はじめに
この記事はぼくのかんがえたさいきょうのデータセット~データセットを作って delika に登録しよう! by delika Advent Calendar 2022の参加記事です。
最近、寒さや暑さで睡眠が深くならずに困っていませんか?
私もそうでした。暖房を付けたら暑すぎて、設定温度を下げると朝には寒く、逆に寒すぎると思って設定温度を上げると朝も寒かったりしました。
そこで、最高の睡眠を得るためには、室内温度や湿度はどのように設定すれば良いかを探ってみました。
今回は、データを元に室内温度や湿度が最高の睡眠にどのように影響するかを、自然言語生成モデルのChatGPTで尋ねてみました。
ChatGPTに聞いてみた
OpenAI社が開発したAIであるChatGPTは、色々なことに答えてくれると言われています。
そこで、私もChatGPTに質問してみました。
しかし、流石に流石にパーソナルなデータのインプットをしなければ、正確な答えを得ることはできないですね。
睡眠のパターンや状態を計測する必要があると言うのはもっともだと思うので、計測してみました!
使うデバイス
今回、睡眠の質や室内温度、湿度を計測するために、以下の2つのデバイスを使用しました。
xiaomi smart band7
睡眠の質を計測することができます。アプリ版だと0~100の睡眠スコアが出力されます。しかし、エクスポートデータには含まれていないのが残念です。
amazonで7000円ほどで購入することができます。
計測したデータをアプリ上からダウンロードすることができます。
睡眠データの他に以下のデータをダウンロードすることもできる優れものです。
- 活動データ(歩行データ)
- 心拍数
- スポーツ

SwitchBot 温湿度計

温度と湿度を計測することができます。ハブミニと連携することで、データをクラウド上にアップロードすることができます。
データの読み込み
睡眠データ:xiaomi smart band7
xiaomi smart band7からのデータ取得は、【意外と簡単】Miスマートバンドで記録したデータをエクスポートする方法を参考にします。
取得したデータは以下のようになります。

deepSleepTime:深い眠りの時間
shallowSleepTime:浅い眠りの時間
wakeTime:途中起床時間
REMTime:レム睡眠時間
start:睡眠開始時間(UNIX時刻)
stop:睡眠終了時間(UNIX時刻)
温湿度:switchbot
データ取得は、SwitchBot温湿度計を買って精度を確認し、時系列データを取ってみたを参考にします。
データの間隔は1分〜24時間で取得できますが、細かすぎてもデータの突合が難しくなるので、1時間の粒度にします。
取得したデータは以下のようになります。
Timestamp:計測された時間(日本時間)
Temperature_Celsius(℃):温度
Relative_Humidity(%):湿度
データの結合
睡眠データが時系列データではないので、このままだと温湿度データと組み合わせることができません。そこで温湿度と結合できるようにするために時系列データに変換します。
時刻がUNIX時刻と東京時間になっている場合は、どちらかに統一する
睡眠データの変換
import pandas as pd
import datetime
import math
def utc_to_jst(x):
dt = datetime.datetime.strptime(x, '%Y-%m-%d %H:%M:%S%z')
datetime_jst = dt.astimezone(datetime.timezone(datetime.timedelta(hours=+9)))
return datetime_jst
def make_year(x):
return x.year
def make_month(x):
return x.month
def make_day(x):
return x.day
def make_hour(x):
return x.hour
df_sleep["start_timestamp"]=df_sleep["start"].apply(utc_to_jst)
df_sleep["end_timestamp"]=df_sleep["stop"].apply(utc_to_jst)
df_sleep_modify = pd.DataFrame(columns=
['deepSleepTime', 'shallowSleepTime', 'wakeTime', 'REMTime','naps',
'timestamp'])
for i in range(len(df_sleep)):
sleep_hour = math.ceil((df_sleep.loc[i,"end_timestamp"]-df_sleep.loc[i,"start_timestamp"]).seconds/3600)
for j in range(sleep_hour):
s = pd.Series([df_sleep.loc[i,"deepSleepTime"], df_sleep.loc[i,"shallowSleepTime"], df_sleep.loc[i,"wakeTime"],
df_sleep.loc[i,"REMTime"],df_sleep.loc[i,"naps"],df_sleep.loc[i,"start_timestamp"]+ datetime.timedelta(hours=j)], index=df_sleep_modify.columns)
df_sleep_modify=df_sleep_modify.append(s,ignore_index=True)
df_sleep_modify["timestamp_year"] = df_sleep_modify["timestamp"].apply(make_year)
df_sleep_modify["timestamp_month"] = df_sleep_modify["timestamp"].apply(make_month)
df_sleep_modify["timestamp_day"] = df_sleep_modify["timestamp"].apply(make_day)
df_sleep_modify["timestamp_hour"] = df_sleep_modify["timestamp"].apply(make_hour)
df_sleep_modify.head(2)
出力結果は以下の様になります。

温湿度データの変換
def temp_to_timestamp(x):
return datetime.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
df_temp["Timestamp_timestamp"]=df_temp["Timestamp"].apply(temp_to_timestamp)
df_temp["timestamp_year"] = df_temp["Timestamp_timestamp"].apply(make_year)
df_temp["timestamp_month"] = df_temp["Timestamp_timestamp"].apply(make_month)
df_temp["timestamp_day"] = df_temp["Timestamp_timestamp"].apply(make_day)
df_temp["timestamp_hour"] = df_temp["Timestamp_timestamp"].apply(make_hour)
出力結果は以下の様になります。

結合
以下の様なコードでデータフレームを内部結合します。
df = pd.merge(df_sleep_modify, df_temp, on=["timestamp_year","timestamp_month","timestamp_day","timestamp_hour"])
時刻でデータを結合したい場合は、年、月、日、時間で列を作成すると便利
データの分析
データの可視化
これでデータ分析をするための準備が整いました。
次に、ヒストグラムを表示させようと思ったのですが、複数並べる方法がわからなかったのでChatGPTに聞いてみます。
ChatGPTに聞いてみると、複数のグラフを並べるには「subplots」を使うと良いとのことです。これを参考に、以下のようなコードを書いてみます。
# 複数のグラフを並べるための図を作成する
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(15, 10))
sns.distplot(df['Temperature_Celsius(℃)'], ax=ax[0][0])
sns.distplot(df['Relative_Humidity(%)'], ax=ax[0][1])
sns.distplot(df['deepSleepTime'],ax=ax[0][2])
sns.distplot(df['shallowSleepTime'], ax=ax[1][0])
sns.distplot(df['REMTime'], ax=ax[1][1])
sns.distplot(df['wakeTime'], ax=ax[1][2])
plt.show()
結果は以下の様になります。
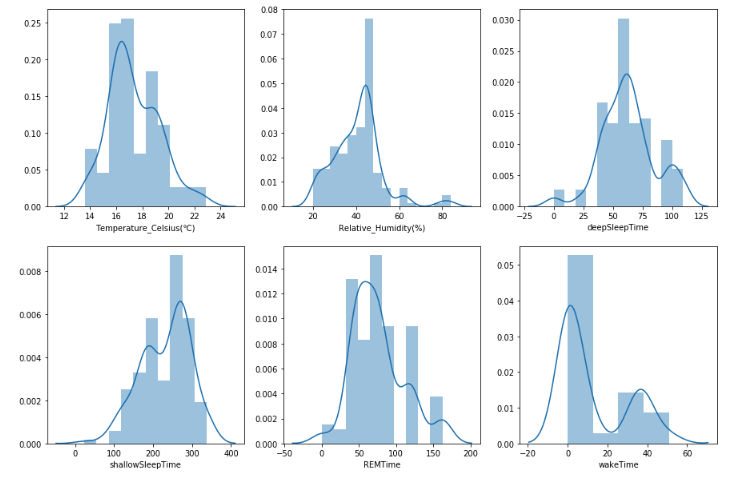
ただ、これだけだと変数同士の関係性が見えてこないので以下のコードを入力して関係性を可視化します。
sns.pairplot(df[usecols])
plt.show()
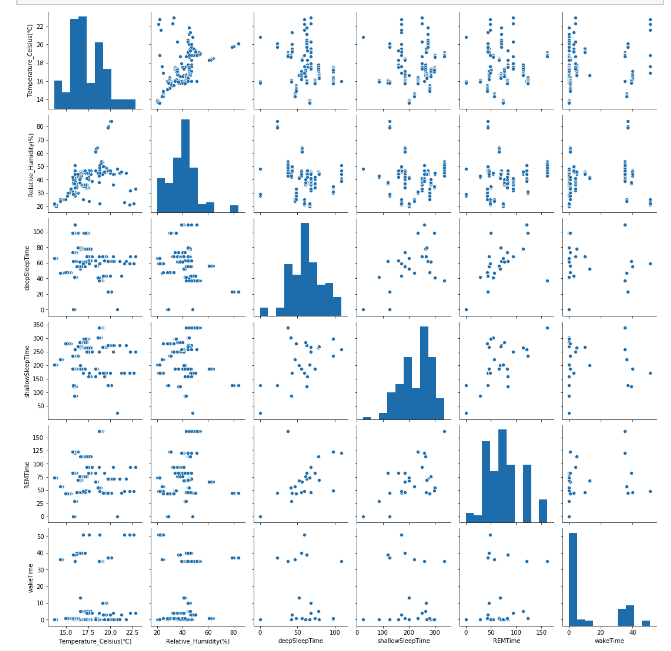
気温と湿度は正の関係が見られますが、それ以外はこれと言った関係性が見られません。二次関数のようなものが見られると思ったのですが。。
睡眠品質の分類
深い睡眠と浅い睡眠、REM睡眠には正の相関があることが分かったので、深い睡眠と途中起床時間のヒストグラムを元に高品質の睡眠と低品質の睡眠を分類します。
高品質の睡眠:深い睡眠が60分以上かつ途中起床時間が60分以下
低品質の睡眠:高品質以外
df["sleeping_quality"]=""
for i in range(len(df)):
if df.loc[i,"deepSleepTime"] >=60 and df.loc[i,"wakeTime"] <=60:
df.loc[i,"sleeping_quality"] = "high"
else:
df.loc[i,"sleeping_quality"] = "low"
さて、ここから品質と環境の関係性を探ってみたいと思います。
どうすれば良いか迷ったので、ChatGPTに聞いてみます。
これまでかなりの精度で回答できているので、データフレームの情報も提示した上で試してみることにしました。
以下のpandasのデータフレームがあります。
temp:気温(float型、12~24の値)
humidity:湿度(float型、0~100の値)
sleeping_quality:睡眠品質(str、highかlow)
睡眠品質が高い時の気温と温度がどうなっているのか、また低い時に気温と湿度がどうなっているのか知りたいです。
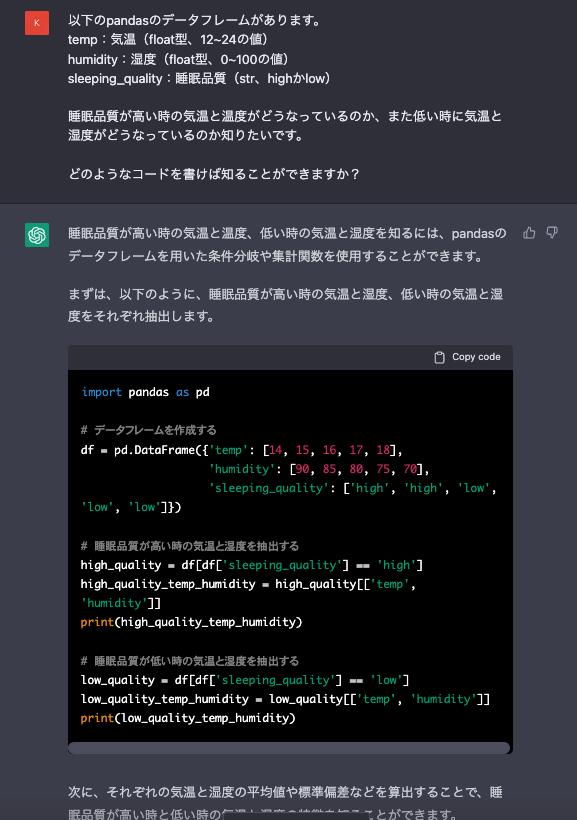
すごすぎる。。きちんと解答が返ってきます。
ChatGPTには、データフレームの入力情報を与えればその入力に応じたサンプルコードの出力までしてくれる
この入力を元に解析します。
# 睡眠品質が高い時の気温と湿度を抽出する
high_quality = df[df['sleeping_quality'] == 'high']
high_quality_temp_humidity = high_quality[['Temperature_Celsius(℃)', 'Relative_Humidity(%)']]
print(high_quality_temp_humidity)
# 睡眠品質が低い時の気温と湿度を抽出する
low_quality = df[df['sleeping_quality'] == 'low']
low_quality_temp_humidity = low_quality[['Temperature_Celsius(℃)', 'Relative_Humidity(%)']]
print(low_quality_temp_humidity)
# 睡眠品質が高い時の気温と湿度の平均値を算出する
high_quality_temp_humidity_mean = high_quality_temp_humidity.mean()
print(high_quality_temp_humidity_mean)
# 睡眠品質が低い時の気温と湿度の平均値を算出する
low_quality_temp_humidity_mean = low_quality_temp_humidity.mean()
print(low_quality_temp_humidity_mean)
最終的な結果としては以下の様になりました。
高品質な睡眠
平均温度:17.1℃ 平均湿度:39%
低品質な睡眠
平均温度:17.6℃平均湿度:43%
delicaへのデータ登録
それでは、作ったデータをdelicaに登録してみます。
こちらの記事を参考にしながら登録してみます。
カラムの説明を入力する欄がなかったので、説明欄に記入しました。
登録したデータのURLは以下になります。是非使ってみてください!
https://delika.io/shin_tomy/sleep_temper
終わりに
快眠を得るための温湿度を探りましたが、睡眠の品質にはほとんど関係が無かったことが分かりました。
もっとデータを増やしたり、環境を調整した上で分析してみたいと思います。
また、ChatGPTを使用することで、コーディングをする上で非常に有用なパートナーとなると感じました。今後も、より多くのデータを集めて分析するよう心がけ、ChatGPTを積極的に活用して、効率的なコーディングを目指したいと思います。