はじめに
Amazon Bedrock Knowledge Base と OpenSearch Serverless を使った RAG ベースのドキュメント検索機構を AWS CDK (TypeScript) で構築しました。
マネージドサービスを組み合わせるだけなので簡単に見えますが、CDK で実装すると CFn トークンの扱いや DataAccessPolicy の2層構造など、ドキュメントだけでは気づきにくい落とし穴がいくつかありました。
(ハマりポイントの詳細は別記事にまとめる予定です。)
この記事では本構成の全体像・設計判断・CDK の実装ポイントを中心に解説します。
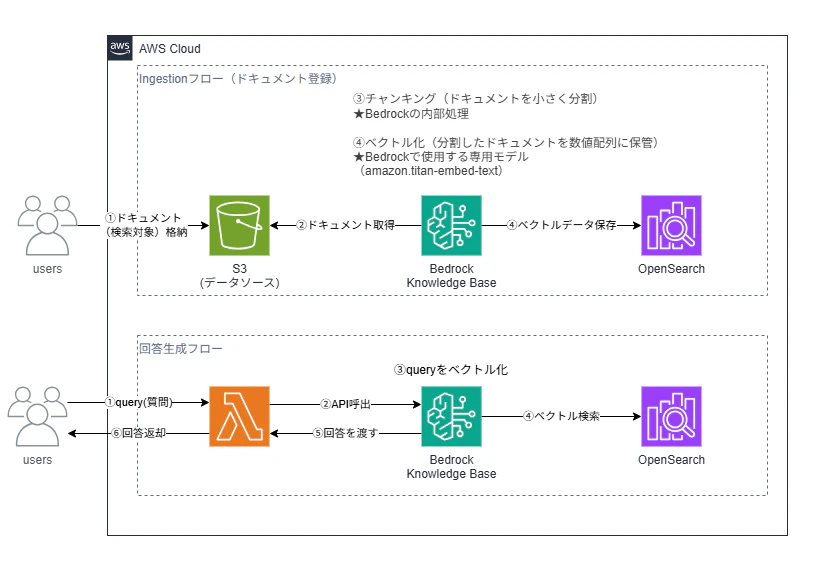
今回作成した構成の構成図は以下の通りです。
ソースコード: GitHub
本構成をデプロイする場合 $350/月 かかります。(OpenSearch Serverlessのせい)
検証が終わったらすぐ cdk destroy することを推奨します。
RAG の全体フロー
構成を理解するために、Ingestion(ドキュメント登録)と 回答生成(Retrieve & Generate)の2つのフローを整理します。
Ingestion フロー(ドキュメント登録)
フローは以下の通りです。
チャンキングとベクトル化は別処理です。(チャンキング = テキストを分割、ベクトル化 = 数値配列に変換)
SEMANTIC チャンキングのみ例外で Foundation Model(今回はTitan) を使うため追加コストが発生します。
また、Ingestion 完了後の検索フローに S3 は登場しません。OpenSearch に保存済みのベクトルを使います。
S3(ドキュメント置き場)
↓ s3:GetObject / s3:ListBucket
Bedrock Knowledge Base
↓ チャンキング(FIXED_SIZE: 300トークン / オーバーラップ20%)
↓ ベクトル化(Titan Embed Text v2)
OpenSearch Serverless(ベクトルを保存)
回答生成 フロー(Retrieve & Generate)
フローは以下の通りで、Ingestionフローよりもシンプルです。
retrieve_and_generate の1回の呼び出しでベクトル検索と回答生成がまとめて返ってきます。
Lambda(query を受け取る)
↓ retrieve_and_generate API(1回の呼び出し)
Bedrock Knowledge Base(query をベクトル化 → OpenSearch で類似度検索 → Nova Lite で回答生成)
↓
Lambda(answer + citations を返す)
CDK スタック構成
今回はマルチスタック分割を採用しましたので、依存関係の順にデプロイされます。
単一スタックにしなかった理由は、IamStack を OpenSearchStack より先に作成する必要があるためです。
OpenSearch Serverless の DataAccessPolicy に Knowledge Base ロールの ARN を登録するには、ロールが先に存在する必要があるので、単一スタックでは循環参照になります。
DatasourceStack(S3)
└─ IamStack(Knowledge Base 実行ロール)
└─ OpenSearchStack(コレクション + インデックス自動作成)
└─ KnowledgeBaseStack(Knowledge Base + DataSource)
└─ ComputeStack(Lambda)
各スタックの実装ポイント
DatasourceStack
RAG のデータソースとなる S3 バケットを管理します。
const bucket = new s3.Bucket(this, 'DocumentBucket', {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
enforceSSL: true,
});
IamStack
Bedrock Knowledge Base の実行ロールを管理します。OpenSearchStack より先に作成することで、ロール ARN を DataAccessPolicy に登録できます(循環参照の回避)。
Knowledge Base ロールに付与する権限:
| アクション | 対象 | 用途 |
|---|---|---|
s3:GetObject / s3:ListBucket
|
DocumentBucket | Ingestion 時のドキュメント取得 |
bedrock:InvokeModel |
Titan Embed Text v2 | ベクトル化 |
aoss:APIAccessAll |
* |
OpenSearch Serverless データプレーンへのアクセス |
aoss:APIAccessAll のリソース指定は * のみ有効です。コレクション ARN での絞り込みはできません。
https://docs.aws.amazon.com/opensearch-service/latest/developerguide/serverless-data-access.html
OpenSearchStack
コレクションの作成と、インデックスを自動作成する Custom Resource を管理します。
const collection = new opensearchserverless.CfnCollection(this, 'Collection', {
name: 'rag-collection',
type: 'VECTORSEARCH',
});
インデックス作成には Custom Resource Lambda を使います。requests-aws4auth を Lambda Layer としてバンドルする必要があります(詳細はハマり記事参照)。
DataAccessPolicy の policy は cdk.Fn.sub で組み立てます(JSON.stringify は CFn トークンを解決できないため)。
const dataAccessPolicy = cdk.Fn.sub(
JSON.stringify([{
Principal: ['${KnowledgeBaseRoleArn}', '${IndexCreatorRoleArn}'],
Permission: ['aoss:CreateIndex', 'aoss:WriteDocument', 'aoss:ReadDocument',
'aoss:UpdateIndex', 'aoss:DescribeIndex', 'aoss:DeleteIndex'],
ResourceType: 'index',
Resource: ['index/rag-collection/*'],
}]),
{
KnowledgeBaseRoleArn: props.knowledgeBaseRole.roleArn,
IndexCreatorRoleArn: indexCreatorRole.roleArn,
}
);
KnowledgeBaseStack
Bedrock Knowledge Base 本体と S3 データソースを管理します。
チャンキング設定:
chunkingStrategy: 'FIXED_SIZE',
fixedSizeChunkingConfiguration: {
maxTokens: 300,
overlapPercentage: 20,
}
ComputeStack
retrieve_and_generate API を呼び出す Lambda を管理します。
Lambda に付与する権限:
| アクション | 対象 |
|---|---|
bedrock:RetrieveAndGenerate |
*(KB ARN にスコープ不可) |
bedrock:Retrieve |
KnowledgeBase ARN |
bedrock:InvokeModel |
Nova Lite ARN |
bedrock:RetrieveAndGenerate だけリソース指定のルールが違います。詳細はハマり記事を参照してください。
Lambda の入出力:
// 入力
{ "query": "質問テキスト" }
// 出力
{ "answer": "回答テキスト", "citations": [{ "チャンクの出典情報" }] }
チャンキング戦略の選択
Bedrock Knowledge Base のチャンキング戦略は4種類あります。
今回は FIXED_SIZE(300トークン / オーバーラップ20%)を採用しました。
まず動かすことを優先し、精度への影響は改造で検証する予定です。
| 戦略 | 特徴 | 追加コスト |
|---|---|---|
| FIXED_SIZE | トークン数で機械的に分割。シンプルで予測しやすい | なし |
| HIERARCHICAL | 親チャンク(大)と子チャンク(小)の2段階。精度と文脈のバランスが良い | なし |
| SEMANTIC | NLP で意味的なまとまりを検出して分割。文の途中で切れない | FM 使用分 |
| NONE | ドキュメント1件 = チャンク1件 | なし |
デプロイ~検証~削除
1.Lambda Layer のセットアップ(初回のみ)
OpenSearch Serverless へのリクエスト署名に requests-aws4auth を使用するため、Lambda Layer としてバンドルする必要があります。
mkdir -p cdk/lambda-layer/python
pip install requests requests-aws4auth -t cdk/lambda-layer/python
2.デプロイ
cd cdk
npm install
npm run deploy # cdk deploy --all --require-approval never
3.S3にドキュメントをアップロード
検証用のサンプルドキュメントとして社内規定集(company-rules.txt)を用意しました。
company-rules.txt の内容
社内規定集
最終更新日: 2025年4月1日
━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第1章 有給休暇
━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【取得ルール】
- 有給休暇は入社6ヶ月後から取得可能。
- 年間付与日数は勤続年数に応じて10〜20日。
- 半日単位での取得が可能。時間単位は不可。
【申請方法】
- 取得希望日の3営業日前までに上長へSlackで申請する。
- 急病など緊急の場合は当日朝9時までに上長へ電話連絡し、後日申請書を提出する。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第2章 経費精算
━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【対象経費】
- 業務上必要な交通費、書籍代、外部研修費、接待交際費が対象。
- 個人的な飲食費・娯楽費は対象外。
【交通費】
- 通勤交通費は月額上限3万円。
- 出張時の交通費は実費精算(新幹線はグリーン車不可、飛行機はエコノミークラスのみ)。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第3章 リモートワーク
━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【利用条件】
- 入社3ヶ月以降から利用可能。
- 週3日までリモートワーク可能。残り2日は原則出社。
- コアタイムは10:00〜15:00(フレックスタイム制)。
【禁止事項】
- カフェ・コワーキングスペースでの機密情報の取り扱いは禁止。
- VPNを使用せずに社内システムへアクセスすることは禁止。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第4章 情報セキュリティ
━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【パスワード管理】
- パスワードは12文字以上、英数字・記号を含めること。
- 同一パスワードの使い回しは禁止。
【端末管理】
- 会社支給端末には必ずMDMを設定すること。
- 端末の紛失・盗難は直ちに情報システム部へ報告する。
$ aws s3 cp sample-docs/company-rules.txt s3://<BUCKET_NAME>/ --profile <PROFILE>
upload: ../sample-docs/company-rules.txt to s3://<BUCKET_NAME>/company-rules.txt
S3 にアップロードしただけでは Knowledge Base には反映されません。
次の Ingestion Job を実行して初めてベクトル化・インデックス登録が行われます。
4.Knowledge BaseのIngestion Jobを開始
S3にアップロードしただけでは Knowledge Base には反映されないので、マネコンから手動で同期ボタンを押下する必要があります。
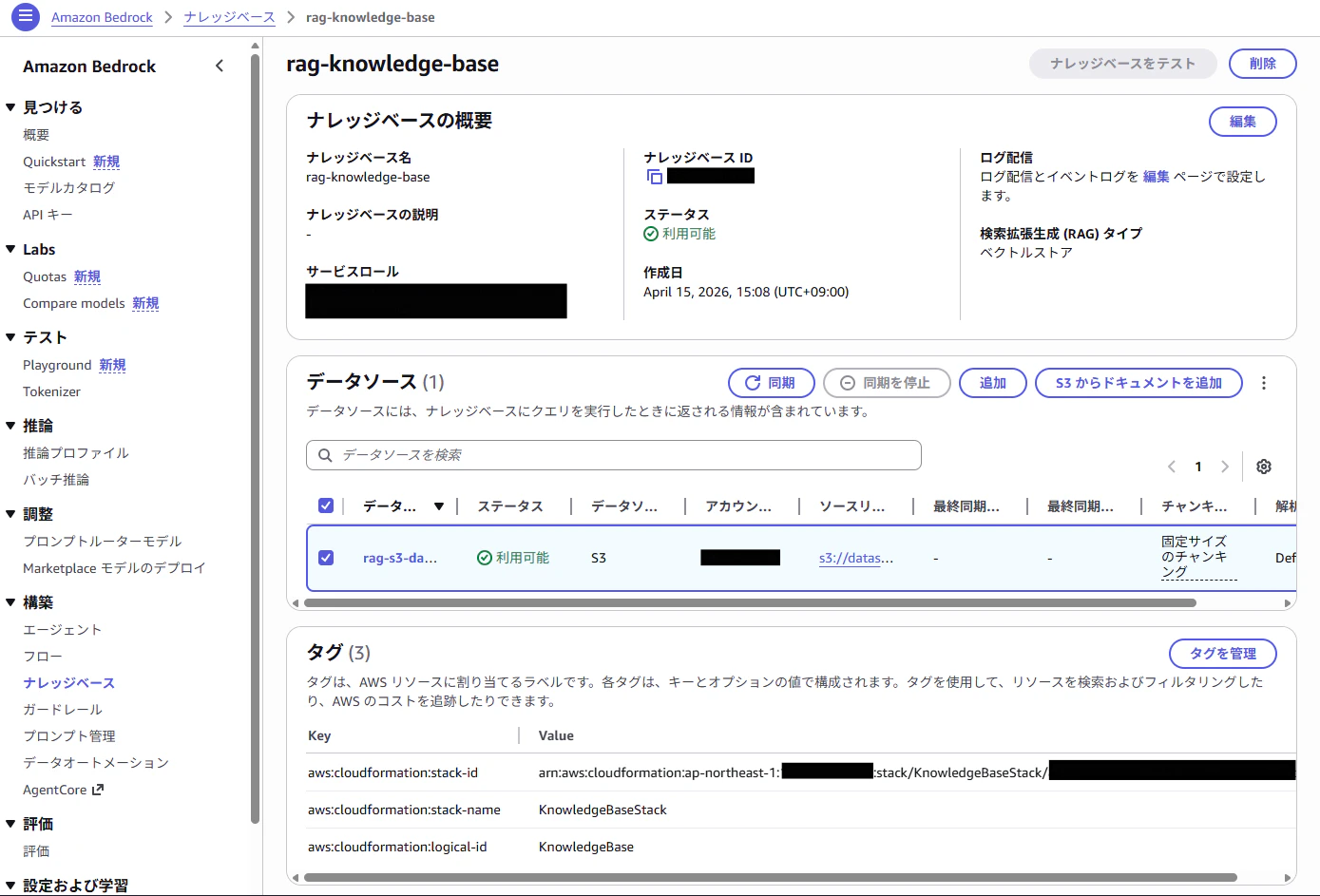
5.Sync完了を確認
マネコンから同期が完了したことを確認するため、Ingestion Job のステータスが COMPLETE になるまで待ちます。
ステータスが FAILED の場合は IAM ロールの権限不足か、S3 バケットポリシーの設定ミスが想定されます。
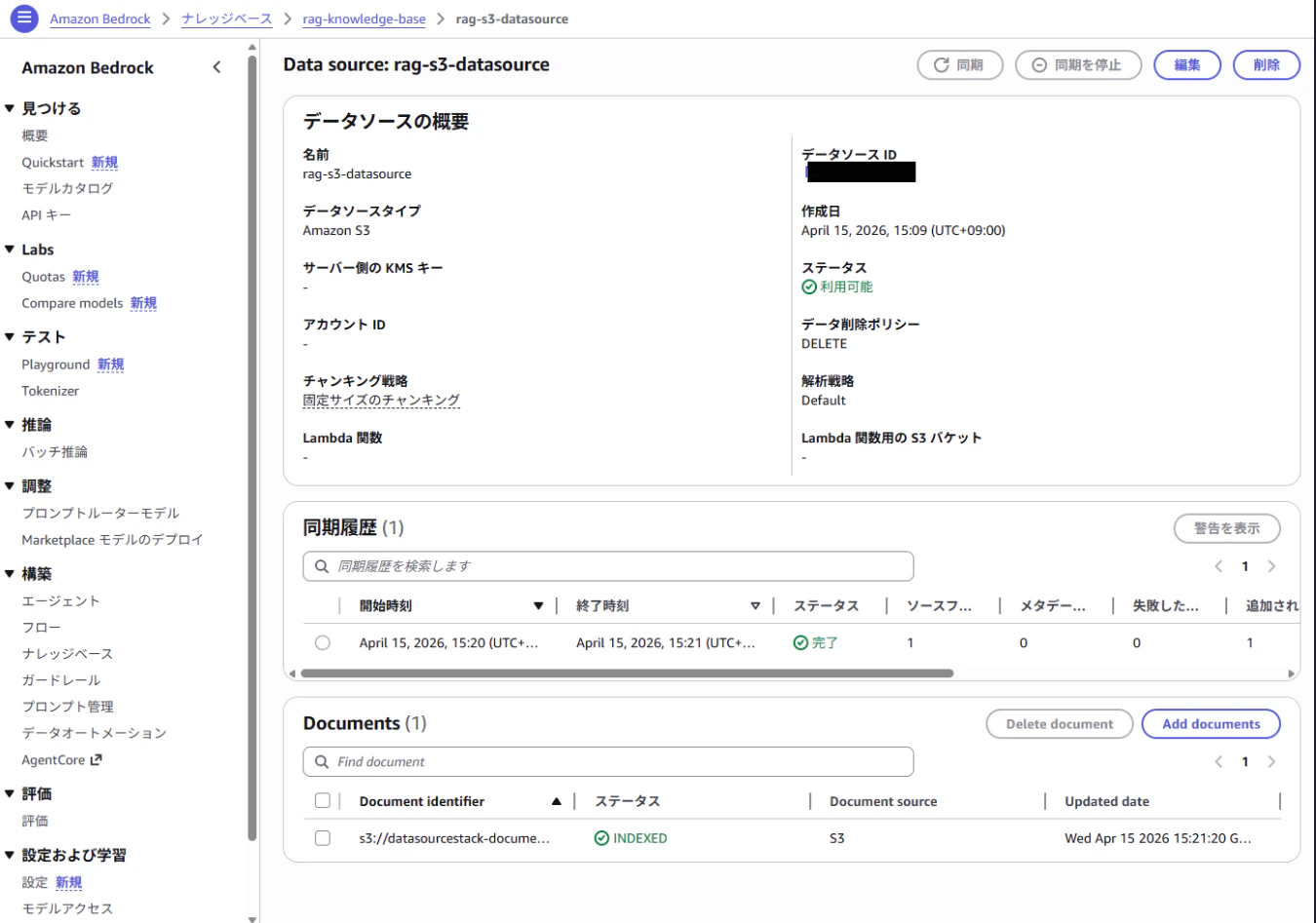
6.回答生成
ローカル端末からlambdaを実行して回答を生成してみます。
$ aws lambda invoke \
--function-name <FUNCTION_NAME> \
--payload '{"query": "リモートワークは週何日できますか?"}' \
--profile <PROFILE> \
--cli-binary-format raw-in-base64-out \
response.json && cat response.json
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
{"answer": "リモートワークは週3日まで可能です 。",
"citations": [{"generatedResponsePart": {"textResponsePart": {"span": {"end": 17, "start": 0}, "text": "リモートワークは週3日まで可能です"}},
"retrievedReferences": [{
"content": {"text": "━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 第3章 リモートワーク ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 【利用条件】 - 入社3ヶ月以降から利用可能。 - 週3日までリモートワーク可能。残り2日は原則出社。 - コアタイムは10:00〜15:00(フレックスタイム制)。 【申請方法】 - 前週金曜日までに翌週のリモート予定をSlackの「#勤怠連絡」チャンネルに投稿する。 - 急な変更は当日9時までに上長へ連絡する。 【禁止事項】 - カフェ・コワーキングスペースでの機密情報の取り扱いは禁止。 - VPNを使用せずに社内システムへアクセスすることは禁止。", "type": "TEXT"},
"location": {"s3Location": {"uri": "s3://xxxxxxxxxxxx/company-rules.txt"}, "type": "S3"},
"metadata": {"x-amz-bedrock-kb-source-uri": "s3://xxxxxxxxxxxx/company-rules.txt", "x-amz-bedrock-kb-source-file-modality": "TEXT", "x-amz-bedrock-kb-chunk-id": "xxxxxxxxxxxx", "x-amz-bedrock-kb-data-source-id": "xxxxxxxxxxxx"}}]}]
}
リモートワークが何日できるかという問いに対して、社内規定集(company-rules.txt)を確認して回答していることが確認できました。
citations にはチャンクの出典情報(S3 のオブジェクトキー・バイト範囲)が含まれます。
「どのドキュメントのどの部分を根拠に回答したか」を追跡できるのが RAG の強みです。
7.削除
npm run destroy
cdk destroy 前に S3 バケット内のオブジェクトを削除する必要はありません。autoDeleteObjects: true を設定しているため、スタック削除時に自動で空にしてから削除されます。
コスト注意点
OpenSearch Serverless は最小構成でも $350/月 かかります。
学習用途では検証が終わったらすぐ cdk destroy することが必須です。
| リソース | 概算月額 |
|---|---|
| OpenSearch Serverless(最小 1 OCU × 2) | $350〜 |
| Bedrock Titan Embeddings v2 | $0.00002/1,000トークン |
| Bedrock Nova Lite(Generate) | 入力 \$0.00006 / 出力 \$0.00024 / 1,000トークン |
| Lambda / S3 | ほぼ $0 |
OpenSearch Serverless の課金は コレクションが存在している時間に対して発生します。
cdk destroy でコレクションを削除するまで課金が続くため、検証が終わったら即削除が鉄則です。
まとめ
- RAG の Ingestion と Retrieve & Generate は別フロー。Ingestion 完了後の検索に S3 は登場しない
- マルチスタック分割は循環参照を避けるための設計判断
- チャンキング戦略は FIXED_SIZE から始めて精度を検証するのが無難
- OpenSearch Serverless は固定費が高いため、検証後即
cdk destroyが必須
ソースコードはGitHubで公開してるので良ければ参考にしてください。
次回は CDK 実装で踏んだハマりポイント(CFn トークン・DataAccessPolicy の2層構造・署名ライブラリ)を書きます。