はじめに
今回は、Genetic Programming(GP)に前処理が必要なのかを検証します.
GPが何なのかは、以前の記事で解説しています.
なお,ここでいう前処理は,正規化や標準化を指しており,欠損値埋めや分布の変形は含みません.
どういうこと?
機械学習で関数近似を行う場合は,一般的に正規化や標準化といった前処理を挟みます.
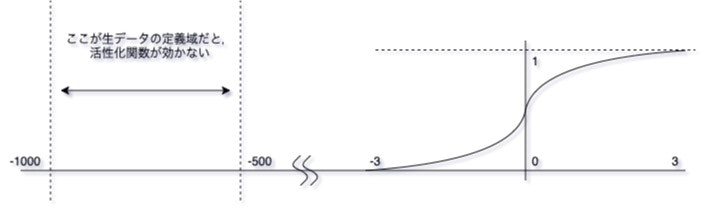
これは,一般に機械学習における入力の定義域が一定に想定されていることに起因します.例えば,Neural Networkにおいて,最小処理単位である活性化関数は以下のような形をしています(イメージ図です).

このとき,0入力で値が大きく変化することや,-3~3の間以外では大きく変化しないことを考えると,前処理の一つの目的は,この暗黙的な定義域に,入力データの分布を持ってくることにあります(もしも前処理をしない場合には,bias項が過度に重要なパラメータとなってしまう).
つまり,前処理というものは機械学習のために存在するのです.一方で、遺伝的プログラミングでは前処理を必須としていません(理論上).なぜなら,遺伝的プログラミングにおける最小処理単位のノード関数は,汎用的数学関数なために定義域が存在しないのです.例えば,四則演算や三角関数に定義域は存在しません(logを除く).
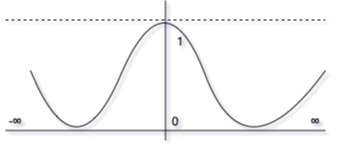
むしろ,三角関数やExp関数では,入力の定義域を[0.0, 1.0]とした場合は,線形演算に近づいてしまうため,演算子そのものの意味を成していません.さらに,標準化によって0を平均値にすると,除算関数には発散点が存在するため,関数近似がバグります.
実際,古いGPの文献を見ていると,前処理の記述はありません.最近になって,機械学習とフェアに競うために前処理をしている印象を受けます.これは,前処理をする手法としない手法は,真の意味で比較できないためです(前処理の妥当性についての議論が始まってしまうため).
実験
目的
GPに前処理が必要なのかを調べたのですが,GP で 機械学習の前処理する文献しか見つけることができなかったので,実際に実験して確かめてみます.
実験内容
bostonおよびdiabetesの回帰問題に対して,次の結果をとります.
- 正規化(MinMaxScaler)を前処理とするGP
- 標準化(StanderdScaler)を前処理とするGP
- 前処理をしないGP
このとき,前処理をしたGPは,関数近似した後にその関数の出力に逆変換をかけます.これにより,生データのスケールで出力が得られます.

今回のGPのパラメータは以下のとおりです.
- Max Generation : 200
- Population Size : 500
- Crossover : subtree swap
- Crossover rate : 0.8
- Mutation : subtree recreate
- Mutation rate : 0.2
- Selection : Batch Tournament Selection
- Batch Size : 8
- Tournament Size : 64
- Depth Limit : 6
- Function Nodes : [+,-,×,÷,sin, cos, exp, log]
- Terminal Nodes : [$x_i$, ERC]
- ERC range : [0.0, 1.0]
また,実験では各GPを10試行し,平均値で比較します.データのスプリットは7:3です.
実験結果
以下では学習データ(training)とテストデータ(test)におけるMAE誤差を比較します.
Boston Dataset
| training | test | |
|---|---|---|
| 正規化GP | 22.310 | 22.250 |
| 標準化GP | 22.236 | 22.563 |
| GP | 20.560 | 22.145 |
思った以上に差がついてないです.前処理ありとなしで結果が大きく変わると思っていたのですが...
結果的には前処理なしGPが最も良い結果ですが,testのMAEはほとんど変わりません.
Diabetes Dataset
| training | test | |
|---|---|---|
| 正規化GP | 155.389 | 152.868 |
| 標準化GP | 147.185 | 144.136 |
| GP | 150.205 | 150.049 |
こちらのほうが,スケールが大きいので差が明確です.なんと標準化GPがもっとも良い結果でした.正直,ゼロを平均とする標準化はGPにとって悪影響が出ると思っていたのですが....
おわりに
結論から言うと,問題依存なので,すべての方法を試すべきということがわかりました.実験する前には,前処理しない方がいい結果を出す気がしていたのですが....
今後,問題数を増やして一般性を試してみたいと思います.また,今回の結果は10試行平均なので,ちょっと乱数の影響が見えます.本当は100か1000試行平均をするべきなので,次回への課題としておきます.
さらに,今回の結果はほとんど差がつかなかったことを考えると,機械学習では前処理は必須ですがGPでは必須でもないということも言えます.これはちょっと面白い結果です.