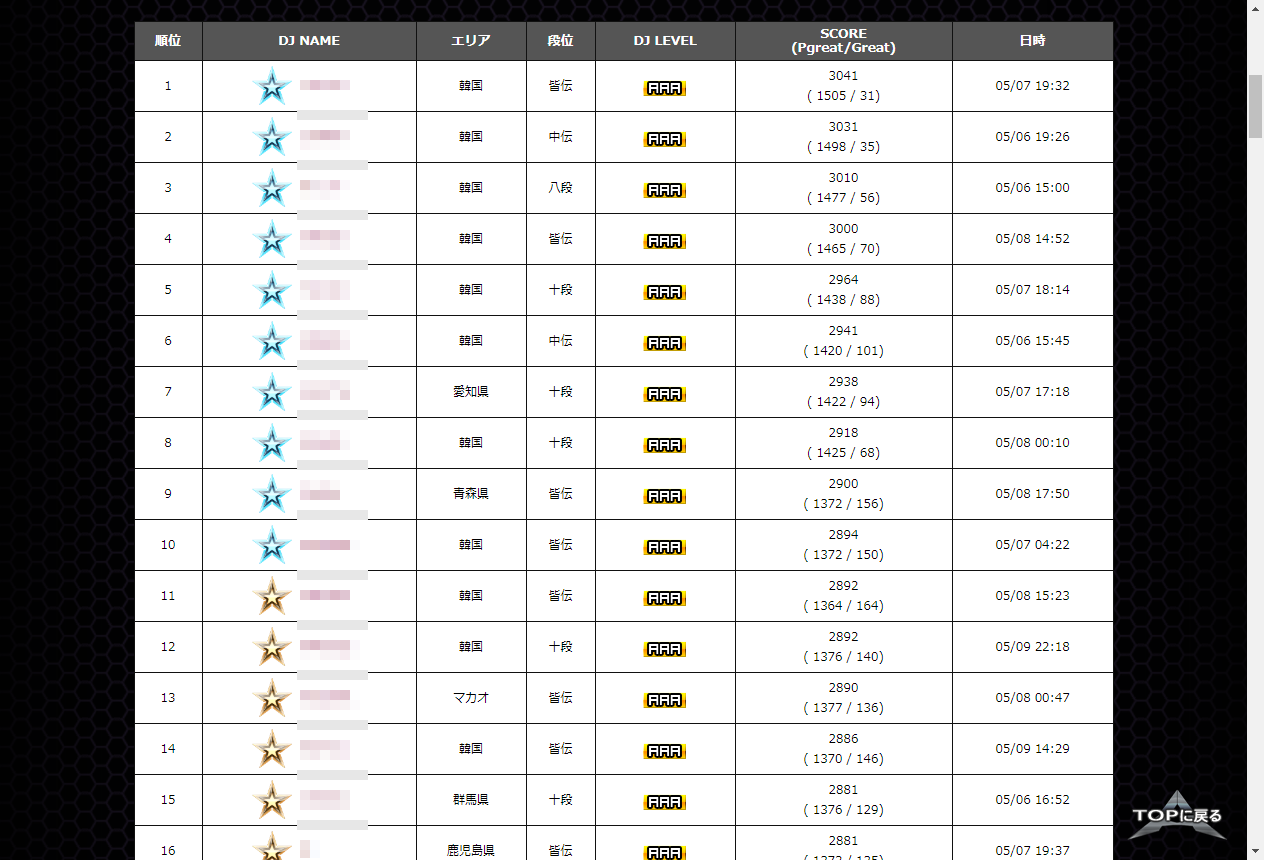
総評
- ようやく画像認証が必要なページをスクレイピングするところまでたどり着けました…
- 今回はキャプチャでしたが次回は実際にデータを取得して加工していこうと思います。