はじめに
ロジスティック回帰に関する2本目の記事です。
前の1本目の記事では、交絡因子や交互作用を理解するため、人工的なデータを使いました。交絡因子や交互作用といた用語になじみのない方は、この拙著などを参考にしていただければと思います。
この記事では、教科書「ロジスティック回帰分析: SASを利用した統計解析の実際」の3章2節にある「低体重児のリスクファクターに関するケースコントロール研究」で行われていることを再現してみます。
この本のサブタイトルにある通り、この本ではSASのサンプルコードが書いてあります。しかし、SASのようにお高いソフトはとても使えないので、この本の内容をどこまでpythonでできるかやってみました。
この本は15年ほど前に買って、必要な時に読み込んでいました。いまほどコーディングで手を動かすことを意識した統計、機械学習の本がなかった時代の本です。少し読みにくいかもしれませんが、今でも読む価値はあると個人的には思っています。
今回の記事で扱う内容
この記事では、以下を扱います。
- 低体重児のリスクファクターに関するケースコントロール研究のデータを読み込み、簡単な確認と前処理を実施
- 主に着眼している説明変数だけを用いて、statsmodelsによるロジスティック回帰を実施
- 出力された係数、モデルの適合度(デビアンス)の説明
記事が長くなってしまうので、年齢調整や交互作用項を検討するロジスティック回帰は、次の記事に回したいと思います。
ケースコントロール研究とコホート研究
医学の研究では、ケースコントロール研究とコホート研究の2つがあります。
ケースコントロール研究は後ろ向き研究とも呼ばれます。ある疾患の患者と、患者でない人に対して、過去にさかのぼって追跡調査をする方法です。すでに疾患を持つ患者がいるため、費用や時間がかからないというメリットがあります。ただし、過去にさかのぼるため、正確な情報を集めるのが大変な場合があります。また、研究対象とする患者の選択にバイアスがかからないようにする必要があります。
コホート研究では、ある危険因子にさらされた人が、将来的にどのような病態になるかを追跡調査します。患者がいない時点から追跡して、疾患の発生を確認していきますので、ケースコントロール研究よりも情報の正確性などは担保しやすいでしょう。ただし、費用や時間がかかります。また、発症率が低い疾患を調べるときは、多大なサンプル数が必要となります。
低体重児のリスクファクターに関するケースコントロール研究
母親の妊娠中の体重が低すぎると、生まれてくる乳児の出生障害などが高率で発生することが知られているようです。
低体重児(出生体重2500g未満)発生要因として、母親の年齢、最終月経時の体重などを検討した研究があります(Hosmer and Lemeshow 1989)。このデータセットは上述の教科書末尾の参考資料に記載されており、調べたところwebでも入手可能でした。このデータを使って、ロジスティック回帰を使って低体重児の発生要因を検討する過程をなぞってみます。
データ
この教科書の末尾に、データが印刷されています。が、電子データがこのサイトにありました。(おかげで、データを手打ちしなくてすみました)。
このデータは、例えば年齢がQuantity[19, "Years"]という形式で入っているため、読み込むときにひと手間必要です。このひと手間はロジスティック回帰とはあまり関係がないのでここでは割愛します。コードをGitHubにあげていますので、興味があればご参照ください。
サンプル数は189件です。うち、59件が低体重児のデータです。
項目としては以下が入っています。
- Low : 出生した乳児が低体重児であったかの2値。低体重児ならばTrue(1)、それ以外ならFalse(0)
- Age : 年齢
- LWT : 最終月経時の体重(単位はポンド)
- Race : 人種 白人=1、黒人=2、その他=3 のダミー変数が入力されています。
- Smoker : 妊娠時の喫煙ありにTrue(1)、喫煙なしにFalse(0)が入っています。
- PTL : 妊娠28週以前の労働回数。0~3の整数が入力されています。
- Hypertension : 高血圧歴があるならTrue(1)、ないならFalse(0)が入っています。
- UI : 子宮の痛みがあった場合はTrue(1)、なかった場合はFalse(0)が入っています。
教科書では各項目の分布などまでは求めていませんが、一応データを確認しておきましょう。
連続変数に関しては低体重児/低体重児でない別にバイオリンプロットを描き、カテゴリー変数に関してはカテゴリー毎の低体重児の割合を確認します。
年齢
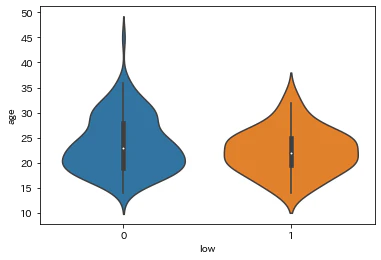
最終月経時の体重(ポンド)
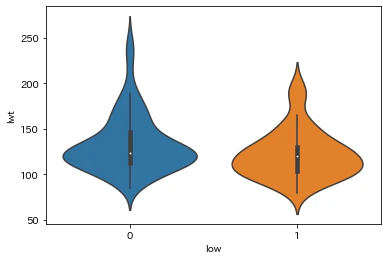
人種
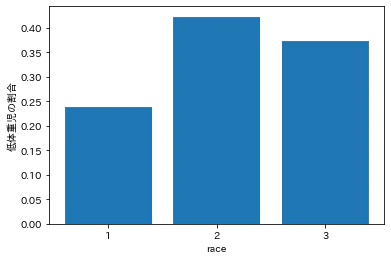
妊娠時の喫煙
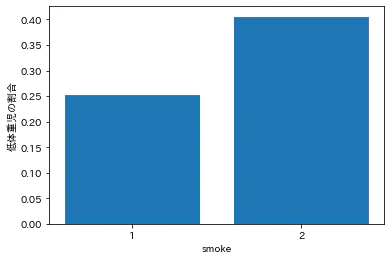
妊娠28週以前の労働回数
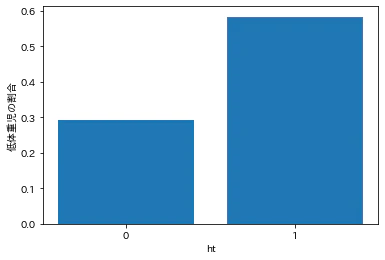
高血圧歴
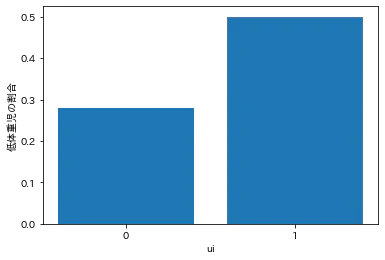
UI:子宮の痛み
前処理
教科書に沿って、連続変数である年齢と最終月経時体重について、離散化して扱うことにします。
離散化したほうが低体重児が発生するオッズの傾向が確認しやすいデータであること、サンプル数は189件と多くはなく3等分などして離散化後の各カテゴリの件数を確保したほうが係数も安定しやすいため、この前処理を実施していると理解しています。
ここでは教科書のSASコードに沿って、pythonで以下のように実装しました。lwt_d1, lwt_d2が3区分に分割する閾値です。lwt_m1, lwt_m2, lwt_m3は3区分それぞれの中央値です。lwt_cはこの中央値を格納した変数です。
lwt_d1 = df["lwt"].quantile(0.333)
lwt_d2 = df["lwt"].quantile(0.667)
lwt_m1 = df["lwt"].quantile(0.1715)
lwt_m2 = df["lwt"].quantile(0.5)
lwt_m3 = df["lwt"].quantile(0.8285)
print(lwt_d1, lwt_d2)
df["lwt_1"] = np.where( df["lwt"] < lwt_d1, 1, 0 )
df["lwt_2"] = np.where( (lwt_d1 <= df["lwt"]) & (df["lwt"] < lwt_d2), 1, 0 )
df["lwt_3"] = np.where( lwt_d2 <= df["lwt"], 1, 0)
df["lwt_c"] = np.where( df["lwt_1"]==1, lwt_m1, np.where(df["lwt_2"]==1, lwt_m2, lwt_m3 ) )
df[ ["lwt_1", "lwt_2", "lwt_3", "lwt_c"] ].drop_duplicates()
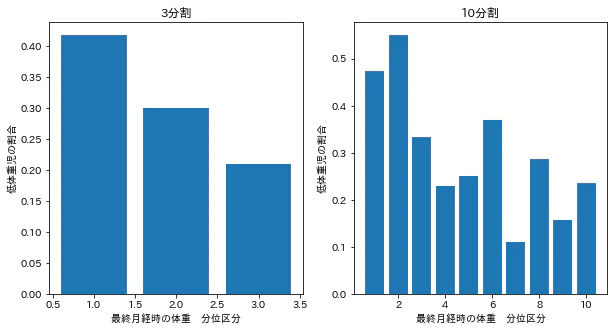
3分割(左)と10分割(右)した時の違いを数に示します。縦軸が低体重児の割合です。3区分にすると、最終月経時の体重と低体重児の割合の関係がはっきりと確認されます。10区分、あるいは連続変数のまま扱っても、低体重児の割合がガタガタしていて、関係をうまく表現できていません。
粗オッズモデル
はじめに、主に着目している最終月経時の体重だけを説明変数にしたロジスティック回帰モデルを作ります。
pythonのstatsmodelsでは、切片は与えてあげないといけないので、以下のように回帰用のデータを作成します。
ここで、説明変数の"lwt_1"と"lwt_2"は上で3区分した最終月経時の体重の一番したと真ん中の区分に対応する変数(0と1をとる)です。
#切片
df["intercept"] = 1
#目的変数yと説明変数X
y = df["low"]
X = df[ ["intercept", "lwt_1", "lwt_2"] ]
statsmodelsでロジスティック回帰は、一般線形モデルを扱うGLMで、familyにBinomial(2項分布)を指定することで実施できます。
logit = sm.GLM(y, X, family=sm.families.Binomial())
logit_result = logit.fit()
print( logit_result.summary() )で結果を確認できます。
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: low No. Observations: 189
Model: GLM Df Residuals: 186
Model Family: Binomial Df Model: 2
Link Function: logit Scale: 1.0000
Method: IRLS Log-Likelihood: -113.84
Date: Wed, 04 Aug 2021 Deviance: 227.69
Time: 07:03:45 Pearson chi2: 189.
No. Iterations: 4
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
intercept -1.2928 0.302 -4.285 0.000 -1.884 -0.701
lwt_1 1.0245 0.399 2.570 0.010 0.243 1.806
lwt_2 0.4305 0.407 1.057 0.290 -0.368 1.229
==============================================================================
係数
最も最終月経時の体重が低い区分の係数は1.0245です。これは、最終月経時の体重が最も高い区分と比較して、低体重児が出生するオッズ比が $e^{1.0245}=2.7856$ であることを示しています。p値も0.01ですので、有意な値となっています。
最終月経時の体重が真ん中の区分の係数は0.4305です。p値は0.29ですので、有意な値となっていません。95%信頼区間も-0.368から1.229となっており、0を含んでいます。
デビアンス
モデルの適合度を表す統計量としてDeviance(デビアンス) $D$ があります。この値が小さいほど、モデルの適合度は良いと判断されます。
statsmodelsで出力されるDevianceは以下の定義で与えられます。
$ D = -2 \times log ($ モデルの尤度 $)$
$ \quad =-2 \Sigma_{j=1}^{J} [ d_j \log( p(x_j) ) + (n_j - d_j) \log (1-p(x_j)) ]$
ここで $j = 1, ..., J $ はカテゴリカルな変数で分割された各区分に振られたラベルです。ここでは、最終月経時の体重に応じて3区分したものに相当し、$J=3$ です。
$n_j$ と $d_j$ は3区分した最終月経時の体重の各区分のサンプル数、および低体重児の数です。
自分で実装して計算すると以下のようになります。
$p(x_j)$は推定したロジスティック回帰モデルが予測する低体重児の発生確率 $p(x_j) = \frac{1}{1+e^{-\beta x_j}}$です。
#各プロファイルのサンプル数、低体重児数を求める
profile_count = pd.pivot_table(data=df, index=["lwt_1", "lwt_2"], columns="low", values="ID", aggfunc="count")
profile_count.reset_index(inplace=True)
profile_count = profile_count.rename(columns={0:"n-d", 1:"d"})
profile_count["n"] = profile_count["d"] + profile_count["n-d"]
profile_count
# 各プロファイルに対するモデルの予測確率を求める
X = df[ ["intercept", "lwt_1", "lwt_2"] ].drop_duplicates()
y_pred = logit_result.predict(X)
X["pred"] = y_pred
# データで集計した件数とモデルの予測確率をマージ
profile_count = profile_count.merge(X, on=["lwt_1", "lwt_2"], how="inner")
display(profile_count)
# 推定したモデルの尤度によるデビアンス
Deviance_fit = 0
for i, row in profile_count.iterrows():
Deviance_fit += -2 *( row["d"]*np.log(row["pred"]) + row["n-d"]*np.log((1-row["pred"])) )
Deviance_fit
profile_countの内容
| lwt_1 | lwt_2 | n-d | d | n | intercept | pred |
|---|---|---|---|---|---|---|
| 0 | 0 | 51 | 14 | 65 | 1 | 0.215385 |
| 0 | 1 | 45 | 19 | 64 | 1 | 0.296875 |
| 1 | 0 | 34 | 26 | 60 | 1 | 0.433333 |
Deviance_fitの結果
227.68707
となり、statsmodelの出力結果と一致しています。
ちなみに、SASでは上のモデルの尤度で求めたデビアンスから、「パーフェクトモデル」のデビアンスを引いた値が出力されます。パーフェクトモデルのデビアンスは以下の式で求められます。
$ D = -2 \Sigma_{j=1}^{J} [ d_j \log( d_j / n_j ) + (n_j - d_j) \log ( (n_j - d_j) / n_j ) ]$
今のケースでは、プロファイルの数が3つで、モデルのパラメータが切片を含めて3つですので、パーフェクトモデルとなっています。
念のため、この式をpythonで計算させると
#パーフェクトモデルでのデビアンス
Deviance_perfect = 0
for i, row in profile_count.iterrows():
Deviance_perfect += -2 *( row["d"]*np.log(row["d"]/row["n"]) + row["n-d"]*np.log(row["n-d"]/row["n"]) )
Deviance_perfect
結果は 227.68707 となり、上のデビアンスの値と一致します。ですから、SASではデビアンスは0と出力されるようです。
なお、RではResidual Devianceとしてstatsmodelと同じ値が出力されます。
粗オッズモデルでモデルの適合度であるデビアンスまで求めました。
次回は年齢調整などをロジスティック回帰でやってみます。