はじめに
これはレイトレ合宿9のアドベントカレンダーの記事です。
最近になってもまだまだ面白いBVHの(またはそれに関連する)論文が出ています。
- Subspace Culling for Ray-Box Intersection
- Performance Comparison of Bounding Volume Hierarchies for GPU Ray Tracing
- Stochastic Subsets for Bounding Volume Hierarchy (BVH) Construction
- Fast Triangle Pairing for Ray Tracing
- Parallel Transformation of Bounding Volume Hierarchies into Oriented Bounding Box Trees
- Real-Time Ray Tracing of Micro-Poly Geometry with Hierarchical Level of Detail
最初のは@Ushioさんの論文で、自分も似たようなものを実装したことがあります。プロダクションで採用するには、カーブ(髪の毛など)を扱えること、またモーション・ブラーができること、構築が速いこと(最初のピクセルがレンダリングされるまでのtime to first pixelと呼ばれる時間が短い)、構築時に使用されるメモリが少ないこと、などが必須の条件として挙げられます。ですので、事前計算に時間がかかるものは敬遠されてしまいます。また可能であれば全てのシーンで高速になって欲しいのですが、改善の余地は十分にあると思うので、今後の発展に期待です。
2つ目はいろいろな構築の手法の比較を行ったもので、Simmulated Annealingを用いた新しい方法についての記載があります。
3つ目は大量の三角形を間引いて、それに対してBVHを構築し、残りの三角形は構築されたBVHに流し込むといった感じで動作します。ミニ・ツリーを並列で構築するBonsaiと高速化の原理は似ていますが、BonsaiはpublicなGPUでの実装がないという理由で比較がありませんでした。個人的にはBonsaiで良いような、という気がしています。興味深かったのは構築が高速になるにも関わらずBinningよりもレイ・トレーシングのパフォーマンスが上がるシーンがいくつかあったことでしょうか。
4つ目はレイと三角形のペアとの交差判定機能を持つシステムのために、高速によいペアを作る簡単な手法が手法が書かれています。今回解説する論文でもQuadを使っているので、この手法も役立ちそうです。
5つ目は既存のAABBを用いたBVHをOBBを用いたBVHへと高速に変換する方法について書かれています。DiTOを用いて長い毛の生えた羊のモデルでは10倍ほどのレンダリングの高速化を達成していますが、利用は毛に限定されているわけではなく、軸平行に作られていない建築物といった様々なモデルで用いることができます。ノードを並べ替えたり、トポロジを変えたり、入力されたBVHを別のBVHと変換するいわば「BVH Filter」の一種と考えることができます。ハードウェアでのOBBのサポートがあると良さそうです。
と、ここまでは自分にとってあまり新しい概念がなかった(もちろんどれも面白いし、OBBのは実装したい)のですが、一番最後に挙げたものに特に興味をそそられたので、少し解説してみたいと思います。ここ最近Tessellation-Free Displacement Mappingやμ-Meshesのように膨大な数の三角形を限られたメモリで高速に扱う手法がいくつか登場していますが、この論文は、vector displacementのみしか扱えない、1つのベースメッシュの三角形の分割数に上限がある、といった既存手法が持つ制約と無縁で、機械学習の助けも借りずに、単純に膨大な数の三角形をなんとか高速にレンダリングするといったもので、少し毛色が異なります。
"Real-Time Ray Tracing of Micro-Poly Geometry with Hierarchical Level of Detail" はどんなものか?
概要
ゲーム業界の方はご存知の通り、Naniteは膨大な三角形をLODを使って非常に高速にレンダリングします。正確にはラスタライズを行います。この論文ではNaniteのように膨大な三角形をレイ・トレーシングによってレンダリングすることを目指しています。
課題
Naniteのようなスタイルでレイ・トレーシングを行うには、三角形(ないしはQuad、この解説では三角形に統一)を階層的にクラスタリングして、視点から近い場所を高解像度で遠い場所は低解像度で表現する必要がありますが、三角形の数が膨大である場合、LODの選択と、選択されたLODにおけるジオメトリに対してBVHの構築を高速に行うことは容易ではありません。
予備知識
この論文ではPLOCと呼ばれる方法を用いて、クラスタをまとめていきます。PLOCは与えられたクラスタの集合から「両思い」であるクラスタのペアを選択して取り除き、取り除いた各ペアをマージして、マージしたものを再度クラスタの集合に戻す、といった具合に動作します。ここでは、各クラスタは自分とマージした際にAABBの表面積が最小となる自身以外のクラスタのことを「好き」であると考えます。成立したカップルが一旦退場する、と想像すると分かりやすいかと思います。実際はより効率の良いPLOC++を用います。
またMeshOptimizerを用いてトポロジを保ったまま、メッシュの簡素化(ポリゴン・リダクション)を行います。リダクションにはQEMを用いた古典的な手法などを用いることができますが、MeshOptimizerを用いたのは、与えられた頂点のサブセットを使うことで入力データの一部を使い回すことができるためのようです。
手法
基本の考え
まずは基礎となる考え方を述べます。入力されたオブジェクトを「256の三角形からなる小さなクラスタ」の集合に分けます(これを初期クラスタと呼びます)。必要に応じてクラスタの解像度を変えることができれば、これだけでも少し役に立ちます。
解像度を下げるにはポリゴン・リダクションを行いますが、隣あう解像度の異なるクラスタの間にひび割れを生じないようにするには、クラスタの境界は触らないよう固定してポリゴン・リダクションを行う必要があります。Nanite: A Deep Diveから拝借した以下の画像がその様子を表しています。
リダクションする前とした後で境界が同一なので、自由に解像度を切り替えることが可能です。
処理の流れ
事前処理として「LOD階層の生成」を行なっておき、レンダリング時には毎フレームで「LODの選択」と「BVHの構築」を行います。
LOD階層の生成
初期クラスタが生成されたら、PLOCを用いてボトムアップでクラスタのペアをマージしながら同時にリダクションを行うことによって、LODの階層を生成します。しかし、実際はこのままではうまくいきません。
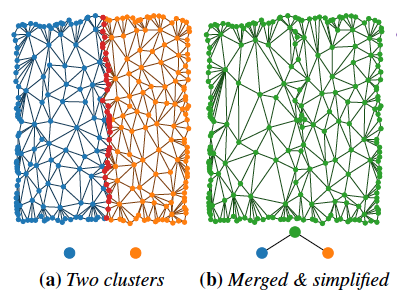
なぜなら、境界部分を固定してクラスタ同士のマージとリダクションを続けていくと、境界部分だけがずっと高解像度であり続けるために、ある時点からリダクションしても三角形の数がそれほど減らなくなってしまうためです。
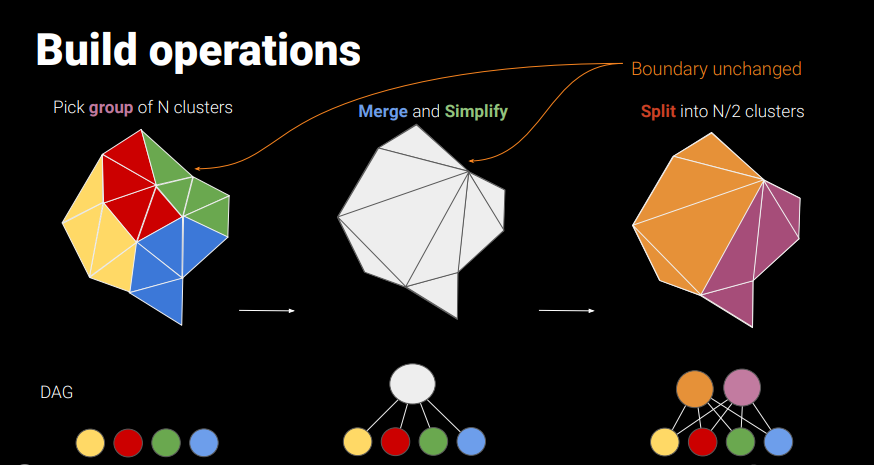
そこで論文では以下のようなsplitと呼ばれる操作を導入します。
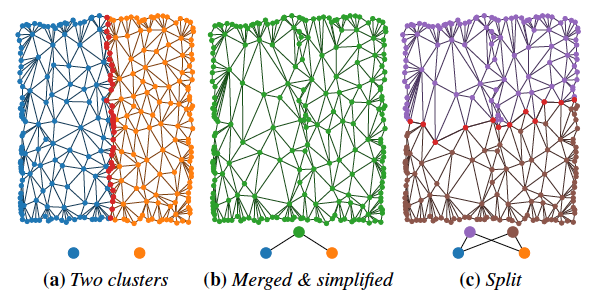
与えられたクラスタをひとまずマージして、リダクションを試みます。ここで、ポリゴンが一定割合以上少なくならなければ、元のクラスタ同士の境界ではない別の境界線で、マージしたクラスタを2つに分割します。緑が親であった中央の画像と違い、親が紫と茶色の2つとなるので、TreeではなくDAGとなります。揃った両親と二人兄弟のイメージです。
PLOCでクラスタのペアを選択する際は、マージした際にそのAABBの表面積が大きくならない、境界を共有する、という条件を用いますが、Splitされた2つのクラスタは、互いに再度マージできないという条件をつけてPLOCで処理されるクラスタの配列に戻されます。こうすることで処理がぐるぐる回ってしまうことを防ぎます。
以下はNanite: A Deep Diveからですが、左側では境界付近が細かい三角形であることがわかります。
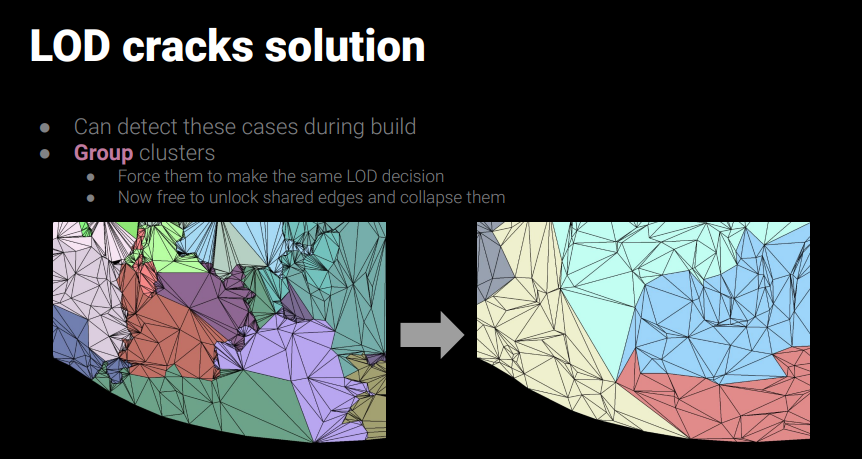
Naniteでは以下のようにレベルごとに異なるクラスタをグループすることでこの問題を回避しています。
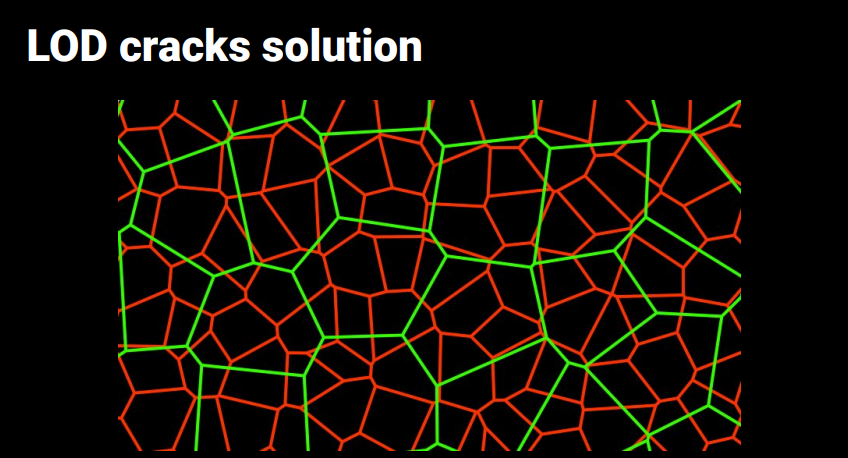
PLOCでクラスタのマージを行っていくわけですが、いつも十分なリダクションが可能であるとは限らないので、処理の結果が1つのクラスタになるとは限らず、複数のクラスタとなることがあります。こういった場合はLODの階層が複数のルート(Entry Points)を持つとして処理を行います。
LODの選択
LODの選択というのは以下の図のようにDAGを視点に依存してカットすることを意味していて、実際には複数のルートからDAGをトップダウンでトラバースして行います。
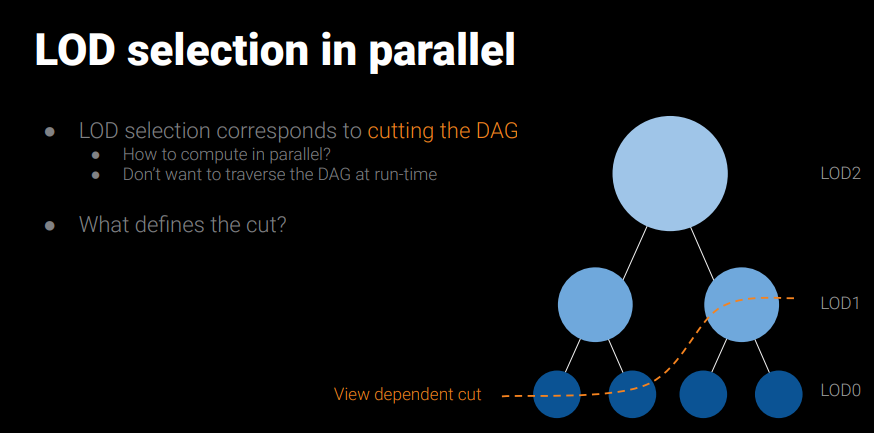
各クラスタはAABBを持っていて、その対角線がスクリーン上で24ピクセル以下であれば十分な解像度であるとして、クラスタを最終的なBVHに含まれるものとし、トラバースを終えます。また、同じSplitから生まれたクラスタのペアには同じAABBを持たせることで、どちらについても必ず同じLODレベルが選択されます。この部分が肝ですね。
LODの選択はDAGを2回トラバースすることで行われます。1回めのパスではどのクラスタが最終的なBVHに含まれるか印だけをつけ、2回目のパスでは印をつけたクラスタをアクティブなクラスタのリストに追加します。これは、DAGでは親のノードが2つあるため、同じクラスタが2回選択されてしまうのを防ぐためです。
Naniteと異なるのはレイ・トレーシングが対象であるので、直接見えないクラスタもCullすることができないという点です。視錐台からはみ出していた場合も、低解像度のものを選択し最終的なBVHに含めることで、Secondary Raysに対応します。LODの選択は完全に視点からの距離に依存しているので、コースティクスや影など特定のもので目立ったポッピング・アーティファクトが発生する可能性があります。この辺は追加のheuristicで容易に解決することが出来るでしょう。
BVHの構築
LODの選択がなされたら、選択されたクラスタに対してBVHを構築します。これには二階層のBVHを用います。BLASは各クラスタに対して構築された小さなBVHで、TLASはBLASを統合したBVHです。これをトラバースすることでレイ・トレーシングによるレンダリングが可能となります。
実装の工夫
効率よくBVHの構築を行うためにはメモリの消費量と、使用する帯域とを削減する必要があります。
まず、そもそものデータ量を削減するために、頂点データはクラスタが属するオブジェクトのAABBを用いて量子化します。通常float x 3で12バイトのところを2 x 3で6バイトに圧縮します。クラスタのAABBではなく、クラスタが属するオブジェクトのAABBを用いるのはHMQにあるように、クラスタ間で隙間が発生しないようにするためです。またクラスタに含める頂点数は256までとしますが、これは1バイトでインデックスを表せるようにすためです。同様にクラスタに含める三角形も256までとします。ここまでで、数Gバイトのメモリで数億の三角形を表せるようになります。
LOD選択時のメモリ帯域を削減するために、LOD選択に必要なデータを分離して、Cluster Headerの配列として持ちます。
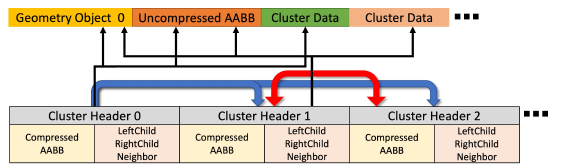
各Cluster Headerは、
- 圧縮されたAABB
- 左右の子(LeftChild, RightChild)への参照
- Splitされた場合の相方(Neighbor)への参照
- 自身が属するオブジェクトへの参照(とその圧縮されていないAABB)
- 実際のクラスタ内部のデータへの参照
を持ち、サイズは40バイトです。LODの選択はこのコンパクトなCluster Headerの配列だけを用いて行うことができます。
Intelの方の論文なので、ターゲットとしているハードウェアがIntel Arc A770となっていて、A770のレイ・トレーシング・ユニットに合わせたBVHを構築する必要があります。これはQBVH6と呼ばれる馴染みのないフォーマットで、通常のQBVHと異なりQは量子化を意味します。6はBVHの幅で、QBVH6は量子化された6-aryのBVHとなっています。
まずは各クラスタに対して、小さなQBVH6を構築する訳ですが、高速に実行するには、事前に各クラスタに対してbinary BVHを構築し、深さ優先のトラバーサル順に三角形を並べ替えておきます。都度binary BVHをコラプスしてwide BVHを作る感じなのだと思いますが、binary BVHのノードはQBVH6にした時点で必要ないのでストアしません。こうすることで帯域を節約できます。
小さなQBVH6はBLASに相当するので、それらを統合(Fuse)してTLASを構築します。全てのQBVH6のルートノードのAABBをPLOC++をもとにしたビルダに渡して一つのQBVH6を構築します。前フレームと大きく変更がない場合は、このFuseの代わりにRefittingも使えますが、RefittingもDAGだとコストがかかるのと、Fuseの方が柔軟であるためFuseを採用しているようです。
最後に
昔実装したInstant Level-of-Detailのコードを発掘して実装してみたいと思いました。さらっと書いてあるSplitは、実装しようとすると「はて、どこで?」と少し悩むかもしれませんが、これはクラスタの数を二等分する最小の境界を選べば良いですね。クラスタを生成する事前処理のコストの削減や、トポロジが変化するようなダイナミックなオブジェクトの扱いなど、まだまだ未解決事項がありますが、今後の発展が楽しみな手法です。細かいところはやってみないとわからないので、実装した後に記事の修正を行いたいと思います。物体表面でNeRFを使う方法もいくつか出てきていますが、こういった細かい制御が可能かつ誰にでも理解できる原理が単純なアルゴリズムはやはり良いものです。