この記事はクラウドワークス Advent Calendar 2019 の11日目の記事です。
昨日は@lemtosh469による「アジャイル開発のスケーリングの方法」でした。
はじめに
みなさんこんにちは、クラウドワークスでサーバーサイドエンジニアをしている@shimopataです。普段はRailsを中心に機能開発したり改修作業とかに勤しんでいます。
先日、大量のデータ変換を伴うテーブルの差し替え作業をしました。データ量も多く、大変な作業でしたが計画、検証からやらせてもらい貴重な経験だったので、公開できる範囲で共有させて頂こうと思います。
やりたいこと
あるテーブルに保存されているデータの形式を変換し保存し直す。
対象は以下のテーブル
| テーブル名 | レコード数 |
|---|---|
| テーブルA | 65,000件 |
| テーブルB | 4,300,000件 |
| テーブルC | 200,000,000件 |
2億件もレコードあるのかー![]()
やったこと
調査と方針決め
まずはじめに、対象のテーブルがどのように使用されているのかについて調べました。一度登録されたデータがユーザの操作等によって更新されるかどうかで、対応方針が大きく異なると思い、調査し始めました。
結果、一度登録されたデータはユーザーによって、変更・削除されないことが分かり、以下の計画で変換することにしました。
【計画】
- 変換後の値を保存するテーブルを作成
- データを変換するスクリプトを実行し、1で作成したテーブルに保存
- テーブル名をリネームして差し替える
- 不要なモデル、テーブルを削除
図に示すと次のような感じです。
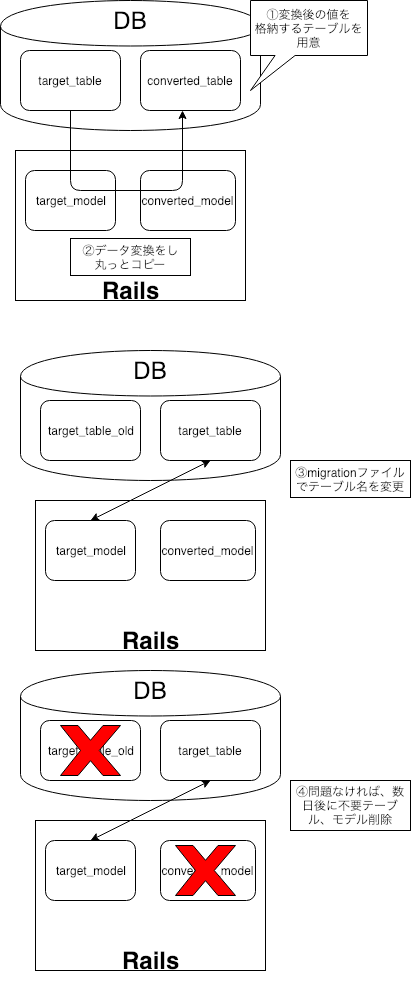
メリットとしては次の通り、安心安全にデータの変換が行えるのでこの方式を採用しました。
- 書き込みを行うテーブルはユーザが直接触るテーブルではないため、書き込み時にテーブルをロックしてもユーザ影響はなく、日中帯に作業ができる。
- 変換前のデータがテーブルに残るので何かあっても、そこからリカバリーができる。
スクリプトの作成について
データ件数が多く、処理時間が長くなってしまうことから、少しでも短くするために以下の対応を行いました。
find_in_batchesを使用して、変換速度の底上げ
繰り返し処理をする場合、データ数が少なければ、eachなどを事足りるのですが、今回は、データ数が多いのでfind_in_batchesを使用しました。find_eachとの違いは
- find_eachはデフォルトで1000個単位(引数batch_size:で指定可能)でデータを取得し、一件ずつをeachで処理していく
- find_in_batchesはデフォルトで1000個単位(引数batch_size:で指定可能)でデータを取得し,1配列毎に処理していく
どのくらい違いが出るかを手元にあるテストデータで試してみます。
Benchmark.realtime do
User.find_each(batch_size: 1000) { |user| p user }
end
-------以下、実行結果-----------
<User id: 1, created_at: "2019-12-15 00:00:00", updated_at: "2019-12-15 00:00:00">
<User id: 2, created_at: "2019-12-15 00:00:00", updated_at: "2019-12-15 00:00:00">
...
<User id: 2000, created_at: "2019-12-15 00:00:00", updated_at: "2019-12-15 00:00:00">
=> 1.006721000012476
Benchmark.realtime do
User.find_in_batches(batch_size: 1000) { |user| p user }
end
-------以下、実行結果-----------
[<User id: 1, created_at: "2019-12-15 00:00:00", updated_at: "2019-12-15 00:00:00">,
・・・
<User id: 1000, created_at: "2019-12-15 00:00:00", updated_at: "2019-12-15 00:00:00">]
[<User id: 1001, created_at: "2019-12-15 00:00:00", updated_at: "2019-12-15 00:00:00">,
・・・
<User id: 2000, created_at: "2019-12-15 00:00:00", updated_at: "2019-12-15 00:00:00">]
=> 0.4186677999678068
2000件程度のデータで約二倍の速度の違いが出ていますね。対象となるデータはこの1000000倍なので、find_in_batchesを使うしかないですね。
また、バッチサイズのサイジングもこのスクリプトのキーポイントでした。この数値を大きくする事で一度に処理できるデータの数を増やすことができ、その分、速度が早くなるのですが、当然、メモリを多く使用してしまいます。安全策をとるのであれば、夜に少しづつ変換を進めていくこともできたのですが、作業締め切りもあるため日中帯にスクリプトを流す必要がありました。
速度を出すために、バッチサイズを大きくしたい、でも、サービスに負荷をかけれない。。。
そのため、検証環境に大量のダミーデータを用意し、検証を行いました。バッチサイズの大きさを変更し実行しては、AWSコンソールメトリクスを確認を繰り返し、最適値を探しました。速度面、リソースの安全性からバッチサイズは5000としました。
activerecord-importを使用して書き込み速度の底上げ
activerecord-importというgemを使用しました。これは、一括でINSERT処理やUPDATE処理を行えるようにするgemで、スクリプト実行時間の大幅な短縮をすることができました。
使い方としては次のような感じです。
books = []
10.times do |i|
books << Book.new(name: "book #{i}")
end
Book.import books
modelにimportというメソッドが追加されるので、引数に取り込みたいデータを入れてあげるだけで、簡単にINSERT処理が行えます。また、オプションもたくさんあるため(特定のカラムだけ取り込む、取り込み時にバリデーションを張るなど)、興味があったら、gemのREADMEをみてみてください。
こちらも、どのくらい違いが出るかを手元にあるテストデータで試してみます。
users = []
Benchmark.realtime do
1000.times do |i|
users << TestUser.new(id: i,name: "test")
end
TestUser.import users
end
------------以下実行結果-----------------
0.1599934000405483
Benchmark.realtime do
1000.times do |i|
TestUser.create!(name: "test")
end
end
------------以下実行結果-----------------
5.3943878000136465
圧倒的に早そうですね。
変換スクリプトの実施
事前検証も終え、負荷なども問題ないことを確認した上で、本番サーバーに対して変換作業を行いました。いくら使用していないテーブルとはいえ、本番環境に対する変更のため、二週の間、対象となるデータを約1000万件単位に分割し勤務時間帯にのみスクリプトを実行していたのですが、とにかくデータ量が多く、時間がかかりました。リソースの監視はAWSのマネジメントコンソールの情報を中心に確認していました。
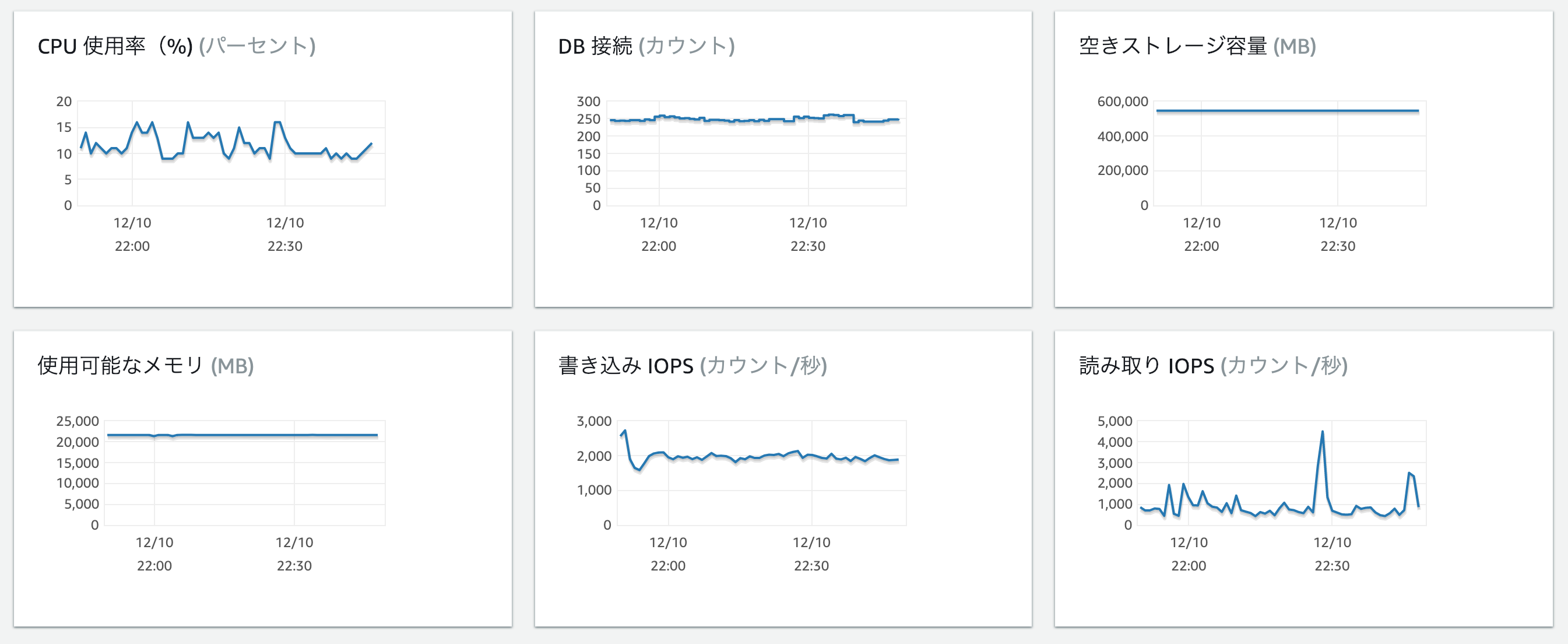
いつ、どのような不具合が発生するのか分からないという状況で長時間作業していくのはなかなか体力と精神を削られる作業で大変でした。![]()
テーブルの差し替え
変換作業が完了後、テーブル名を変換するmigrationを作成し、テーブルの差し替えを行いました。
def up
rename_table :target_table, :backup_target_table
rename_table :converted_table, :target_table
end
作業を初めて見ると、なかなかmigrationが終わらず、原因を探るために、migration実行中に発行しているクエリを確認しました。
次のクエリを実行して見てみると、インデックスの再作成で時間かかっている事が分かりました。
SELECT * FROM information_schema.PROCESSLIST WHERE Time >= 10 AND command = 'Query' ORDER BY Time DESC;
クエリ自体は問題なく発行されているので、ただ待つしかなく、結果として、作業時間を超えてしまったのですが、大量のデータ取り扱ってく上での学びになりました。
終わりに
テーブルの差し替え作業のタイミングでチームを移ってしまい、先輩エンジニアに作業を引き継ぎました。この作業のタイミングで、tableBのデータについて、特定の条件下で登録したデータがユーザによって削除であることが分かりました。1が、なんとかこれも対応してもらい、ほんと、ありがとうございました。
データ変換をやり始めてからでないと分からないリスクとして、
- バリデーションなどの制約から外れているデータ
- 過去に何らかの理由で手動でデータ修正をして、想定していない形で入っているデータ
などを想定していたのですが、実際にやってみると意外に該当するものは少なく、よかったです。
振り返ってみるとやっていること自体は単純だったりするのですが、やっていた当時は「本当に大丈夫なんだろうか、問題ないのだろうか」とリスクがないことを証明する悪魔の証明をずっとしながら、作業工程を組み立てていたので、非常に不安になりながら作業を進めていました。
そんな状況の中でも、相談に乗ってくれたり、作業に協力してくれたエンジニアに支えられてなんとかゴールまで行けたのかなと思います。
ゴールに辿り着くまでに色々失敗をしたりしたのですが、学びとして得られるものも大きく、今後に生かしていきたいと思います。
-
最初の調査の時に気づけなかったのは反省です。。。 ↩