はじめに
ごめんなさいタイトル盛りました。ただのPythonでのWEBスクレイピング記事です。
(一応モテるための情報収集をしよう・・・というコンセプトです)

この記事で説明しているアプリケーションでは以下をポイントにしています。
- PythonでのWEBスクレイピングの実装
- Pythonでの非同期処理
- Pythonでの追加要望(スクレイピング対象の追加)に強い実装
※ちなみに「WEBスクレイピング」とはWEBサイトから情報を抽出するコンピュータソフトウェア技術のことです。
アプリケーションを作ろうと思った経緯
ここは読み飛ばしてもらっても構わないです。技術的な話は一切ないです。長い上にほぼ雑談です。
何を作ろうか
会社ではC#やJavaでの開発が多いので、プライベートでPythonで何か作りたいなーと思い立ちました。Python初心者ですがどうせなら楽しく実際に使えるものが出来たらいいなと思い**「これがあったら便利だな」**を考えたのですが・・・
やはり
「モテる男になるためのツール」
があったら最高だなと。
お遊びで作るアプリケーションだしそのくらいが気持ち的にも良いですよね?
ネタとして友達や同僚にも話しやすいですし。
さて、どんなアプリケーションを作るか。まず方向性を情報収集系のアプリケーションか記録系のアプリケーションに絞りました。
アイデアを書きだしてみたのですが、記録系のアプリケーションはありきたりのものしか思いつかなかったです。髪型管理とかスタイル管理とか。それってスマホアプリでありそうだなと。そんなこんなで割とすぐに情報収集系のアプリケーションに舵を切りました。
PythonでWEBスクレイピングって定番ですし、一度作ってみたかったというのも理由のひとつです。
WEBスクレイピングの対象をどうするか
やっぱり話題が豊富な男性はモテますよね?
「女性との会話が弾む話題」を色々とネットで調べてみると**「休日の過ごし方」、「(相手の)趣味」、「グルメ・スイーツ」、「お互いの持ち物」**などが出てきました。なるほど確かに。

熟考の末、以下の理由から**「グルメ・スイーツ」**をスクレイピング対象とすることに決定しました。
1.「とにかく無難。多くの人にとって共通の話題になる。」
⇒とにかく無難です。食に興味のない人間は少ないです。
2.「知っていて損はない。」
⇒ひとりでだって美味しい情報は使えます。
3.「私の周りの女性へのヒアリングの結果。」
⇒休日の過ごし方とか聞くな。趣味の話とか面倒臭い。だそうです。
4.「リスクが少ない。」
⇒これが一番大事だと思います。
女性との会話について調べると共通してどのサイトにも
**「仕事や趣味の自慢話や知識をひけらかすことはNG。」**と書いてありました。
変な話をしてしまって印象を悪くするくらいなら無難な話題で盛り上がりましょう。
5.「共感を生みやすい。」
⇒女性は共感する(される)と一気に心の距離が縮まるらしいです。
服や化粧品の話題は共感出来ませんけどスイーツなら出来ます!
6.「女性はグルメ・スイーツの話が好き。」
⇒はい。私の偏見です。
とまぁここまで説明すれば食べ物の話題が最強だとわかってもらえたと思います。
このアプリケーションを作成するにあたっての事前調べのしすぎで脳内でモテ男になった私が言っているので間違いないです。
本記事のアプリケーションを使って取得したニュース記事を先にいくつか紹介したいと思います。
どうです。これで会話に困ることはないとわかったはず!
ふぅ。やっとやることが決まったので次に行こうと思います。
そうです**「どのサイトを対象とするか」**です。お察しの通りまだまだ雑談は続きます。。。
どのサイトを対象とするか
これも色々と調べました。
女性目線の情報を知っておいた方がいいよなーと考え、知人の女性に聞くと大半が**「インスタグラムかTwitterで調べる」とのこと。
インスタグラムもTwitterもWEBスクレイピングの定番かもしれませんが「情報収集する軸」**が決められませんでした。
- いいね数が多い「グルメ・スイーツ」というキーワードの投稿でスクレイピングする
- インフルエンサ―と呼ばれる人の「グルメ・スイーツ」というキーワードの投稿でスクレイピングする
- 最新の「グルメ・スイーツ」というキーワードの投稿でスクレイピングする
等を考えましたがイマイチまとまらなかったので今回は自分の中で却下としました。
**「インフルエンサーの○○さんが渋谷の××ってお店紹介してたんだー」**とかおじさんに言われても困ると思いますし。
ヒアリングの結果と独自に調べた結果で対象サイトを以下としました。
対象のサイト1:MERY
ヒアリングで名前があがった、女性に人気のある(らしい)サイト。
対象のサイト2:macaroni
女性に人気のある(らしい)日本最大級の食特化型WEBメディア。
対象のサイト3:LOCARI(ロカリ)
女性向けキュレーションサイトで調べていたら色々なサイトで紹介されていたので。
対象のサイト4:livedoor
「グルメ ニュース」でGoogle検索すると一番上位に表示されるため。
対象のサイト5:ロケットニュース24
きっとモテる男に必要な情報はすべてここにあるはず。
※面白系ニュース中心のサイトです。
上記5サイトは女性目線も面白系も網羅していて、オシャレなお店からコンビニスイーツまで幅広く紹介しているのでなかなか良い感じです。
アプリケーションの説明
やっとアプリケーション自体の話です。
順を追って説明したいと思います。
現時点で何を作ったか
一旦動くアプリケーションは作成済ですが、実はまだまだ作成途中です。
まずは、ローカルPCでPythonプログラムを実行してWEBスクレイピング結果をCSV出力するアプリケーションを作成しました。
今後サーバレスで定期実行(AWSのLambda等)してデータを取得、それを表示するWEBサイトを作成する予定です。
WEBスクレイピングの注意点
WEBスクレイピングを実装したことのある人ならわかると思いますが、情報を抽出するために見なければいけないタイトルやリンクが取得出来るタグはサイトによってバラバラです。
<div class="list">
<div class="item">
<a href="https://xxxxxx/xxxxxx">タイトル</a>
</div>
<div class="item">
<a href="https://xxxxxx/xxxxxx">タイトル</a>
</div>
</div>
<ul>
<li>
<a href="https://xxxxxx/xxxxxx">
<h3>タイトル</h3>
</a>
</li>
<li>
<a href="https://xxxxxx/xxxxxx">
<h3>タイトル</h3>
</a>
</li>
</ul>
こんな感じで。
サイト1ではリストをdivで表していますが、サイト2ではulとliで表しています。
そのため、要素の抽出処理を分ける必要があります。
そこで何も考えずに実装をすると以下のようなコードが出来てしまいます。
if url == サイト1:
サイト1の情報を抽出する処理
elif url == サイト2:
サイト2の情報を抽出する処理
elif url == サイト3:
サイト3の情報を抽出する処理
追加のサイトが増えるたびに分岐を追加するのは密結合で保守性が悪いなと感じます。
そこで**「サイト単位でクラスを分け、サイトが追加されたらクラスを追加するだけで他のコードを一切修正しない方法」**を考えました。
クラスを追加するだけで他のコードを一切修正しない
サイト単位でクラスを分け、サイトが追加されたらクラスを追加するだけで他のコードを一切修正しない方法とは何かを説明します。
フォルダ構成
まず、フォルダ構成は以下のようにしました。
src
├── news_site
│ ├── livedoor.py
│ ├── locari.py
│ ├── macaroni.py
│ ├── mery.py
│ └── rocketnews24.py
├── main.py
└── news_get_common.py
フォルダ**「news_site」が今回の実装のポイントです。
スクレイピング対象の「サイト名のファイル」が格納されています。
このファイルを増やすだけで自動的に**取得結果のニュース記事が(追加されたサイトの分)増える仕組みです。
図にするとこんなイメージです。
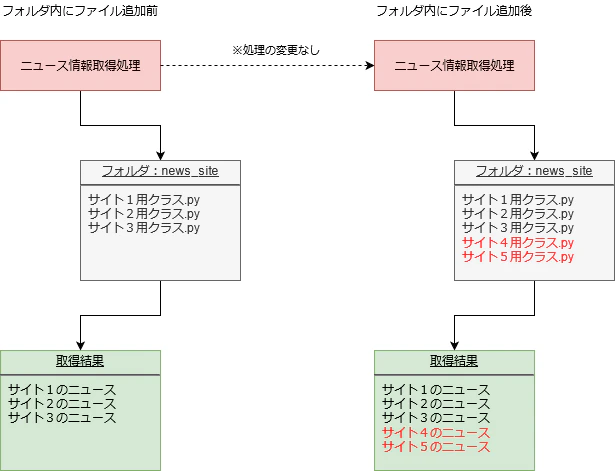
・・・上手く図に出来てない。けどこんなイメージです。
上記の図でサイト用クラス.pyを2つ増やしたことで取得結果のサイトも2つ増えています。
サイト名のファイル(/news_site/xxxx.py)
実際に**「サイト名のクラスファイル」**の中身を見ていきます。
import news_get_common
from bs4 import BeautifulSoup
import requests
class mery:
"""
meryのグルメニュースを取得するクラス
"""
URL = 'https://mery.jp/gourmet/'
QUERY = '?page='
SITE = 'mery'
def get_list(self, soup):
return soup.select('div.article_list > div.article_list_content')
def get_title(self, element):
return (element.select_one('h3 > a').text).strip()
def get_url(self, element):
return element.select_one('h3 > a').get("href")
def get(self):
"""
ニュース取得のメイン関数を呼ぶだけ
"""
return news_get_common.get(self.URL, self.QUERY, self.SITE, self.get_list, self.get_title, self.get_url)
import news_get_common
from bs4 import BeautifulSoup
import requests
class macaroni:
"""
macaroniのグルメニュースを取得するクラス
"""
URL = 'https://macaro-ni.jp/category/food/'
QUERY = '?page='
SITE = 'macaroni'
def get_list(self, soup):
return soup.select('ul.articleList > li')
def get_title(self, element):
return (element.select_one('p.articleList__title').text).strip()
def get_url(self, element):
return 'https://macaro-ni.jp' + element.select_one('a').get("href")
def get(self):
"""
ニュース取得のメイン関数を呼ぶだけ
"""
return news_get_common.get(self.URL, self.QUERY, self.SITE, self.get_list, self.get_title, self.get_url)
import news_get_common
from bs4 import BeautifulSoup
import requests
class locari:
"""
locariのグルメニュースを取得するクラス
"""
URL = 'https://locari.jp/post_categories/27'
QUERY = '?page='
SITE = 'locari'
def get_list(self, soup):
return soup.select('ul.post-list > li.post')
def get_title(self, element):
return (element.select_one('div.post__title').text).strip()
def get_url(self, element):
return 'https://locari.jp' + element.select_one('a').get("href")
def get(self):
"""
ニュース取得のメイン関数を呼ぶだけ
"""
return news_get_common.get(self.URL, self.QUERY, self.SITE, self.get_list, self.get_title, self.get_url)
import news_get_common
from bs4 import BeautifulSoup
import requests
class livedoor:
"""
livedoorのグルメニュースを取得するクラス
"""
URL = 'https://news.livedoor.com/topics/category/gourmet/'
QUERY = '?p='
SITE = 'livedoor'
def get_list(self, soup):
return soup.select('ul.articleList > li')
def get_title(self, element):
return element.find('h3').text.strip()
def get_url(self, element):
return element.a['href']
def get(self):
"""
ニュース取得のメイン関数を呼ぶだけ
"""
return news_get_common.get(self.URL, self.QUERY, self.SITE, self.get_list, self.get_title, self.get_url)
import news_get_common
from bs4 import BeautifulSoup
import requests
class rocketnews24:
"""
rocketnews24のグルメニュースを取得するクラス
"""
URL = 'https://rocketnews24.com/category/%E3%82%B0%E3%83%AB%E3%83%A1/'
QUERY = 'page/'
SITE = 'rocketnews24'
def get_list(self, soup):
return soup.select('#main-content > div.post')
def get_title(self, element):
return (element.select_one('h2').text).strip()
def get_url(self, element):
return element.select_one('a').get("href")
def get(self):
"""
ニュース取得のメイン関数を呼ぶだけ
"""
return news_get_common.get(self.URL, self.QUERY, self.SITE, self.get_list, self.get_title, self.get_url)
上記のクラスには共通して以下の関数を定義しています。
- def get_list(self, soup)
- def get_title(self, element)
- def get_url(self, element)
- def get(self)
JavaやC#のインターフェイスですね。ポリモーフィズムってやつです。
同じ名前の関数があることで、クラスの指定さえ切り替えれば「get()を実行する」コードはそのまま使えます。
それぞれのクラスに定義されている関数に独自の抽出処理を記載しています。
Pythonでは**「定義した関数をそのまま引数として渡し、渡した先で実行する」ということが可能です。
news_get_common.get(self.URL, self.QUERY, self.SITE, self.get_list, self.get_title, self.get_url)はまさに各クラス内で定義した関数を引数として渡しています。
そのため、どのクラスから呼ばれたとしても呼ばれた側は「引数にある関数をただ実行するだけ」**でいいのです。
親処理(main.py)
次に、各サイト名クラスを実際に呼び出している親処理を見てみます。
import importlib
import asyncio
import pathlib
import pandas
import csv
import itertools
async def get_news(loop, class_name):
"""
ニュース情報取得関数
"""
module = importlib.import_module('news_site.' + class_name)
class_obj = getattr(module, class_name)
return await loop.run_in_executor(None, class_obj().get)
def get_py_list(loop):
"""
pythonプログラムリスト取得関数(スクレイピング対象リスト取得)
"""
f_list = []
for py_file in pathlib.Path('news_site').glob('*.py'):
# ニュース情報取得
f_list.append(get_news(loop, py_file.name.replace('.py', '')))
return f_list
def main():
"""
ページ内のニュース情報取得関数
"""
loop = asyncio.get_event_loop()
result = loop.run_until_complete(asyncio.gather(*get_py_list(loop)))
df = pandas.io.json.json_normalize(sorted(list(itertools.chain.from_iterable(result)), key=lambda x:x['number']))
df.to_csv('data.csv', index=False, encoding='utf-8', quoting=csv.QUOTE_ALL)
if __name__ == "__main__":
main()
コードを読むだけだと何をしているかわかりにくいですよね。ひとつずつ説明します。
メイン関数(エントリーポイント)
**def main()**の内の話です。
ここではニュース情報取得処理の呼び出しと、CSV出力を行っています。
loop = asyncio.get_event_loop()
result = loop.run_until_complete(asyncio.gather(*get_py_list(loop)))
上記コードで、非同期にてニュース情報取得処理を呼び出しています。
df = pandas.io.json.json_normalize(sorted(list(itertools.chain.from_iterable(result)), key=lambda x:x['number']))
df.to_csv('data.csv', index=False, encoding='utf-8', quoting=csv.QUOTE_ALL)
上記コードで、取得したニュースリストをCSV出力しています。
スクレイピング対象のサイトクラスリスト取得
**def get_py_list(loop)**内の話です。
def get_py_list(loop):
"""
pythonプログラムリスト取得関数(スクレイピング対象リスト取得)
"""
f_list = []
for py_file in pathlib.Path('news_site').glob('*.py'):
# ニュース情報取得
f_list.append(get_news(loop, py_file.name.replace('.py', '')))
return f_list
for py_file in pathlib.Path('news_site').glob('*.py'):にて、フォルダ「news_site」内のPythonファイルを抽出し、for文でそれぞれに処理を行っています。
f_list.append(get_news(loop, py_file.name.replace('.py', '')))にて、ファイル名から拡張子を除去した文字列を引数として関数「get_news」を呼び出しています。
ニュース情報を非同期で取得
**async def get_news(loop, class_name)**内の話です。
async def get_news(loop, class_name):
"""
ニュース情報取得関数
"""
module = importlib.import_module('news_site.' + class_name)
class_obj = getattr(module, class_name)
return await loop.run_in_executor(None, class_obj().get)
module = importlib.import_module('news_site.' + class_name)にて、クラスを動的にimportしています。
この仕組みのおかげでサイトを追加するたびに「main.py」にimport文を書かなくて済みます。
class_obj = getattr(module, class_name)にて、クラスのインスタンスを生成しています。
return await loop.run_in_executor(None, class_obj().get)にて、生成したクラスのインスタンスの関数「get」を実行し、返却しています。
図にするとこんなイメージです。
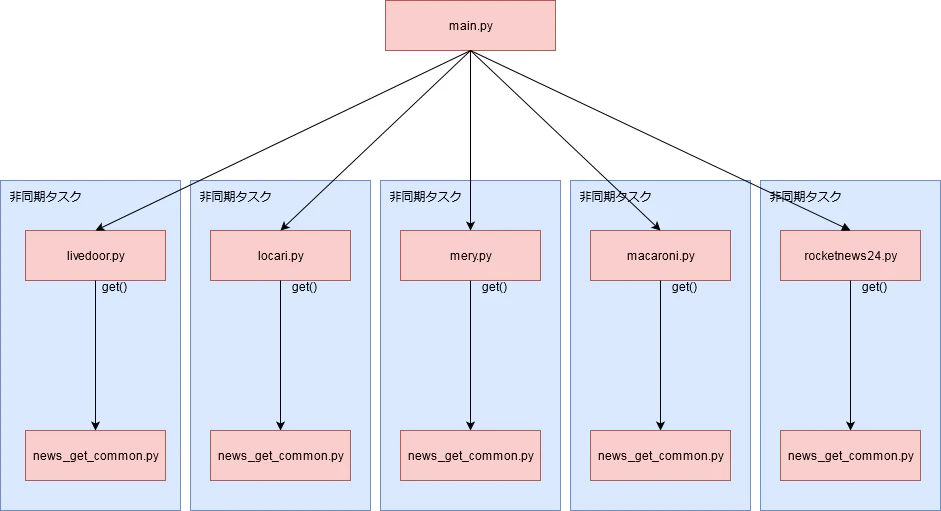
※非同期処理を説明する予定でしたが長くなってきたので割愛します。というかあまり速度が出ていないので非同期処理を見直す必要があるかもしれません。。。
ニュース情報を取得する共通処理(news_get_common.py)
最後に、ニュース情報を取得する共通処理のコードを載せておきます。
main.py ⇒ 各サイトクラス.py ⇒ news_get_common.py
と流れるnews_get_common.pyです。
requestsとBeautifulSoupを使ってWEBスクレイピングを行い、各サイトクラスから渡された関数を用いて情報を取得しています。
from bs4 import BeautifulSoup
import requests
MAX_COUNT = 30
MAX_PAGE = 20
def get_news_on_page(site_name, get_list, get_title, get_url, soup, number):
"""
ページ内のニュース情報取得関数
"""
# ニュースリストの取得(各クラスのリスト取得関数を呼び出し)
news_list = get_list(soup)
result_list = []
for element in news_list:
# 取得情報の設定(各クラスのタイトル取得関数、URL取得関数の呼び出し)
news = {
'title' : get_title(element),
'url' : get_url(element),
'number' : number,
'site' : site_name
}
result_list.append(news)
number += 1
if number > MAX_COUNT:
break
return result_list
def get(url, paging_query_string, site_name, get_list, get_title, get_url):
"""
ニュース取得のメイン関数
ページングも考慮
"""
result_list = []
number = 1
for num in range(1, MAX_PAGE):
target_url = url
if num != 1 :
# 次ページのURLを生成
target_url += paging_query_string + str(num)
# ページ情報の取得
response = requests.get(target_url, headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0'})
soup = BeautifulSoup(response.text, 'html.parser')
news = get_news_on_page(site_name, get_list, get_title, get_url, soup, number)
result_list.extend(news)
number = len(result_list) + 1
if number > MAX_COUNT:
break
return result_list
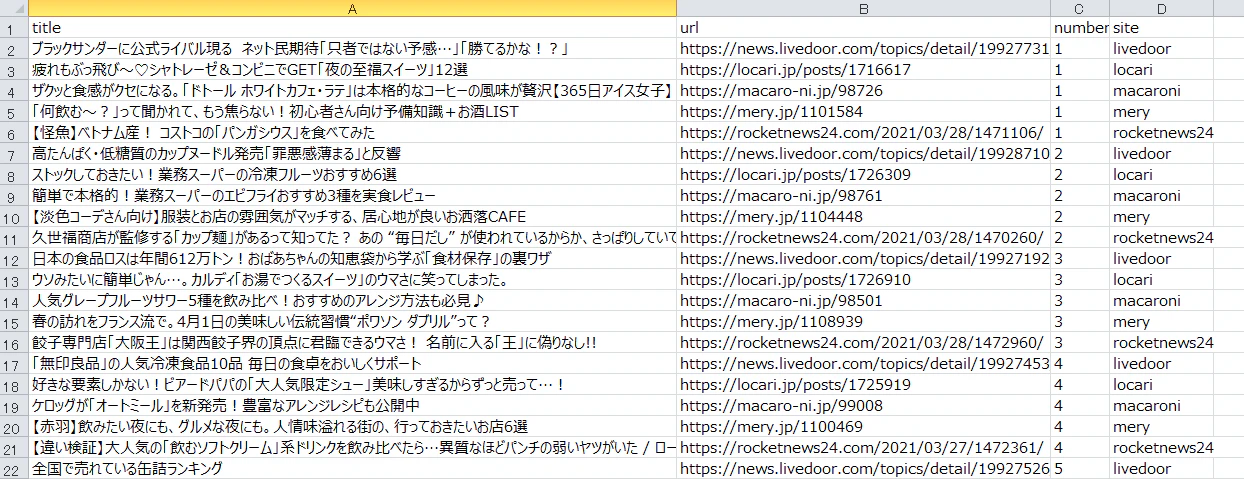
実行結果
CSVで表示 ※一部のみ表示
"title","url","number","site"
"ブラックサンダーに公式ライバル現る ネット民期待「只者ではない予感…」「勝てるかな!?」","https://news.livedoor.com/topics/detail/19927731/","1","livedoor"
"疲れもぶっ飛び〜♡シャトレーゼ&コンビニでGET「夜の至福スイーツ」12選","https://locari.jp/posts/1716617","1","locari"
"ザクッと食感がクセになる。「ドトール ホワイトカフェ・ラテ」は本格的なコーヒーの風味が贅沢【365日アイス女子】","https://macaro-ni.jp/98726","1","macaroni"
"「何飲む〜?」って聞かれて、もう焦らない!初心者さん向け予備知識+お酒LIST","https://mery.jp/1101584","1","mery"
"【怪魚】ベトナム産! コストコの「パンガシウス」を食べてみた","https://rocketnews24.com/2021/03/28/1471106/","1","rocketnews24"
"高たんぱく・低糖質のカップヌードル発売「罪悪感薄まる」と反響","https://news.livedoor.com/topics/detail/19928710/","2","livedoor"
"ストックしておきたい!業務スーパーの冷凍フルーツおすすめ6選","https://locari.jp/posts/1726309","2","locari"
"簡単で本格的!業務スーパーのエビフライおすすめ3種を実食レビュー","https://macaro-ni.jp/98761","2","macaroni"
"【淡色コーデさん向け】服装とお店の雰囲気がマッチする、居心地が良いお洒落CAFE","https://mery.jp/1104448","2","mery"
"久世福商店が監修する「カップ麺」があるって知ってた? あの “毎日だし” が使われているからか、さっぱりしていて上品な仕上がりだぞ","https://rocketnews24.com/2021/03/28/1470260/","2","rocketnews24"
"日本の食品ロスは年間612万トン!おばあちゃんの知恵袋から学ぶ「食材保存」の裏ワザ","https://news.livedoor.com/topics/detail/19927192/","3","livedoor"
"ウソみたいに簡単じゃん…。カルディ「お湯でつくるスイーツ」のウマさに笑ってしまった。","https://locari.jp/posts/1726910","3","locari"
Excelで表示
さいごに
無事モテるための話題収集が出来ました。
このアプリケーションではサイトクラスの中身を変えるだけで、抽出対象を政治ニュースやスポーツニュースに変更することも簡単に出来ます。
なのでわりと汎用性が高く作れたかなと思います。
しかし、Pythonはほぼ初心者なので変なコーディングを見つけたりこうした方が良いというアドバイスがございましたらコメントいただけると喜びます!
今後、自分用にスクレイピング結果を一覧表示してリンクに飛べるWEBサイトを作成予定です。
この記事の反応が多少なりとも良かったら頑張ってみなさんにも公開するかもしれません。
モテる男になるためのPythonアプリケーション・・・やっぱり盛りすぎましたね。
読んでくださってありがとうございます!
以上です。
おわり。