今回は第2回目です。
Pythonデータ分析勉強会 第1回資料
Pythonデータ分析勉強会 第2回資料
Pythonデータ分析勉強会 第3回資料
第1回 演習の答え
for i in range(1,11):
if i%2 == 0:
print(i,"G")
else:
print(i,"K")
もしくは
for i in range(10):
if (i+1)%2 == 0:
print(i+1,"G")
if (i+1)%2 == 1:
print(i+1,"K")
matplotlibで描画してみよう
Pythonでグラフの描画といえば、matplotlibが多く使われます。
データ分析では、データの可視化は避けては通れません。是非マスターしましょう。
試しにmatplotlibで描画してみましょう。
import matplotlib.pyplot as plt
A = [1, 2, 3]
plt.figure()
plt.plot(A)
plt.show()
1行目でmatplotlibを使えるように宣言しています。今のところ、グラフが使いたくなったら
「import matplotlib.pyplot as plt」をコピペしてください。
そして、最後の3行もセットで覚えてください。plt.plotに配列(A)を渡すだけでグラフを描画してくれます。
色々なグラフを描いてみよう
plt.plot()は折れ線グラフですが、他にもグラフは用意されています。
plt.scatter()は散布図です。
import matplotlib.pyplot as plt
A = [1, 2, 3]
plt.figure()
plt.scatter(range(3),A)
plt.show()
ポイントは「plt.scatter (x,y)」という形式にすることです。
xとyは配列にして、x[0]とy[0]がそれぞれ1番目のx座標、1番目のy座標に対応しています。
plt.bar()は棒グラフです。
import matplotlib.pyplot as plt
A=[1, 2, 3]
plt.figure()
plt.bar(range(3),A)
plt.show()
ポイントはplt.scatterと同じく、「plt.bar (x,y)」という形式にしてください。
グラフの体裁を整えよう
matplotlibでは、グラフのタイトルやx軸の単位を入れることが可能です。
慣れてくると、Excelより使いやすいです。
import matplotlib.pyplot as plt
A = [1, 2, 3]
plt.figure()
plt.scatter(range(3), A, s=100)
plt.title("Scatter", fontsize=50)
plt.xlabel("T", fontsize=20)
plt.ylabel("KN", fontsize=20)
plt.show()
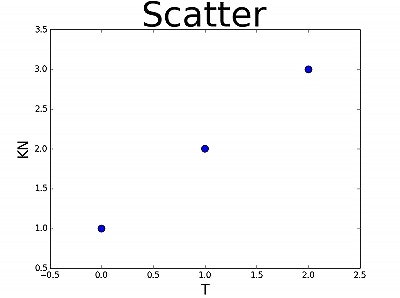
・plt.scatter(range(3), A, s=100 )で、「s=」は散布図の点のサイズを意味します。
上の図では、さきほどより点が大きくなりました。
・plt.title("Scatter", fontsize=50)は、""にタイトルを入れて表示することができます。
fontsizeは文字の大きさです。
・plt.xlabel("T", fontsize=20)とplt.ylabel("KN", fontsize=20)で、それぞれx軸、y軸に単位を入れられます。
numpyを使ってみよう
さあ、いよいよデータ分析の主役numpyの登場です!
numpyを使いこなさないと、データ分析はできないと言っても過言ではありません。しっかりと覚えましょう。
numpyは、基本的に配列と同じ形式をとります。
import numpy as np
A = np.array([1, 2, 3])
matplotlibと同じく、1行目でnumpyを使えるように宣言しています。
numpyを使いたくなったら、「import numpy as np」をコピペしてください。
ここでは、「np.array()」で宣言された配列を「np配列」と呼ぶことにします。
np配列にすることで、numpyのいろいろな機能が使えるようになります。
以下のように、np配列をprint文で出力してみます。
print(A)
出力↓
[1 2 3]
配列とは異なり、「,」がない状態で出力されます。
np配列にするメリット
np配列に変更することによって、データを行列形式で扱えるようになり、データのアクセスが楽になります。
試しに、以下の行列をnp配列で定義してみます。
A=
\begin{pmatrix}
1&2&3\\
10&20&30\\
100&200&300
\end{pmatrix}
import numpy as np
A = np.array([[1, 2, 3],[10, 20, 30],[100, 200, 300]])
例えば、1行目だけ取り出したい場合は、以下のようにコマンドします。
B = A[0,:]
print(B)
出力↓
[1 2 3]
例えば、2行目以降を取り出したい場合は、以下のようになります。
B = A[1:,:]
print(B)
出力↓
[[ 10 20 30]
[100 200 300]]
1列目だけ取り出したい場合は以下のようになります。
B = A[:,0]
print(B)
出力↓
[1 10 100]
単なる配列と比べ、コードが直感的に書けるようになります。
np配列を変更してみよう
次の行列をnp配列で定義して、「1」の部分だけを取り出してみましょう。
A=
\begin{pmatrix}
10&1&1&10\\
10&1&1&10\\
10&10&10&10\\
10&10&10&10
\end{pmatrix}
import numpy as np
A = np.array([[10, 1, 1, 10],[10, 1, 1, 10],[10, 10, 10, 10],[10, 10, 10, 10]])
B = A[0:2,1:3]
print(B)
出力↓
[[1 1]
[1 1]]
ある範囲の行(列)だけを取り出したい場合は、数字:数字という形式で書きます。
今回は、「1行目から2行目」かつ「2列目から3列目」なので、「A[0:2,1:3]」という形式になります。
列指定の「3」という数字はややこしいですが、:の後の数字は読みに行きません。
従って、「1:3」は、2列目と3列目は読み込みますが、4列目は読みに行きません。
ここらへんは慣れるしかないので、たくさんコードを書いて感覚を掴んでください。
試しに、1の部分を100に変えてみましょう。
A[0:2,1:3] = 100
print(A)
出力↓
[[ 10 100 100 10]
[ 10 100 100 10]
[ 10 10 10 10]
[ 10 10 10 10]]
一個ずつアクセスしなくても、一括で100に変えることが可能です。
csvファイルの入出力
numpyでは、csvファイルの保存・読み込みができます。
csvファイルは可読性も良いので2次元の行列を扱うときは、オススメです。
3次元以上の場合でも、保存・読み込み方法は用意されています。興味がある方は調べてみてください。
import numpy as np
A = np.array([[1, 1, 1],[1, 1, 1]])
np.savetxt("A.csv", A, delimiter=",")
上記のコードを入力することで、Aの中身が「A.csv」ファイルに保存されました。
A.csvファイルを探して、Excelなどで開いてみましょう。
また、下記のように「A.csv」を読み込むこともできます。
B = np.loadtxt("A.csv", delimiter=",")
Bの中身をプリント文で見てみましょう。
print(B)
出力↓
[[1. 1. 1.]
[1. 1. 1.]]
確かにA.csvの読み込みができました。
色々な関数
numpyには便利な関数が用意されています。
よく使う関数を列挙しておきます。
np.max()#最大値
np.min()#最小値
np.argmax()#最大値が入っている配列の番地
np.argmin()#最小値が入っている配列の番地
np.zeros((n, m))#中身が「0」で、n行-m列のnp配列を定義
np.ones((n, m)) #中身が「1」で、n行-m列のnp配列を定義
統計的な処理に役立つ関数もあります。
np.mean()#配列内の平均値
np.sum() #配列内の合計値
np.std() #配列内の標準偏差
np.cos()#コサイン(ラジアンで入力)
np.sin()#サイン(ラジアンで入力)
np.pi #円周率
MT法でよく使う特殊な関数も紹介します。
np.dot() #行列の積
np.corrcoef() #相関係数を計算
np.linalg.inv() #逆行列の計算
data.transpose()#転置行列
最後の転置行列は「data」のところに、転置したい行列を入れてあげます。
numpyにかかれば、特殊な計算も1行で実行できて、楽ちんです!
shapeについて
shapeはnp配列の形を知りたいときに使用します。
例えば、以下のnp配列の形を知りたいときは、「.shpae」とコマンドします。
\begin{pmatrix}
1&1&1\\
1&1&1\\
1&1&1
\end{pmatrix}
import numpy as np
A = np.ones((3,3))
print(A.shape)
出力↓
(3, 3)
「3行、3列」と出力されました。
shapeはコードにバグがないか確認するときによく使われます。
例えば、Aに今日のデータが入っており、Bが昨日のデータとして、AとBを合体させ
Cに代入することを考えます。そして、Cがどんな形をしているか確認するときに
shapeを使います。
A = range(100)
B = range(100)
C = []
C.append(A)
C.append(B)
C = np.array(C)
print(C.shape)
出力↓
(2, 100)
ちゃんと、Cは「2行100列」になっていることを確認できました。
上記の場合、Cの中身は目で追って分かる範囲ですが、appendを重ねていくと
目で見ても分からなくなってきます。そんなときはshapeを使うと、Cの中身が
確認できます。
たまに使う「reshape」もご紹介しておきます。reshapeはその名の通り、np配列の形を
変更するものです。試しに、先ほどのCを「1行、200列」に変更してみます。
C = C.reshape((1,200))
print(C.shape)
出力↓
(1, 200)
reshapeは、matplotlibで可視化する場合によく使われます。
plt.plot()では、np配列の形を整えて与えないと、うまくグラフ化してくれません。
自作関数を作ってみよう
同じプロセスを何回も行うときは、自作関数を作りましょう。
その方が、コードが見やすくなります。
自作関数は以下の形式で書きます。
def f(x):
return r
fは関数名で、任意の文字列が入れられます。
また、xは自作関数がもらう変数で、好きな文字列で結構です。一個でも良いですし、複数でも可です。
returnは返す値で、数字でも配列でも大丈夫です。返す値がない場合は、returnはなくてもOKです。
試しに、2乗を計算する自作関数を書いてみましょう。
def nijou(x, y):
result1 = x**2
result2 = y**2
return result1, result2
A, B = nijou(2, 3)
print(A)
print(B)
1行目から4行目までが自作関数です。1行目で関数を定義しています。
2~3行目では自作関数内の計算方法を書いています。4行目では計算結果を返しています。
6行目で自作関数を呼びだしています。ここでは数字の「2」と「3」を自作関数に渡しています(2→x、3→y)。
そして、AとBにはresult1とresult2の値が返ってきます。
出力↓
4
9
**自作関数は事前に定義しないといけません。**従って、1行目の前にA, B = nijou(2, 3)と入れてもエラーになります。
また、自作関数内で変数を変更しても、自作関数内でしか反映されません。
自作関数外でも反映させたい場合はglobalを使います。
下記のコードで、Aはグローバル変数ですが、Bはグローバル変数ではないため変更されません。
A = 1
B = 1
def modify():
global A
A = 10
B = 10
modify()
print("A",A)
print("B",B)
出力↓
('A', 10)
('B', 1)
globalの使用は推奨されていません。その理由は、変数の変更は自作関数内で完結させた方が、
他への影響が少なく、誤動作が防げるためです。
しかし、globalを使わざるを得ない場合は、global変数を大文字にするなど、工夫することが
推奨されています。(MT法のコードでは大文字にしていません。すみません。)
演習
その1
・「A = np.sin(2np.pinp.array(range(100))/100)」で発生させたサインカーブを、正と負に分けて
グラフ化しましょう。
・A、「正」データ、「負」データを、csvファイルで保存しましょう。
<ヒント>
・サインカーブの中身を見る際は、for文を使いましょう。(for i in A:)
・正と負を分けるときは、if文を使いましょう。
・データの仕分けは、空の配列[]を用意して追加しましょう。
・plt.plot()では、「c="red"」で赤いグラフを描画することもできます。
<正解出力>
・「生」のデータ
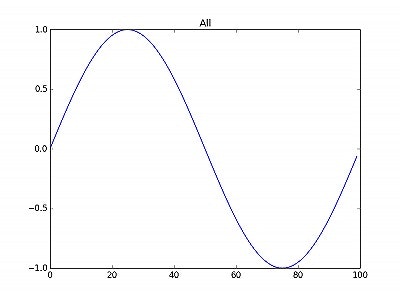
・「正」のデータ
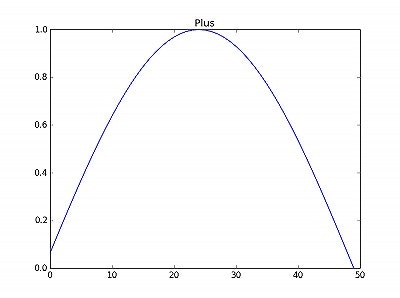
・「負」のデータ
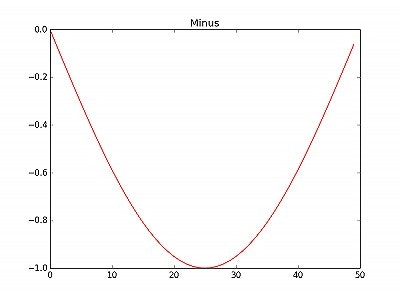
その2
・演習その1で作成したcsvファイルを読み込み、それぞれのグラフを描画しましょう。
・さらに、「csvファイル読み込み部分」と「グラフの描画部分」を同時に処理する自作関数を組み込んでみましょう。
(グラフの線の色は、全て同じ色で結構です。)
<ヒント>
・自作関数には「"All"」等、文字列を与えましょう。
・自作関数では、nameで文字列を受け取り、np.loadtxt(name + ".csv", delimiter=",")で
csvファイルを読み込みましょう。
<正解出力>
演習その1と同じ出力結果になります。
答えは第3回資料をご覧ください。