はじめに
Pythonのライブラリの1つであるPandasについて初心者でも超わかりやすくまとめてみました。
本記事の内容
- 1.Pandasとは
- 2.SeriesとDataFrameについて
- 3.ファイルの読み込み・書き出し
- 4.データセットからDataFrameを作成
- 5.データの参照
- 6.ソート(並び替え)
- 7.DataFrameの列の追加
※順番に意味はなし
参考教材
- 産婦人科医とみーさんのブログ「Tommy blog」
リンク→Python入門者のための学習ロードマップ【ブログでも独学可能】
- AI Academyさんのテキスト教材
リンク→AI Academy
どちらもめっちゃわかりやすくオススメです。
環境
Python 3.7.6
Jupyter Notebook 6.0.3
1.Pandasとは

Pandas(パンダス)はPythonのデータ整形用ライブラリの1つです。
pandasは、プログラミング言語Pythonにおいて、データ解析を支援する機能を提供するライブラリである。
出典:Wikipedia
機械学習をする上で必須となるデータの解析や加工を行うことがライブラリです。
表形式のデータをSQL、Rのように操作することが可能で、かつ高速に処理可能。
Pandasでできること&よく使う機能を噛み砕いて書くとすると、
- CSV等のファイルの読み込み、書き出し
- 列・行の追加や削除
- データの抽出
- 欠損値(NaN)の補完(他の数字で置換する)
- データの結合
あたりだと感じてます。
上記の機能をまとめると**「データの前処理」**ですかね。
(データの整形、とも言うのかな?)
2.SeriesとDataFrameについて
Pandasの使ってデータを整形していく上での基本的なデータ構造。
- Series:1次元配列データ
- DataFrame:2次元配列データ
2-1.Seriesの作成
import pandas as pd
s = pd.Series([1, 11, 111, 1111])
print(s)
# 出力
# 左の列は行ラベル(インデックス)指定しなければ0からの連番になる
# 右の列はSeriesのデータ
0 1
1 11
2 111
3 1111
参考:Pandasの基本的なデータ構造Seriesの基礎と活用方法
2-2.DataFrameの作成
import pandas as pd
df = pd.DataFrame([
[1, 11, 111],
[2, 22, 222],
[3, 33, 333],
[4, 44, 444]
])
print(df)
# 出力
0 1 2
0 1 11 111
1 2 22 222
2 3 33 333
3 4 44 444
指定しない場合、1番左の列=インデックス(index)と1番上の行=カラム(columns)が自動で0からの連番が割り振られます。
インデックスとカラムを指定したDataFrameの作成
import pandas as pd
# indexとcolumnsはリスト型で定義する
index = [2017, 2018, 2019, 2020]
columns = ["部員数", "マネージャー数", "成績",]
# dataもリスト型で定義する
data = [
[30, 2, "1回戦負け"],
[35, 0, "3回戦負け"],
[50, 1, "準優勝"],
[70, 5, "優勝"]
]
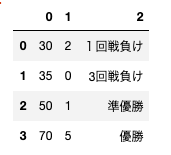
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
# 出力
部員数 マネージャー数 成績
2017 30 2 1回戦負け
2018 35 0 3回戦負け
2019 50 1 準優勝
2020 70 5 優勝
作成されたDataFrameを表形式で表すと以下の通り。
2017〜2020がインデックス(index)、
部員数〜成績がカラム(columns)です。
| 部員数 | マネージャー数 | 成績 | |
|---|---|---|---|
| 2017 | 30 | 2 | 1回戦負け |
| 2018 | 35 | 0 | 3回戦負け |
| 2019 | 50 | 1 | 準優勝 |
| 2020 | 70 | 5 | 優勝 |
DataFrameの作成方法について詳しく学びたい方は以下のリンクから飛んでください。
参考:【Python】pandas.DataFrameの概要と作成方法・変換方法
参考:Pandasのデータを格納するオブジェクトDataFrameを理解する
2-3.SeriesとDataFrameまとめ
SeriesとDataFrameとは
| データ型 | 概要 |
|---|---|
| Series(シリーズ) | 1次元配列データ |
| DataFrame(データフレーム) | 2次元配列データ |
作成方法
pd.Series(data, index)
pd.DataFrame(data, index, columns)
3.ファイルの読み込み・書き出し
Pandasでかなり使用頻度の高い機能です。
3-1.読み込み
読み込みは以下のコードで行う。
(読み込みたいファイルが、コードを書くファイルと同階層に存在する場合はファイルパスの記載は不要なのでファイル名の記載のみでOK)
pd.read_ファイル形式("ファイルのパス/ファイル名")
3-2.CSVファイルを読み込む場合
(読み込むCSVファイル(sample.csv)はJupyter Notebookと同じ階層とする)
import pandas as pd
# CSVファイルを読み込む
# encoding="cp932"がないと文字化けすることがある
data = pd.read_csv("sample.csv", encoding="cp932")
print(type(data))
# 出力
# CSVファイルを読み込むとDataFrame型になっている
<class 'pandas.core.frame.DataFrame'>
読み込めるファイル形式はCSVだけでなく、Excel等も可能
参考:【Python】pandasでCSV/TSVファイルを読み込む方法
参考:pandasでcsv/tsvファイル読み込み(read_csv, read_table)
3-3.書き出し
書き出しは以下のコードで行う。
(書き出したファイルをコードを書いているコードと同階層に保存する場合はファイルパスの記載は不要なのでファイル名のみでOK)
df.to_ファイル形式("ファイルのパス/ファイル名")
dfは定義する時にpd.DataFrameをしているのでdf.pd.to_ファイル形式にしなくてOKです。
※これはDataFrame型のデータを格納した変数に関してはどのメソッド(関数)でも同じです。
3-4.CSVファイルを書き出す場合
(Jupyter Notebookと同じ階層に書き出すことにする)
import pandas as pd
# 書き出すDataFrameを定義
index = [2017, 2018, 2019, 2020]
columns = ["部員数", "マネージャー数", "成績",]
data = [
[30, 2, "1回戦負け"],
[35, 0, "3回戦負け"],
[50, 1, "準優勝"],
[70, 5, "優勝"]
]
df = pd.DataFrame(data=data, index=index, columns=columns)
# CSVファイルを書き出す
# encoding="cp932"がないと文字化けすることがある(今回はしました)
df.to_csv("sample.csv", encoding="cp932")
上記コードを実行するとsample.csvが生成されます。
Jupter Notebook上でCSVファイルを開くとこんな感じです。
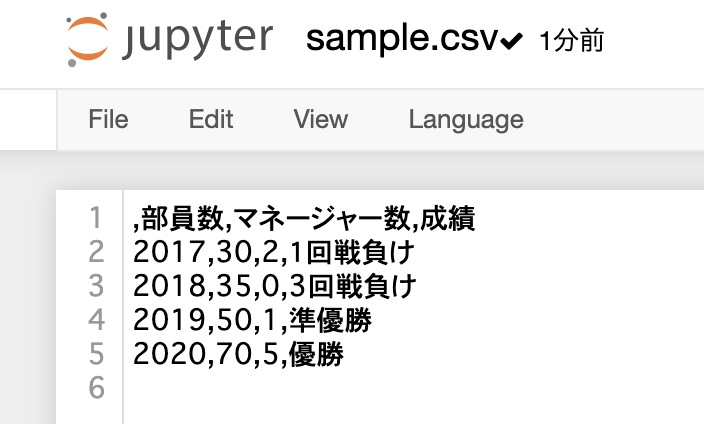
csvファイルをExcelで実際に開いて確認するとしっかり確認できています。
encoding="cp932"がない状態で書き出ししてみると文字化けしてました。
(ぜひご自分で試してみてください)

書き出す時に
インデックス(1番左の列)を表示しない場合は
df.read_csv("sample.csv", index=False)
カラム(1番上の行)を表示しない場合は
df.read_csv("sample.csv", header=False)
インデックス、カラムどちらも表示しない場合は
df.read_csv("sample", index=False, header=False)
※デフォルトはTrueなので何も指定しなければインデックスとカラムは表示されます
参考:【Python】pandasでCSV/TSVファイルを読み込む方法
参考:pandasでcsvファイルの書き出し・追記(to_csv)
3-5.ファイルの読み込み・書き込みまとめ
| 用途 | 書き方 | 注意点 |
|---|---|---|
| CSVファイルを読み込む | df.read_csv("ファイルパス/ファイル名") | encoding="pc932"を記載しないと文字化けする可能性がある |
| CSVファイルに書き出す | df.to_csv("ファイルパス/ファイル名") | encoding="pc932"を記載しないと文字化けする可能性がある |
| ※扱えるファイル形式はCSVだけではない。 |
4.データセットからDataFrameの準備
これまでDataFrameは適当な数字で作りましたが、これ以降はScikit-learnという機械学習用ライブラリに用意されているirisというデータセットを使ってみます。
(後述するがSeabornでも呼び出し可能)
irisとはアヤメという花の名前で、その花の情報がまとめられています。
Scikit-learnにはirisの他にも以下の通りすぐに機械学習やデータ分析に使えるデータが準備されています。
- boston(ボストン市の住宅価格データ)
- diabetes(糖尿病患者の診療データ)
- digits(数字の手書き文字データ)
- linnerrud(生理学的特徴と運動能力の関係についてのデータ)
- wine(ワインの品質データ)
- breast_cancer(乳がんデータ)
上記のirisを含むデータセットの説明と読み込み方はこちら
scikit-learnに付いてくるデータセット7種類を全部まとめてみた
まず、DataFrameを作成します。
4-1.irisデータセットの読み込み
from sklearn.datasets import load_iris
# irisデータセットをirisに格納
iris = load_iris()
4-2.読み込んだirisデータセットをDataFrameに変換して表示
from sklearn.datasets import load_iris
import pandas as pd
# irisデータセットをirisに格納
iris = load_iris()
# irisデータセットをDataFrameに変換
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df
実行すると、以下の表が表示されます。

Jupiter Notebookの良いところはDataFrame自体を打ち込んで実行すると綺麗な表形式で表示してくれるところですね。
print(df)
を実行してみると違いがわかります。
ここで、以下の式について軽く説明しておきます。
# irisデータセットをDataFrameに変換
df = pd.DataFrame(iris.data, columns=iris.feature_names)
irisデータセットにはdataオブジェクトとtargetオブジェクトがあり、
data:{ndarray, dataframe} of shape (150, 4)
The data matrix. If as_frame=True, data will be a pandas DataFrame.
target: {ndarray, Series} of shape (150,)
The classification target. If as_frame=True, target will be a pandas Series.
と書かれており、
iris.data・・・行列データ(分類するための情報)=説明変数
iris.target・・・分類対象=目的変数
と書くことでそれぞれの情報を取得することができます。
カラム名の指定(columns=iris.feature_names)についてですが、
先ほど同様、Scikit-learnの公式ドキュメントに、
feature_names: list
The names of the dataset columns.
と書かれており、カラム名はiris.feature_nameで取得することができます。
以上で、DataFrameを作成し、Pandasのメソッドを使う準備ができました。
4-3.irisデータセットからDataFrameの準備(その2)
Pythonのデータ可視化用ライブラリであるSeabornを使ってもirisデータセットを読み込むことができます。
以下のコードを実行することでirisデータセットを読み込むことができます。
Serbornはなぜかsnsという別名をつけるのが一般的です
import seaborn as sns
iris = sns.load_dataset("iris")
iris

Serbornでirisデータセットを読み込んだ場合、DataFrame型として読み込まれるので、
Scikit-learnで読み込んだ時のようにデータ型の変換は不要です。
その証拠にiris.head()でDataFrameの先頭から5つのデータを読み込むことができます。

以降はSeabornを使って作成したDataFrameであるirisを使います。
5.データの参照
データの参照はPandasの中でも重要な機能です。
以下のことを指します。
- データ情報の取得
- データの先頭、最後尾を数行表示
- データの中の一部を抽出
5-1.データの情報を取得
データの情報を取得するには以下のように記述。
情報なのでinfo、そのままですね。
iris.info()
ちなみにPandasが用意しているのでpd.info()じゃないの?
と思われた方もいるかもしれませんが、DataFrame型のデータの場合、pandas.DataFrameなのでPandasが既に適用されているので不要です。
(pd.DataFrame.pd.info()になってしまう)
出力結果

上の出力結果からざっくりわかることは以下の通り
- データの型がDataFrame型
- 行数が150つで、0から149ある
- 列数が5つ
- データの型、列名
そのDataFrameの全体的な情報を観見たい時に使います。
5-2.行数、列数の取得
# 行数の取得
len(iris)
# 出力結果
150
# 列数の取得
len(iris.columns)
# 出力結果
5
データの数を取得するにはlenを使います。(lengthのlen)
行数と列数をかければセルの数がわかります。
(150×5=750)
5-1.列名、行名の取得
列名、行名を取得するためには以下のコードを記述します。
(dfはDataFrame型のデータとします)
| 書き方 | 意味 |
|---|---|
| df.columns | 列名を取得 |
| df.index | 行名を取得 |
実際にirisデータセットから作成したDataFrame(iris)で試します。
# 列名を取得
iris.columns
# 出力結果
Index(['sepal_length', 'sepal_width', 'petal_length','petal_width','species'],dtype='object')
# 行名を取得
iris.index
# 出力結果
# 行名は0から150まで1ずつ割り振られていることがわかる
RangeIndex(start=0, stop=150, step=1)
5-2.列のみを指定して取得
ここからは実際にDataFrameのデータの一部を抽出していく操作です。
列のみを指定する場合は以下の通り記述します。
# 1列のデータを取得する
df.["列名"]
# 複数列のデータを取得する
# リストで渡す
df.[["列名1", "列名2", "列名3"]]
実際にirisで試してみると
iris.["sepal_length"]
出力結果

となります。
出力結果からもわかるように1列のみの取得の場合、取り出したデータの型はSeriesになります。
実際に
type(iris.["sepal_length"])
を実行してみるとわかります。
複数列を取得してみると
iris.[["sepal_length", "sepal_width"]]
出力結果
こちらは2列以なのでDataFrame型です。
Jupyter Notebookだとtype()を使わなくてもビジュアルでSeriesとDataFrameがわかりますね。
ちなみに、列名が設定されてない場合は、列に0からの数字が割り振られているので以下の記述で取得可能。
df[番号]
例えば以下のようなDataFrameとすると、
df[1]
を実行すると、以下の通り左から2列目のデータを取得できます。

ですが、実際にデータ分析をするデータには列名が設定されているので列番号による取得を使う機会は少ないと思います。
5-3.行のみを指定して取得
行を指定してデータを取得する場合は以下の通り記述します。
df[ここから:ここまで]
ここからとここまでには行に0から割り振られた数字が入ります。
(1番上が0行目で1、2、3・・・と下にいく)
つまり、
df[2:6]
は2行目から5行目までとなります。(※ここまで、の番号は入らない)
では実際にirisで試してみます。
iris[2:6]
出力結果
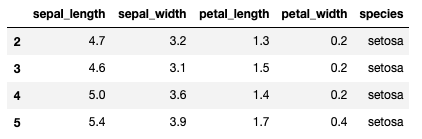
ちなみに1行だけ取得する場合はこのように記述します。
(4行目だけ取得)
df[4:5]
出力結果

ちなみに
df[4:4]
こう書いてしまうと、以下の通りヘッダーだけが表示されますのでご注意ください。

5-4.行と列を組み合わせて取得(行のみ取得も可能)
行と列を組み合わせて取得するにはloc[]、iloc[],query()等を使います。
5-4-1.loc[]での抽出
loc[]の使い方は以下の通り
df.loc[行, 列]
loc[]の引数には**ラベル名(index名、columns名)**を渡す必要があります。
行に関しては名前が設定されていない場合も多いので0からの連番で指定することが多いです。
# 2行目、sepal_length列を取得する
iris.loc[2, "sepal_length"]
# 出力結果
4.7
# どちらも絶対座標(行名、列名を指定していない時に割り振られる順番)を指定するとエラーになる
print(df.loc[1, 2])
# 出力はエラーメッセージになります
複数の行と列を指定する方法は以下の通りです。
df.loc[開始行:終了行, 開始列:終了列]
iris.iloc[2:6, "sepal_length":"sepal_width"]
上のコードで取得できるデータは以下の通り
- 2行目から6行目
- sepal_length列からsepal_width列まで
出力結果
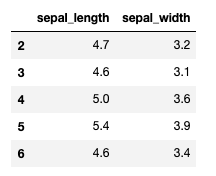
loc[]を使った場合は終了行、終了列のデータも含まれることがわかります。
5-4-2.iloc[]での抽出
iloc[]の使い方は以下の通り
df.iloc[開始行番号, 終了列番号]
iloc[]の引数には番号を渡す必要があります。
※loc[]の時のようにラベル名(index名、columns名)だとエラーになりますので注意
# 4行目、3列目を取得する
iris.iloc[3, 2]
# 出力結果
1.5
# ラベル名(index名、columns名)を指定するとエラーになる
iris.iloc[2018, "petal_length"]
# 出力はエラーメッセージになります
列は省略して行のみを指定することも可能。
# 10行目を取得(列は省略可能)
iris.iloc[10]
出力結果

1行のみを取得した場合はSeries型になります。
データの抽出では特定の範囲を指定することが可能。
iris.iloc[0:3, 0:2]
上記コードは
- 行:0〜2行目
- 列:0〜1列目
のデータを抽出するという意味になります。
**:は〜**と同じ使い方をします。
loc[]と違い、A:Bで指定したBは抽出対象に含まれないことに注意です。
出力結果
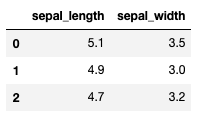
ではこちらは。
iris.iloc[:, :]
上記の場合は
- 行:全行
- 列:全列
のデータを抽出するので元々のデータフレームが返されます。
ではではこちら
iris.iloc[60:, :2]
上記の場合は
- 行:60行目〜最終行までの行
- 列:0列目〜1列目までの列
のデータを抽出することができます。
出力結果
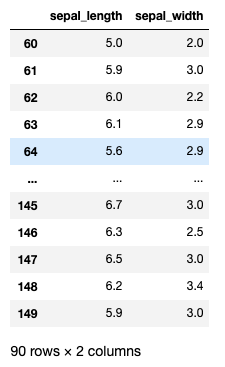
iloc[]の使う方をまとめると以下の表の通りになります。
| []の中 | 意味 |
|---|---|
| [4] | 4行目(列は省略) |
| [:10] | 0〜9行目(列は省略) |
| [3:9] | 3〜8行目 |
| [2:4, 4:6] | 2〜3行目、4〜6列目 |
| [:, 4] | 全行、4列目 |
| [2, :] | 2行目、全列 |
| [:, :] | 全行、全列(元のDataFrameが返る) |
| [1:, :5] | 1〜最終行、0〜4列目 |
上表の意味はすぐわかるようにしっかり抑えておきましょう。
参考:Pandasで要素を抽出する方法(loc,iloc,iat,atの使い方)
5-4-3.query()での抽出(条件付加)
条件に応じてデータを抽出したいときはquery()と使う。
query()の使い方は以下の通り
df.query("条件")
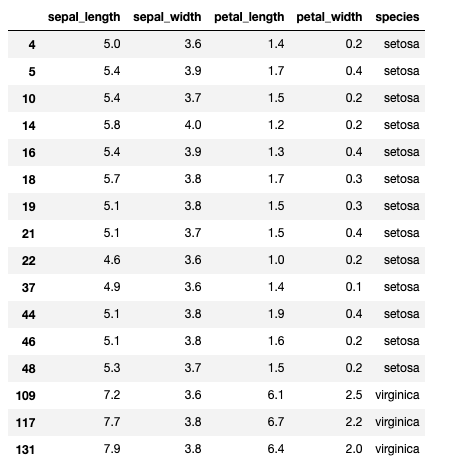
# sepal_width列の値が3.5より大きく、4以下の行を取得
iris.query("3.5 < sepal_width <= 4")
出力結果
# species列がvirginicaのもの
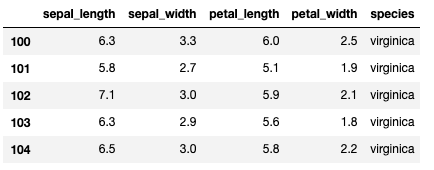
# そのまま出力すると数が多いのでhead()で先頭5行だけ表示
iris.query("species == 'virginica' ").head()
query()でデータを取得する場合、()の中の条件にはクオーテーション(' or ")を付けなければエラーになります。
以下、参考までに。
# 条件にクオーテーションを付けないとエラーになる
iris.query(species == 'virginica' ).head()
# 出力結果
NameError: name 'species' is not defined
エラーメッセージが表示されます。
では、最後にこちら。
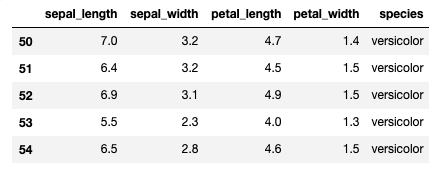
# species列にsetocaとvirginicaがないもの
# そのまま出力すると数が多いのでhead()で先頭5行だけ表示
iris.query(" species not in ['setosa', 'virginica']").head()
下の画像のようにversicolorのデータのみが取得できます。
参考:pandas.DataFrameの行を条件で抽出するquery
5-4.データの抽出まとめ
| 用途 | 使い方 | 注意点 |
|---|---|---|
| 行名、列名を指定 | loc[行,列]] | 終了行、終了列のデータも含む |
| 行番号、列番号を指定 | iloc[行,列] | 終了行、終了列のデータは含まない |
| 条件を指定 | query("条件") |
データの抽出の詳しい内容は以下のリンクから飛んでください。
参考:pandasのdataframeの要素の参照方法をマスターしよう
6.ソート(並び替え)
Pandasを使うと、要素をソート(並び替え)することができます。
ソートではScikit-learnのirisデータセットから作成したDataFrameであるdfを使用していきます。
(理由は特にないので、これまで通りSeabornのirisデータセットから作成したDataFrameであるirisを使っても全く問題ないですし、結果も同じです)
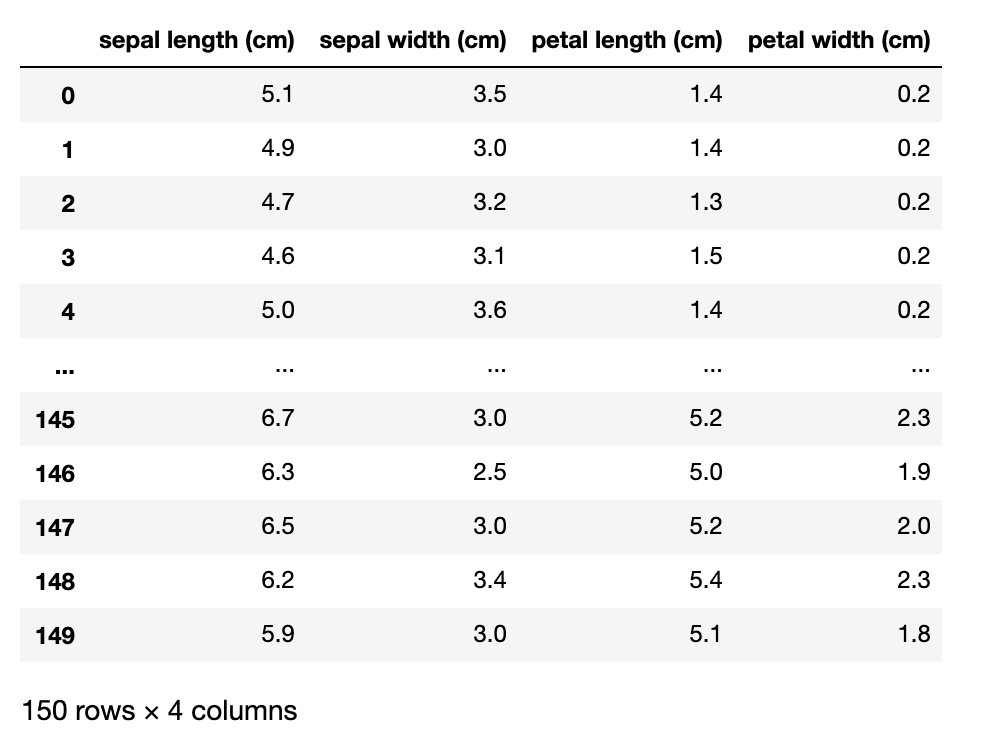
ソートする前にもう一度、dfを表示させておきます。
こちらを色々な方法でソートします。
6-1.要素でソート
要素でソート=特定のカラム(複数選択可)にある要素をソート
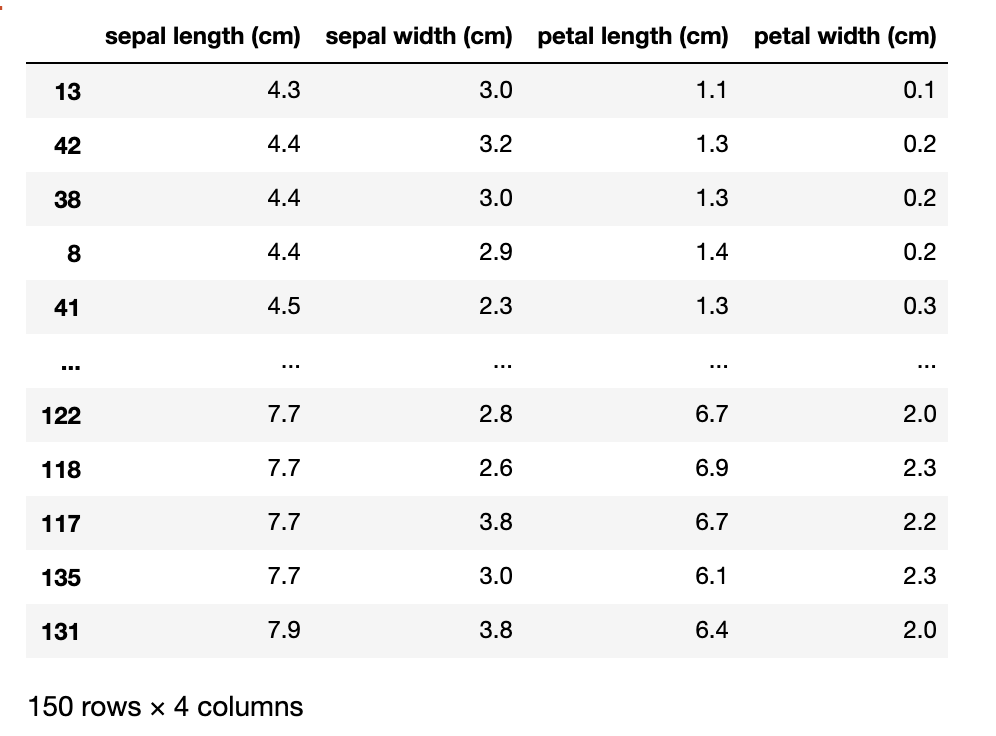
6-1-1.1列目のsepal length (cm)の要素をソート(昇順)
df.sort_values('sepal length (cm)')
# 注意点:lengthと(cm)の間に半角スペースを入れないとエラーになる
# 'でも"でもどちらでもOK
下の画像のようにsepal length(cm)列の要素が4.3→7.9のように並び替えられました。
(列名がバラバラになっている)
デフォルトでは昇順にソートされるので、降順でソートするためには第2引数にascending=Falseをつける。
ちなみに昇順、降順は以下の意味です。
- 昇順:小→大
- 降順:大→小
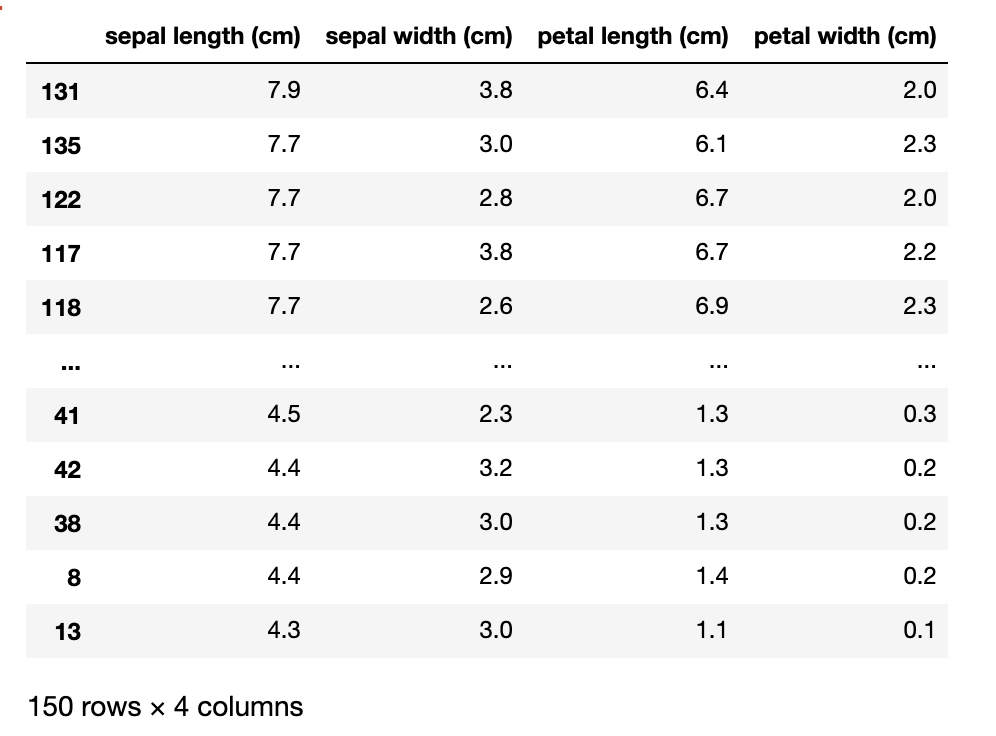
6-1-2.1列目のsepal length (cm)の要素をソート(降順)
df.sort_values('sepal length (cm)', ascending=False)
# 注意点:lengthと(cm)の間に半角スペースを入れないとエラーになる
# 'でも"でもどちらでもOK
下の画像のようにsepal length(cm)列の要素が7.9→4.3のように並び替えられました。
(列名がバラバラになっている)
デフォルトでは昇順でソートされますが、第2引数にascending=TrueをつけてもOK。
6-1-3.3列目(petal lenght (cm))と4列目(petal width (cm))でソート(複数列指定)
複数列の要素を同時にソートする場合は引数にリストで指定する。
# リストで指定する
df.sort_values(['petal length (cm)', 'petal width (cm)'])
# 注意点:length(width)と(cm)の間に半角スペースを入れないとエラーになる
# 'でも"でもどちらでもOK

イメージとしてはpetal length (cm)の値を昇順でソートして値が同じデータがあれば、petal width (cm)の値を昇順でソートする感じ。
上の画像だと122行目と117行目はpetal length (cm)の値はどちらも6.7です。
ソートの基準がpetal length (cm)だけだったら上から117行目、122行目になるはずです。
今回は引数にpetal width (cm)も指定しているので、petal width (cm)の値が小さい122行目が先に表示されています。
参考までにpetal length (cm)だけでソートした結果
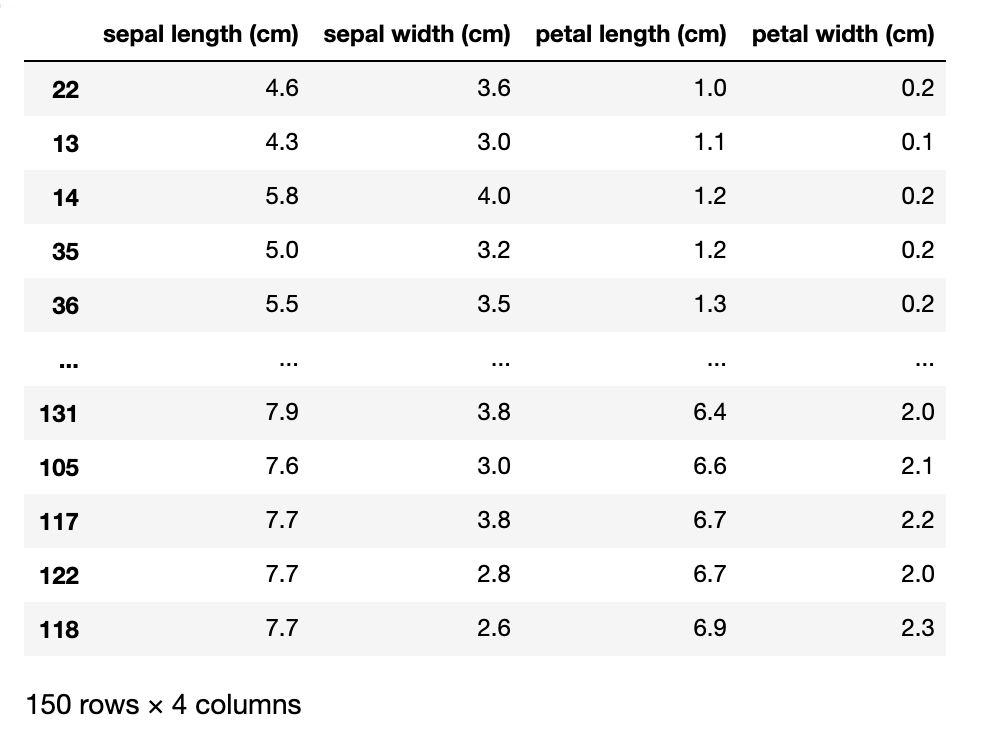
2つの画像で122行目と117行目の順番が逆になっている。
6-2.インデックス(行名・列名)でソート
インデックスでソート=行名または列名自体をソート
6-2-1.行名をソート
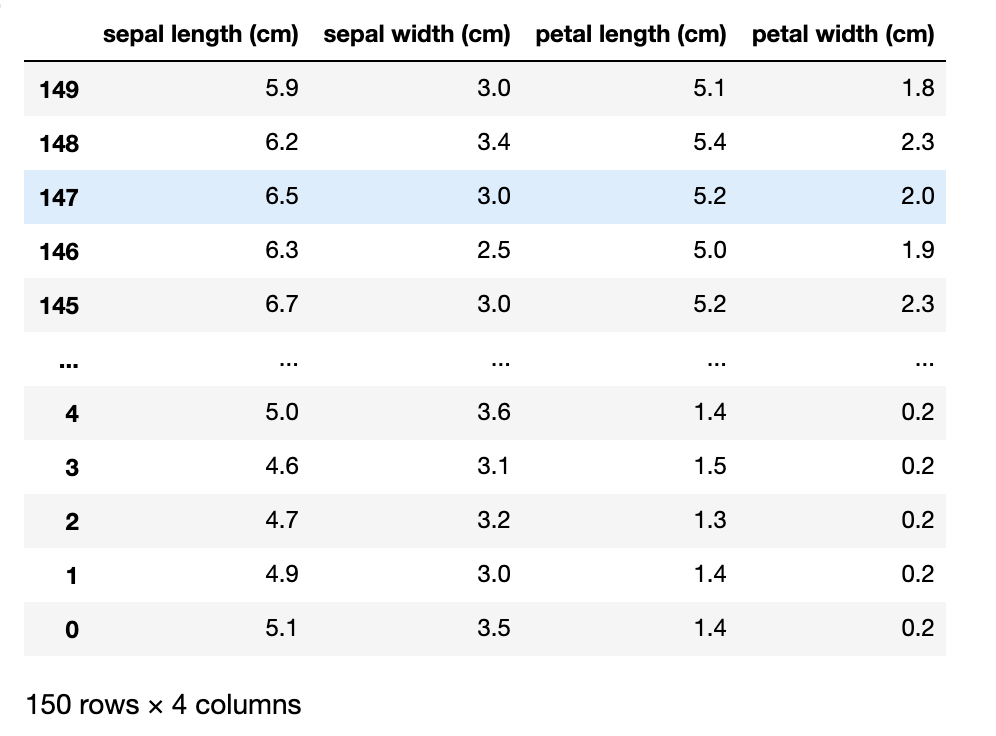
まず、行名に関しては元々のDataFrameが0から昇順に並んでいるので降順でソートします。
# ascending=Falseは降順の意味
df.sort_index(ascending=False)
下の画像のように行名が149→0にソートされます。
6-2-2.列名をソート
列名ソートするためには第1引数にaxis=1を指定する。降順の指定はこれまでと同じ
df.sort_index(axis=1)
列名がアルファベット順にソートされました。
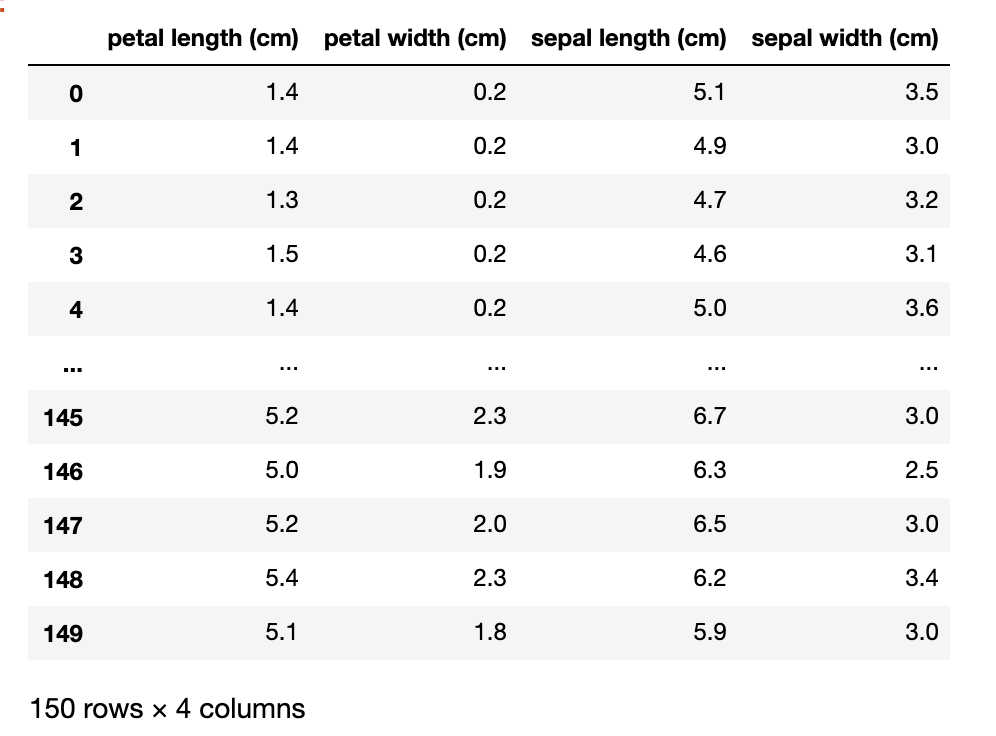
降順にソートする場合は第二引数にascending=Falseを指定するだけなので割愛。
ソートの方法はこちらの記事にもわかりやすくまとめられています。
参考:pandas.DataFrame, Seriesをソートするsort_values, sort_index
7.DataFrameの列の追加
列の追加もソート同様、Scikit-learnのirisデータセットから作成したDataFrameであるdfを使用していきます。
(理由は特にないので、これまで通りSeabornのirisデータセットから作成したDataFrameであるirisを使っても全く問題ないですし、結果も同じです)
DataFrameに列を追加する・値を上書きする方法は以下の通り。
- df[列名] = 値
- assign()メソッド
(他にもありますが本記事では割愛)
列の追加はデータ分析において、元々のデータから新しい特徴量(≒説明変数)を作成してDataFrameに追加する時に使用されます。
7-1.df[列名] = 値
dfにaddという列を追加します。(簡略化のため値は全て0)
df['add'] = 0
df

add列が追加されています。
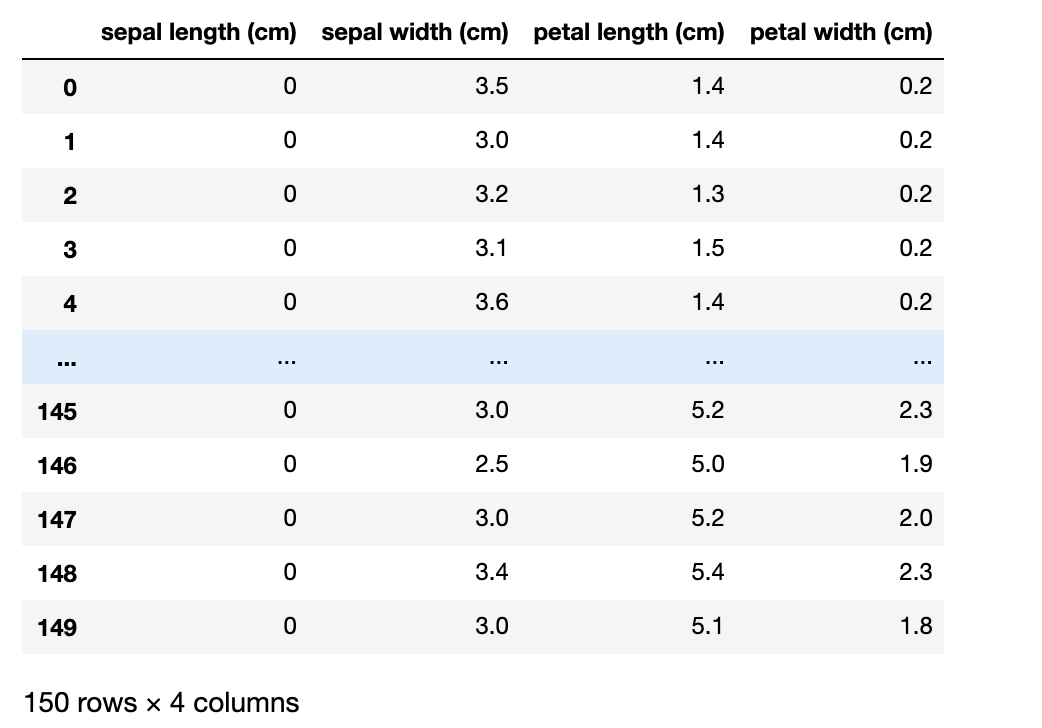
ちなみに既存列を指定することでデータを上書きすることもできます。
df['sepal length (cm)'] = 0
df
7-2.assign()メソッド
先ほど同様、add列を追加します。
df.assign(add=0)
df
# assgin()メソッドでは列名が文字列でも''を付けるとエラーになる
# エラー例
# df.assign('add'=0)

あれ?変わっていませんね。
ここが先ほどのdf[列名] = 値での追加と異なるところです。
assign()メソッドで列を追加した場合、新たなオブジェクト(DataFrame)が返され、元のオブジェクトは変更されません。
なので最後にdfを表示させると元々のirisデータセットが表示されます。
逆にdf[列名] = 値で列を追加もしくは既存列データの上書きをした場合は元のオブジェクトが変更されてしまうので注意が必要です。
例えば、df[列名] = 値の形で列を追加した場合は以下の通りになります。
(add列追加、sepal length (cm)列のデータ上書きどちらも反映)
df['add'] = 0
df['sepal length (cm)'] = 0
df
出力結果
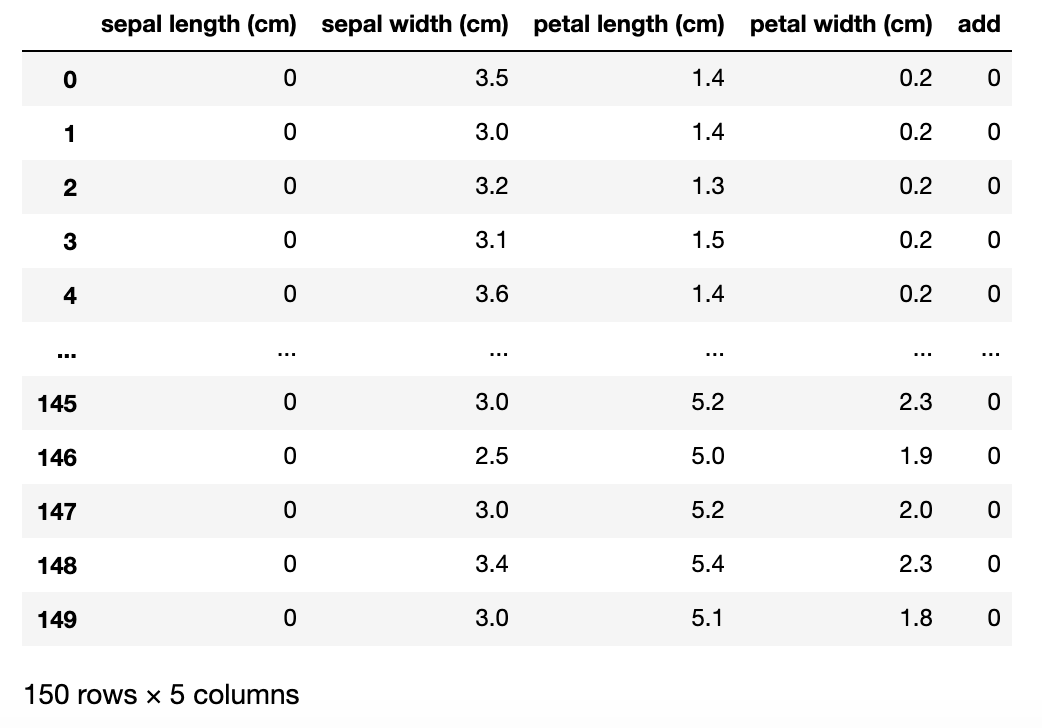
上の画像からわかるように元々のDataFrameに影響を及ぼします。
※なのでJupyter Notebookでこの処理を複数回実行してしまうとどんどん列が追加されてしまいます。
列を追加する処理はパートを分けて書いて上げると良いです。
df[列名] = 値でのDataFrameの操作の注意点を説明したところで話を戻します。
assign()メソッドを使用するときは以下のように実行します。
# この書き方をすると列がされた状態のDataFrameを表示可能
df.assign(add=0)
# ここで実行
# もしくは
# 返された新たなオブジェクトを変数に格納
df_new = df.assign(add=0)
df
# ここで実行

これでadd列が追加されましたね。
上書きの場合も同様です。
列の追加、行の追加も下リンクの記事に詳しく書かれています。
参考:pandas.DataFrameに列や行を追加(assign, appendなど)
列、行の名前の変更はこちら
参考:【Python】pandas.DataFrameの概要と作成方法・変換方法
まとめ
今回の記事ではPandasの基本的な扱い方を初学者の方でもかなりわかりやすいようにまとめました。
- 1.Pandasとは
- 2.SeriesとDataFrameについて
- 3.ファイルの読み込み・書き出し
- 4.データセットからDataFrameを作成
- 5.データの参照
- 6.ソート(並び替え)
- 7.DataFrameの列の追加
内容に間違い等あればコメントいただけると嬉しいです。
また、わかりにくいところがあればそちらもコメントいただけると嬉しいですm(__)m
僕がこれまでに投稿したPython関連の記事はこちら↓
【Python】集合型(セット)について図でわかりやすくまとめてみた