なぜレコメンドエンジンか?
これはデジタルマーケターの分析負荷をなくすことができると考えたからだ。
現在、多くのサイトはGoogleAnalyticsを導入している。目的は単純な
サイトトラッキングもあれば、広告アトリビューションやECサイトの
ROI計測などだ。
さらに、GoogleAnaltyicsにはeコマーストラッキングも可能なので、
誰が、どの商品に、どんなアクションを行ったかがわかる。
このデータを用いてレコメンドエンジンを構築する事で、
どのユーザにどんな商品を薦めるべきかを自動で推論できる。
利用したデータセット
今回、BigQueryのパブリックデータセットの一つである、
GoogleAnalyticsデータセットをサンプルで用いた。
このデータセットはGoogleAnalyticsのローデータが投入されており、
本来、GoogleAnalytics360でしかサポートされていない機能で得られる
データセットだ。
利用したい場合は以下のページからGCPのプロジェクトとデータセットを
連携させて閲覧可能にする必要がある。
https://support.google.com/analytics/answer/7586738?hl=en
レコメンドエンジンの構築
どのように構築を行ったか、順を追って説明していく。
データの取得と整形
BigQueryに格納されたデータのうち、以下をSQLで取得する。
ClientID:fullVisitorId
商品ID:hits.product.productSKU
アクション:hits.eCommerceAction.action_type
アクション値はその他、商品リストの閲覧、商品詳細の閲覧、
購入完了に限定しており、以下の値に変換した。
その他→0、商品リスト閲覧→1、商品詳細の閲覧→2、購入完了→3
変換後はCSV形式でエクスポートし、以下の形式となる。
| fullVisitorId | hits.product.productSKU | hits.eCommerceAction.action_type |
|---|---|---|
| 11111 | AAAAA | 0 |
| 11111 | BBBBB | 2 |
| 22222 | AAAAA | 3 |
| 22222 | CCCCC | 1 |
| 22222 | DDDDD | 2 |
レコメンドモデルの構築
レコメンドで頻繁に使用される「協調フィルタリング」と呼ばれる手法のモデルを
複数作成した。このモデルに先ほど作成した。CSVデータを投入し、予測が行えるように
モデルを学習させた。
予測精度(今回はRMSE)を比較した結果、「Non-negative Matrix Factorization」モデルの
RMSEが最も誤差が低く、予測精度が高かった。
| モデル | 誤差(RMSE) |
|---|---|
| SVD | 0.5520 |
| SVD++ | 0.5153 |
| MatrixFactorization | 0.5541 |
| Non-negative Matrix Factorization | 0.5012 |
| knn baseline | 0.5267 |
| knn with z-score | 0.6481 |
| knn basic | 0.5516 |
以下でNon-negative Matrix Factorizationを順序たてて解説する。
アルゴリズムの話となるため読み飛ばしていただいても構わない。
協調フィルタリングとは:
ユーザ同士の類似度から推奨するアイテムを決める手法である。
例えば、あるECサイトで3人のユーザが5つのアイテムに対して
5段階評価をしたとき、その評価値を以下のように表す。
| アイテム1 | アイテム2 | アイテム3 | アイテム4 | アイテム5 |
|---|---|---|---|---|
| ユーザ1 | 3 | 2 | 4 | 3 |
| ユーザ2 | 0 | 1 | 0 | 0 |
| ユーザ3 | 3 | 2 | 2 | 0 |
例えば、ユーザ3に推奨するアイテムが何かを考えてみよう。
まずは、ユーザの評価をベクトルに変換する。
p1=(3,2,4,3,2)
p2=(0,1,0,0,5)
p3=(3,2,2,0,2)
次にユーザ同士の類似度を計算する。(今回はコサイン類似度を使用し1に近いほど類似しているとみなす。)
cos(p1, p3) = p1 * p2 / |p1| * |p2| = 0.8417
cos(p2, p3) = p1 * p3 / |p1| * |p3| = 0.5135
今回の例ではユーザ3はユーザ1と類似度が高いため、ユーザ1は購入しているが、ユーザ3は
購入していないアイテム4を推奨することがふさわしい、という結論になる。
ただ、協調フィルタリングでは精度の高いレコメンドは実現できない。実際のECサイトでは
何万、何十万の商品があることも珍しくない。ユーザが評価した商品はわずかだ。
評価に使えない商品数(列)が多すぎると、「次元の呪い」と
呼ばれる、予測精度が大きく下がる問題が発生する。
Matrix Factorizationとは:
次元の呪いを解消するために生まれた手法がMatrix Factorizationである。
これは、ユーザ数とアイテム数を減らした状態で予測を行う手法だ。
ユーザとアイテムの評価は以下のR(u * i)のような表となる。
これを任意の k個の行(X)と列(Y)の2つに分解・圧縮する。
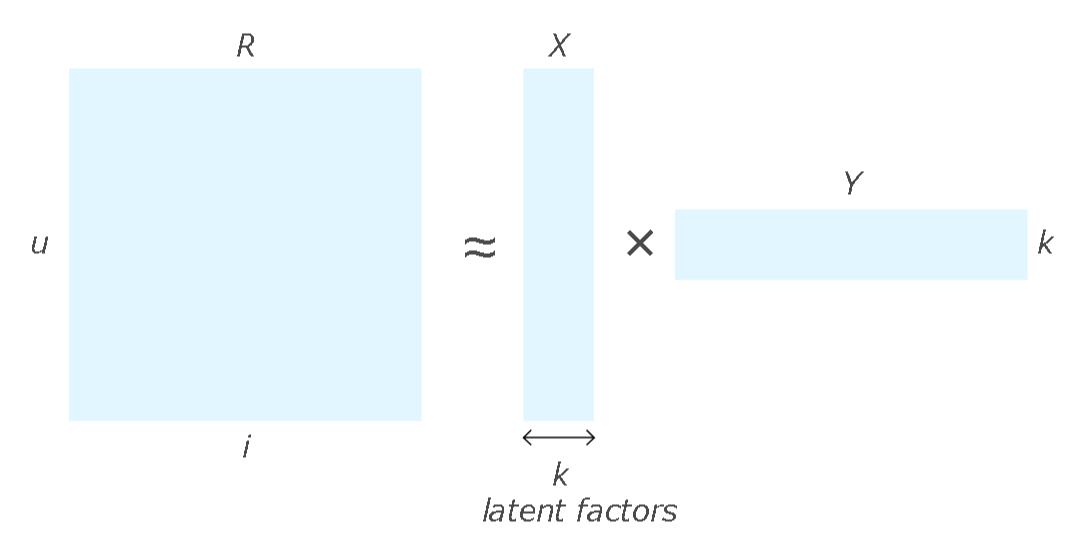
この圧縮したXとYの内積を計算することで、Rと同じ行列の評価を推測できる。アルゴリズムの説明は一部省いている。
よって、正確な内容については以下を参考にしてほしい。
TensorFlow でのレコメンデーション システムの構築:
https://cloud.google.com/solutions/machine-learning/recommendation-system-tensorflow-overview
Non-negative Matrix Factorizationとは:
Matrix Factorizationにも一つ欠点がある。圧縮した際のX, Yの値が負の値をとりうることだ。
今回、実際の評価は正の値しかとらず,未評価であっても0点である。そのため負の値を取り得ない。
Non-negative Matrix Factorizationでは負の値を使用しない。
これにより、足し算のみで評価を行うことで推論がシンプルになり、
精度が高まる。
Non-negative Matrix Factorizationの実装について:
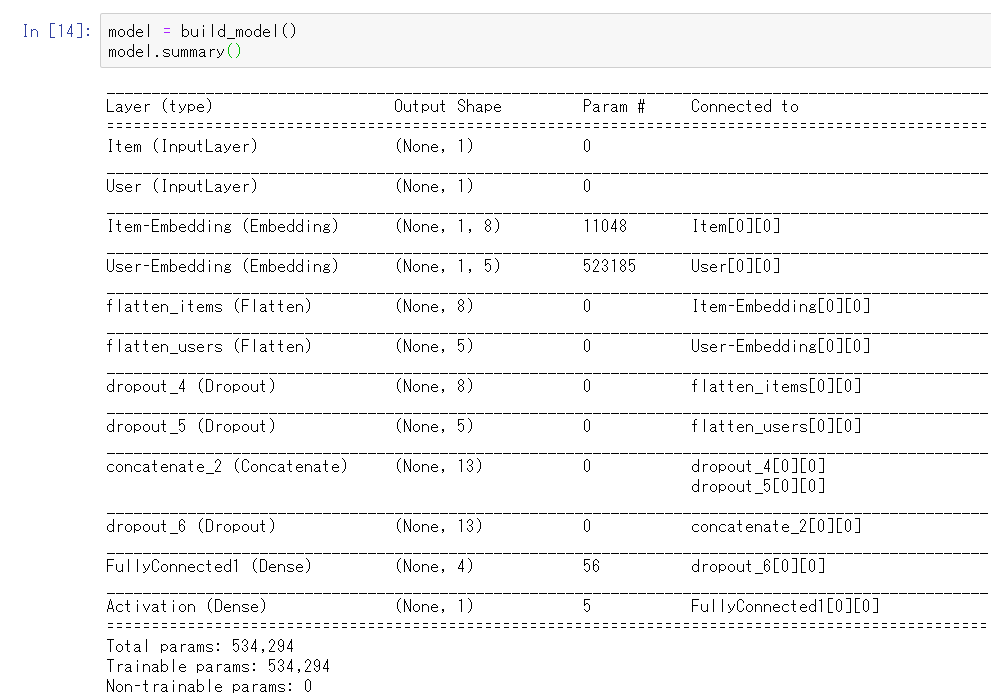
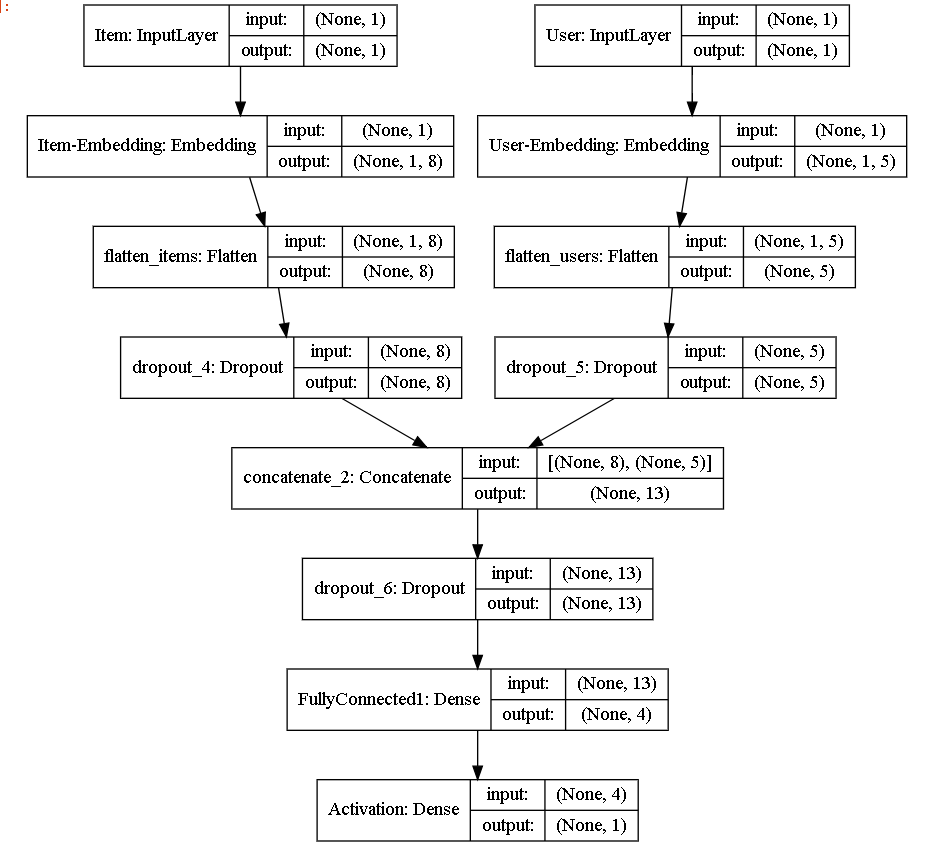
上記のモデルを深層学習用ライブラリのKerasのを用いて構築した。
ソースコードは省くが、ネットワークグラフ図を下記に記載する。
モデルサマリ:
モデルグラフ図:
予測
最後に、アクションを行っていないユーザと商品の組み合わせをCSVに抽出する。抽出したCSVをモデルに投入すると、
学習時と同様に行列の分解と圧縮、評価の予測が行われ、値が返される。この結果をまとめたのが以下だ。
| fullVisitorId | hits.product.productSKU | pred_action |
|---|---|---|
| 44444 | AAAAA | 2.21 |
| 44444 | BBBBB | 1.45 |
| 55555 | AAAAA | 2.33 |
| 55555 | CCCCC | 1.66 |
| 55555 | DDDDD | 1.21 |
ユーザの商品ごとの予測行動が予測できる。
最後に
GoogleAnalyticsや他のDMPツールの恩恵で膨大なデータを得ることができる。
その蓄積したデータでモデルを構築する事で、RPAのようにユーザの負荷を
削減できるようになっていくと私は考えています。
※ 本記事は個人の見解であり、所属する団体の見解ではございません。
私の理解に相違などあればコメントいただければ幸いです。
※ 参考にさせていただいた記事、サイトは以下となります。
http://surpriselib.com/
https://keras.io/ja/
https://cloud.google.com/solutions/machine-learning/recommendation-system-tensorflow-overview