この記事で触れること
遅ればせながらLangChainってどういうの?というのを見てみる。ライブラリ自体は何となく使ったことがあるが、数多くの機能の一部みたいな感じでしか使ったことがないため全体をみてみたさがある。
動きを見てみる
Langchain all in one
クローン元リポジトリURLからソースをクローンし、
指定されたpythonのバージョンにしてrequirements.txtでパッケージをインストールし、all-in-oneディレクトリ内のHome.pyをstreamlitコマンドで叩く
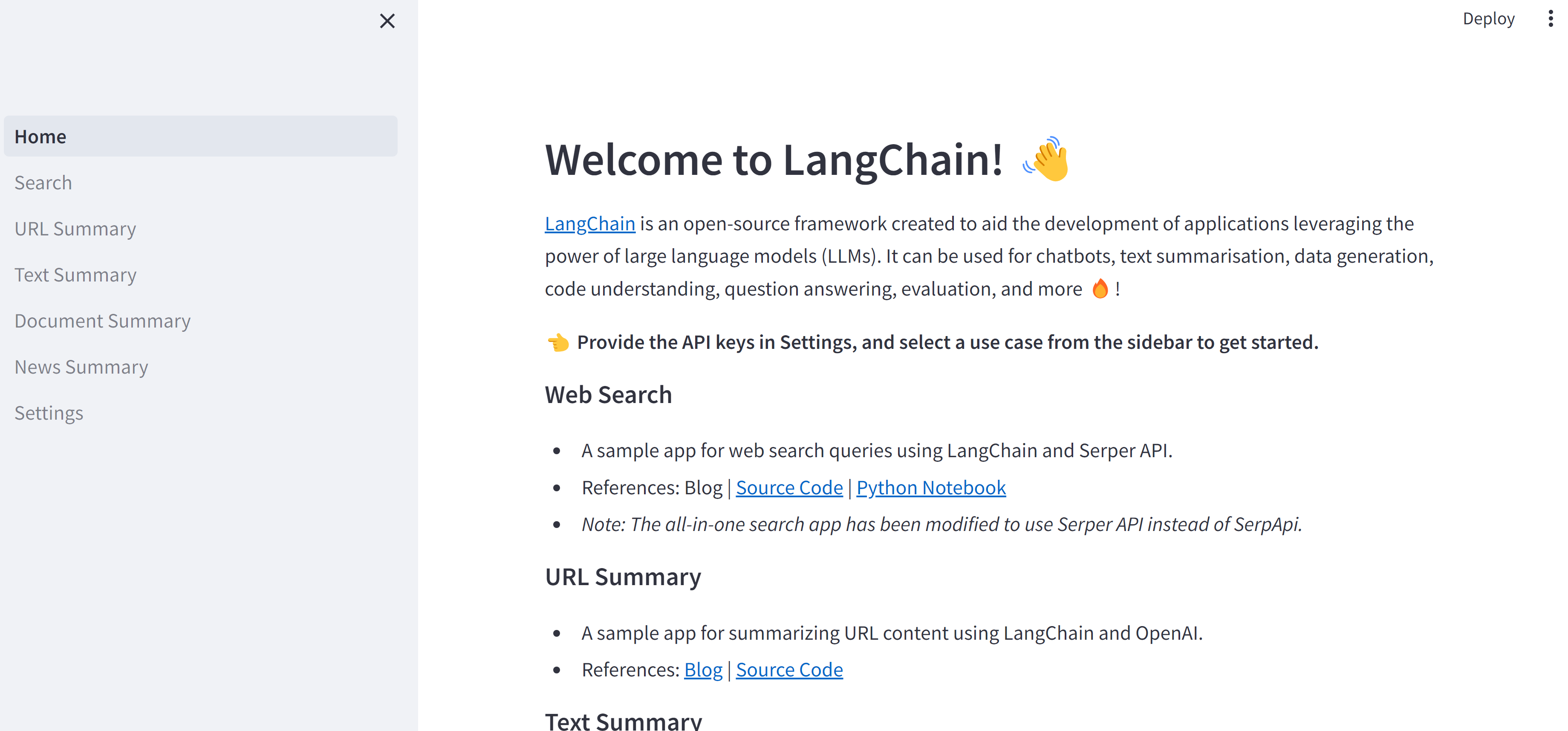
サイドバーに機能が一覧化されている、と考えてよさそう(Settings以外)
Settings
APIキーをセットする
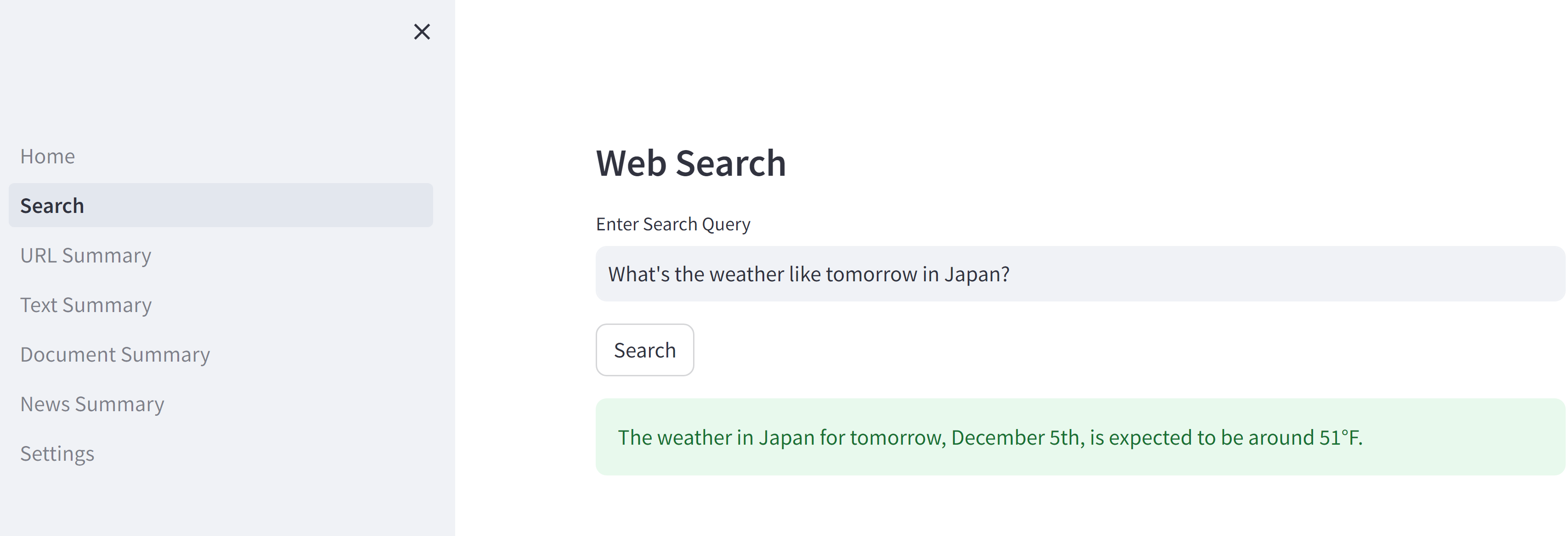
Web Search
質問に対してインターネット検索を実施して回答を探してくる
ここで採用されているのはReActエージェントである。
簡単に言うとReActとは、与えられた質問に対して「思考」し、「行動」し、結果を「観察」するというループによって答えを導き出す手法を指す。
今回はゼロショットで、Google検索のみを「行動」方法として定義している
実際のコード
try:
with st.spinner('Please wait...'):
# Initialize the OpenAI module, load the Google Serper API tool, and run the search query using an agent
llm = ChatOpenAI(temperature=0, openai_api_key=openai_api_key, verbose=True)
tools = load_tools(["google-serper"], llm, serper_api_key=serper_api_key)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
result = agent.run(search_query)
st.success(result)
except Exception as e:
st.exception(f"An error occurred: {e}")
中のログ
> Entering new AgentExecutor chain...
I should use the google_serper tool to search for the weather forecast in Japan for tomorrow.
Action: google_serper
Action Input: Weather forecast in Japan for tomorrow
Observation: 10-Day Weather Forecast. Tonight. 12/5. 44° Lo. A little rain early; clearing. 49% · Fri. 12/6. 64° 41°. Mostly cloudy. Night: Partly cloudy. 2% · Sat. 12/7. 57 ... 10 Day Weather-Minato-ku, Tokyo Prefecture, Japan High near 60F. Winds light and variable. A larger storm system will bring more snow and gusty winds, but a ... 2 Week Extended Forecast in Tokyo, Japan Sunny. Increasing cloudiness. Mostly sunny. Morning clouds. Wed 04 | Day ... Some clouds this morning will give way to generally sunny skies for the afternoon. High 62F. Winds NNW at 5 to 10 mph. Tokyo Weather Forecasts. Weather Underground provides local & long-range weather forecasts, weatherreports, maps & tropical weather conditions for the Tokyo ... Tue 03 | Day ... A mix of clouds and sun. High 63F. Winds light and variable. Japan Weather Forecast for Travelers ; Sapporo · 60%. 3° ; Kushiro · 70%. 6° ; Niigata · 90%. 9° ; Sendai · 50%. 11° ; Kanazawa · 90%. 10° ... Weather in Tokyo, Japan ... Broken clouds. Feels Like: 57 °F Forecast: 65 / 40 °F Wind: 5 mph ↑ from Southeast ... Cloudy; areas of drizzle in the morning followed by a little rain in the afternoon. RealFeel®50°. RealFeel Shade™50°. Max UV Index1 Low. WindNNE 4 mph ... Partly cloudy skies. Low 42F. Winds light and variable. icon. TomorrowThu 12/05 ...
Thought:I should look for the specific weather forecast for tomorrow in Japan.
Action: google_serper
Action Input: Weather forecast in Japan for December 5th
Observation: 51°F
Thought:I now know the final answer
Final Answer: The weather in Japan for tomorrow, December 5th, is expected to be around 51°F.
> Finished chain.
ちょっと別の質問もしてみる
> Entering new AgentExecutor chain...
I am not familiar with this question, I should use the google_serper tool to search for more information.
Action: google_serper
Action Input: "縦の糸はあなたで、横の糸は私である場合、織りなす布はどのような挙動をすると予想されますか?"
Observation: 縦の糸はあなた横の糸は私簡単にいうと人と人が協力すれば他の人を励ましたり助けたりすることができるかもって言ってるのだと思います。 Missing: 場合、 挙動. 生地の模様は横の糸で紡いでいくものですよね? 要するに、あなたがいてくれたら、縦の糸になってくれたら、私は彩りを形づけるわ。というように解釈した ... Missing: 場合、 挙動. 縦の糸がきちんと張られていないと美しい模様にはなりませんし、なめらかな布にはなりません。 中島みゆきさんは縦の糸と横の糸を人間関係になぞられました。これを仏教で ... Missing: 場合、 挙動 予想. 関係がつむがれることで、かけがえのない「布」が織りなされる。 その布は、いつか誰かの傷口をかばい、あたためるかもしれない、と歌われる。 Missing: 場合、 挙動 予想. 男女を縦糸と横糸に見立てて、その糸から布が織り出されるというのは、男女が協力して何かを成し遂げるということなのでしょう。これは特別な男女の一回 ... Missing: ある 場合、 挙動 予想. 縦の糸はあなた横の糸はわたし織りなす布はいつか誰かを暖めうるかもしれない. 縦と横の糸(両親)が出会い、わたしがこの世に誕生した。縦と横の愛が糸 ... Missing: 私 場合、 どの 挙動 予想 され. 「縦の糸はあなた 横の糸は私 織りなす布はいつか誰かを暖めうるのかもしれない」。人を糸にたとえ、別の糸と出逢うことで「布」という新しい形になり、 ... Missing: 挙動 予想. 「♪縦の糸はあなた 横の糸は私…」というフレーズです。お互いを、縦横の糸によって織りなされている布にたとえている歌詞で、結婚をするカップルには最適 ... Missing: 場合、 織りなす どの 挙動 予想. 会社の取締役の兼任が禁止されています。 また、Cが親会社の監査役であると同時. に子会社の使用人であるような場合、Cは. 子会社の取締役の業務執行について監査す. る ... 1 回答者の属性(性別・年代・居住地区) ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・5. 2 定住意向.
Thought:After reviewing the search results, it seems like this question is more metaphorical and related to relationships rather than a literal fabric weaving scenario.
Final Answer: The fabric woven when the vertical thread is you and the horizontal thread is me is a metaphor for relationships and cooperation.
> Finished chain.
URL Summary
URLリンク先の中身を要約する
mediumのグラフRAGについての記事
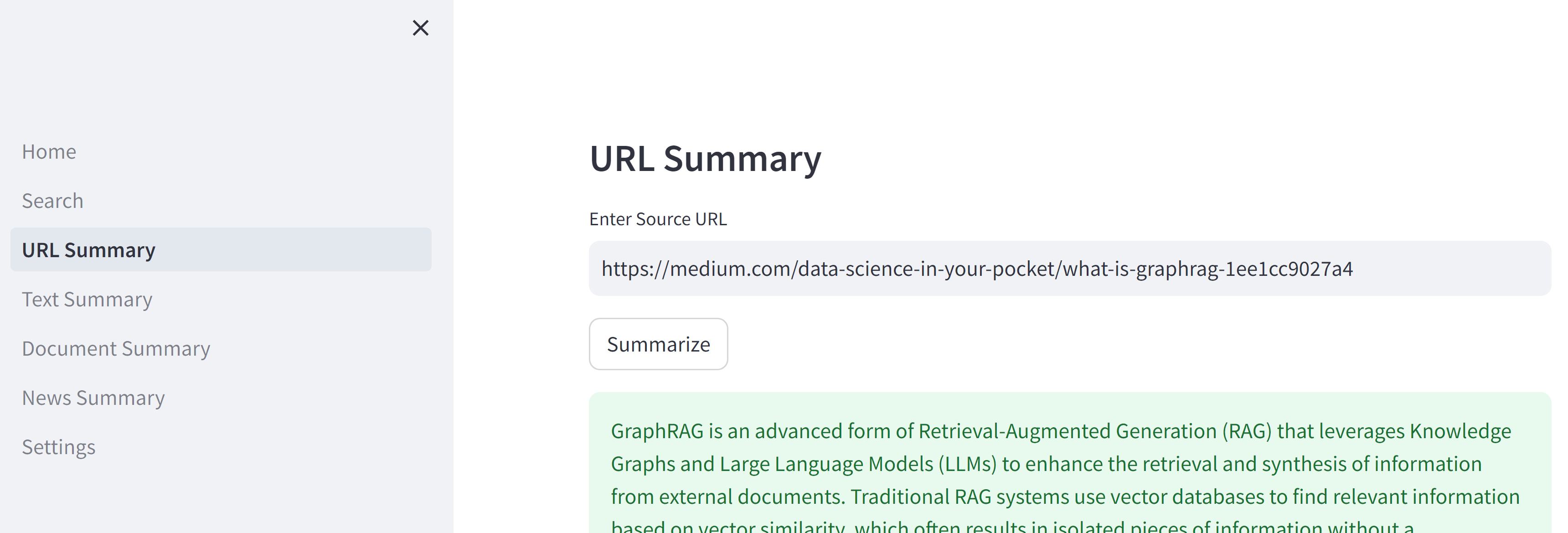
要約結果
GraphRAG is an advanced form of Retrieval-Augmented Generation (RAG) that leverages Knowledge Graphs and Large Language Models (LLMs) to enhance the retrieval and synthesis of information from external documents. Traditional RAG systems use vector databases to find relevant information based on vector similarity, which often results in isolated pieces of information without a comprehensive understanding of the context. This approach can struggle to connect insights across different documents, leading to a fragmented understanding of the data.
GraphRAG addresses these limitations by using Knowledge Graphs instead of vector databases. A Knowledge Graph is a structured representation of information that captures entities, their attributes, and relationships, providing a more holistic view of the data. In GraphRAG, an LLM automatically extracts a rich knowledge graph from a collection of text documents, capturing the semantic structure and detecting communities of densely connected nodes. This allows GraphRAG to provide more complete and varied responses, as it can connect related advancements spread across documents and offer a holistic understanding of overarching trends or themes.
When a user inputs a query, GraphRAG retrieves the most relevant information from the knowledge graph and uses it to condition the LLM's response. This improves the accuracy of the generated answers and reduces hallucinations. The system can also provide overviews of the dataset at different levels, allowing users to understand the overall context without needing specific questions. GraphRAG is more efficient than summarizing the full text while still generating high-quality responses, making it a significant advancement over baseline RAG systems. The implementation of GraphRAG is available in a modular graph-based system by Microsoft on GitHub.
UnstructuredURLLoaderなるもので、URL先の各タグのtextを読み取っている模様
ソースコード
try:
with st.spinner("Please wait..."):
# Load URL data
if "youtube.com" in url:
loader = YoutubeLoader.from_youtube_url(url, add_video_info=True)
else:
loader = UnstructuredURLLoader(urls=[url], ssl_verify=False, headers={"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13_5_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"})
data = loader.load()
# Initialize the ChatOpenAI module, load and run the summarize chain
llm = ChatOpenAI(temperature=0, model='gpt-4o', openai_api_key=openai_api_key)
prompt_template = """Write a summary of the following in 250-300 words.
{text}
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["text"])
chain = load_summarize_chain(llm, chain_type="stuff", prompt=prompt, verbose=True)
summary = chain.run(data)
st.success(summary)
except Exception as e:
st.exception(f"Exception: {e}")
追記:このアプリではyoutubeの動画の内容抽出もできるはずだったが、なぜかアクセスできないというエラーが発生していた。無事解決したので記事にしてみた。
Text Summary
与えられたテキスト情報を要約する
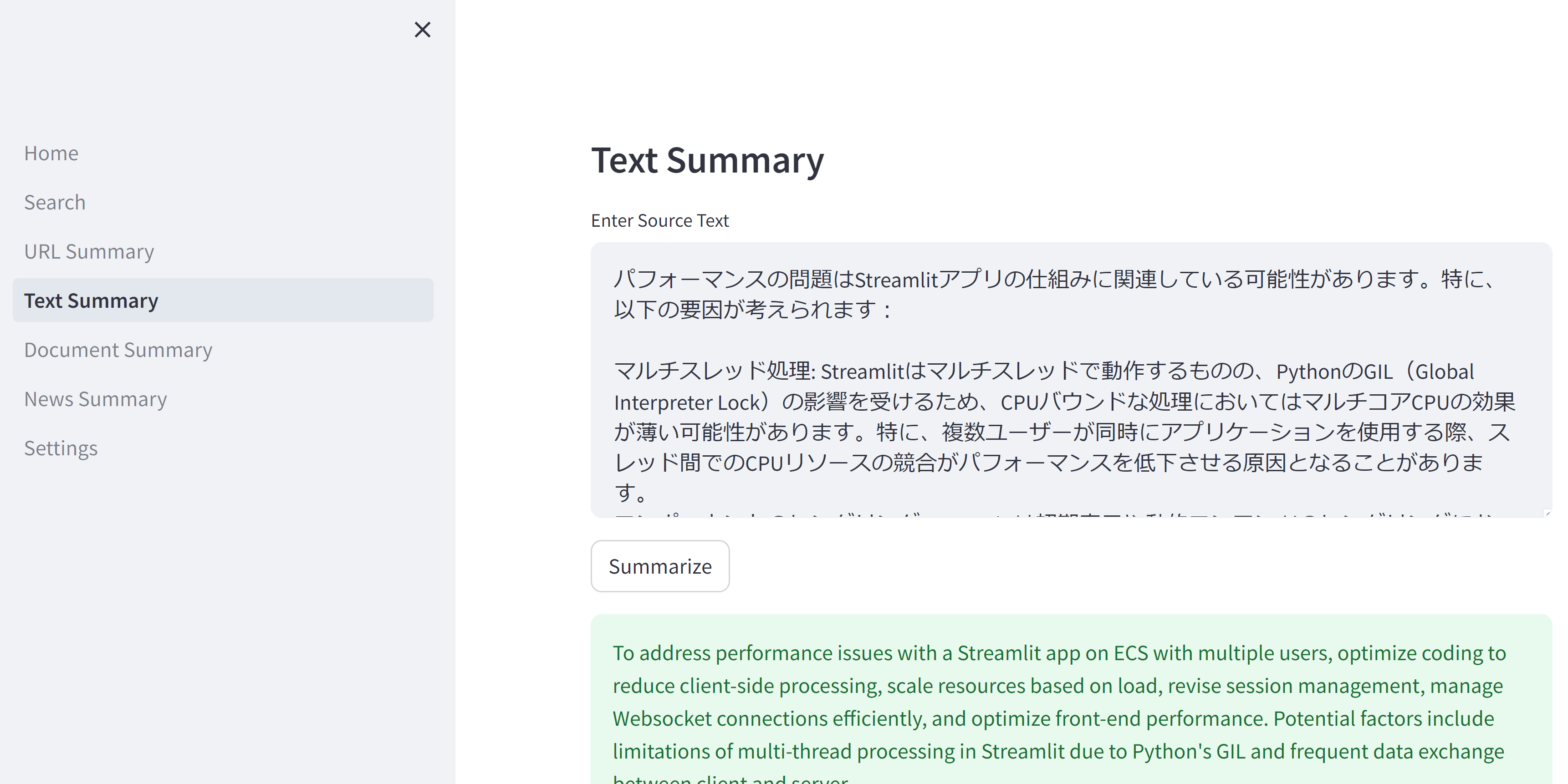
入力
あなたの指摘を以下の通り抽出しました。ここから、Issueチケットに記載することを想定し、簡潔な文体にまとめてください。箇条書きなどは維持してください。
ECS(Amazon Elastic Container Service)で動作するStreamlitアプリが複数ユーザーからの接続時にパフォーマンス問題を抱えている場合、以下の点をチェックしてみてください:
アプリケーションのコーディング: Streamlitはインタラクティブな操作を多く含むアプリケーションに使われることが多く、その性質上、クライアント側(ユーザーのブラウザ)での処理が重くなりがちです。クライアント側での処理負荷を軽減するために、不要な再描画やデータ更新を最小限に抑えるようにコードを最適化することが重要です。
リソースのスケーリング: コンテナが1つのみで運用されているとのことですが、アプリケーションの負荷に応じて自動的にスケールアウト(コンテナの数を増やす)設定がされているかどうかを確認してください。ECSではタスクの自動スケーリングポリシーを設定することで、リクエスト増加時に追加のコンテナをデプロイすることが可能です。
セッション管理: Streamlitはデフォルトでセッション情報をサーバー側に保持し、ユーザーのインタラクションごとにサーバー側で計算を行い結果をクライアントに返します。ユーザーが多い場合、このセッション情報の管理がボトルネックになることがあります。セッション情報の管理方法を見直し、不要な情報はクライアント側で処理するように変更すると良いかもしれません。
Websocketの利用: StreamlitはWebsocketを利用してサーバーとクライアント間の通信を行います。Websocketの接続数が多くなると、その管理に必要なリソースが増え、パフォーマンスが低下することがあります。接続数の上限やタイムアウトの設定を適切に行うことが重要です。
フロントエンドの最適化: クライアント側でのスクロールやその他のインタラクションの遅延は、JavaScriptやCSSの最適化が不十分である場合にも発生します。ブラウザのデベロッパーツールを使用してパフォーマンスを分析し、改善が必要な部分を特定すると良いでしょう。
パフォーマンスの問題はStreamlitアプリの仕組みに関連している可能性があります。特に、以下の要因が考えられます:
マルチスレッド処理: Streamlitはマルチスレッドで動作するものの、PythonのGIL(Global Interpreter Lock)の影響を受けるため、CPUバウンドな処理においてはマルチコアCPUの効果が薄い可能性があります。特に、複数ユーザーが同時にアプリケーションを使用する際、スレッド間でのCPUリソースの競合がパフォーマンスを低下させる原因となることがあります。
コンポーネントのレンダリング: Streamlitは初期表示や動的コンテンツのレンダリングにおいて、クライアントとサーバー間で頻繁にデータを送受信します。特に双方向コンポーネントが多用されている場合、これらの通信のオーバーヘッドがパフォーマンスに影響を与える可能性があります。
出力
To address performance issues with a Streamlit app on ECS with multiple users, optimize coding to reduce client-side processing, scale resources based on load, revise session management, manage Websocket connections efficiently, and optimize front-end performance. Potential factors include limitations of multi-thread processing in Streamlit due to Python's GIL and frequent data exchange between client and server.
文章をいくつかのページ(というか塊)に分けて、それぞれを要約した後、それぞれの要約結果を集めて一つの要約文章にする、というロジックを実施している模様(=map_reduce)
中のコード
try:
with st.spinner('Please wait...'):
# Split the source text
text_splitter = CharacterTextSplitter()
texts = text_splitter.split_text(source_text)
# Create Document objects for the texts (max 3 pages)
docs = [Document(page_content=t) for t in texts[:3]]
# Initialize the OpenAI module, load and run the summarize chain
llm = ChatOpenAI(temperature=0, openai_api_key=openai_api_key)
chain = load_summarize_chain(llm, chain_type="map_reduce")
summary = chain.run(docs)
st.success(summary)
except Exception as e:
st.exception(f"An error occurred: {e}")
Document Summary
アップロードしたpdfの中身を要約する
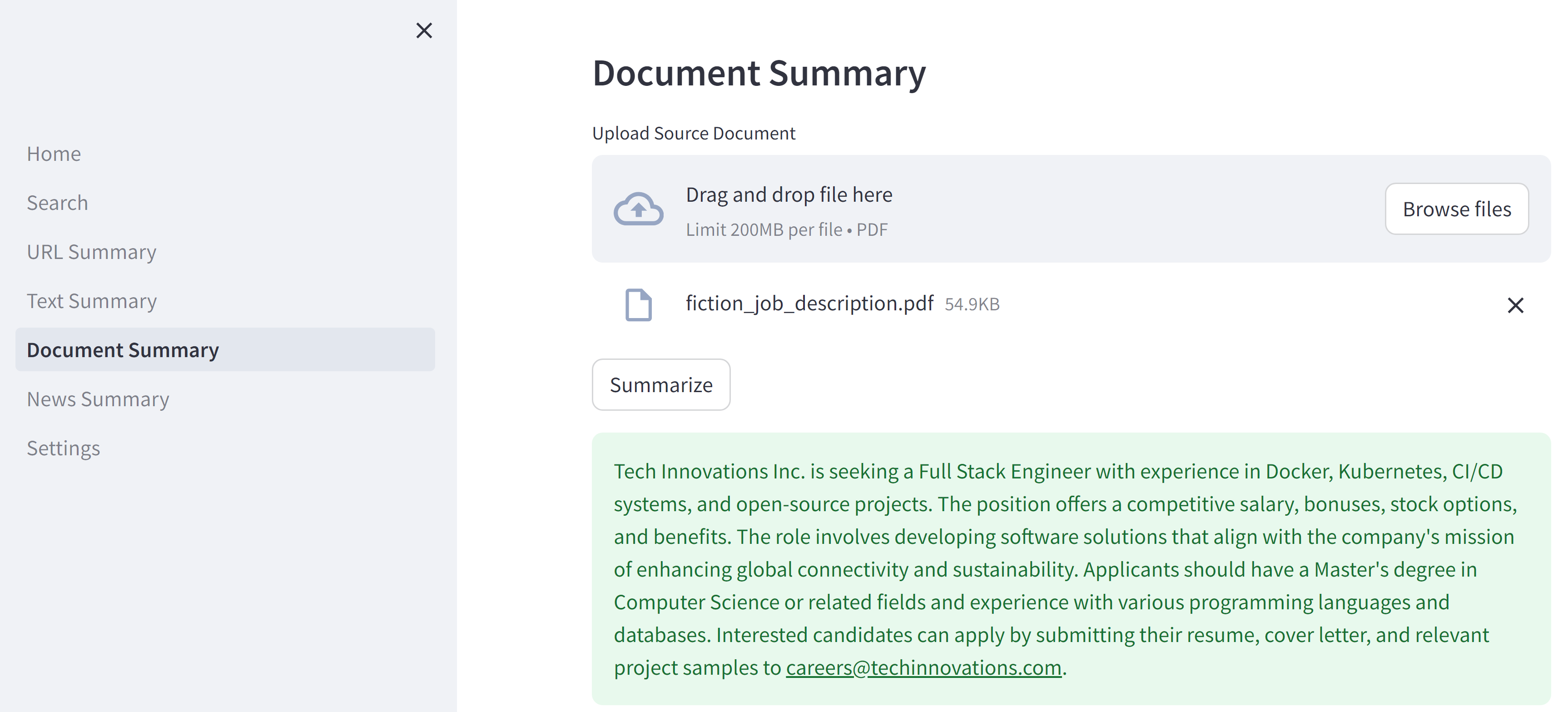
pdfの中身
# Full Stack Engineer Position at Tech Innovations Inc.
**Company Overview:**
At Tech Innovations Inc., we are committed to pioneering sustainable technology solutions that address real-world problems. Our mission is to create user-centric software that promotes global connectivity and efficiency. With a team spread across more than 20 countries, we strive for excellence through diversity and innovation.
**Job Title:**
Full Stack Engineer
**Location:**
Tokyo, Japan - Hybrid (with remote working options)
**Job Description:**
We are looking for a talented Full Stack Engineer to join our dynamic team. The ideal candidate will be responsible for designing, developing, and implementing software solutions across our platform. You will work closely with both the front-end and back-end teams to craft scalable and efficient systems that deliver a seamless user experience.
**Key Responsibilities:**
- Develop high-quality software design and architecture.
- Identify, prioritize, and execute tasks in the software development life cycle.
- Develop tools and applications by producing clean, efficient code.
- Automate tasks through appropriate tools and scripting.
- Review and debug code.
- Perform validation and verification testing.
- Collaborate with internal teams and vendors to fix and improve products.
- Document development phases and monitor systems.
- Ensure software is up-to-date with latest technologies.
**Requirements:**
- Proven experience as a Full Stack Developer or similar role.
- Experience with programming languages like Java, Python, Ruby, and PHP.
- Familiarity with front-end languages (e.g., HTML, JavaScript, CSS) and frameworks/libraries (e.g., Angular, React, Node.js).
- Excellent knowledge of relational databases (e.g., PostgreSQL, MySQL) and NoSQL databases (e.g., MongoDB).
- Experience with cloud-based infrastructure, preferably AWS.
- BSc/BA in Computer Science, Engineering or a related field.
**Preferred Qualifications:**
- Experience with Docker and Kubernetes.
- Familiarity with CI/CD systems.
- Master’s degree in Computer Science or related fields.
- Contributions to open-source projects.
**What We Offer:**
- Competitive salary package: ¥8,000,000 - ¥12,000,000 per year, based on experience.
- Performance bonuses and stock options.
- Health, dental, and vision insurance.
- Generous vacation allowance and flexible working hours.
- Opportunities for on-the-job training and yearly professional development.
- A vibrant, inclusive workplace culture that encourages innovation and creativity.
**Mission:**
As a Full Stack Engineer at Tech Innovations Inc., your mission is to develop software solutions that are not only robust and efficient but also align with our core philosophy of enhancing connectivity and sustainability globally. You will be instrumental in shaping the future of our technology and impacting the lives of millions worldwide.
**How to Apply:**
Please submit your resume, cover letter, and any relevant project samples or GitHub links to careers@techinnovations.com. We look forward to discovering how you can make a difference at Tech Innovations Inc.
要約内容
Tech Innovations Inc. is seeking a Full Stack Engineer with experience in Docker, Kubernetes, CI/CD systems, and open-source projects.
The position offers a competitive salary, bonuses, stock options, and benefits.
The role involves developing software solutions that align with the company's mission of enhancing global connectivity and sustainability.
Applicants should have a Master's degree in Computer Science or related fields and experience with various programming languages and databases.
Interested candidates can apply by submitting their resume, cover letter, and relevant project samples to careers@techinnovations.com.
ページごとに分割してテキストをロードし、それらをChromaDB(OSS: オンメモリのベクトルDB)にエンベディング
文章をいくつかに分け、そのすべてをプロンプトのコンテキストに埋め込んでしまう(chain_type=stuff)
ソースコード
try:
with st.spinner('Please wait...'):
# Save uploaded file temporarily to disk, load and split the file into pages, delete temp file
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(source_doc.read())
loader = PyPDFLoader(tmp_file.name)
pages = loader.load_and_split()
os.remove(tmp_file.name)
# Create embeddings for the pages and insert into Chroma database
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectordb = Chroma.from_documents(pages, embeddings)
# Initialize the OpenAI module, load and run the summarize chain
llm = ChatOpenAI(temperature=0, openai_api_key=openai_api_key)
chain = load_summarize_chain(llm, chain_type="stuff")
search = vectordb.similarity_search(" ")
summary = chain.run(input_documents=search, question="Write a summary within 200 words.")
st.success(summary)
except Exception as e:
st.exception(f"An error occurred: {e}")
News Summary
クエリからGoogle検索し、ヒットした記事を要約する
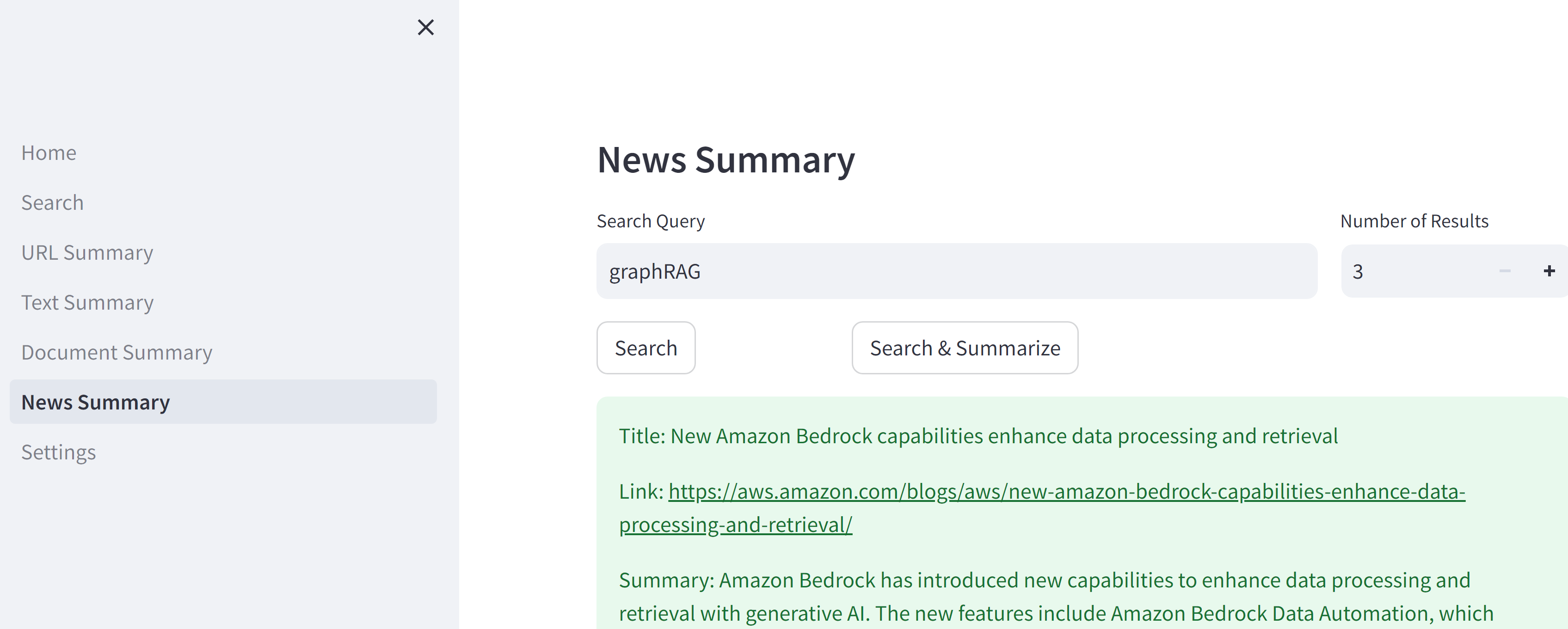
serperのapiでURL取得したあとはURL Summaryといっしょ
ドキュメントによると、type: Literal['news', 'search', 'places', 'images'] のように、検索するジャンルを場所や画像にもできそう
try:
with st.spinner("Please wait..."):
# Show the top X relevant news articles from the previous week using Google Serper API
search = GoogleSerperAPIWrapper(type="news", tbs="qdr:w1", serper_api_key=serper_api_key)
result_dict = search.results(search_query)
if not result_dict['news']:
st.error(f"No search results for: {search_query}.")
else:
for i, item in zip(range(num_results), result_dict['news']):
st.success(f"Title: {item['title']}\n\nLink: {item['link']}\n\nSnippet: {item['snippet']}")
except Exception as e:
st.exception(f"Exception: {e}")